Orkiestracja zadań apache Flink® przy użyciu programu Orchestration Manager przepływu pracy usługi Azure Data Factory (obsługiwanego przez platformę Apache Airflow)
Uwaga
Wycofamy usługę Azure HDInsight w usłudze AKS 31 stycznia 2025 r. Przed 31 stycznia 2025 r. należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure, aby uniknąć nagłego zakończenia obciążeń. Pozostałe klastry w ramach subskrypcji zostaną zatrzymane i usunięte z hosta.
Tylko podstawowa pomoc techniczna będzie dostępna do daty wycofania.
Ważne
Ta funkcja jest aktualnie dostępna jako funkcja podglądu. Dodatkowe warunki użytkowania dla wersji zapoznawczych platformy Microsoft Azure obejmują więcej warunków prawnych, które dotyczą funkcji platformy Azure, które znajdują się w wersji beta, w wersji zapoznawczej lub w inny sposób nie zostały jeszcze wydane w wersji ogólnodostępnej. Aby uzyskać informacje o tej konkretnej wersji zapoznawczej, zobacz Informacje o wersji zapoznawczej usługi Azure HDInsight w usłudze AKS. W przypadku pytań lub sugestii dotyczących funkcji prześlij żądanie w usłudze AskHDInsight , aby uzyskać szczegółowe informacje i postępuj zgodnie z nami, aby uzyskać więcej aktualizacji w społeczności usługi Azure HDInsight.
W tym artykule opisano zarządzanie zadaniem Flink przy użyciu interfejsu API REST platformy Azure i potoku danych orkiestracji w usłudze Azure Data Factory Workflow Orchestration Manager. Usługa Azure Data Factory Workflow Orchestration Manager to prosty i wydajny sposób tworzenia środowisk Apache Airflow i zarządzania nimi, co umożliwia łatwe uruchamianie potoków danych na dużą skalę.
Apache Airflow to platforma typu open source, która programowo tworzy, planuje i monitoruje złożone przepływy pracy danych. Umożliwia zdefiniowanie zestawu zadań nazywanych operatorami, które można połączyć w skierowane grafy acykliczne (DAG) do reprezentowania potoków danych.
Na poniższym diagramie przedstawiono rozmieszczenie usług Airflow, Key Vault i HDInsight w usłudze AKS na platformie Azure.

Wiele jednostek usługi platformy Azure jest tworzonych na podstawie zakresu w celu ograniczenia wymaganego dostępu i niezależnego zarządzania cyklem życia poświadczeń klienta.
Zaleca się okresowe obracanie kluczy dostępu lub wpisów tajnych.
Kroki instalacji
Przekaż plik JAR zadania Flink do konta magazynu. Może to być podstawowe konto magazynu skojarzone z klastrem Flink lub dowolnym innym kontem magazynu, w którym należy przypisać rolę "Właściciel danych obiektu blob usługi Storage" do przypisanej przez użytkownika tożsamości usługi zarządzanej używanej dla klastra na tym koncie magazynu.
Azure Key Vault — możesz wykonać czynności opisane w tym samouczku, aby utworzyć nową usługę Azure Key Vault , jeśli jej nie masz.
Tworzenie jednostki usługi Microsoft Entra w celu uzyskania dostępu do usługi Key Vault — udzielanie uprawnień dostępu do usługi Azure Key Vault za pomocą roli "Key Vault Secrets Officer" i zanotuj identyfikator "appId" i "tenant" z odpowiedzi. W przypadku funkcji Airflow należy użyć tej samej funkcji, aby używać magazynu Key Vault jako zapleczy do przechowywania poufnych informacji.
az ad sp create-for-rbac -n <sp name> --role “Key Vault Secrets Officer” --scopes <key vault Resource ID>Włącz usługę Azure Key Vault dla programu Workflow Orchestration Manager , aby przechowywać poufne informacje i zarządzać nimi w bezpieczny i scentralizowany sposób. Dzięki temu można używać zmiennych i połączeń, a także automatycznie przechowywać je w usłudze Azure Key Vault. Nazwa połączeń i zmiennych musi być poprzedzona prefiksem variables_prefix zdefiniowanym w AIRFLOW__SECRETS__BACKEND_KWARGS. Jeśli na przykład variables_prefix ma wartość hdinsight-aks-variables, wówczas dla klucza zmiennej hello należy przechowywać zmienną w zmiennej hdinsight-aks-variable -hello.
