Architektury ciągłości działania usługi Azure HDInsight
W tym artykule przedstawiono kilka przykładów architektur ciągłości działania, które można rozważyć w przypadku usługi Azure HDInsight. Tolerancja dla ograniczonej funkcjonalności podczas awarii to decyzja biznesowa, która różni się od jednej aplikacji do następnej. Niektóre aplikacje mogą być niedostępne lub częściowo dostępne z ograniczoną funkcjonalnością lub opóźnione przetwarzanie przez pewien czas. W przypadku innych aplikacji wszelkie ograniczone funkcje mogą być niedopuszczalne.
Uwaga
Architektury przedstawione w tym artykule nie są w żaden sposób wyczerpujące. Po określeniu celów związanych z oczekiwaną ciągłością działania, złożonością operacyjną i kosztem własności należy zaprojektować własne unikatowe architektury.
Apache Hive i interakcyjne zapytanie
Replikacja hive w wersji 2 jest zalecana w przypadku ciągłości działania w klastrach zapytań hive i interaktywnych usługi HDInsight. Trwałe sekcje autonomicznego klastra Hive, które należy replikować, to warstwa magazynu i magazyn metadanych Hive. Klastry Hive w scenariuszu z wieloma użytkownikami z pakietem Enterprise Security wymagają usług Microsoft Entra Domain Services i magazynu metadanych Ranger.
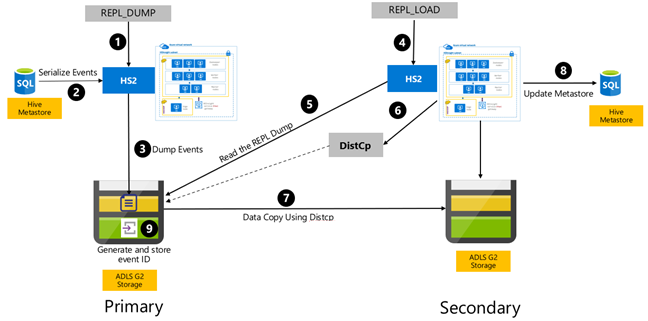
Replikacja oparta na zdarzeniach programu Hive jest konfigurowana między klastrami podstawowymi i pomocniczymi. Składa się to z dwóch odrębnych faz, uruchamiania i uruchamiania przyrostowego:
Bootstrapping replikuje cały magazyn Hive, w tym informacje magazynu metadanych Hive z podstawowego do pomocniczego.
Przebiegi przyrostowe są zautomatyzowane w klastrze podstawowym, a zdarzenia generowane podczas przebiegów przyrostowych są odtwarzane w klastrze pomocniczym. Klaster pomocniczy nadrabia zaległości zdarzeń wygenerowanych z klastra podstawowego, zapewniając, że klaster pomocniczy jest spójny ze zdarzeniami klastra podstawowego po uruchomieniu replikacji.
