Automatyczne skalowanie klastrów usługi Azure HDInsight
Bezpłatna funkcja automatycznego skalowania usługi Azure HDInsight może automatycznie zwiększyć lub zmniejszyć liczbę węzłów roboczych w klastrze na podstawie metryk klastra i zasad skalowania przyjętych przez klientów. Funkcja autoskalowania działa przez skalowanie liczby węzłów w ramach wstępnie ustawionych limitów na podstawie metryk wydajności lub zdefiniowanego harmonogramu operacji skalowania w górę i w dół.
Jak to działa
Funkcja automatycznego skalowania używa dwóch typów warunków do wyzwalania zdarzeń skalowania: progi dla różnych metryk wydajności klastra (nazywanych skalowaniem opartym na obciążeniu) i wyzwalaczy opartych na czasie (nazywanych skalowaniem opartym na harmonogramie). Skalowanie oparte na obciążeniu zmienia liczbę węzłów w klastrze w określonym zakresie, aby zapewnić optymalne użycie procesora CPU i zminimalizować koszty działania. Skalowanie oparte na harmonogramie zmienia liczbę węzłów w klastrze na podstawie harmonogramu operacji skalowania w górę i skalowania w dół.
Poniższy film wideo zawiera omówienie wyzwań, które rozwiązuje autoskalowanie i jak może pomóc w kontrolowaniu kosztów za pomocą usługi HDInsight.
Wybieranie skalowania opartego na obciążeniu lub opartego na harmonogramie
Skalowanie oparte na harmonogramie może być używane:
- Gdy oczekuje się, że zadania będą uruchamiane zgodnie z ustalonymi harmonogramami i przewidywalnym czasem trwania lub gdy przewidujesz niskie użycie w określonych porach dnia. Na przykład środowiska testowe i deweloperskie w godzinach pracy po zakończeniu pracy.
Skalowanie oparte na obciążeniu może być używane:
- Gdy wzorce obciążenia zmieniają się znacząco i nieprzewidywalnie w ciągu dnia. Na przykład zamawianie przetwarzania danych z losowymi wahaniami wzorców obciążenia na podstawie różnych czynników.
Metryki klastra
Automatyczne skalowanie stale monitoruje klaster i zbiera następujące metryki:
| Metryczne | opis |
|---|---|
| Łączna liczba oczekujących procesorów | Całkowita liczba rdzeni wymaganych do rozpoczęcia wykonywania wszystkich oczekujących kontenerów. |
| Łączna liczba oczekujących pamięci | Łączna ilość pamięci (w MB) wymagana do rozpoczęcia wykonywania wszystkich oczekujących kontenerów. |
| Łączna liczba bezpłatnych procesorów CPU | Suma wszystkich nieużywanych rdzeni w aktywnych węzłach procesu roboczego. |
| Całkowita ilość wolnej pamięci | Suma nieużywanej pamięci (w MB) w aktywnych węzłach roboczych. |
| Używana pamięć na węzeł | Obciążenie węzła roboczego. Węzeł roboczy, na którym jest używana pamięć o pojemności 10 GB, jest uznawany za bardziej obciążony niż proces roboczy z 2 GB używanej pamięci. |
| Liczba wzorców aplikacji na węzeł | Liczba kontenerów wzorca aplikacji (AM) uruchomionych w węźle procesu roboczego. Węzeł roboczy hostujący dwa kontenery am jest uważany za ważniejszy niż węzeł roboczy hostujący zero kontenerów am. |
Powyższe metryki są sprawdzane co 60 sekund. Skalowanie automatyczne sprawia, że decyzje dotyczące skalowania w górę i w dół są podejmowane na podstawie tych metryk.
Aby uzyskać pełną listę metryk klastra, zobacz Obsługiwane metryki dla usługi Microsoft.HDInsight/clusters.
Warunki skalowania oparte na obciążeniu
Po wykryciu następujących warunków skalowanie automatyczne wystawia żądanie skalowania:
| Skalowanie w górę | Skalowanie w dół |
|---|---|
| Łączna liczba oczekujących procesorów CPU jest większa niż łączna liczba wolnych procesorów przez ponad 3–5 minut. | Łączna liczba oczekujących procesorów CPU jest mniejsza niż łączna ilość wolnego procesora PRZEZ ponad 3–5 minut. |
| Łączna liczba oczekujących pamięci jest większa niż całkowita ilość wolnej pamięci przez ponad 3–5 minut. | Łączna liczba oczekujących pamięci jest mniejsza niż łączna ilość wolnej pamięci przez ponad 3–5 minut. |
W przypadku skalowania w górę automatyczne skalowanie wysyła żądanie skalowania w górę, aby dodać wymaganą liczbę węzłów. Skalowanie w górę zależy od liczby nowych węzłów roboczych wymaganych do spełnienia bieżących wymagań dotyczących procesora CPU i pamięci.