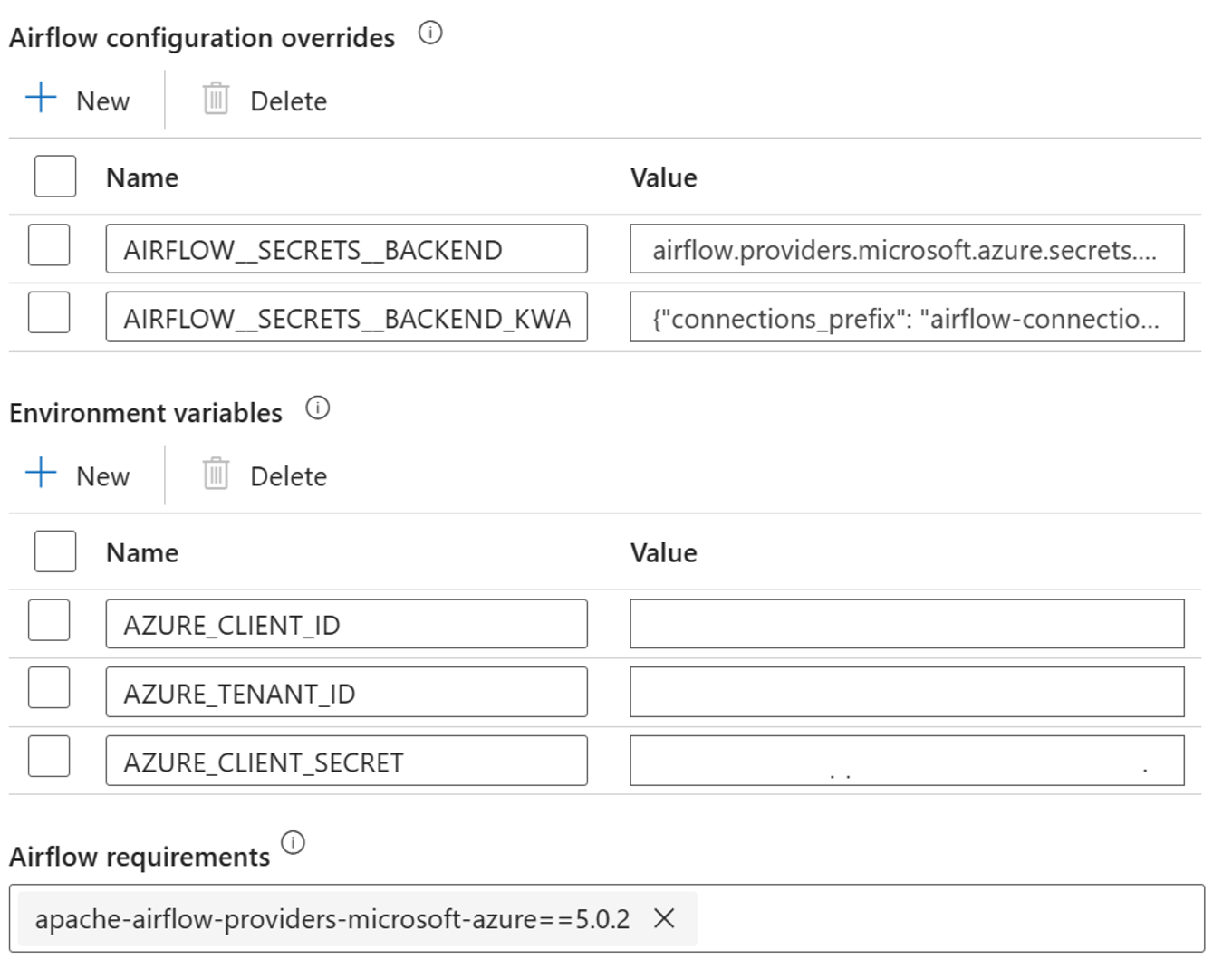
Dodaj następujące ustawienia dla przesłonięć konfiguracji airflow we właściwościach zintegrowanego środowiska uruchomieniowego:
AIRFLOW__SECRETS__BACKEND:
"airflow.providers.microsoft.azure.secrets.key_vault.AzureKeyVaultBackend"AIRFLOW__SECRETS__BACKEND_KWARGS:
"{"connections_prefix": "airflow-connections", "variables_prefix": "hdinsight-aks-variables", "vault_url": <your keyvault uri>}”
Dodaj następujące ustawienie dla konfiguracji zmiennych środowiskowych we właściwościach zintegrowanego środowiska uruchomieniowego airflow:
AZURE_CLIENT_ID =
<App Id from Create Azure AD Service Principal>AZURE_TENANT_ID =
<Tenant from Create Azure AD Service Principal>AZURE_CLIENT_SECRET =
<Password from Create Azure AD Service Principal>
Dodawanie wymagań dotyczących przepływu powietrza — apache-airflow-providers-microsoft-azure
Tworzenie jednostki usługi Microsoft Entra w celu uzyskania dostępu do platformy Azure — udzielanie uprawnień dostępu do klastra usługi HDInsight AKS z rolą współautora, zanotuj identyfikator appId, hasło i dzierżawę z odpowiedzi.
