Uruchamianie zapytań Apache Hive przy użyciu wtyczki Data Lake Tools for Visual Studio
Dowiedz się, jak używać narzędzi Data Lake dla programu Visual Studio do wykonywania zapytań w usłudze Apache Hive. Narzędzia usługi Data Lake umożliwiają łatwe tworzenie, przesyłanie i monitorowanie zapytań Hive w usłudze Apache Hadoop w usłudze Azure HDInsight.
Wymagania wstępne
Klaster Apache Hadoop w usłudze HDInsight. Aby uzyskać informacje na temat tworzenia tego elementu, zobacz Create Apache Hadoop cluster in Azure HDInsight using Resource Manager template (Tworzenie klastra Apache Hadoop w usłudze Azure HDInsight przy użyciu szablonu usługi Resource Manager).
Visual Studio. Kroki opisane w tym artykule korzystają z programu Visual Studio 2019.
Narzędzia usługi HDInsight dla programu Visual Studio lub narzędzi Azure Data Lake dla programu Visual Studio. Aby uzyskać informacje na temat instalowania i konfigurowania narzędzi, zobacz Instalowanie narzędzi Data Lake Tools for Visual Studio.
Uruchamianie zapytań apache Hive przy użyciu programu Visual Studio
Masz dwie opcje umożliwiające utworzenie i uruchomienie zapytań Hive:
- Tworzenie zapytań ad hoc.
- Tworzenie aplikacji Hive.
Tworzenie zapytania ad hoc programu Hive
Zapytania ad hoc można wykonywać w trybie batch lub interaktywnym.
Uruchom program Visual Studio i wybierz pozycję Kontynuuj bez kodu.
W Eksploratorze serwera kliknij prawym przyciskiem myszy pozycję Azure, wybierz pozycję Połącz z subskrypcją platformy Microsoft Azure... i ukończ proces logowania.
Rozwiń węzeł HDInsight, kliknij prawym przyciskiem myszy klaster, w którym chcesz uruchomić zapytanie, a następnie wybierz polecenie Napisz zapytanie Hive.
Wprowadź następujące zapytanie hive:
SELECT * FROM hivesampletable;Wybierz polecenie Wykonaj. Tryb wykonywania jest domyślnie ustawiona na Interakcyjne.
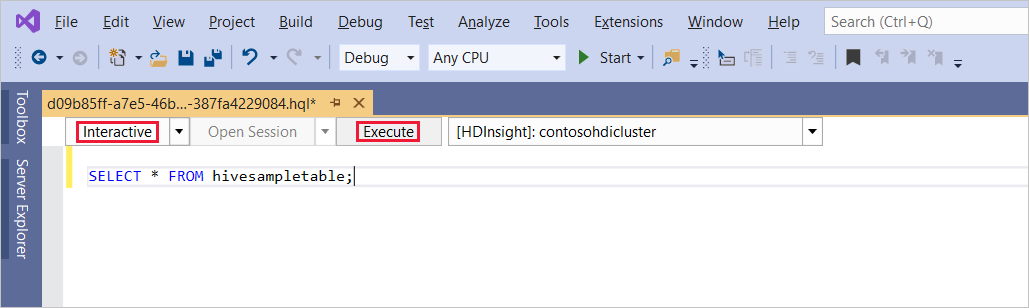
Aby uruchomić to samo zapytanie w trybie usługi Batch , przełącz listę rozwijaną z interakcyjnej na batch. Przycisk wykonywania zmienia się z Wykonaj na Prześlij.