Klaster pomocniczy jest potrzebny tylko w czasie replikacji do uruchamiania kopii rozproszonej, DistCpale magazyny i magazyny metadanych muszą być trwałe. Możesz uruchomić skryptowy klaster pomocniczy na żądanie przed replikacją, uruchomić na nim skrypt replikacji, a następnie usunąć go po pomyślnej replikacji.
Klaster pomocniczy jest zwykle tylko do odczytu. Można wprowadzić pomocniczy klaster do odczytu i zapisu, ale zwiększa to dodatkową złożoność, która obejmuje replikowanie zmian z klastra pomocniczego do klastra podstawowego.
Cel punktu odzyskiwania i cel punktu odzyskiwania opartego na zdarzeniach Programu Hive
Cel punktu odzyskiwania: Utrata danych jest ograniczona do ostatniego pomyślnego zdarzenia replikacji przyrostowej z podstawowego do pomocniczego.
Cel czasu odzyskiwania: czas między awarią a wznowieniem transakcji nadrzędnych i podrzędnych z pomocniczym.
Architektury zapytań interakcyjnych i apache Hive
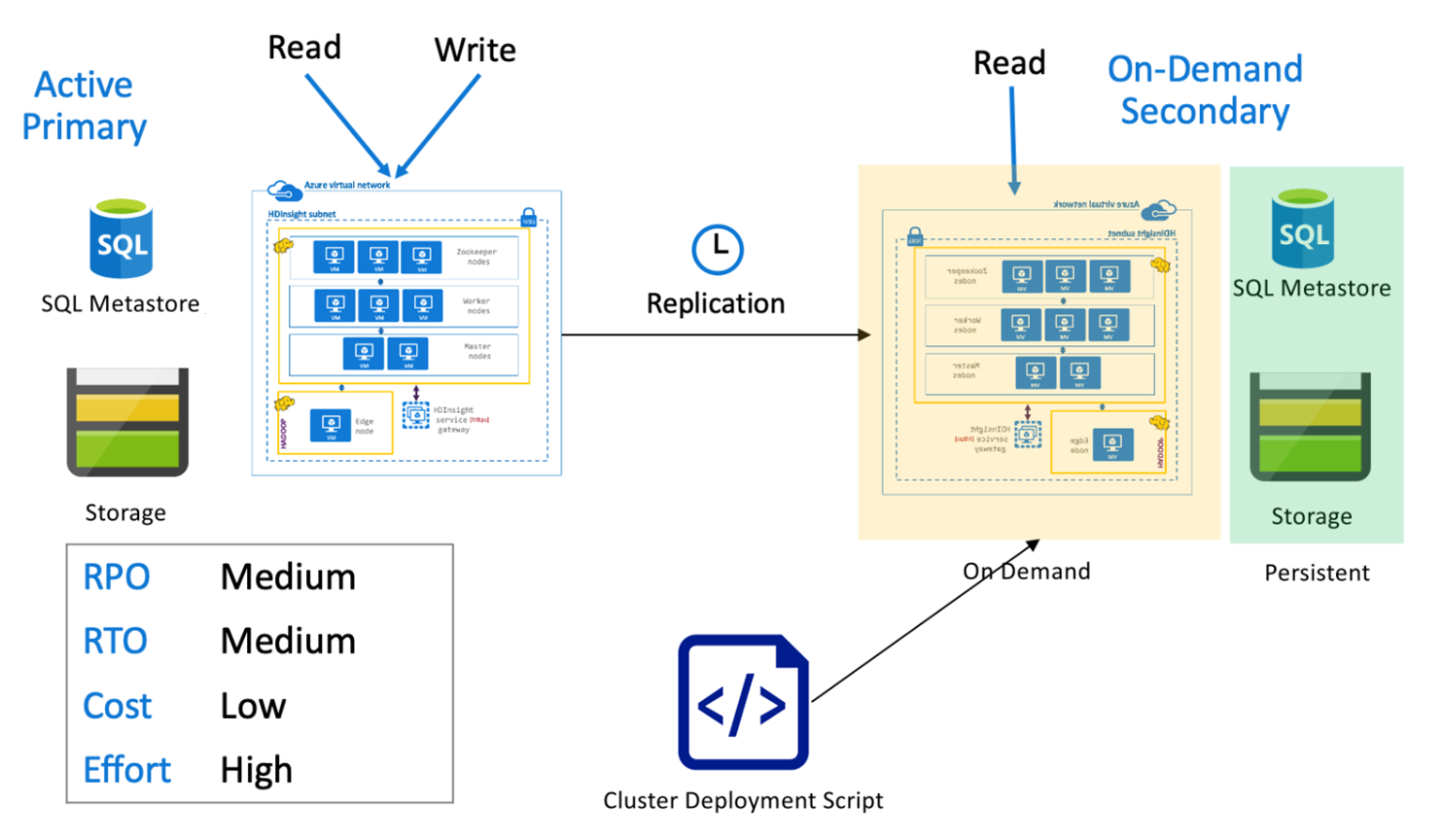
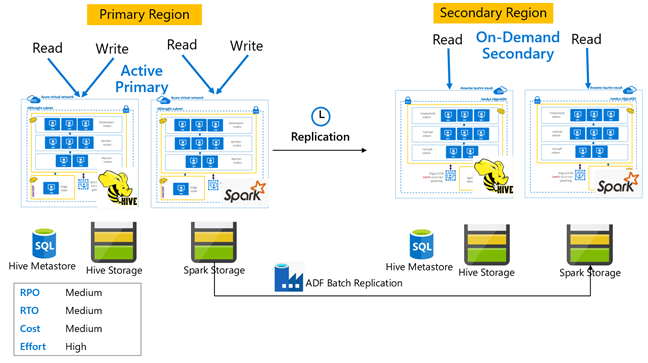
Hive aktywny podstawowy z pomocniczym serwerem na żądanie
W aktywnej podstawowej architekturze pomocniczej na żądanie aplikacje zapisują się w aktywnym regionie podstawowym, podczas gdy żaden klaster nie jest aprowizowany w regionie pomocniczym podczas normalnych operacji. Magazyn metadanych SQL i magazyn w regionie pomocniczym są trwałe, podczas gdy klaster usługi HDInsight jest skryptowy i wdrażany na żądanie tylko przed uruchomieniem zaplanowanej replikacji programu Hive.
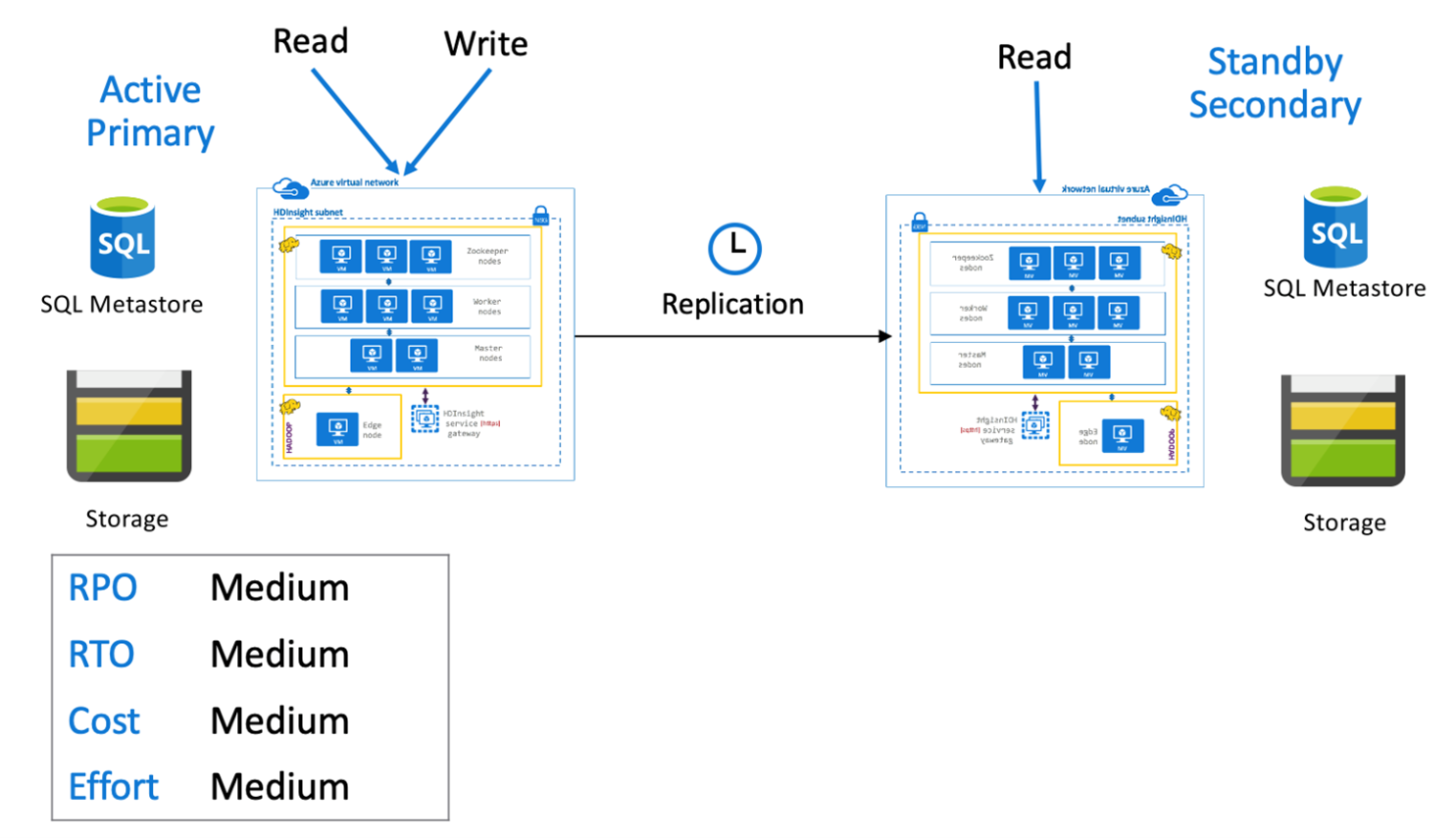
Aktywny podstawowy program Hive z pomocniczym trybem wstrzymania
W aktywnym podstawowym z pomocniczym rezerwowym aplikacjami zapisują się w aktywnym regionie podstawowym, podczas gdy rezerwowy klaster pomocniczy skalowany w dół w trybie tylko do odczytu jest uruchamiany podczas normalnych operacji. Podczas normalnych operacji można odciążyć operacje odczytu specyficzne dla regionu do pomocniczego.
Aby uzyskać więcej informacji na temat replikacji i przykładów kodu hive, zobacz Replikacja apache Hive w klastrach usługi Azure HDInsight