W przypadku skalowania w dół automatyczne skalowanie wysyła żądanie usunięcia niektórych węzłów. Skalowanie w dół jest oparte na liczbie kontenerów wzorca aplikacji (AM) na węzeł. A bieżące wymagania dotyczące procesora CPU i pamięci. Usługa wykrywa również, które węzły są kandydatami do usunięcia na podstawie bieżącego wykonania zadania. Operacja skalowania w dół najpierw likwiduje węzły, a następnie usuwa je z klastra.
Zagadnienia dotyczące określania rozmiaru bazy danych Ambari na potrzeby skalowania automatycznego
Zaleca się, aby baza danych Ambari była prawidłowo rozmiarem, aby czerpać korzyści z autoskalowania. Klienci powinni używać odpowiedniej warstwy bazy danych i używać niestandardowej bazy danych Ambari dla klastrów o dużym rozmiarze. Przeczytaj zalecenia dotyczące ustalania rozmiaru bazy danych i węzła głównego.
Zgodność klastra
Ważne
Funkcja automatycznego skalowania usługi Azure HDInsight została ogólnie udostępniona 7 listopada 2019 r. dla klastrów Spark i Hadoop. Zawiera ona ulepszenia niedostępne w wersji zapoznawczej tej funkcji. Jeśli utworzono klaster Spark przed 7 listopada 2019 r. i chcesz użyć funkcji autoskalowania w klastrze, zalecaną ścieżką jest utworzenie nowego klastra i enable Autoscale w nowym klastrze.
Automatyczne skalowanie zapytań interakcyjnych (LLAP) zostało wydane w celu zapewnienia ogólnej dostępności dla usługi HDI 4.0 w dniu 27 sierpnia 2020 r. Autoskalowanie jest dostępne tylko w przypadku platform Spark, Hadoop i Interactive Query, klastrów
W poniższej tabeli opisano typy klastrów i wersje zgodne z funkcją autoskalowania.
| Wersja | platforma Spark | Hive | Zapytanie interakcyjne | HBase | Kafka |
|---|---|---|---|---|---|
| HDInsight 4.0 bez esp | Tak | Tak | Tak* | Nie | Nie. |
| Usługa HDInsight 4.0 ze stanem rejestracji | Tak | Tak | Tak* | Nie | Nie. |
| HDInsight 5.0 bez esp | Tak | Tak | Tak* | Nie | Nie. |
| Usługa HDInsight 5.0 ze stanem rejestracji | Tak | Tak | Tak* | Nie | Nie. |
* Klastry zapytań interakcyjnych można skonfigurować tylko do skalowania opartego na harmonogramie, a nie na podstawie obciążenia.
Rozpocznij
Tworzenie klastra z skalowaniem automatycznym opartym na obciążeniu
Aby włączyć funkcję autoskalowania ze skalowaniem opartym na obciążeniu, wykonaj następujące kroki w ramach normalnego procesu tworzenia klastra:
Na karcie Konfiguracja i cennik zaznacz
Enable autoscalepole wyboru.Wybierz pozycję Oparte na obciążeniu w obszarze Typ skalowania automatycznego.
Wprowadź zamierzone wartości dla następujących właściwości:
- Początkowa liczba węzłów węzła procesu roboczego.
- Minimalna liczba węzłów roboczych.
- Maksymalna liczba węzłów roboczych.