Edytor Hive obsługuje funkcję IntelliSense. Narzędzia Data Lake Tools for Visual Studio obsługują ładowanie zdalnych metadanych podczas edycji skryptu Hive. Jeśli na przykład wpiszesz ,
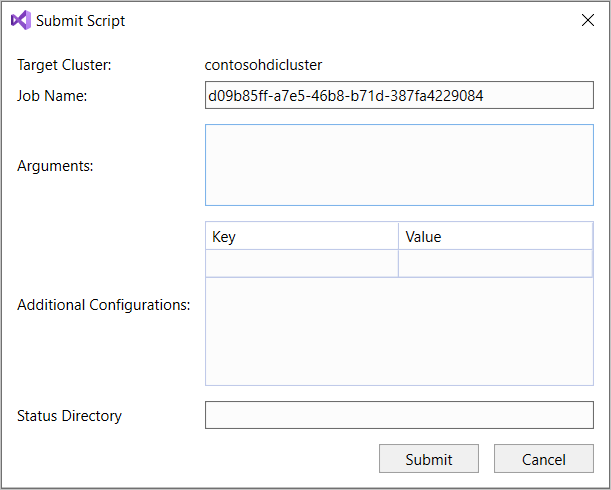
SELECT * FROMfunkcja IntelliSense wyświetli listę wszystkich sugerowanych nazw tabel. Po określeniu nazwy tabeli funkcja IntelliSense wyświetla nazwy kolumn. Narzędzia obsługują większość instrukcji DML programu Hive, podzapytań i wbudowanych sterowników UDF. Funkcja IntelliSense zasugeruje tylko metadane klastra zaznaczonego na pasku narzędzi usługi HDInsight.Na pasku narzędzi zapytania (obszarze poniżej karty zapytania i nad tekstem zapytania) wybierz pozycję Prześlij lub wybierz strzałkę ściągnięcia obok pozycji Prześlij i wybierz pozycję Zaawansowane z listy rozwijanej. Jeśli wybierzesz tę drugą opcję,
W przypadku wybrania opcji przesyłania zaawansowanego skonfiguruj nazwę zadania, argumenty, dodatkowe konfiguracje i katalog stanu w oknie dialogowym Przesyłanie skryptu. Następnie wybierz pozycję Prześlij.
Tworzenie aplikacji Hive
Aby uruchomić zapytanie hive, tworząc aplikację Hive, wykonaj następujące kroki:
Otwórz program Visual Studio.
W oknie Start wybierz pozycję Utwórz nowy projekt.
W oknie Tworzenie nowego projektu w polu Wyszukaj szablony wprowadź Hive. Następnie wybierz pozycję Aplikacja Hive i wybierz pozycję Dalej.
W oknie Konfigurowanie nowego projektu wprowadź nazwę projektu, wybierz lub utwórz lokalizację dla nowego projektu, a następnie wybierz pozycję Utwórz.
Otwórz plik Script.hql utworzony za pomocą tego projektu i wklej następujące instrukcje HiveQL:
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4j Logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;Te instrukcje wykonują następujące czynności:
DROP TABLE: Usuwa tabelę, jeśli istnieje.CREATE EXTERNAL TABLE: Tworzy nową tabelę "zewnętrzną" w programie Hive. Tabele zewnętrzne przechowują tylko definicję tabeli w programie Hive. (Dane pozostają w oryginalnej lokalizacji).Uwaga
Tabele zewnętrzne powinny być używane w przypadku oczekiwania, że bazowe dane zostaną zaktualizowane przez źródło zewnętrzne, takie jak zadanie MapReduce lub usługa platformy Azure.
Usunięcie tabeli zewnętrznej nie powoduje usunięcia danych, tylko definicji tabeli.
ROW FORMAT: informuje hive o sposobie formatowania danych. W takim przypadku pola w każdym dzienniku są oddzielone spacją.STORED AS TEXTFILE LOCATION: informuje hive, że dane są przechowywane w katalogu przykładowym/danych i że są przechowywane jako tekst.SELECT: wybiera liczbę wszystkich wierszy, w których kolumnat4zawiera wartość[ERROR]. Ta instrukcja zwraca wartość3, ponieważ trzy wiersze zawierają tę wartość.INPUT__FILE__NAME LIKE '%.log': informuje hive, aby zwracał tylko dane z plików kończących się na .log. Ta klauzula ogranicza wyszukiwanie do pliku sample.log zawierającego dane.