Apache Spark
Obciążenia platformy Spark mogą lub nie obejmują składnika Programu Hive. Aby umożliwić obciążeń Spark SQL odczytywanie i zapisywanie danych z programu Hive, klastry spark usługi HDInsight współużytkują niestandardowe magazyny metadanych Hive z klastrów zapytań Hive/Interactive w tym samym regionie. W takich scenariuszach replikacja obciążeń platformy Spark między regionami musi również towarzyszyć replikacji magazynów metadanych Hive i magazynu. Scenariusze trybu failover w tej sekcji dotyczą obu tych scenariuszy:
- Usługa Spark SQL w tabelach ACID przy użyciu konfiguracji łącznika magazynu Hive Warehouse (HWC) przy użyciu klastra interakcyjnego zapytań usługi HDInsight.
- Obciążenie Spark SQL w tabelach innych niż ACID przy użyciu klastra hadoop usługi HDInsight.
W przypadku scenariuszy, w których platforma Spark działa w trybie autonomicznym, wyselekcjonowane dane i przechowywane pliki Spark Jars (dla zadań usługi Livy) muszą być regularnie replikowane z regionu podstawowego do regionu pomocniczego przy użyciu usługi Azure Data Factory DistCP.
Zalecamy używanie systemów kontroli wersji do przechowywania notesów i bibliotek platformy Spark, w których można je łatwo wdrożyć w klastrach podstawowych lub pomocniczych. Upewnij się, że rozwiązania oparte na notesach i inne niż notesy są przygotowane do załadowania poprawnych instalacji danych w podstawowym lub pomocniczym obszarze roboczym.
Jeśli istnieją biblioteki specyficzne dla klienta, które wykraczają poza funkcje usługi HDInsight zapewniane natywnie, muszą być śledzone i okresowo ładowane do klastra pomocniczego rezerwowego.
Cel punktu odzyskiwania i cel czasu odzyskiwania replikacji platformy Apache Spark
Cel punktu odzyskiwania: Utrata danych jest ograniczona do ostatniej pomyślnej replikacji przyrostowej (Spark i Hive) z podstawowej do pomocniczej.
Cel czasu odzyskiwania: czas między awarią a wznowieniem transakcji nadrzędnych i podrzędnych z pomocniczym.