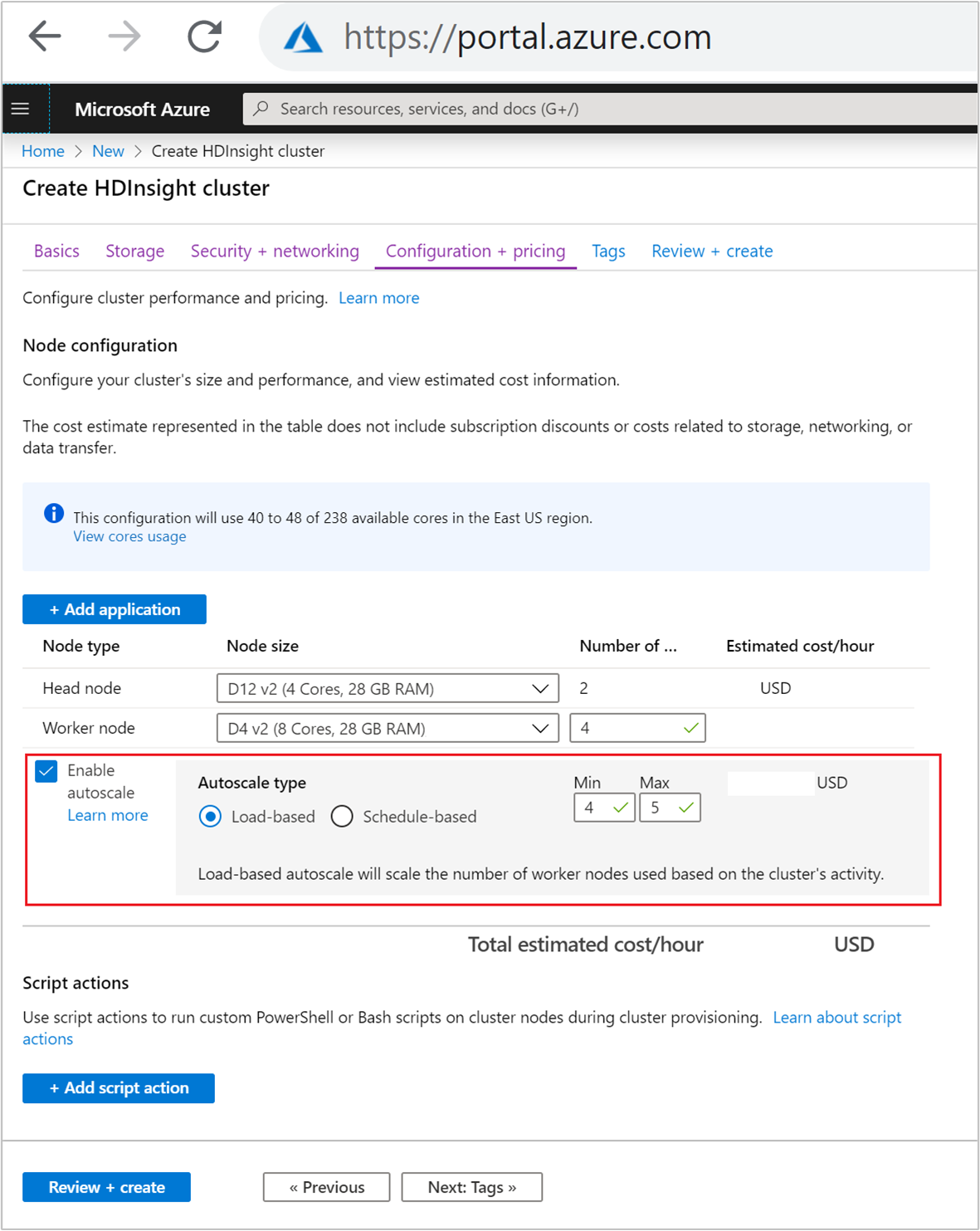
Początkowa liczba węzłów roboczych musi należeć do zakresu od minimalnej do maksymalnej. Ta wartość definiuje początkowy rozmiar klastra podczas jego tworzenia. Minimalna liczba węzłów roboczych powinna być ustawiona na co najmniej trzy. Skalowanie klastra do mniej niż trzech węzłów może spowodować zablokowanie klastra w trybie awaryjnym z powodu niewystarczającej replikacji plików. Aby uzyskać więcej informacji, zobacz Getting stuck in safe mode (Utknięcie w trybie awaryjnym).
Tworzenie klastra z skalowaniem automatycznym opartym na harmonogramie
Aby włączyć funkcję autoskalowania z skalowaniem opartym na harmonogramie, wykonaj następujące kroki w ramach normalnego procesu tworzenia klastra:
Na karcie Konfiguracja i cennik zaznacz
Enable autoscalepole wyboru.Wprowadź liczbę węzłów dla węzła Proces roboczy, który kontroluje limit skalowania w górę klastra.
