Jak używać notesu usługi Azure Machine Learning na platformie Spark
Uwaga
Wycofamy usługę Azure HDInsight w usłudze AKS 31 stycznia 2025 r. Przed 31 stycznia 2025 r. należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure, aby uniknąć nagłego zakończenia obciążeń. Pozostałe klastry w ramach subskrypcji zostaną zatrzymane i usunięte z hosta.
Tylko podstawowa pomoc techniczna będzie dostępna do daty wycofania.
Ważne
Ta funkcja jest aktualnie dostępna jako funkcja podglądu. Dodatkowe warunki użytkowania dla wersji zapoznawczych platformy Microsoft Azure obejmują więcej warunków prawnych, które dotyczą funkcji platformy Azure, które znajdują się w wersji beta, w wersji zapoznawczej lub w inny sposób nie zostały jeszcze wydane w wersji ogólnodostępnej. Aby uzyskać informacje o tej konkretnej wersji zapoznawczej, zobacz Informacje o wersji zapoznawczej usługi Azure HDInsight w usłudze AKS. W przypadku pytań lub sugestii dotyczących funkcji prześlij żądanie w usłudze AskHDInsight , aby uzyskać szczegółowe informacje i postępuj zgodnie z nami, aby uzyskać więcej aktualizacji w społeczności usługi Azure HDInsight.
Uczenie maszynowe to rozwijająca się technologia, która umożliwia komputerom automatyczne uczenie się z poprzednich danych. Uczenie maszynowe używa różnych algorytmów do tworzenia modeli matematycznych i przewidywania używają danych historycznych lub informacji. Mamy model zdefiniowany do niektórych parametrów, a uczenie się jest wykonywaniem programu komputerowego w celu zoptymalizowania parametrów modelu przy użyciu danych treningowych lub środowiska. Model może być predykcyjny, aby przewidywać w przyszłości, lub opisowy, aby uzyskać wiedzę na podstawie danych.
W poniższym notesie samouczka przedstawiono przykład trenowania modeli uczenia maszynowego na danych tabelarycznych. Możesz zaimportować ten notes i uruchomić go samodzielnie.