Architektury platformy Apache Spark
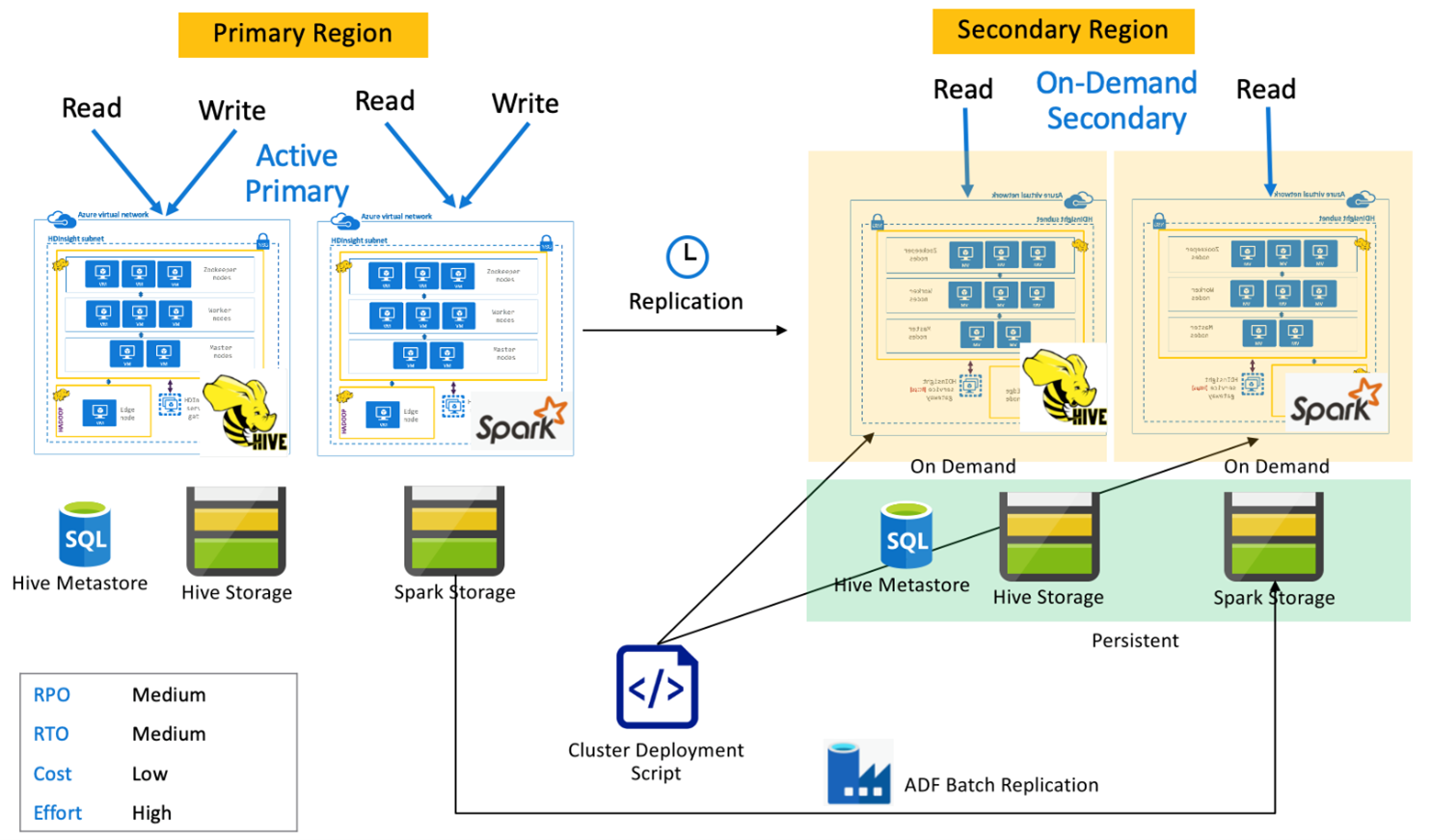
Platforma Spark aktywna podstawowa z pomocniczym użyciem na żądanie
Aplikacje odczytują i zapisują w klastrach Spark i Hive w regionie podstawowym, podczas gdy żadne klastry nie są aprowidowane w regionie pomocniczym podczas normalnych operacji. Magazyn metadanych SQL, magazyn Hive i usługa Spark Storage są trwałe w regionie pomocniczym. Klastry Spark i Hive są skryptami i wdrażane na żądanie. Replikacja hive służy do replikowania magazynów metadanych Hive Storage i Hive, podczas gdy usługa Azure Data Factory DistCP może służyć do kopiowania autonomicznego magazynu Spark. Klastry Hive muszą zostać wdrożone przed uruchomieniem każdej replikacji programu Hive z powodu obliczeń zależności DistCp .
Platforma Spark aktywna podstawowa z pomocniczym trybem wstrzymania
Aplikacje odczytują i zapisują w klastrach Spark i Hive w regionie podstawowym, podczas gdy klastry Hive i Spark skalowane w dół są uruchamiane w trybie tylko do odczytu w regionie pomocniczym podczas normalnych operacji. Podczas normalnych operacji można odciążyć operacje odczytu hive i Spark specyficzne dla regionu do pomocniczych.
Apache HBase
Replikacja HBase Export i HBase to typowe sposoby włączania ciągłości działania między klastrami HBase usługi HDInsight.
Eksport HBase to proces replikacji wsadowej, który używa narzędzia eksportu HBase do eksportowania tabel z podstawowego klastra HBase do jego bazowego magazynu usługi Azure Data Lake Storage Gen 2. generacji. Następnie można uzyskać dostęp do wyeksportowanych danych z pomocniczego klastra HBase i zaimportować je do tabel, które muszą wstępnie istnieć w pomocniczej bazie danych. Podczas gdy eksport HBase oferuje stopień szczegółowości na poziomie tabeli, w sytuacjach aktualizacji przyrostowych aparat automatyzacji steruje zakresem wierszy przyrostowych do uwzględnienia w każdym uruchomieniu. Aby uzyskać więcej informacji, zobacz HDInsight HBase Backup and Replication (Tworzenie kopii zapasowych i replikacja bazy danych HBase w usłudze HDInsight).
Replikacja HBase używa replikacji niemal w czasie rzeczywistym między klastrami HBase w pełni zautomatyzowany. Replikacja jest wykonywana na poziomie tabeli. Wszystkie tabele lub określone tabele mogą być przeznaczone do replikacji. Replikacja bazy danych HBase jest ostatecznie spójna, co oznacza, że ostatnie edycje tabeli w regionie podstawowym mogą nie być natychmiast dostępne dla wszystkich pomocniczych. Elementy pomocnicze mają gwarancję, że w końcu staną się zgodne z podstawowymi elementami. Replikację bazy danych HBase można skonfigurować między co najmniej dwoma klastrami HBase usługi HDInsight, jeśli:
- Podstawowa i pomocnicza znajdują się w tej samej sieci wirtualnej.
