Używanie języka C# z przesyłaniem strumieniowym MapReduce na platformie Apache Hadoop w usłudze HDInsight
Dowiedz się, jak za pomocą języka C# utworzyć rozwiązanie MapReduce w usłudze HDInsight.
Przesyłanie strumieniowe apache Hadoop umożliwia uruchamianie zadań MapReduce przy użyciu skryptu lub pliku wykonywalnego. W tym miejscu platforma .NET służy do implementowania mapatora i reduktora dla rozwiązania liczby wyrazów.
Platforma .NET w usłudze HDInsight
Klastry usługi HDInsight używają platformy Mono (https://mono-project.com) do uruchamiania aplikacji platformy .NET. Mono w wersji 4.2.1 jest dołączony do usługi HDInsight w wersji 3.6. Aby uzyskać więcej informacji na temat wersji platformy Mono dołączonej do usługi HDInsight, zobacz Apache Hadoop components available with HDInsight versions (Składniki platformy Apache Hadoop dostępne w wersjach usługi HDInsight).
Aby uzyskać więcej informacji na temat zgodności mono z wersjami programu .NET Framework, zobacz Zgodność mono.
Jak działa przesyłanie strumieniowe w usłudze Hadoop
Podstawowy proces używany do przesyłania strumieniowego w tym dokumencie jest następujący:
- Usługa Hadoop przekazuje dane do mapowania (mapper.exe w tym przykładzie) w narzędziu STDIN.
- Maper przetwarza dane i emituje pary klucz/wartość rozdzielane tabulatorami do wartości STDOUT.
- Dane wyjściowe są odczytywane przez usługę Hadoop, a następnie przekazywane do reduktora (reducer.exe w tym przykładzie) w narzędziu STDIN.
- Reduktor odczytuje pary klucz/wartość rozdzielane tabulatorami, przetwarza dane, a następnie emituje wynik jako pary klucz/wartość rozdzielane tabulatorami w stDOUT.
- Dane wyjściowe są odczytywane przez usługę Hadoop i zapisywane w katalogu wyjściowym.
Aby uzyskać więcej informacji na temat przesyłania strumieniowego, zobacz Przesyłanie strumieniowe w usłudze Hadoop.
Wymagania wstępne
Visual Studio.
Znajomość pisania i kompilowania kodu w języku C#, który jest przeznaczony dla platformy .NET Framework 4.5.
Sposób przekazywania plików .exe do klastra. Kroki opisane w tym dokumencie używają narzędzi Data Lake Tools for Visual Studio do przekazywania plików do magazynu podstawowego dla klastra.
Klaster Apache Hadoop w usłudze HDInsight. Zobacz Wprowadzenie do usługi HDInsight w systemie Linux.
Schemat identyfikatora URI dla magazynu podstawowego klastrów. Ten schemat dotyczyłby
wasb://usługi Azure Storage,abfs://usługi Azure Data Lake Storage Gen2 lubadl://usługi Azure Data Lake Storage Gen1. Jeśli bezpieczny transfer jest włączony dla usługi Azure Storage lub Data Lake Storage Gen2, identyfikator URI towasbs://lubabfss://, odpowiednio.
Tworzenie mapowania
W programie Visual Studio utwórz nową aplikację konsolową .NET Framework o nazwie maper. Użyj następującego kodu dla aplikacji:
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
Po utworzeniu aplikacji skompiluj /bin/Debug/mapper.exe ją, aby utworzyć plik w katalogu projektu.
Tworzenie reduktora
W programie Visual Studio utwórz nową aplikację konsolową .NET Framework o nazwie reducer. Użyj następującego kodu dla aplikacji:
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
Po utworzeniu aplikacji skompiluj /bin/Debug/reducer.exe ją, aby utworzyć plik w katalogu projektu.
Przekazywanie do magazynu
Następnie należy przekazać aplikacje mapatora i reduktora do magazynu usługi HDInsight.
W programie Visual Studio wybierz pozycję Wyświetl>Eksploratora serwera.
Kliknij prawym przyciskiem myszy pozycję Azure, wybierz pozycję Połącz z subskrypcją platformy Microsoft Azure..., a następnie zakończ proces logowania.
Rozwiń klaster usługi HDInsight, w którym chcesz wdrożyć tę aplikację. Zostanie wyświetlony wpis z tekstem (domyślne konto magazynu).