Przekazywanie pliku CSV do magazynu
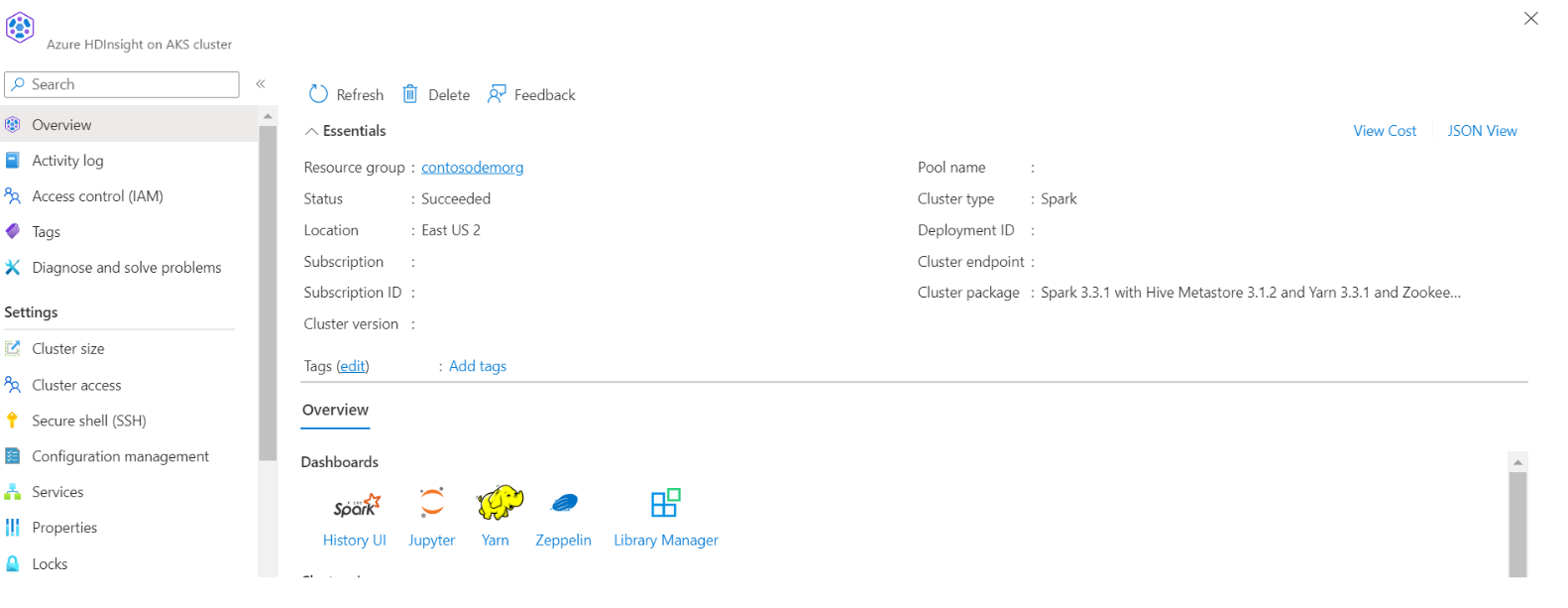
Znajdowanie nazwy magazynu i kontenera w widoku JSON portalu
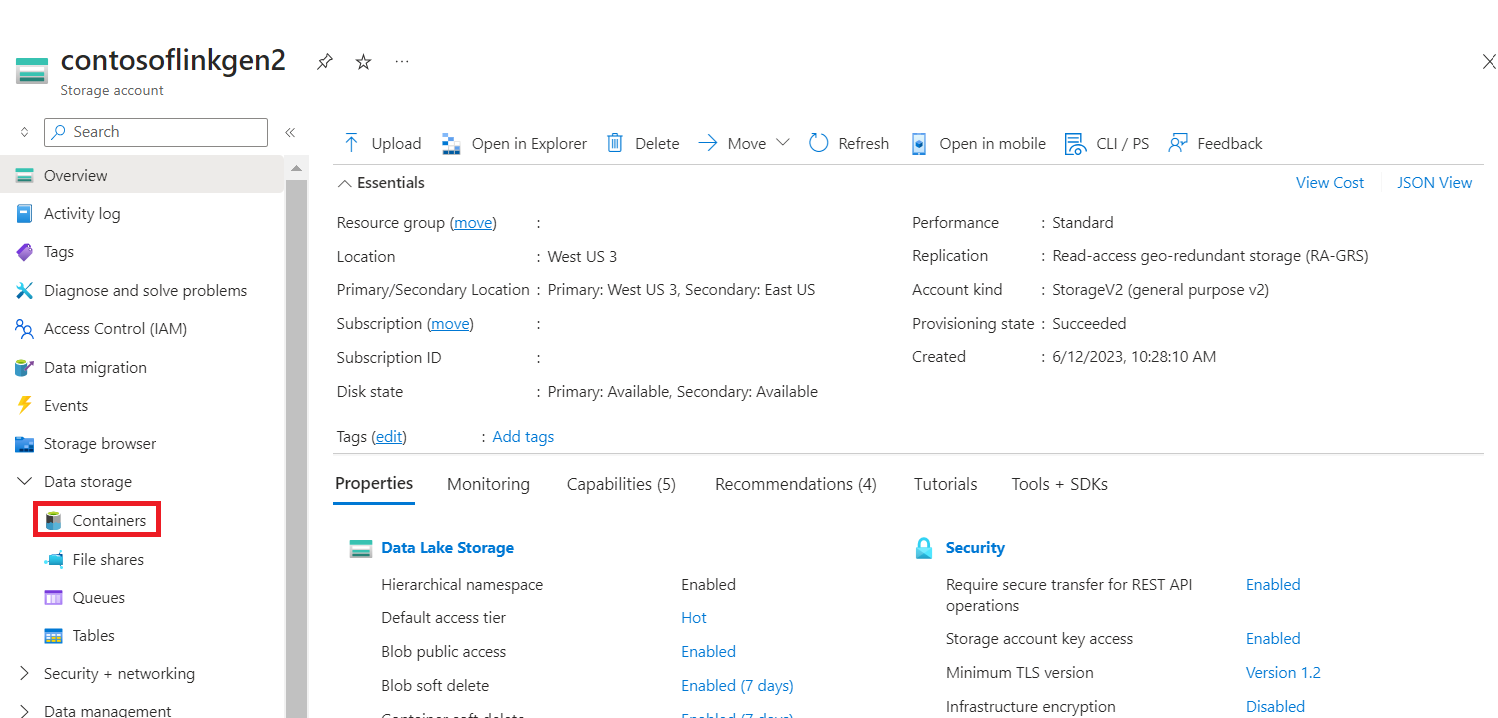
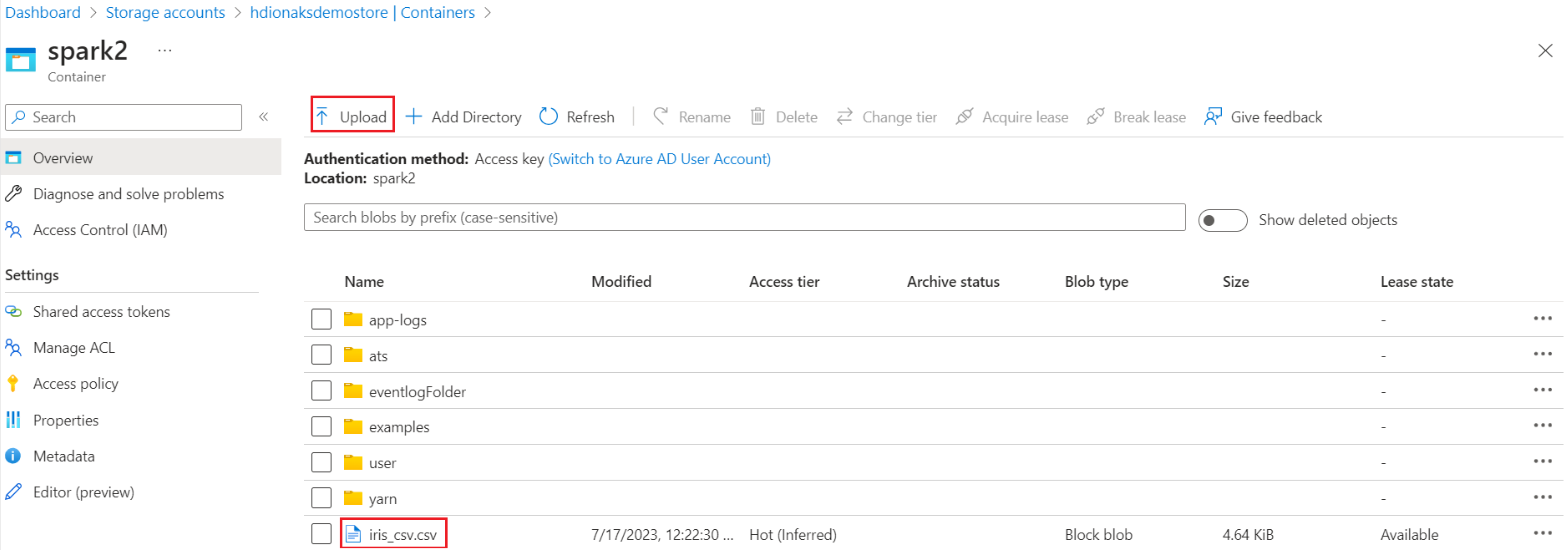
Przejdź do podstawowego folderu podstawowego kontenera>magazynu>hdi przekaż plik> CSV
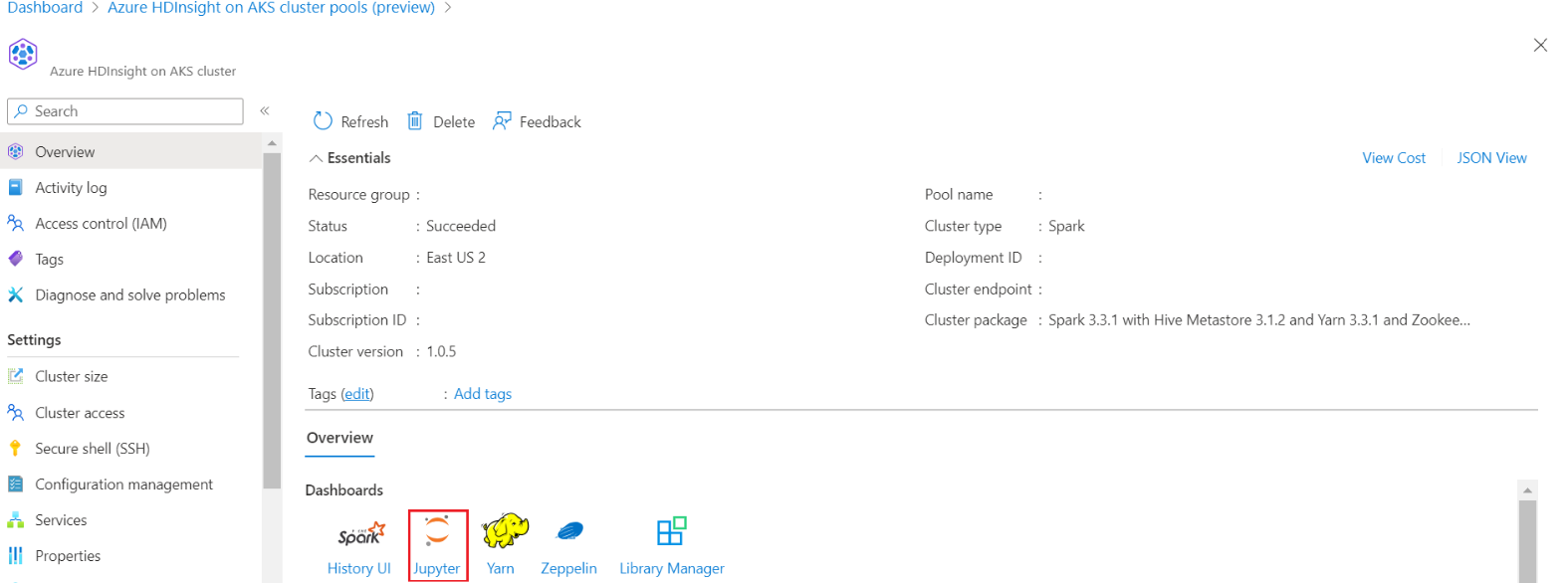
Zaloguj się do klastra i otwórz notes Jupyter Notebook
Importowanie bibliotek MLlib platformy Spark w celu utworzenia potoku
import pyspark from pyspark.ml import Pipeline, PipelineModel from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import VectorAssembler, StringIndexer, IndexToString
Odczytywanie pliku CSV w ramce danych platformy Spark
df = spark.read.("abfss:///iris_csv.csv",inferSchema=True,header=True)Dzielenie danych na potrzeby trenowania i testowania
iris_train, iris_test = df.randomSplit([0.7, 0.3], seed=123)Tworzenie potoku i trenowanie modelu
assembler = VectorAssembler(inputCols=['sepallength', 'sepalwidth', 'petallength', 'petalwidth'],outputCol="features",handleInvalid="skip") indexer = StringIndexer(inputCol="class", outputCol="classIndex", handleInvalid="skip") classifier = LogisticRegression(featuresCol="features", labelCol="classIndex", maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[assembler,indexer,classifier]) model = pipeline.fit(iris_train) # Create a test `dataframe` with predictions from the trained model test_model = model.transform(iris_test) # Taking an output from the test dataframe with predictions test_model.take(1)
Ocena dokładności modelu
import pyspark.ml.evaluation as ev evaluator = ev.MulticlassClassificationEvaluator(labelCol='classIndex') print(evaluator.evaluate(test_model,{evaluator.metricName: 'accuracy'}))