- Podstawowe i pomocnicze znajdują się w różnych równorzędnych sieciach wirtualnych w tym samym regionie.
- Podstawowe i pomocnicze znajdują się w różnych równorzędnych sieciach wirtualnych w różnych regionach.
Aby uzyskać więcej informacji, zobacz Konfigurowanie replikacji klastra Apache HBase w sieciach wirtualnych platformy Azure.
Istnieje kilka innych sposobów wykonywania kopii zapasowych klastrów HBase, takich jak kopiowanie folderu hbase, kopiowanie tabel i migawek.
Cel punktu odzyskiwania bazy danych HBase i cel czasu odzyskiwania
Eksportowanie bazy danych HBase
- Cel punktu odzyskiwania: Utrata danych jest ograniczona do ostatniego pomyślnego importowania przyrostowego partii przez pomocniczą z bazy podstawowej.
- Cel czasu odzyskiwania: czas między awarią operacji we/wy podstawowej i wznowienia operacji we/wy na pomocniczym.
Replikacja bazy danych HBase
- Cel punktu odzyskiwania: Utrata danych jest ograniczona do ostatniej przesyłki WalEdit otrzymanej w miejscu pomocniczym.
- Cel czasu odzyskiwania: czas między awarią operacji we/wy podstawowej i wznowienia operacji we/wy na pomocniczym.
Architektury bazy danych HBase
Replikację bazy danych HBase można skonfigurować w trzech trybach: Leader-Follower, Leader-Leader i Cykliczny.
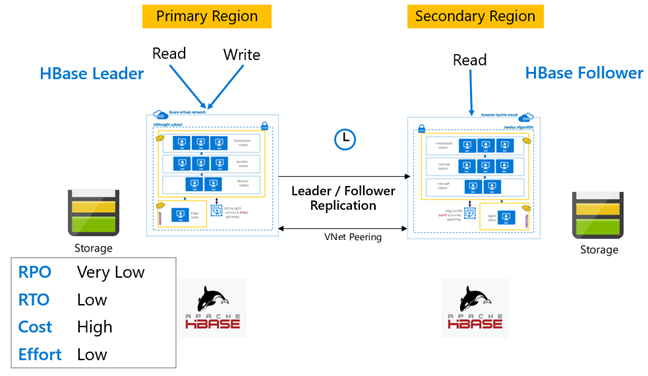
Replikacja bazy danych HBase: Lider — model obserwowany
