Jak używać usługi Azure Pipelines z Apache Flink® na HDInsight w AKS
Ważny
Usługa Azure HDInsight w usłudze AKS została wycofana 31 stycznia 2025 r. Dowiedz się więcej w tym ogłoszeniu.
Aby uniknąć nagłego kończenia obciążeń, należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure.
Ważny
Ta funkcja jest obecnie dostępna w wersji zapoznawczej. Dodatkowe warunki użytkowania dla wersji zapoznawczych platformy Microsoft Azure obejmują więcej warunków prawnych, które dotyczą funkcji platformy Azure w wersji beta, w wersji zapoznawczej lub w inny sposób nie zostały jeszcze wydane w wersji ogólnodostępnej. Aby uzyskać informacje na temat tej konkretnej wersji zapoznawczej, zobacz informacje o wersji zapoznawczej Azure HDInsight na AKS. W przypadku pytań lub sugestii dotyczących funkcji, prosimy o przesłanie zgłoszenia na AskHDInsight wraz ze szczegółami, a także śledź nas, aby uzyskać więcej aktualizacji w temacie społeczności Azure HDInsight.
W tym artykule dowiesz się, jak używać Azure Pipelines razem z HDInsight na AKS do przesyłania zadań Flink za pomocą interfejsu API REST klastra. Przeprowadzimy Cię przez proces przy użyciu przykładowego potoku YAML i skryptu PowerShell, które usprawniają automatyzację interakcji z interfejsem API REST.
Warunki wstępne
Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, utwórz bezpłatne konto.
Konto usługi GitHub, na którym można utworzyć repozytorium. Utwórz jedno za darmo.
Utwórz katalog
.pipeline, skopiuj flink-azure-pipelines.yml oraz flink-job-azure-pipeline.ps1Organizacja usługi Azure DevOps. Utwórz je bezpłatnie. Jeśli twój zespół już go ma, upewnij się, że jesteś administratorem projektu usługi Azure DevOps, którego chcesz użyć.
Możliwość uruchamiania pipeline'ów na agentach hostowanych przez firmę Microsoft. Aby korzystać z agentów hostowanych przez firmę Microsoft, organizacja usługi Azure DevOps musi mieć dostęp do zadań równoległych hostowanych przez firmę Microsoft. Możesz kupić zadanie równoległe lub zażądać bezpłatnej dotacji.
Klaster Flink. Jeśli go nie masz, Utwórz klaster Flink w usłudze HDInsight w usłudze AKS.
Utwórz jeden katalog na koncie magazynu klastra, aby skopiować plik JAR zadania. Ten katalog należy później skonfigurować w potoku YAML jako lokalizację dla pliku jar zadania (<JOB_JAR_STORAGE_PATH>).
Kroki konfigurowania potoku
Tworzenie jednostki usługi dla usługi Azure Pipelines
Utwórz główny obiekt usługi Microsoft Entra , aby uzyskać dostęp do Azure – udziel uprawnień dostępu do usługi HDInsight w klastrze AKS z rolą współtwórcy, zanotuj identyfikator appId, hasło i dzierżawcę z odpowiedzi.
az ad sp create-for-rbac -n <service_principal_name> --role Contributor --scopes <Flink Cluster Resource ID>`
Przykład:
az ad sp create-for-rbac -n azure-flink-pipeline --role Contributor --scopes /subscriptions/abdc-1234-abcd-1234-abcd-1234/resourceGroups/myResourceGroupName/providers/Microsoft.HDInsight/clusterpools/hiloclusterpool/clusters/flinkcluster`
Odniesienie
- witryny internetowej Apache Flink
Notatka
Nazwy projektów open source Apache, Apache Flink, Flink i powiązane są znakami towarowymiApache Software Foundation (ASF).
Utwórz magazyn kluczy
Utwórz Azure Key Vault. Skorzystaj z tego samouczka, aby utworzyć nowy Azure Key Vault.
Utwórz trzy sekrety
cluster-storage-key dla klucza magazynu.
service-principal-key dla identyfikatora klienta (client ID) lub identyfikatora aplikacji (app ID) jednostki.
tajny dla jednostki usługi dla klucza tajnego.
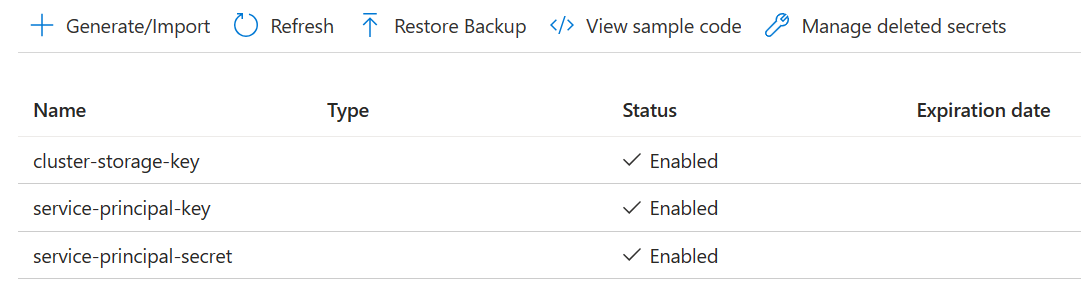
Udziel uprawnień dostępu do usługi Azure Key Vault za pomocą roli "Key Vault Secrets Officer" dla jednostki usługi.

Potok instalacji
Przejdź do projektu i kliknij pozycję Ustawienia projektu.
Przewiń w dół i wybierz pozycję Połączenia z usługą, a następnie pozycję Nowe połączenie z usługą.
Wybierz pozycję Azure Resource Manager.
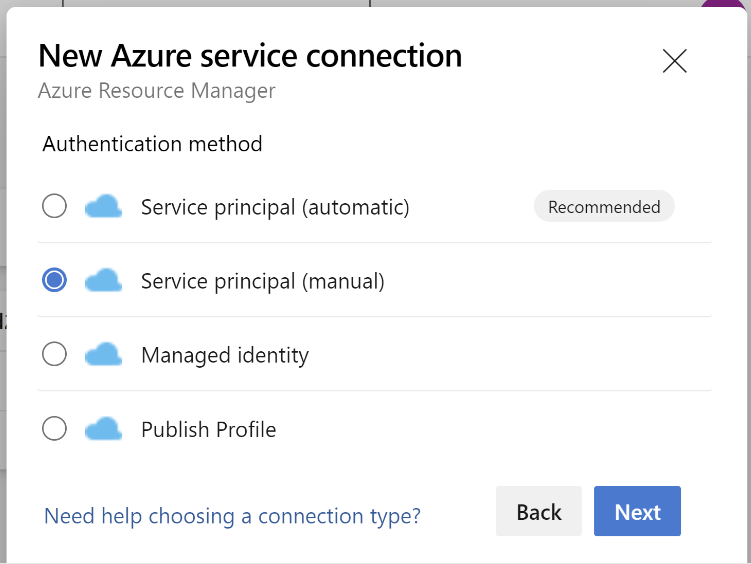
W metodzie uwierzytelniania wybierz Podmiot zabezpieczający usługę (ręcznie).
Edytuj właściwości połączenia usługi. Wybierz niedawno utworzoną jednostkę usługi.
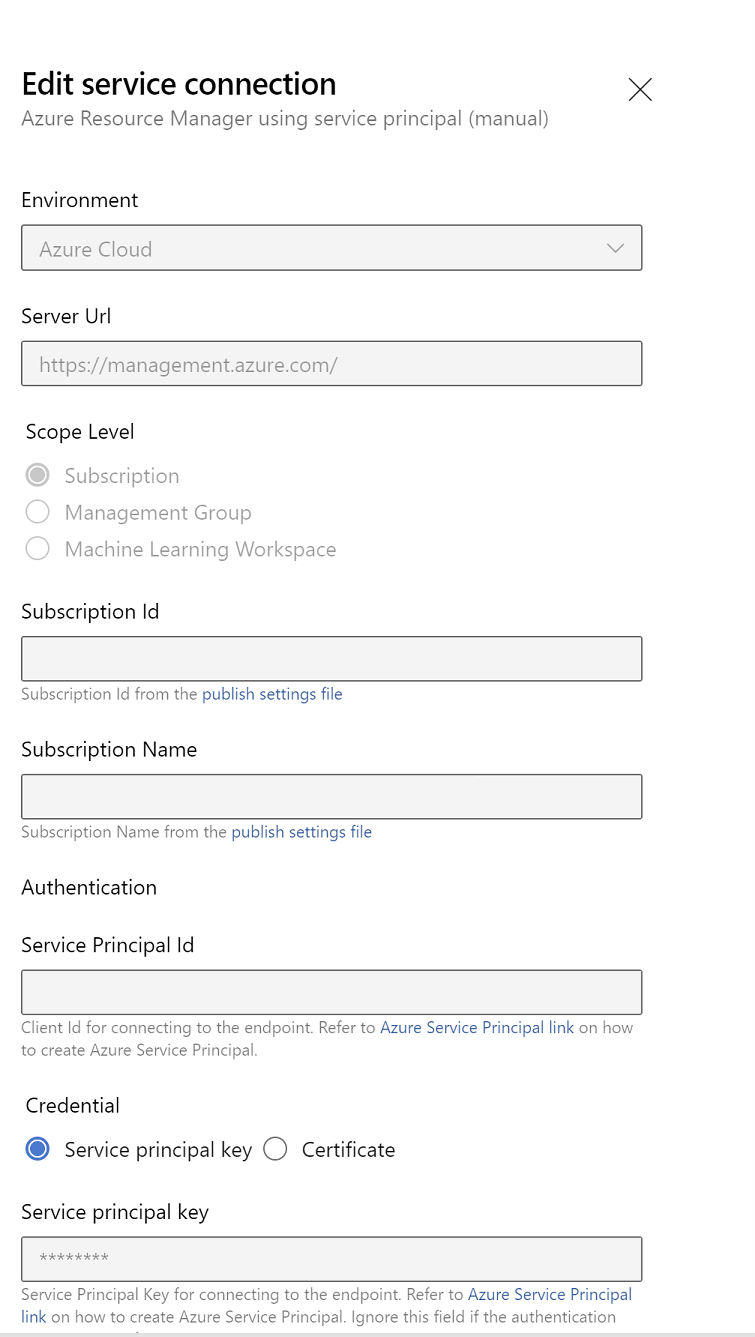
Kliknij przycisk Weryfikuj, aby sprawdzić, czy połączenie zostało poprawnie skonfigurowane. Jeśli wystąpi następujący błąd:

Następnie musisz przypisać rolę Czytelnika do subskrypcji.