Wybierz opcję Harmonogram oparty na typie autoskalowaniu.
Wybierz pozycję Konfiguruj , aby otworzyć okno konfiguracji autoskalowania.
Wybierz strefę czasową, a następnie kliknij pozycję + Dodaj warunek
Wybierz dni tygodnia, do których ma mieć zastosowanie nowy warunek.
Edytuj czas, w jakim warunek powinien obowiązywać, oraz liczbę węzłów, do których ma zostać przeskalowany klaster.
W razie potrzeby dodaj więcej warunków.
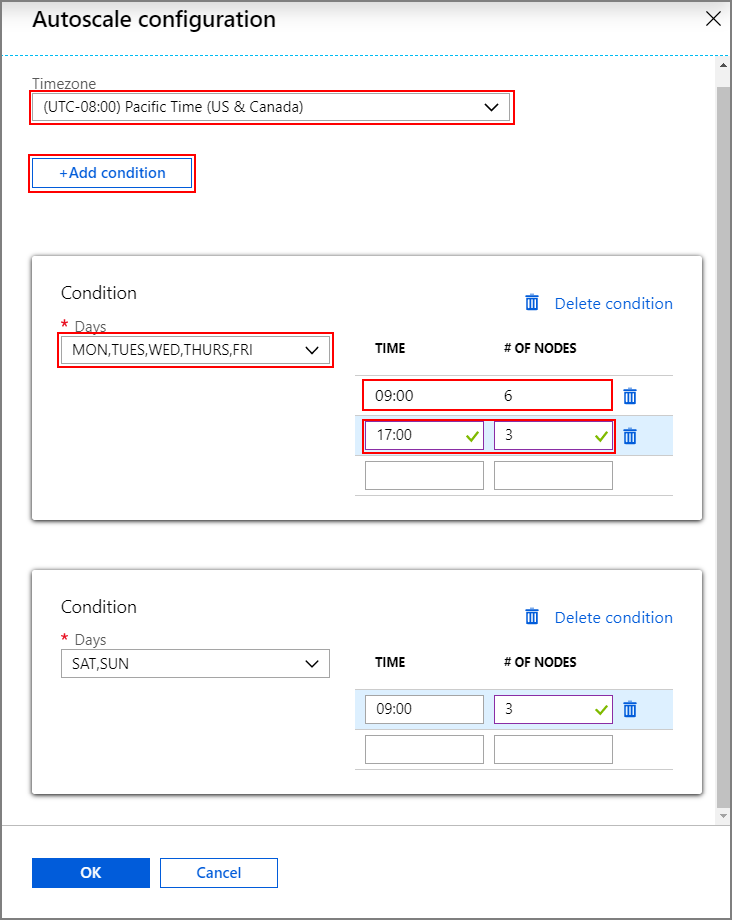
Liczba węzłów musi należeć do zakresu od 3 do maksymalnej liczby wprowadzonych węzłów roboczych przed dodaniem warunków.
Końcowe kroki tworzenia
Wybierz typ maszyny wirtualnej dla węzłów roboczych, wybierając maszynę wirtualną z listy rozwijanej w obszarze Rozmiar węzła. Po wybraniu typu maszyny wirtualnej dla każdego typu węzła można zobaczyć szacowany zakres kosztów dla całego klastra. Dostosuj typy maszyn wirtualnych, aby pasowały do budżetu.
Twoja subskrypcja ma limit przydziału pojemności dla każdego regionu. Całkowita liczba rdzeni węzłów głównych i maksymalna liczba węzłów roboczych nie może przekroczyć limitu przydziału pojemności. Jednak ten limit przydziału jest miękkim limitem; Zawsze możesz utworzyć bilet pomocy technicznej, aby łatwo go zwiększyć.
Uwaga
Jeśli przekroczysz łączny limit przydziału rdzeni, zostanie wyświetlony komunikat o błędzie informujący o tym, że "maksymalny węzeł przekroczył dostępne rdzenie w tym regionie, wybierz inny region lub skontaktuj się z pomocą techniczną, aby zwiększyć limit przydziału".
Aby uzyskać więcej informacji na temat tworzenia klastra usługi HDInsight przy użyciu witryny Azure Portal, zobacz Tworzenie klastrów opartych na systemie Linux w usłudze HDInsight przy użyciu witryny Azure Portal.