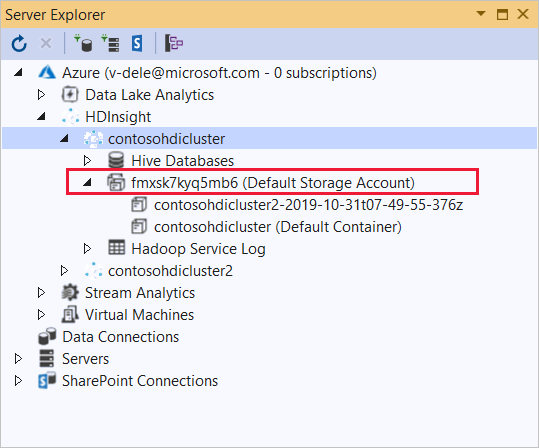
Jeśli można rozwinąć wpis (domyślne konto magazynu), używasz konta usługi Azure Storage jako domyślnego magazynu dla klastra. Aby wyświetlić pliki w domyślnym magazynie klastra, rozwiń wpis, a następnie kliknij dwukrotnie (kontener domyślny).
Jeśli nie można rozwinąć wpisu (domyślne konto magazynu), używasz usługi Azure Data Lake Storage jako domyślnego magazynu dla klastra. Aby wyświetlić pliki w domyślnym magazynie klastra, kliknij dwukrotnie wpis (domyślne konto magazynu).
Aby przekazać pliki .exe, użyj jednej z następujących metod:
Jeśli używasz konta usługi Azure Storage, wybierz ikonę Przekaż obiekt blob .

W oknie dialogowym Przekazywanie nowego pliku w obszarze Nazwa pliku wybierz pozycję Przeglądaj. W oknie dialogowym Przekazywanie obiektu blob przejdź do folderu bin\debug dla projektu mapera, a następnie wybierz plik mapper.exe. Na koniec wybierz pozycję Otwórz , a następnie przycisk OK , aby ukończyć przekazywanie.
W przypadku usługi Azure Data Lake Storage kliknij prawym przyciskiem myszy pusty obszar na liście plików, a następnie wybierz polecenie Przekaż. Na koniec wybierz plik mapper.exe , a następnie wybierz pozycję Otwórz.
Po zakończeniu przekazywania mapper.exe powtórz proces przekazywania dla pliku reducer.exe .
Uruchamianie zadania: używanie sesji SSH
Poniższa procedura opisuje sposób uruchamiania zadania MapReduce przy użyciu sesji SSH:
Użyj polecenia ssh, aby nawiązać połączenie z klastrem. Zmodyfikuj poniższe polecenie, zastępując ciąg CLUSTERNAME nazwą klastra, a następnie wprowadź polecenie:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netUruchom zadanie MapReduce za pomocą jednego z następujących poleceń:
Jeśli domyślnym magazynem jest Azure Storage:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutJeśli domyślnym magazynem jest usługa Data Lake Storage Gen1:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutJeśli domyślnym magazynem jest usługa Data Lake Storage Gen2:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
Na poniższej liście opisano, co reprezentuje każdy parametr i opcja:
Parametr Opis hadoop-streaming.jar Określa plik jar zawierający funkcję przesyłania strumieniowego MapReduce. -Pliki Określa pliki mapper.exe i reducer.exe dla tego zadania. Deklaracja wasbs:///protokołu ,adl:///lubabfs:///przed każdym plikiem jest ścieżką do katalogu głównego domyślnego magazynu dla klastra.-Mapowania Określa plik, który implementuje maper. -Reduktor Określa plik, który implementuje reduktor. -danych wejściowych Określa dane wejściowe. -wyjście Określa katalog wyjściowy. Po zakończeniu zadania MapReduce użyj następującego polecenia, aby wyświetlić wyniki:
hdfs dfs -text /example/wordcountout/part-00000Poniższy tekst to przykład danych zwracanych przez to polecenie:
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
Uruchamianie zadania: korzystanie z programu PowerShell
Użyj następującego skryptu programu PowerShell, aby uruchomić zadanie MapReduce i pobrać wyniki.
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
Ten skrypt wyświetla monit o podanie nazwy i hasła konta logowania klastra wraz z nazwą klastra usługi HDInsight. Po zakończeniu zadania dane wyjściowe są pobierane do pliku o nazwie output.txt. Poniższy tekst jest przykładem danych w output.txt pliku:
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17