Wdrażanie na maszynach wirtualnych z systemem Linux w środowisku
Azure DevOps Services | Azure DevOps Server 2022 | Azure DevOps Server 2020
Z tego przewodnika Szybki start dowiesz się, jak skonfigurować potok usługi Azure DevOps na potrzeby wdrażania do wielu zasobów maszyny wirtualnej z systemem Linux w środowisku. Możesz użyć tych instrukcji dla dowolnej aplikacji, która publikuje pakiet wdrażania sieci Web.
Wymagania wstępne
- Konto platformy Azure z aktywną subskrypcją. Utwórz konto bezpłatnie.
- Organizacja i projekt usługi Azure DevOps. Utwórz konto w usłudze Azure Pipelines.
W przypadku aplikacji JavaScript lub Node.js co najmniej dwie maszyny wirtualne z systemem Linux skonfigurowane za pomocą serwera Nginx na platformie Azure.
Rozwidlenie przykładowego kodu
Jeśli masz już aplikację w usłudze GitHub, którą chcesz wdrożyć, możesz utworzyć potok dla tego kodu.
Jeśli jesteś nowym użytkownikiem, rozwidlenie tego repozytorium w usłudze GitHub:
https://github.com/MicrosoftDocs/pipelines-javascript
Tworzenie środowiska przy użyciu maszyn wirtualnych z systemem Linux
Maszyny wirtualne można dodawać jako zasoby w środowiskach i kierować do nich wdrożenia z wieloma maszynami wirtualnymi. Historia wdrażania środowiska zapewnia możliwość śledzenia z maszyny wirtualnej do zatwierdzenia.
Dodawanie zasobu maszyny wirtualnej
W projekcie usługi Azure DevOps przejdź do pozycji Środowiska potoków>, a następnie wybierz pozycję Utwórz środowisko lub Nowe środowisko.
Na pierwszym ekranie Nowe środowisko dodaj nazwę i opcjonalny opis.
W obszarze Zasób wybierz pozycję Maszyny wirtualne, a następnie wybierz pozycję Dalej.
Na następnym ekranie Nowe środowisko wybierz pozycję Linux w obszarze System operacyjny.
Skopiuj skrypt rejestracji systemu Linux. Skrypt jest taki sam dla wszystkich maszyn wirtualnych z systemem Linux dodanych do środowiska.
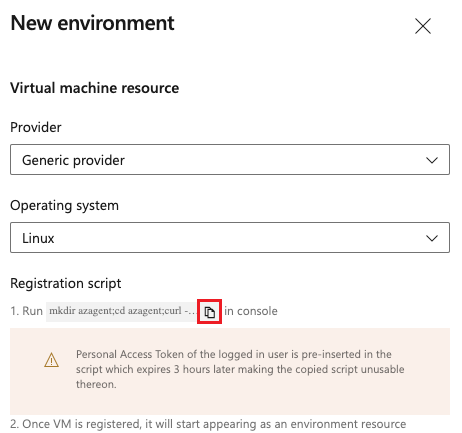
Uwaga
Osobisty token dostępu (PAT) zalogowanego użytkownika jest wstępnie wstawiany w skrypcie i wygasa po trzech godzinach.
Wybierz pozycję Zamknij i zanotuj, że nowe środowisko zostało utworzone.
Uruchom skopiowany skrypt na każdej docelowej maszynie wirtualnej, którą chcesz zarejestrować w środowisku.
Uwaga
Jeśli maszyna wirtualna ma już na nim uruchomionego innego agenta, podaj unikatową nazwę agenta do zarejestrowania się w środowisku.
Po zarejestrowaniu maszyny wirtualnej jest ona wyświetlana jako zasób na karcie Zasoby środowiska.
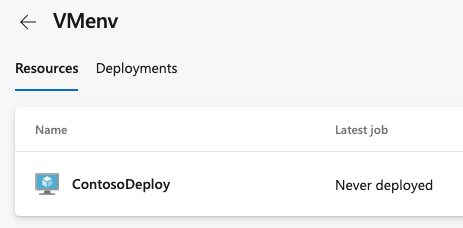
Aby ponownie skopiować skrypt do tworzenia większej liczby zasobów, na przykład w przypadku wygaśnięcia tokenu dostępu wybierz pozycję Dodaj zasób na stronie środowiska.
Dodawanie tagów i zarządzanie nimi
Tagi to sposób kierowania określonego zestawu maszyn wirtualnych w środowisku do wdrożenia. Nie ma limitu liczby tagów, których można użyć. Tagi są ograniczone do 256 znaków.
Tagi można dodawać lub usuwać tagi dla maszyn wirtualnych w skryscie rejestracji interakcyjnej lub za pośrednictwem interfejsu użytkownika, wybierając pozycję Więcej akcji ![]() dla zasobu maszyny wirtualnej. Na potrzeby tego przewodnika Szybki start przypisz inny tag do każdej maszyny wirtualnej w środowisku.
dla zasobu maszyny wirtualnej. Na potrzeby tego przewodnika Szybki start przypisz inny tag do każdej maszyny wirtualnej w środowisku.

Definiowanie potoku kompilacji ciągłej integracji
Potrzebujesz potoku kompilacji ciągłej integracji (CI), który publikuje aplikację internetową, oraz skrypt wdrożenia, który będzie uruchamiany lokalnie na serwerze z systemem Linux. Skonfiguruj potok kompilacji ciągłej integracji na podstawie środowiska uruchomieniowego, którego chcesz użyć.