W tej konfiguracji między regionami replikacja jest jednokierunkowa z regionu podstawowego do regionu pomocniczego. Dla replikacji jednokierunkowej można zidentyfikować wszystkie tabele lub określone tabele podstawowe. Podczas normalnych operacji klaster pomocniczy może służyć do obsługi żądań odczytu we własnym regionie.
Klaster pomocniczy działa jako normalny klaster HBase, który może hostować własne tabele i może obsługiwać odczyty i zapisy z aplikacji regionalnych. Jednak zapis w replikowanych tabelach lub tabelach natywnych dla pomocniczych nie jest replikowany z powrotem do bazy podstawowej.
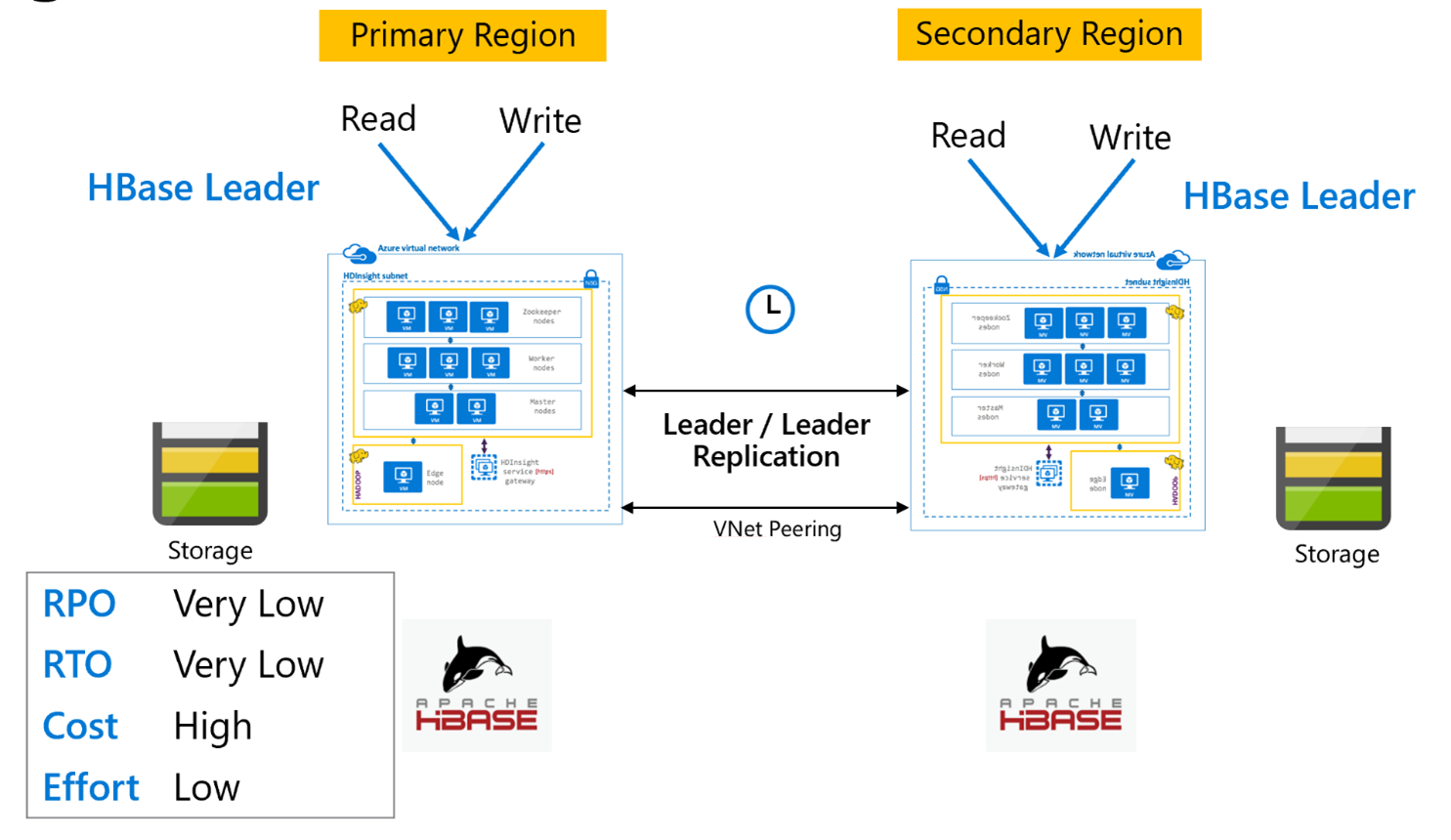
Replikacja bazy danych HBase: model lidera
Ta konfiguracja między regionami jest bardzo podobna do konfiguracji jednokierunkowej, z tą różnicą, że replikacja odbywa się dwukierunkowo między regionem podstawowym a regionem pomocniczym. Aplikacje mogą używać obu klastrów w trybach odczytu i zapisu, a aktualizacje są wymieniane asynchronicznie między nimi.
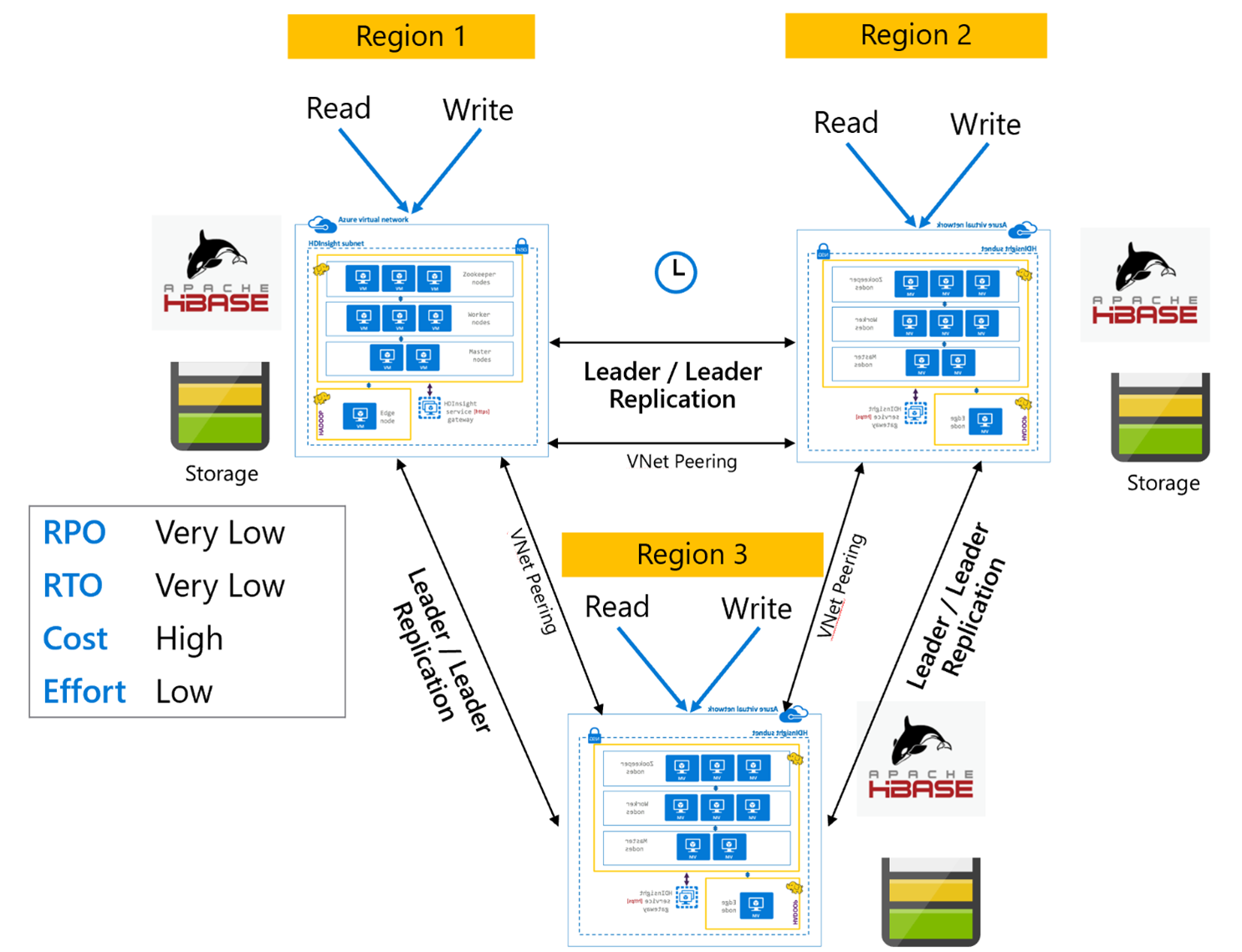
Replikacja bazy danych HBase: wiele regionów lub cyklicznych
Model replikacji wieloregionowej/cyklicznej jest rozszerzeniem replikacji bazy danych HBase i może służyć do tworzenia globalnie nadmiarowej architektury HBase z wieloma aplikacjami, które odczytują i zapisują w określonych regionach klastry HBase. Klastry można skonfigurować w różnych kombinacjach elementów Leader/Leader lub Leader/Follower w zależności od wymagań biznesowych.