Następnie weryfikacja powinna zakończyć się pomyślnie.
Zapisz połączenie z usługą.

Przejdź do potoków i kliknij pozycję Nowy potok.
Wybierz pozycję GitHub jako lokalizację kodu.
Wybierz repozytorium. Zobacz , jak utworzyć repozytorium w usłudze GitHub. obraz select-github-repo.
Wybierz repozytorium. Aby uzyskać więcej informacji, zobacz Jak utworzyć repozytorium w usłudze GitHub.
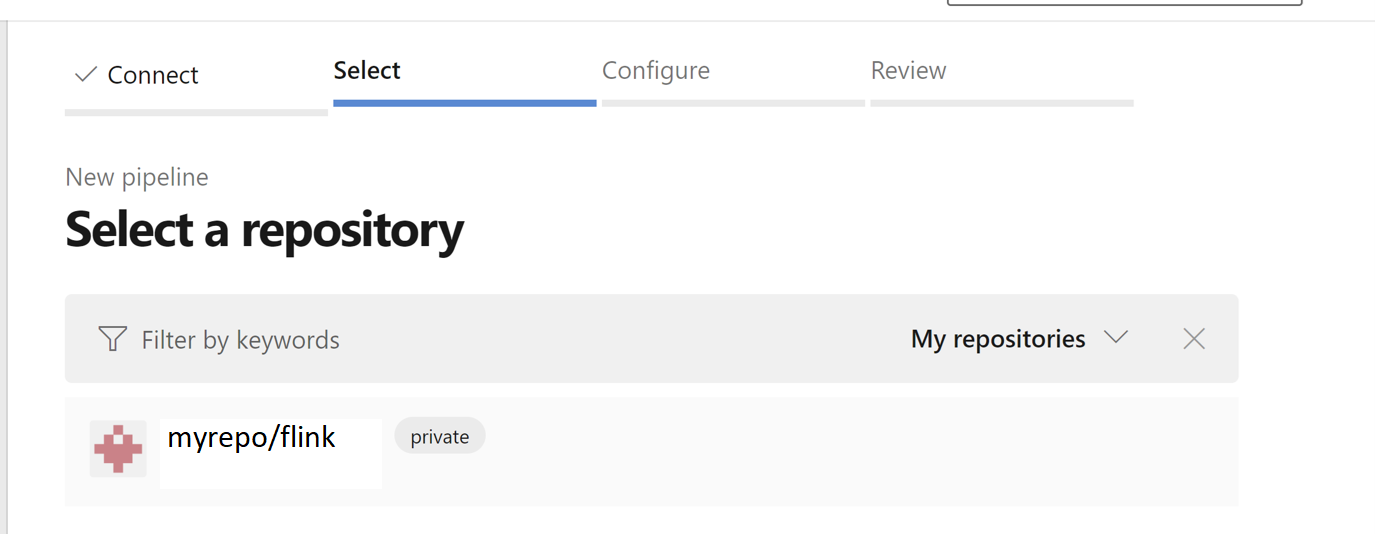
W obszarze skonfiguruj opcję potoku możesz wybrać istniejący plik YAML usługi Azure Pipelines. Wybierz gałąź i skrypt potoku, które skopiowałeś wcześniej. (.pipeline/flink-azure-pipelines.yml)
Zastąp wartość w sekcji zmiennej.

Popraw sekcję budowania kodu zgodnie z wymaganiami i skonfiguruj <JOB_JAR_LOCAL_PATH> w sekcji zmiennej dla lokalnej ścieżki pliku jar jobu.