Ważne
Podczas procedur usługi GitHub może zostać wyświetlony monit o utworzenie połączenia usługi GitHub lub przekierowanie do usługi GitHub w celu zalogowania się, zainstalowania usługi Azure Pipelines lub autoryzowania usługi Azure Pipelines. Postępuj zgodnie z instrukcjami wyświetlanymi na ekranie, aby ukończyć proces. Aby uzyskać więcej informacji, zobacz Access to GitHub repozytoria.
- W projekcie usługi Azure DevOps wybierz pozycję Potoki>Utwórz potok, a następnie wybierz pozycję GitHub jako lokalizację kodu źródłowego.
- Na ekranie Wybieranie repozytorium wybierz rozwidlenie przykładowego repozytorium.
- Na ekranie Konfigurowanie potoku wybierz pozycję Potok startowy. Usługa Azure Pipelines generuje plik YAML o nazwie azure-pipelines.yml dla potoku.
- Wybierz daszek listy rozwijanej obok pozycji Zapisz i uruchom, wybierz pozycję Zapisz, a następnie ponownie wybierz pozycję Zapisz . Plik jest zapisywany w rozwidlonym repozytorium GitHub.
Edytowanie kodu
Wybierz pozycję Edytuj i zastąp zawartość pliku azure-pipelines.yml następującym kodem. Dodasz do tego kodu YAML w kolejnych krokach.
Poniższy kod kompiluje projekt Node.js za pomocą narzędzia npm.
trigger:
- main
pool:
vmImage: ubuntu-latest
stages:
- stage: Build
displayName: Build stage
jobs:
- job: Build
displayName: Build
steps:
- task: UseNode@1
inputs:
version: '16.x'
displayName: 'Install Node.js'
- script: |
npm install
npm run build --if-present
npm run test --if-present
displayName: 'npm install, build and test'
- task: ArchiveFiles@2
displayName: 'Archive files'
inputs:
rootFolderOrFile: '$(System.DefaultWorkingDirectory)'
includeRootFolder: false
archiveType: zip
archiveFile: $(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip
replaceExistingArchive: true
- upload: $(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip
artifact: drop
Aby uzyskać więcej informacji, zapoznaj się z krokami w temacie Build your Node.js app with gulp for creating a build (Tworzenie aplikacji Node.js za pomocą narzędzia gulp na potrzeby tworzenia kompilacji).
Uruchamianie potoku
Wybierz pozycję Zweryfikuj i zapisz, a następnie wybierz pozycję Zapisz, wybierz pozycję Uruchom, a następnie wybierz pozycję Uruchom ponownie.
Po uruchomieniu potoku sprawdź, czy zadanie zostało uruchomione pomyślnie i czy widzisz opublikowany artefakt.
Wdrażanie na maszynach wirtualnych z systemem Linux
Edytuj potok, aby dodać następujące zadanie wdrożenia. Zastąp
<environment name>ciąg nazwą utworzonego wcześniej środowiska. Wybierz określone maszyny wirtualne ze środowiska, aby odebrać wdrożenie, określając<VM tag>zdefiniowane dla każdej maszyny wirtualnej.jobs: - deployment: VMDeploy displayName: Web deploy environment: name: <environment name> resourceType: VirtualMachine tags: <VM tag> # Update value for VMs to deploy to strategy:Aby uzyskać więcej informacji, zobacz definicję complete jobs.deployment.
Aby uzyskać więcej informacji na temat słowa kluczowego
environmenti zasobów docelowych przez zadanie wdrożenia, zobacz definicję jobs.deployment.environment.Określ element
runOncelubrollingjako wdrożeniestrategy.runOncejest najprostszą strategią wdrażania. PoszczególnepreDeploydeployelementy ,routeTrafficipostRouteTrafficcyklu życia są wykonywane raz. Następnie wykonaj polecenieon:successlubon:failure.Poniższy kod przedstawia zadanie wdrożenia dla
runOnceprogramu :jobs: - deployment: VMDeploy displayName: Web deploy environment: name: <environment name> resourceType: VirtualMachine tags: <VM tag> strategy: runOnce: deploy: steps: - script: echo my first deploymentPoniższy kod przedstawia fragment kodu YAML dla
rollingstrategii wdrażania przy użyciu potoku Języka Java. W każdej iteracji można zaktualizować maksymalnie pięć elementów docelowych. ParametrmaxParallelokreśla liczbę obiektów docelowych, które można wdrożyć równolegle.Wybór
maxParallelodpowiada bezwzględnej liczbie lub procentowi obiektów docelowych, które muszą pozostać dostępne w dowolnym momencie, z wyłączeniem wdrożonych obiektów docelowych i określa warunki powodzenia i niepowodzenia podczas wdrażania.jobs: - deployment: VMDeploy displayName: web environment: name: <environment name> resourceType: VirtualMachine tags: <VM tag> strategy: rolling: maxParallel: 2 #for percentages, mention as x% preDeploy: steps: - download: current artifact: drop - script: echo initialize, cleanup, backup, install certs deploy: steps: - task: Bash@3 inputs: targetType: 'inline' script: | # Modify deployment script based on the app type echo "Starting deployment script run" sudo java -jar '$(Pipeline.Workspace)/drop/**/target/*.jar' routeTraffic: steps: - script: echo routing traffic postRouteTraffic: steps: - script: echo health check post-route traffic on: failure: steps: - script: echo Restore from backup! This is on failure success: steps: - script: echo Notify! This is on successPo każdym uruchomieniu tego zadania historia wdrożenia jest rejestrowana w środowisku utworzonym i zarejestrowanym w programie maszyn wirtualnych.
Uzyskiwanie dostępu do śledzenia potoku w środowisku
Widok Wdrożenia środowiska zapewnia pełną możliwość śledzenia zatwierdzeń i elementów roboczych oraz historii wdrażania między potokami dla środowiska.