Apache Kafka
Aby włączyć dostępność między regionami, usługa HDInsight 4.0 obsługuje narzędzie Kafka MirrorMaker, które może służyć do obsługi pomocniczej repliki podstawowego klastra kafka w innym regionie. MirrorMaker działa jako para wysokiego poziomu producent-konsument, korzysta z określonego tematu w klastrze podstawowym i tworzy do tematu o tej samej nazwie w pomocniczym. Replikacja między klastrami w celu odzyskiwania po awarii o wysokiej dostępności przy użyciu narzędzia MirrorMaker jest dostarczana z założeniem, że producenci i konsumenci muszą przejść w tryb failover do klastra repliki. Aby uzyskać więcej informacji, zobacz Używanie narzędzia MirrorMaker do replikowania tematów platformy Apache Kafka za pomocą platformy Kafka w usłudze HDInsight
W zależności od okresu istnienia tematu podczas uruchamiania replikacji replikacja tematu MirrorMaker może prowadzić do różnych przesunięć między tematami źródłowymi i replikami. Klastry platformy Kafka w usłudze HDInsight obsługują również replikację partycji tematu, która jest funkcją wysokiej dostępności na poziomie poszczególnych klastrów.
Architektury platformy Apache Kafka
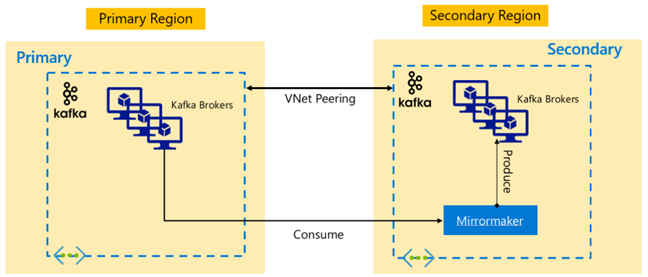
Replikacja platformy Kafka: Aktywna — pasywna
Konfiguracja aktywne-pasywna umożliwia asynchroniczne dublowanie jednokierunkowe z aktywnej na pasywną. Producenci i konsumenci muszą pamiętać o istnieniu klastra aktywnego i pasywnego i musi być gotowy do przejścia w tryb failover do pasywnego w przypadku awarii aktywnej. Poniżej przedstawiono pewne zalety i wady konfiguracji aktywne-pasywne.
Zalety:
- Opóźnienie sieci między klastrami nie wpływa na wydajność aktywnego klastra.
- Prostota replikacji jednokierunkowej.
Wady:
- Klaster pasywny może pozostać niedostatecznie wykorzystany.
- Projektowanie złożoności w zakresie uwzględniania świadomości trybu failover w producentach aplikacji i użytkownikach.
- Możliwa utrata danych podczas awarii aktywnego klastra.
- Spójność ostateczna między tematami między klastrami aktywnymi i pasywnymi.
- Powrót po awarii do podstawowego może prowadzić do niespójności komunikatów w tematach.
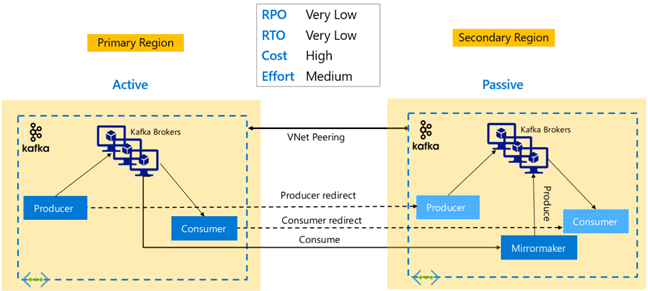
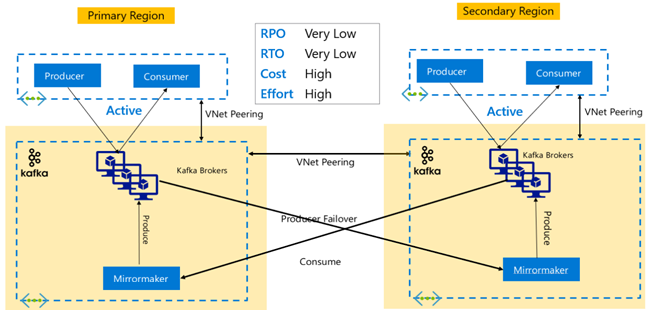
Replikacja platformy Kafka: Aktywna — aktywna
Konfiguracja Active-Active obejmuje dwie regionalnie oddzielone klastry platformy Kafka równorzędnej sieci wirtualnej w usłudze HDInsight z dwukierunkową replikacją asynchroniczną za pomocą narzędzia MirrorMaker. W tym projekcie komunikaty używane przez użytkowników w podstawowej wersji są również udostępniane konsumentom w pomocniczym i odwrotnie. Poniżej przedstawiono niektóre zalety i wady konfiguracji Active-Active.
Zalety:
- Ze względu na ich zduplikowany stan tryb failover i powroty po awarii są łatwiejsze do wykonania.
Wady:
- Konfigurowanie, zarządzanie i monitorowanie jest bardziej złożone niż aktywne-pasywne.
- Problem replikacji cyklicznej musi być rozwiązany.