az ad sp create-for-rbac -n <sp name> --role Contributor --scopes <Flink Cluster Resource ID>Utwórz następujące wpisy tajne w magazynie kluczy z wartością z poprzedniej jednostki usługi AD appId, password i tenant, poprzedzonej właściwością variables_prefix zdefiniowaną w AIRFLOW__SECRETS__BACKEND_KWARGS. Kod DAG może uzyskać dostęp do dowolnej z tych zmiennych bez variables_prefix.
hdinsight-aks-variables-api-client-id=
<App ID from previous step>hdinsight-aks-variables-api-secret=
<Password from previous step>hdinsight-aks-variables-tenant-id=
<Tenant from previous step>
from airflow.models import Variable def retrieve_variable_from_akv(): variable_value = Variable.get("client-id") print(variable_value)

Definicja języka DAG
DaG (Skierowany graf Acykliczny) to podstawowa koncepcja przepływu powietrza, zbieranie zadań razem, zorganizowane z zależnościami i relacjami, aby powiedzieć, jak powinny być uruchamiane.
Istnieją trzy sposoby deklarowania grupy DAG:
Możesz użyć menedżera kontekstu, który dodaje grupę DAG do dowolnego elementu niejawnie
Można użyć standardowego konstruktora, przekazując grupę DAG do dowolnych operatorów, których używasz
Możesz użyć dekoratora @dag , aby przekształcić funkcję w generator DAG (z airflow.decorators import dag)
Grupy DAGs nie są niczym bez zadań do uruchomienia, a te są dostępne w postaci operatorów, czujników lub przepływu zadań.
Więcej informacji na temat grup DAG, przepływu sterowania, poddagów, grup zadań itp. można znaleźć bezpośrednio z poziomu platformy Apache Airflow.
Wykonywanie języka DAG
Przykładowy kod jest dostępny w repozytorium git. Pobierz kod lokalnie na komputerze i przekaż wordcount.py do magazynu obiektów blob. Postępuj zgodnie z instrukcjami , aby zaimportować grupę DAG do przepływu pracy utworzonego podczas instalacji.
Wordcount.py to przykład organizowania przesyłania zadania Flink przy użyciu platformy Apache Airflow z usługą HDInsight w usłudze AKS. Grupa DAG ma dwa zadania:
Pobierz
OAuth TokenWywoływanie przesyłania zadania Flink usługi HDInsight za pomocą interfejsu API REST platformy Azure w celu przesłania nowego zadania
Grupa DAG oczekuje konfiguracji jednostki usługi zgodnie z opisem podczas procesu instalacji poświadczeń klienta OAuth i przekaże następującą konfigurację wejściową do wykonania.
Kroki wykonywania
Wykonaj grupę DAG z interfejsu użytkownika przepływu pracy platformy Airflow. Możesz otworzyć interfejs użytkownika programu Azure Data Factory Workflow Orchestration Manager, klikając ikonę Monitor.

Wybierz grupę DAG "FlinkWordCountExample" ze strony "DAGs".

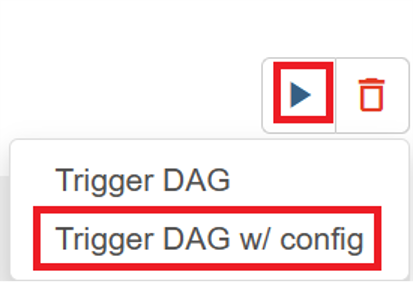
Kliknij ikonę "wykonaj" w prawym górnym rogu i wybierz pozycję "Wyzwól grupę DAG w/ config".
Przekaż wymagany kod JSON konfiguracji
{ "jarName":"WordCount.jar", "jarDirectory":"abfs://filesystem@<storageaccount>.dfs.core.windows.net", "subscription":"<cluster subscription id>", "rg":"<cluster resource group>", "poolNm":"<cluster pool name>", "clusterNm":"<cluster name>" }Kliknij przycisk "Wyzwalacz", uruchamia wykonywanie grupy DAG.