Tworzenie klastra przy użyciu szablonu usługi Resource Manager
Skalowanie automatyczne oparte na obciążeniu
Klaster usługi HDInsight można utworzyć przy użyciu skalowania automatycznego opartego na obciążeniu szablonu usługi Azure Resource Manager, dodając autoscale węzeł do computeProfileworkernode>sekcji z właściwościami minInstanceCount i maxInstanceCount jak pokazano we fragmencie kodu json. Aby uzyskać pełny szablon usługi Resource Manager, zobacz Szablon szybkiego startu: Wdrażanie klastra Spark z włączonym automatycznym skalowaniem opartym na obciążeniu.
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
Skalowanie automatyczne oparte na harmonogramie
Klaster usługi HDInsight można utworzyć przy użyciu skalowania automatycznego opartego na harmonogramie szablonu usługi Azure Resource Manager, dodając autoscale węzeł do computeProfile>workernode sekcji. Węzeł autoscale zawiera element recurrence , który zawiera timezone element i schedule opisujący, kiedy następuje zmiana. Aby uzyskać pełny szablon usługi Resource Manager, zobacz Deploy Spark Cluster with schedule-based Autoscale Enabled (Wdrażanie klastra Spark z włączonym automatycznym skalowaniem opartym na harmonogramie).
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
Włączanie i wyłączanie automatycznego skalowania dla uruchomionego klastra
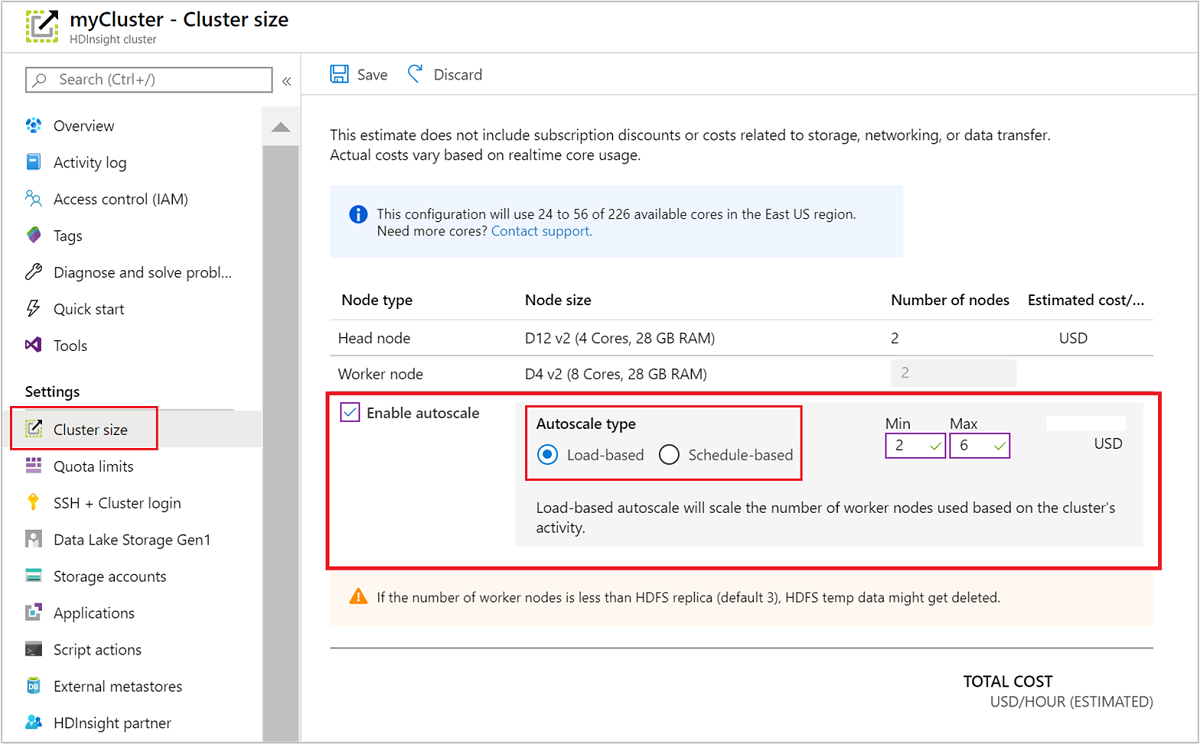
Korzystanie z witryny Azure Portal
Aby włączyć skalowanie automatyczne w uruchomionym klastrze, wybierz pozycję Rozmiar klastra w obszarze Ustawienia. Następnie wybierz pozycję Enable autoscale. Wybierz odpowiedni typ skalowania automatycznego i wprowadź opcje skalowania opartego na obciążeniu lub na podstawie harmonogramu. Na koniec wybierz pozycję Zapisz.