- Replikacja dwukierunkowa prowadzi do wyższych kosztów ruchu wychodzącego danych regionalnych.
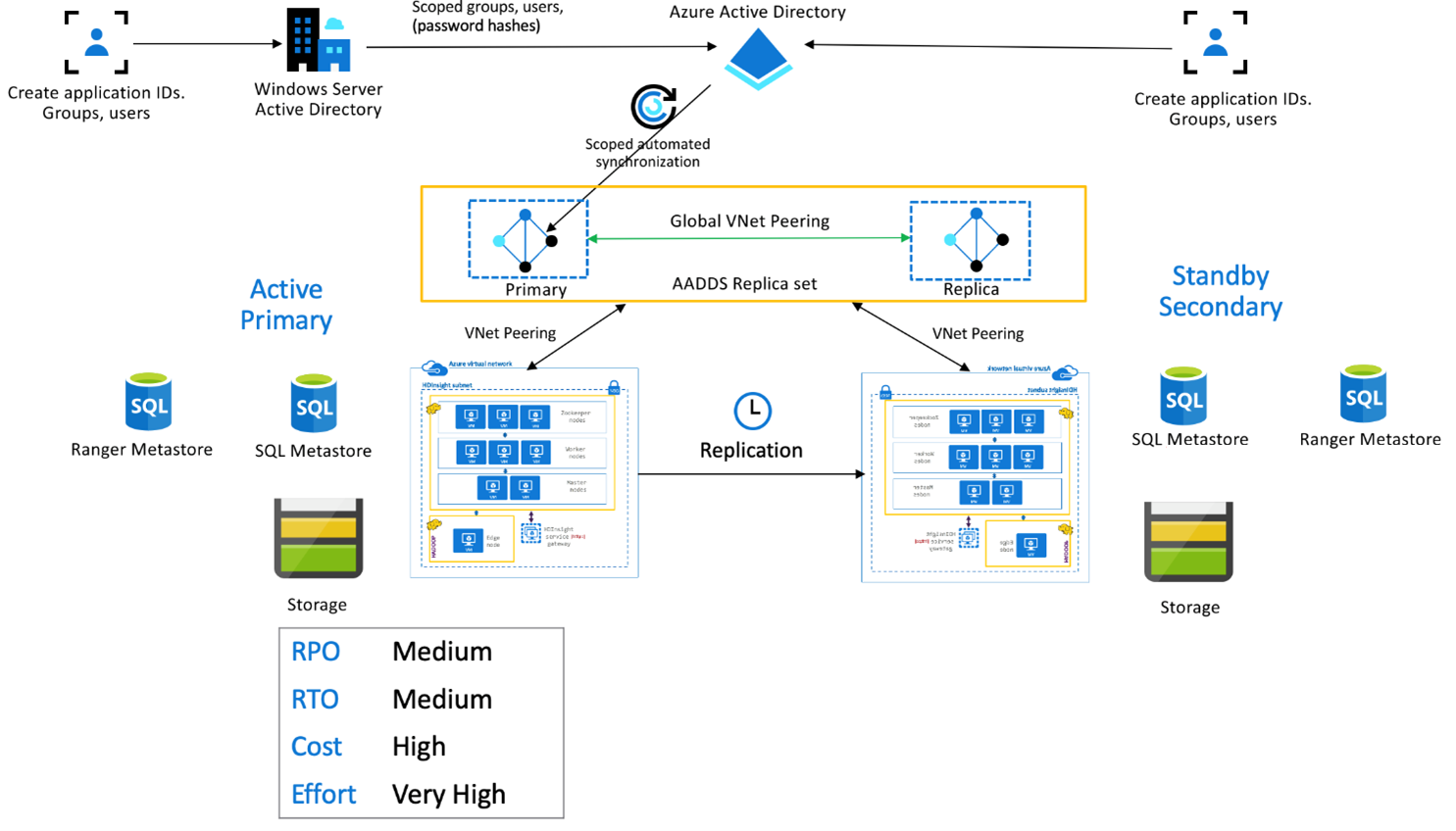
Pakiet HDInsight Enterprise Security
Ta konfiguracja służy do włączania funkcji wielu użytkowników zarówno w podstawowym, jak i pomocniczym, a także w zestawach replik usług Microsoft Entra Domain Services w celu zapewnienia, że użytkownicy mogą uwierzytelniać się w obu klastrach. Podczas normalnych operacji zasady platformy Ranger należy skonfigurować w pomocniczym systemie, aby zapewnić, że użytkownicy są ograniczeni do operacji odczytu. W poniższej architekturze wyjaśniono, jak może wyglądać konfiguracja podstawowa z włączoną obsługą rejestracji Hive Active — Rezerwowa konfiguracja pomocnicza.
Replikacja magazynu metadanych platformy Ranger:
Magazyn metadanych platformy Ranger służy do trwałego przechowywania i obsługi zasad platformy Ranger w celu kontrolowania autoryzacji danych. Zalecamy zachowanie niezależnych zasad platformy Ranger w podstawowej i pomocniczej i pomocniczej oraz obsługę pomocniczej jako repliki do odczytu.
Jeśli wymaganie polega na zachowaniu synchronizacji zasad platformy Ranger między podstawowym i pomocniczym, użyj narzędzia Ranger Import/Export , aby okresowo tworzyć kopie zapasowe i importować zasady ranger z podstawowej do pomocniczej.
Replikowanie zasad ranger między podstawowym i pomocniczym może spowodować, że pomocniczy stanie się włączony zapis, co może prowadzić do nieumyślnych zapisów w pomocniczym, co prowadzi do niespójności danych.
Następne kroki
Aby dowiedzieć się więcej o elementach omówionych w tym artykule, zobacz: