Wprowadzenie do oceniania odpowiedzi w aplikacji czatu w języku Python
W tym artykule pokazano, jak ocenić odpowiedzi aplikacji czatu na zestaw poprawnych lub idealnych odpowiedzi (nazywanych prawem podstawy). Za każdym razem, gdy zmienisz aplikację czatu w sposób, który ma wpływ na odpowiedzi, uruchom ocenę, aby porównać zmiany. Ta aplikacja demonstracyjna oferuje narzędzia, których można używać dzisiaj, aby ułatwić uruchamianie ocen.
Postępując zgodnie z instrukcjami w tym artykule, wykonasz następujące czynności:
- Użyj podanych przykładowych monitów dostosowanych do domeny podmiotu. Te monity znajdują się już w repozytorium.
- Wygeneruj przykładowe pytania użytkownika i podstawowe odpowiedzi prawdy na podstawie własnych dokumentów.
- Uruchamianie ocen przy użyciu przykładowego monitu z wygenerowanymi pytaniami użytkownika.
- Przejrzyj analizę odpowiedzi.
Uwaga
W tym artykule użyto co najmniej jednego szablonu aplikacji sztucznej inteligencji jako podstawy przykładów i wskazówek w artykule. Szablony aplikacji sztucznej inteligencji zapewniają dobrze utrzymywane, łatwe w wdrażaniu implementacje referencyjne, które pomagają zapewnić wysokiej jakości punkt wyjścia dla aplikacji sztucznej inteligencji.
Omówienie architektury
Kluczowe składniki architektury obejmują:
- Aplikacja do czatu hostowana na platformie Azure: aplikacja do czatu działa w usłudze aplikacja systemu Azure Service.
- Protokół Microsoft AI Chat Protocol udostępnia standardowe kontrakty interfejsu API w rozwiązaniach i językach sztucznej inteligencji. Aplikacja do czatu jest zgodna z protokołem Microsoft AI Chat Protocol, który umożliwia uruchamianie aplikacji ewaluacyjnej względem dowolnej aplikacji czatu zgodnej z protokołem.
- Azure AI Search: aplikacja do czatu używa usługi Azure AI Search do przechowywania danych z własnych dokumentów.
- Generator przykładowych pytań: może wygenerować wiele pytań dla każdego dokumentu wraz z odpowiedzią na podstawy prawdy. Tym więcej pytań, tym dłużej ocena.
- Ewaluator uruchamia przykładowe pytania i wyświetla monity dotyczące aplikacji czatu i zwraca wyniki.
- Narzędzie do przeglądania umożliwia przeglądanie wyników ocen.
- Narzędzie różnic pozwala porównać odpowiedzi między ocenami.
Podczas wdrażania tej oceny na platformie Azure punkt końcowy usługi Azure OpenAI jest tworzony dla GPT-4 modelu z własną pojemnością. Podczas oceniania aplikacji czatu ważne jest, aby ewaluator miał własny zasób OpenAI przy użyciu GPT-4 własnej pojemności.
Wymagania wstępne
Subskrypcja platformy Azure. Utwórz bezpłatnie
Dostęp jest udzielany usłudze Azure OpenAI w żądanej subskrypcji platformy Azure. Dowiedz się więcej na https://aka.ms/oai/access.
Wykonaj poprzednią procedurę aplikacji czatu, aby wdrożyć aplikację czatu na platformie Azure. Ten zasób jest wymagany, aby aplikacja oceny działała. Nie należy ukończyć sekcji Czyszczenie zasobów w poprzedniej procedurze.
Z tego wdrożenia będą potrzebne następujące informacje o zasobach platformy Azure, które są określane jako aplikacja czatu w tym artykule:
- Identyfikator URI interfejsu API czatu: punkt końcowy zaplecza usługi wyświetlany na końcu
azd upprocesu. - Azure AI Search. Wymagane są następujące wartości:
- Nazwa zasobu: nazwa zasobu usługi Azure AI Search zgłoszona
Search servicepodczasazd upprocesu. - Nazwa indeksu: nazwa indeksu usługi Azure AI Search, w którym są przechowywane dokumenty. Można to znaleźć w witrynie Azure Portal dla usługa wyszukiwania.
- Nazwa zasobu: nazwa zasobu usługi Azure AI Search zgłoszona
Adres URL interfejsu API czatu umożliwia ewaluacjom wysyłanie żądań za pośrednictwem aplikacji zaplecza. Informacje usługi Azure AI Search umożliwiają skryptom oceny używanie tego samego wdrożenia co zaplecze załadowane z dokumentami.
Po zebraniu tych informacji nie należy ponownie używać środowiska deweloperskiego aplikacji czatu. W dalszej części tego artykułu kilka razy omówiono go, aby wskazać, jak aplikacja czatu jest używana przez aplikację Oceny. Nie usuwaj zasobów aplikacji do czatu, dopóki nie ukończysz całej procedury opisanej w tym artykule.
- Identyfikator URI interfejsu API czatu: punkt końcowy zaplecza usługi wyświetlany na końcu
Środowisko kontenera deweloperskiego jest dostępne ze wszystkimi zależnościami wymaganymi do ukończenia tego artykułu. Kontener deweloperski można uruchomić w usłudze GitHub Codespaces (w przeglądarce) lub lokalnie przy użyciu programu Visual Studio Code.
- Konto usługi GitHub
Otwieranie środowiska projektowego
Rozpocznij teraz od środowiska programistycznego, które ma zainstalowane wszystkie zależności, aby ukończyć ten artykuł. Należy rozmieścić obszar roboczy monitora, aby jednocześnie wyświetlić zarówno tę dokumentację, jak i środowisko deweloperskie.
Ten artykuł został przetestowany z regionem switzerlandnorth wdrożenia oceny.
Usługa GitHub Codespaces uruchamia kontener deweloperski zarządzany przez usługę GitHub za pomocą programu Visual Studio Code dla sieci Web jako interfejsu użytkownika. W przypadku najprostszego środowiska programistycznego użyj usługi GitHub Codespaces, aby wstępnie zainstalować odpowiednie narzędzia deweloperskie i zależności, aby ukończyć ten artykuł.
Ważne
Wszystkie konta usługi GitHub mogą korzystać z usługi Codespaces przez maksymalnie 60 godzin bezpłatnych każdego miesiąca z 2 podstawowymi wystąpieniami. Aby uzyskać więcej informacji, zobacz GitHub Codespaces monthly included storage and core hours (Miesięczne miejsca do magazynowania i godzin rdzeni usługi GitHub Codespaces).
Rozpocznij proces tworzenia nowego repozytorium GitHub Codespace
mainwAzure-Samples/ai-rag-chat-evaluatorgałęzi repozytorium GitHub.Aby wyświetlić środowisko programistyczne i dokumentację dostępną w tym samym czasie, kliknij prawym przyciskiem myszy poniższy przycisk i wybierz polecenie Otwórz link w nowym oknie.

Na stronie Tworzenie przestrzeni kodu przejrzyj ustawienia konfiguracji przestrzeni kodu, a następnie wybierz pozycję Utwórz nową przestrzeń kodu
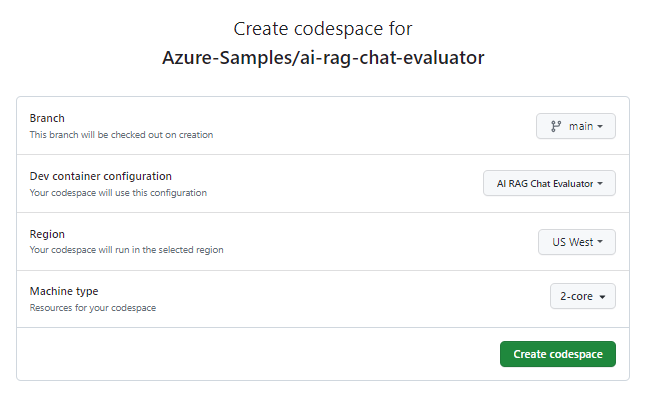
Poczekaj na uruchomienie przestrzeni kodu. Ten proces uruchamiania może potrwać kilka minut.
W terminalu w dolnej części ekranu zaloguj się do platformy Azure przy użyciu interfejsu wiersza polecenia dla deweloperów platformy Azure.
azd auth login --use-device-codeSkopiuj kod z terminalu, a następnie wklej go w przeglądarce. Postępuj zgodnie z instrukcjami, aby uwierzytelnić się przy użyciu konta platformy Azure.
Aprowizuj wymagany zasób platformy Azure, Azure OpenAI, dla aplikacji ewaluacyjnej.
azd upNie powoduje to
AZD commandwdrożenia aplikacji ewaluacyjnej, ale tworzy zasób usługi Azure OpenAI z wymaganymGPT-4wdrożeniem w celu uruchomienia ocen w lokalnym środowisku projektowym.Pozostałe zadania w tym artykule mają miejsce w kontekście tego kontenera deweloperskiego.
Nazwa repozytorium GitHub jest wyświetlana na pasku wyszukiwania. Ten wskaźnik wizualizacji pomaga odróżnić aplikację oceny od aplikacji do czatu. To
ai-rag-chat-evaluatorrepozytorium jest nazywane aplikacją Oceny w tym artykule.