Korzystanie z interfejsu API REST
Aby włączyć lub wyłączyć automatyczne skalowanie w uruchomionym klastrze przy użyciu interfejsu API REST, wykonaj żądanie POST do punktu końcowego autoskalowania:
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
Użyj odpowiednich parametrów w ładunku żądania. Poniższy ładunek json może służyć do enable Autoscale. Użyj ładunku {autoscale: null} , aby wyłączyć autoskalowanie.
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
Zobacz poprzednią sekcję dotyczącą włączania automatycznego skalowania opartego na obciążeniu, aby uzyskać pełny opis wszystkich parametrów ładunku. Nie zaleca się wymuszania wymuszania automatycznego skalowania usługi w uruchomionym klastrze.
Monitorowanie działań skalowania automatycznego
Stan klastra
Stan klastra wymieniony w witrynie Azure Portal może pomóc w monitorze działań skalowania automatycznego.
Wszystkie komunikaty o stanie klastra, które mogą zostać wyświetlone, zostały wyjaśnione na poniższej liście.
| Stan klastra | opis |
|---|---|
| Uruchomiono | Klaster działa normalnie. Wszystkie poprzednie działania autoskalowania zostały ukończone pomyślnie. |
| Aktualizowanie | Konfiguracja automatycznego skalowania klastra jest aktualizowana. |
| Konfiguracja usługi HDInsight | Trwa skalowanie klastra w górę lub w dół. |
| Błąd aktualizacji | Usługa HDInsight napotkała problemy podczas aktualizacji konfiguracji autoskalowania. Klienci mogą ponowić próbę aktualizacji lub wyłączyć skalowanie automatyczne. |
| Błąd | Wystąpił problem z klastrem i nie można go używać. Usuń ten klaster i utwórz nowy. |
Aby wyświetlić bieżącą liczbę węzłów w klastrze, przejdź do wykresu Rozmiar klastra na stronie Przegląd klastra. Możesz też wybrać pozycję Rozmiar klastra w obszarze Ustawienia.
Historia operacji
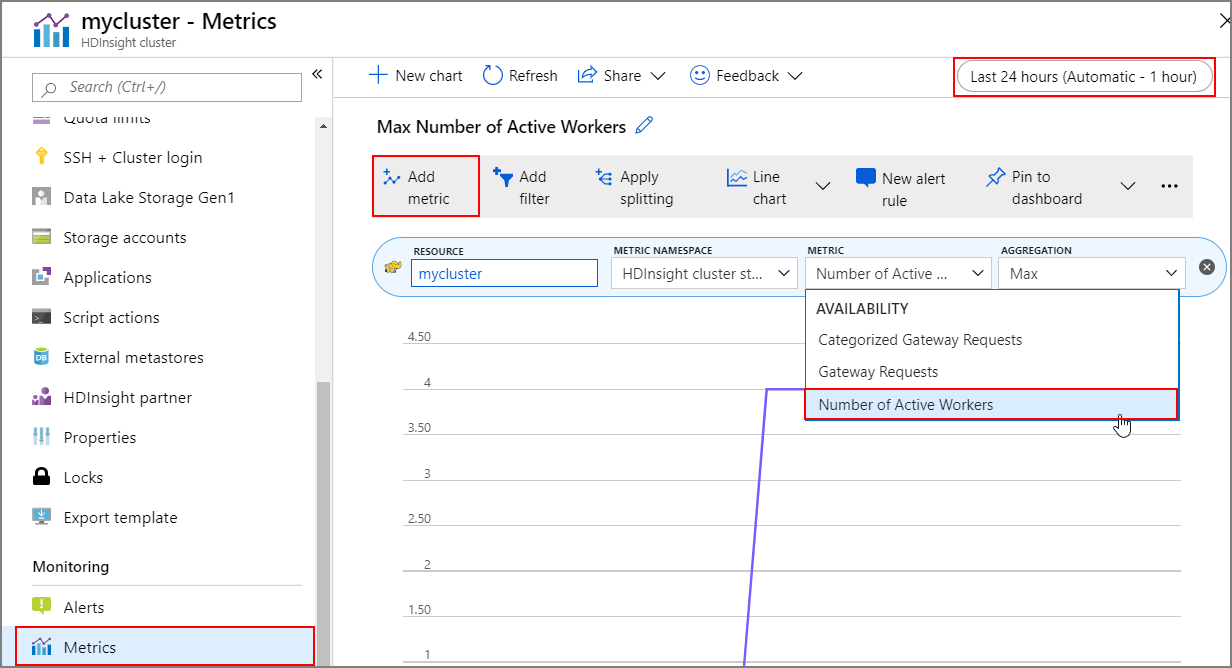
Możesz wyświetlić historię skalowania klastra w górę i w dół w ramach metryk klastra. Możesz również wyświetlić listę wszystkich akcji skalowania w ciągu ostatniego dnia, tygodnia lub innego okresu.