Stan zadań DAG można wizualizować na podstawie przebiegu grupy DAG
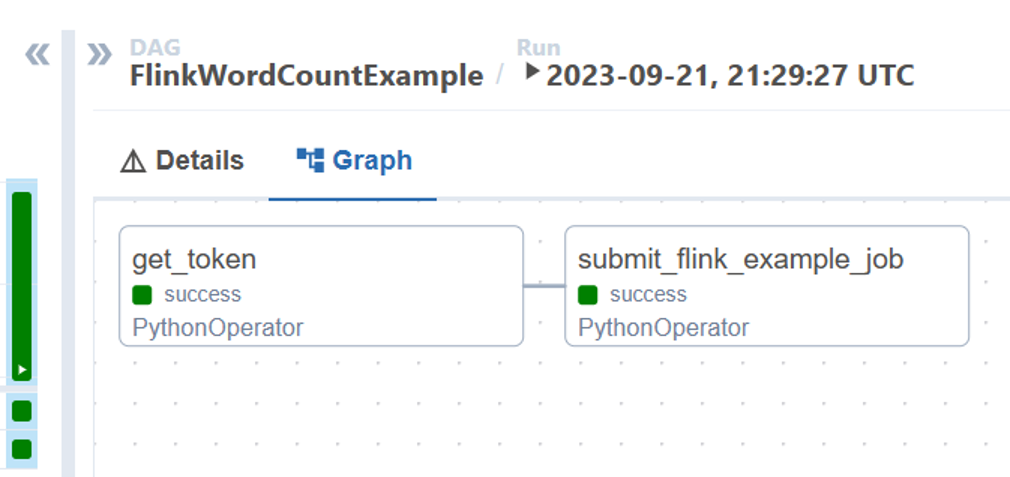
Weryfikowanie wykonania zadania z poziomu portalu
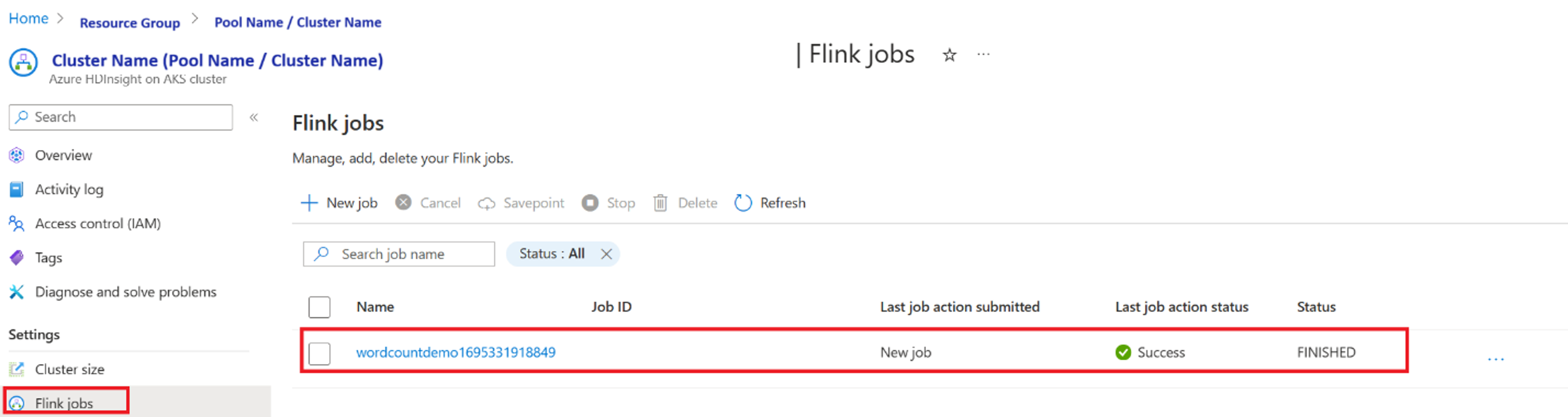
Weryfikowanie zadania z poziomu pulpitu nawigacyjnego narzędzia Apache Flink






Przykładowy kod
Jest to przykład organizowania potoku danych przy użyciu funkcji Airflow z usługą HDInsight w usłudze AKS.
Grupa DAG oczekuje konfiguracji jednostki usługi dla poświadczeń klienta OAuth i przekaże następującą konfigurację danych wejściowych do wykonania:
{
'jarName':'WordCount.jar',
'jarDirectory':'abfs://filesystem@<storageaccount>.dfs.core.windows.net',
'subscription':'<cluster subscription id>',
'rg':'<cluster resource group>',
'poolNm':'<cluster pool name>',
'clusterNm':'<cluster name>'
}
Odwołanie
- Zapoznaj się z przykładowym kodem.
- Witryna internetowa platformy Apache Flink
- Apache, Apache Airflow, Airflow, Apache Flink, Flink i skojarzone nazwy projektów typu open source są znakami towarowymi platformy Apache Software Foundation (ASF).