Na pasku narzędzi pliku zapytania (który ma podobny wygląd do paska narzędzi zapytania ad hoc) wybierz klaster usługi HDInsight, którego chcesz użyć dla tego zapytania. Następnie zmień wartość Interactive na Batch (w razie potrzeby) i wybierz pozycję Prześlij , aby uruchomić instrukcje jako zadanie hive.
Zostanie wyświetlone podsumowanie zadania programu Hive i zostaną wyświetlone informacje o uruchomionym zadaniu. Użyj linku Odśwież , aby odświeżyć informacje o zadaniu, dopóki stan zadania nie zmieni się na Ukończono.
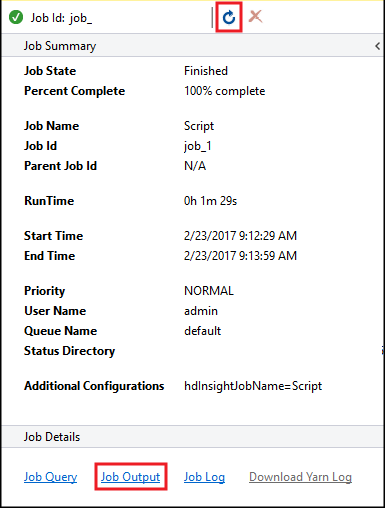
Wybierz pozycję Dane wyjściowe zadania, aby wyświetlić dane wyjściowe tego zadania. Wyświetla
[ERROR] 3wartość , która jest wartością zwracaną przez to zapytanie.
Dodatkowy przykład
Poniższy przykład opiera się na log4jLogs tabeli utworzonej w poprzedniej procedurze Create a Hive application (Tworzenie aplikacji Hive).
W Eksploratorze serwera kliknij prawym przyciskiem myszy klaster i wybierz polecenie Napisz zapytanie Hive.
Wprowadź następujące zapytanie hive:
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';Te instrukcje wykonują następujące czynności:
CREATE TABLE IF NOT EXISTS: Tworzy tabelę, jeśli jeszcze nie istnieje. Ponieważ słowoEXTERNALkluczowe nie jest używane, ta instrukcja tworzy tabelę wewnętrzną. Tabele wewnętrzne są przechowywane w magazynie danych programu Hive i są zarządzane przez program Hive.Uwaga
W przeciwieństwie do
EXTERNALtabel usunięcie tabeli wewnętrznej powoduje również usunięcie danych bazowych.STORED AS ORC: przechowuje dane w zoptymalizowanym formacie kolumnowym wierszy (ORC). ORC to wysoce zoptymalizowany i wydajny format do przechowywania danych hive.INSERT OVERWRITE ... SELECT: Wybiera wiersze z tabeli zawierającejlog4jLogs[ERROR]element , a następnie wstawia dane doerrorLogstabeli.
W razie potrzeby zmień wartość Interactive na Batch , a następnie wybierz pozycję Prześlij.
Aby sprawdzić, czy zadanie zostało utworzone w tabeli, przejdź do Eksploratora serwera i rozwiń węzeł Azure>HDInsight. Rozwiń klaster usługi HDInsight, a następnie rozwiń węzeł Domyślne bazy danych>Hive. Zostanie wyświetlona tabela errorLogs i tabela Log4jLogs.
Następne kroki
Jak widać, narzędzia usługi HDInsight dla programu Visual Studio umożliwiają łatwą pracę z zapytaniami programu Hive w usłudze HDInsight.
Aby uzyskać ogólne informacje na temat technologii Hive w usłudze HDInsight, zobacz Co to jest apache Hive i HiveQL w usłudze Azure HDInsight?
Aby uzyskać informacje na temat innych sposobów pracy z usługą Hadoop w usłudze HDInsight, zobacz Use MapReduce in Apache Hadoop on HDInsight (Korzystanie z usługi MapReduce w usłudze Apache Hadoop w usłudze HDInsight)
Aby uzyskać więcej informacji na temat narzędzi usługi HDInsight dla programu Visual Studio, zobacz Używanie narzędzi Data Lake Tools for Visual Studio do nawiązywania połączenia z usługą Azure HDInsight i uruchamiania zapytań apache Hive