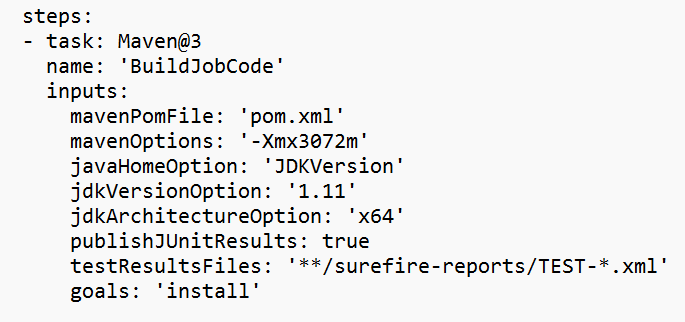
Dodaj zmienną potoku "action" i skonfiguruj wartość "RUN".
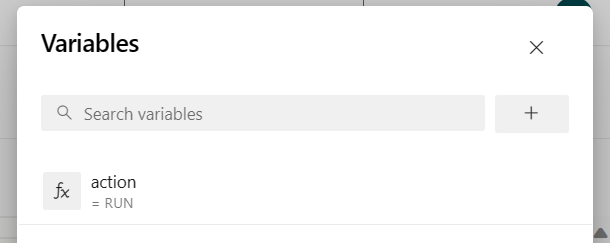
Wartości danej zmiennej można zmienić przed uruchomieniem potoku.
NOWY: Ta wartość jest domyślna. Uruchamia nowe zadanie, a jeśli zadanie jest już uruchomione, aktualizuje uruchomione zadanie przy użyciu najnowszego pliku jar.
SAVEPOINT: Ta wartość ustawia punkt zapisu dla uruchomionego zadania.
DELETE: Anuluj lub usuń uruchomione zadanie.
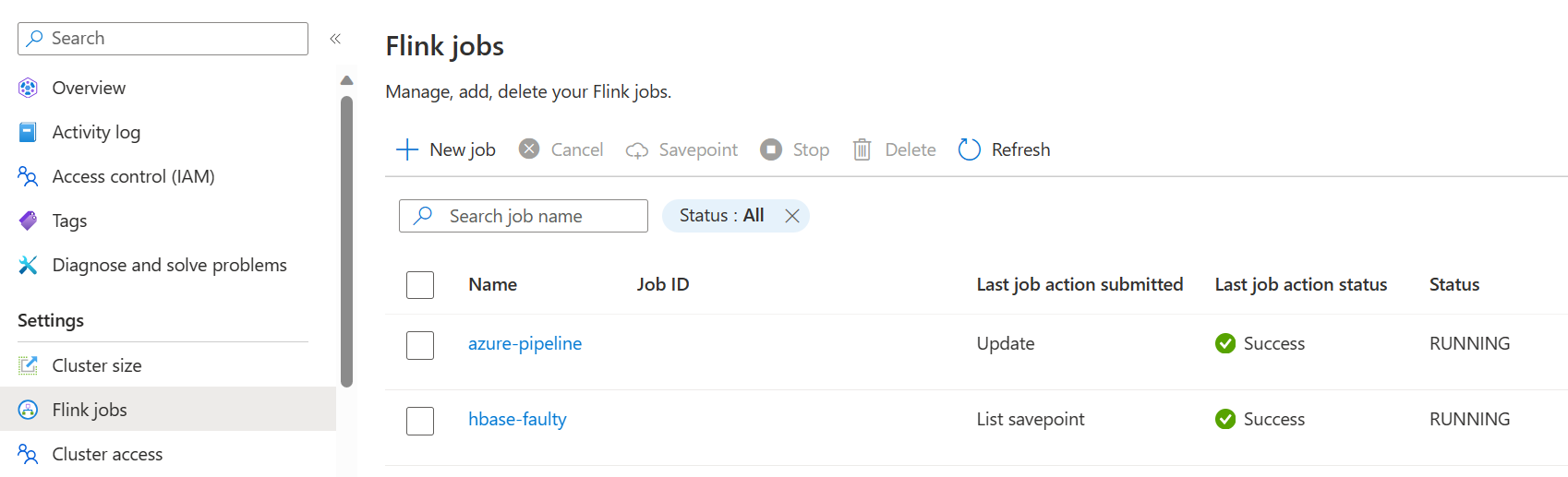
Zapisz i uruchom potok. Uruchomione zadanie można wyświetlić w portalu w sekcji Zadanie Flink.








Notatka
Jest to przykład wysłania zadania przy użyciu pipeline. Możesz postępować zgodnie z dokumentem interfejsu API REST Flink, aby napisać własny kod do przesłania zadania.