Wybierz pozycję Metryki w obszarze Monitorowanie. Następnie wybierz pozycję Dodaj metrykę i Liczbę aktywnych procesów roboczych z listy rozwijanej Metryka . Wybierz przycisk w prawym górnym rogu, aby zmienić zakres czasu.
Najlepsze rozwiązania
Rozważ opóźnienie operacji skalowania w górę i w dół
Ukończenie ogólnej operacji skalowania może potrwać od 10 do 20 minut. Podczas konfigurowania dostosowanego harmonogramu zaplanuj to opóźnienie. Jeśli na przykład rozmiar klastra będzie miał wartość 20 o godzinie 9:00, ustaw wyzwalacz harmonogramu na wcześniejszy czas, taki jak 8:30 lub wcześniej, aby operacja skalowania została ukończona o 9:00.
Przygotowanie do skalowania w dół
Podczas procesu skalowania klastra w dół skalowanie automatyczne likwiduje węzły w celu spełnienia rozmiaru docelowego. W przypadku skalowania automatycznego opartego na obciążeniu, jeśli zadania są uruchomione w tych węzłach, autoskalowanie czeka na ukończenie zadań dla klastrów Spark i Hadoop. Ponieważ każdy węzeł roboczy pełni również rolę w systemie plików HDFS, dane tymczasowe są przesuwane do pozostałych węzłów roboczych. Upewnij się, że na pozostałych węzłach jest wystarczająca ilość miejsca na hostowanie wszystkich danych tymczasowych.
Uwaga
W przypadku skalowania automatycznego skalowania w dół opartego na harmonogramie nie jest obsługiwane bezproblemowe likwidowania. Może to spowodować błędy zadań podczas operacji skalowania w dół i zaleca się zaplanowanie harmonogramów na podstawie przewidywanych wzorców harmonogramu zadań, aby uwzględnić wystarczający czas na zakończenie trwających zadań. Możesz ustawić harmonogramy patrząc na historyczny rozkład czasów ukończenia, aby uniknąć niepowodzeń zadań.
Konfigurowanie automatycznego skalowania opartego na harmonogramie na podstawie wzorca użycia
Należy zrozumieć wzorzec użycia klastra podczas konfigurowania automatycznego skalowania opartego na harmonogramie. Pulpit nawigacyjny narzędzia Grafana może ułatwić zrozumienie obciążenia zapytań i miejsc wykonywania. Dostępne miejsca funkcji wykonawczej i całkowite miejsca funkcji wykonawczej można pobrać z pulpitu nawigacyjnego.
Oto sposób oszacowania liczby potrzebnych węzłów roboczych. Zalecamy przekazanie kolejnego buforu o 10% do obsługi odmiany obciążenia.
Liczba używanych miejsc funkcji wykonawczej = Łączna liczba miejsc funkcji wykonawczej — łączna liczba dostępnych miejsc funkcji wykonawczej.
Wymagana liczba węzłów procesu roboczego = liczba gniazd funkcji wykonawczej, które rzeczywiście są używane / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size).
*hive.llap.daemon.num.executors można skonfigurować, a wartość domyślna to 4.
*hive.llap.daemon.task.scheduler.wait.queue.size można skonfigurować, a wartość domyślna to 10.
