Interfejs API tabel i sql w klastrach Apache Flink® w usłudze HDInsight w usłudze AKS
Uwaga
Wycofamy usługę Azure HDInsight w usłudze AKS 31 stycznia 2025 r. Przed 31 stycznia 2025 r. należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure, aby uniknąć nagłego zakończenia obciążeń. Pozostałe klastry w ramach subskrypcji zostaną zatrzymane i usunięte z hosta.
Tylko podstawowa pomoc techniczna będzie dostępna do daty wycofania.
Ważne
Ta funkcja jest aktualnie dostępna jako funkcja podglądu. Dodatkowe warunki użytkowania dla wersji zapoznawczych platformy Microsoft Azure obejmują więcej warunków prawnych, które dotyczą funkcji platformy Azure, które znajdują się w wersji beta, w wersji zapoznawczej lub w inny sposób nie zostały jeszcze wydane w wersji ogólnodostępnej. Aby uzyskać informacje o tej konkretnej wersji zapoznawczej, zobacz Informacje o wersji zapoznawczej usługi Azure HDInsight w usłudze AKS. W przypadku pytań lub sugestii dotyczących funkcji prześlij żądanie w usłudze AskHDInsight , aby uzyskać szczegółowe informacje i postępuj zgodnie z nami, aby uzyskać więcej aktualizacji w społeczności usługi Azure HDInsight.
Apache Flink oferuje dwa relacyjne interfejsy API — interfejs API tabel i sql — do ujednoliconego przetwarzania strumieniowego i przetwarzania wsadowego. Interfejs API tabel to zintegrowany ze językiem interfejs API zapytań, który umożliwia intuicyjne tworzenie zapytań z operatorów relacyjnych, takich jak wybór, filtrowanie i łączenie. Obsługa języka SQL języka Flink jest oparta na platformie Apache Calcite, która implementuje standard SQL.
Interfejsy API tabel i interfejsy SQL bezproblemowo integrują się ze sobą i interfejsem API datastream języka Flink. Możesz łatwo przełączać się między wszystkimi interfejsami API i bibliotekami, które są oparte na nich.
Apache Flink SQL
Podobnie jak w przypadku innych aparatów SQL zapytania Flink działają na podstawie tabel. Różni się ona od tradycyjnej bazy danych, ponieważ funkcja Flink nie zarządza danymi magazynowanych lokalnie; zamiast tego zapytania działają stale w tabelach zewnętrznych.
Potoki przetwarzania danych flink zaczynają się od tabel źródłowych i kończą się tabelami ujścia. Tabele źródłowe tworzą wiersze obsługiwane podczas wykonywania zapytania; są to tabele, do których odwołuje się klauzula FROM zapytania. Łączniki mogą być typu HDInsight Kafka, HDInsight HBase, Azure Event Hubs, bazy danych, systemy plików lub dowolny inny system, którego łącznik znajduje się w ścieżce klas.
Używanie klienta SQL Flink w usłudze HDInsight w klastrach usługi AKS
Ten artykuł zawiera informacje na temat używania interfejsu wiersza polecenia z poziomu protokołu Secure Shell w witrynie Azure Portal. Poniżej przedstawiono kilka szybkich przykładów sposobu rozpoczęcia pracy.
Aby uruchomić klienta SQL
./bin/sql-client.shAby przekazać plik sql inicjalizacji do uruchomienia wraz z sql-client
./sql-client.sh -i /path/to/init_file.sqlAby ustawić konfigurację w programie sql-client
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
SQL DDL
Język Flink SQL obsługuje następujące instrukcje CREATE
- CREATE TABLE
- CREATE DATABASE
- TWORZENIE WYKAZU
Poniżej przedstawiono przykładową składnię definiującą tabelę źródłową przy użyciu łącznika jdbc w celu nawiązania połączenia z usługą MSSQL z identyfikatorem, nazwą jako kolumnami w instrukcji CREATE TABLE
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
CREATE DATABASE :
CREATE DATABASE students;
UTWÓRZ WYKAZ:
CREATE CATALOG myhive WITH ('type'='hive');
Możesz uruchamiać zapytania ciągłe na podstawie tych tabel
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Zapisz w tabeli ujścia z tabeli źródłowej:
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Dodawanie zależności
Instrukcje JAR służą do dodawania plików jar użytkownika do ścieżki klasy lub usuwania plików jar użytkownika ze ścieżki klasy lub wyświetlania dodanych plików jar w ścieżce klasy w środowisku uruchomieniowym.
Język Flink SQL obsługuje następujące instrukcje JAR:
- ADD JAR
- POKAŻ PLIKI JAR
- USUŃ PLIK JAR
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
Magazyn metadanych Hive w klastrach Apache Flink® w usłudze HDInsight w usłudze AKS
Wykazy zapewniają metadane, takie jak bazy danych, tabele, partycje, widoki i funkcje oraz informacje potrzebne do uzyskania dostępu do danych przechowywanych w bazie danych lub innych systemach zewnętrznych.
W usłudze HDInsight w usłudze AKS link obsługujemy dwie opcje katalogu:
GenericInMemoryCatalog
GenericInMemoryCatalog to implementacja wykazu w pamięci. Wszystkie obiekty są dostępne tylko przez okres istnienia sesji sql.
HiveCatalog
Dziennik HiveCatalog służy do dwóch celów: jako magazyn trwały dla czystych metadanych Flink oraz jako interfejs do odczytywania i zapisywania istniejących metadanych hive.
Uwaga
Usługa HDInsight w klastrach usługi AKS zawiera zintegrowaną opcję magazynu metadanych Hive dla platformy Apache Flink. Możesz wybrać magazyn metadanych Hive podczas tworzenia klastra
Jak tworzyć i rejestrować bazy danych Flink do katalogów
Zapoznaj się z tym artykułem na temat korzystania z interfejsu wiersza polecenia i rozpoczynania pracy z klientem Flink SQL z poziomu protokołu Secure Shell w witrynie Azure Portal.
Rozpocznij
sql-client.shsesję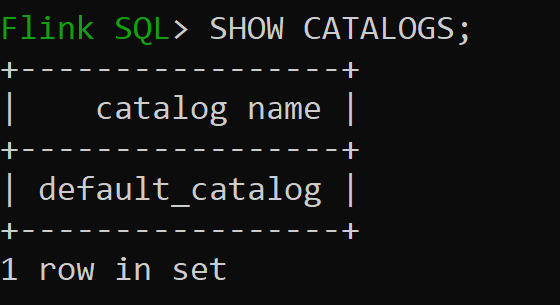
Default_catalog jest domyślnym wykazem w pamięci
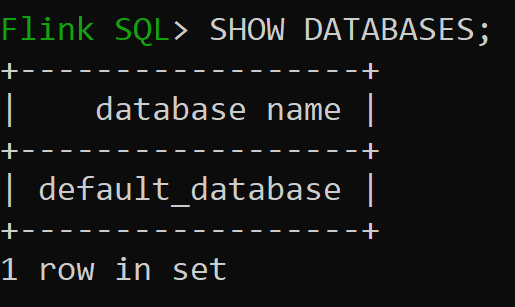
Teraz sprawdźmy domyślną bazę danych wykazu w pamięci
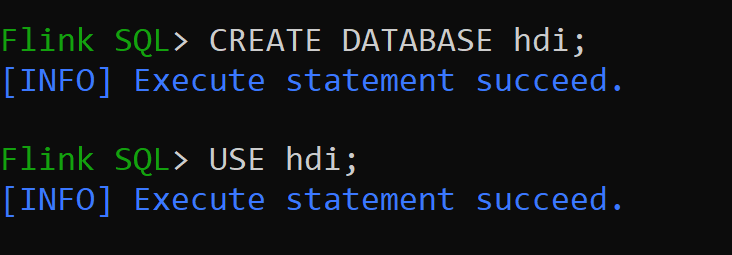
Utwórzmy katalog hive wersji 3.1.2 i użyjmy go
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;Uwaga
Usługa HDInsight w usłudze AKS obsługuje programy Hive 3.1.2 i Hadoop 3.3.2. Właściwość jest ustawiona
hive-conf-dirna lokalizację/opt/hive-confUtwórzmy bazę danych w katalogu hive i ustawmy ją jako domyślną dla sesji (chyba że została zmieniona).
How to Create and Register Hive Tables to Hive Catalog
Postępuj zgodnie z instrukcjami w temacie How to Create and Register Flink Databases to Catalog (Jak utworzyć i zarejestrować bazy danych Flink do katalogu)
Utwórzmy tabelę Flink typu łącznika Hive bez partycji
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');Wstawianie danych do hive_table
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';Odczytywanie danych z hive_table
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rowsUwaga
Katalog magazynu Hive znajduje się w wyznaczonym kontenerze konta magazynu wybranego podczas tworzenia klastra Apache Flink. Można go znaleźć w katalogu hive/warehouse/
Umożliwia utworzenie tabeli Flink typu łącznika hive z partycją
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
Ważne
Istnieje znane ograniczenie w narzędziu Apache Flink. Ostatnie kolumny "n" są wybierane dla partycji niezależnie od kolumny partycji zdefiniowanej przez użytkownika. FLINK-32596 Klucz partycji będzie nieprawidłowy, gdy użyj dialektu Flink do utworzenia tabeli Programu Hive.
Odwołanie
- Interfejs API tabel apache Flink i SQL
- Nazwy projektów apache, Apache Flink, Flink i skojarzone z nimi są znakami towarowymi programu Apache Software Foundation (ASF).