Niestandardowe akcje skryptu
Niestandardowe akcje skryptu są najczęściej używane do dostosowywania węzłów (HeadNode / WorkerNodes), które umożliwiają naszym klientom konfigurowanie niektórych bibliotek i narzędzi, które są używane przez nich. Jednym z typowych przypadków użycia jest to, że zadania uruchamiane w klastrze mogą mieć pewne zależności od biblioteki innej firmy, która jest własnością klienta, i powinna być dostępna w węzłach, aby zadanie zakończyło się pomyślnie. W przypadku skalowania automatycznego obecnie obsługujemy niestandardowe akcje skryptu, które są utrwalane, dlatego za każdym razem, gdy nowe węzły zostaną dodane do klastra w ramach operacji skalowania w górę, te utrwalone akcje skryptu zostaną wykonane i opublikują, że kontenery lub zadania zostaną przydzielone do nich. Mimo że akcje skryptu niestandardowego ułatwiają uruchamianie nowych węzłów, zaleca się, aby zachować minimalny rozmiar, ponieważ spowoduje to zwiększenie ogólnego opóźnienia skalowania w górę i może mieć wpływ na zaplanowane zadania.
Należy pamiętać o minimalnym rozmiarze klastra
Nie skaluj klastra w dół do mniej niż trzech węzłów. Skalowanie klastra do mniej niż trzech węzłów może spowodować zablokowanie klastra w trybie awaryjnym z powodu niewystarczającej replikacji plików. Aby uzyskać więcej informacji, zobacz utknięcie w trybie awaryjnym.
Microsoft Entra Domain Services i operacje skalowania
Jeśli używasz klastra usługi HDInsight z pakietem Enterprise Security Package (ESP), który jest przyłączony do domeny zarządzanej usług Microsoft Entra Domain Services, zalecamy ograniczenie obciążenia usług Microsoft Entra Domain Services. W przypadku złożonych struktur katalogów w zakresie synchronizacji zalecamy unikanie wpływu na operacje skalowania.
Ustaw konfigurację programu Hive Maksymalna łączna liczba współbieżnych zapytań dla scenariusza szczytowego użycia
Zdarzenia skalowania automatycznego nie zmieniają konfiguracji programu Hive Maksymalna łączna liczba współbieżnych zapytań w systemie Ambari. Oznacza to, że usługa interaktywna programu Hive Server 2 może obsługiwać tylko daną liczbę współbieżnych zapytań w dowolnym momencie, nawet jeśli liczba demonów interakcyjnych jest skalowana w górę i w dół na podstawie obciążenia i harmonogramu. Ogólną rekomendacją jest ustawienie tej konfiguracji dla scenariusza szczytowego użycia, aby uniknąć ręcznej interwencji.
Jednak może wystąpić błąd ponownego uruchomienia programu Hive Server 2, jeśli istnieje tylko kilka węzłów roboczych, a wartość maksymalnej liczby współbieżnych zapytań jest skonfigurowana zbyt wysoko. Co najmniej wymagana jest minimalna liczba węzłów roboczych, które mogą pomieścić daną liczbę Tez Ams (równą konfiguracji Maksymalna łączna liczba współbieżnych zapytań).
Ograniczenia
Liczba demonów zapytań interakcyjnych
Jeśli klastry zapytań interakcyjnych z włączoną funkcją automatycznego skalowania, zdarzenie automatycznego skalowania w górę/w dół również skaluje liczbę demonów interakcyjnych zapytań do liczby aktywnych węzłów roboczych. Zmiana liczby demonów nie jest utrwalana w num_llap_nodes konfiguracji w systemie Ambari. Jeśli usługi Hive są ponownie uruchamiane ręcznie, liczba demonów interakcyjnych zapytań jest resetowana zgodnie z konfiguracją w systemie Ambari.
Jeśli usługa Interactive Query jest ręcznie uruchamiana ponownie, musisz ręcznie zmienić num_llap_node konfigurację (liczbę węzłów wymaganych do uruchomienia demona interakcyjnego zapytania Hive) w obszarze Zaawansowane hive-interactive-env , aby dopasować bieżącą liczbę aktywnych węzłów roboczych. Interaktywny klaster zapytań obsługuje tylko automatyczne skalowanie oparte na harmonogramie.
Następne kroki
Zapoznaj się z wytycznymi dotyczącymi ręcznego skalowania klastrów w wytycznych dotyczących skalowania.