Przygotowywanie wartości środowiska i informacji o konfiguracji
Zaktualizuj wartości środowiska i informacje o konfiguracji przy użyciu informacji zebranych podczas wymagań wstępnych dla aplikacji ewaluacyjnej.
.envUtwórz plik na podstawie elementu.env.sample:cp .env.sample .envUruchom następujące polecenia, aby pobrać wymagane wartości dla
AZURE_OPENAI_EVAL_DEPLOYMENTAZURE_OPENAI_SERVICEi z wdrożonej grupy zasobów i wkleić te wartości do.envpliku:azd env get-value AZURE_OPENAI_EVAL_DEPLOYMENT azd env get-value AZURE_OPENAI_SERVICEDodaj następujące wartości z aplikacji do czatu dla wystąpienia usługi Azure AI Search do
.envpliku zebranego w sekcji wymagań wstępnych :AZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>"
Informacje o konfiguracji przy użyciu protokołu Microsoft AI Chat Protocol
Aplikacja do czatów i aplikacja ewaluacyjne implementują zarówno kontrakt interfejsu Microsoft AI Chat Protocol specificationAPI punktu końcowego sztucznej inteligencji typu open source, chmury, jak i języka używane do użycia i oceny. Gdy punkty końcowe klienta i warstwy środkowej są zgodne ze specyfikacją tego interfejsu API, można konsekwentnie korzystać z zapleczy sztucznej inteligencji i uruchamiać oceny.
Utwórz nowy plik o nazwie
my_config.jsoni skopiuj do niego następującą zawartość:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "top": 3, "temperature": 0.3, "retrieval_mode": "hybrid", "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt", "seed": 1 } } }Skrypt oceny tworzy
my_resultsfolder.Obiekt
overrideszawiera wszystkie ustawienia konfiguracji wymagane dla aplikacji. Każda aplikacja definiuje własny zestaw właściwości ustawień.W poniższej tabeli przedstawiono znaczenie właściwości ustawień wysyłanych do aplikacji do czatu:
Właściwość Ustawienia opis semantic_ranker Czy używać semantycznego rangatora, modelu, który ponownie korekuje wyniki wyszukiwania na podstawie semantycznej podobieństwa do zapytania użytkownika. Wyłączyliśmy go na potrzeby tego samouczka, aby zmniejszyć koszty. retrieval_mode Tryb pobierania do użycia. Wartość domyślna to hybrid.temperature Ustawienie temperatury dla modelu. Wartość domyślna to 0.3.najpopularniejsze Liczba wyników wyszukiwania do zwrócenia. Wartość domyślna to 3.prompt_template Zastąpienie monitu użytego do wygenerowania odpowiedzi na podstawie pytania i wyników wyszukiwania. nasienie Wartość inicjatora dla wszystkich wywołań modeli GPT. Ustawienie inicjatora powoduje bardziej spójne wyniki w ocenach. target_urlZmień wartość na wartość identyfikatora URI aplikacji do czatu, która została zebrana w sekcji wymagań wstępnych. Aplikacja do czatu musi być zgodna z protokołem czatu. Identyfikator URI ma następujący formathttps://CHAT-APP-URL/chat. Upewnij się, że protokół ichattrasa są częścią identyfikatora URI.
Generowanie danych przykładowych
Aby ocenić nowe odpowiedzi, muszą być porównywane z odpowiedzią "podstawy prawdy", która jest idealną odpowiedzią na konkretne pytanie. Wygeneruj pytania i odpowiedzi na podstawie dokumentów przechowywanych w usłudze Azure AI Search dla aplikacji do czatu.
example_inputSkopiuj folder do nowego folderu o nazwiemy_input.W terminalu uruchom następujące polecenie, aby wygenerować przykładowe dane:
python -m evaltools generate --output=my_input/qa.jsonl --persource=2 --numquestions=14
Pary pytań/odpowiedzi są generowane i przechowywane w my_input/qa.jsonl formacie (w formacie JSONL) jako dane wejściowe dla ewaluatora używanego w następnym kroku. W przypadku oceny produkcyjnej wygenerujesz więcej par QA, ponad 200 dla tego zestawu danych.
Uwaga
Liczba pytań i odpowiedzi na źródło jest przeznaczona do szybkiego wykonania tej procedury. Nie jest przeznaczona do oceny produkcyjnej, która powinna mieć więcej pytań i odpowiedzi na źródło.
Uruchamianie pierwszej oceny przy użyciu uściślinego monitu
my_config.jsonEdytuj właściwości pliku konfiguracji:Właściwości Nowa wartość results_dir my_results/experiment_refinedprompt_template <READFILE>my_input/prompt_refined.txtUściśliny monit jest specyficzny dla domeny podmiotu.
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by colon and the actual information, always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].W terminalu uruchom następujące polecenie, aby uruchomić ocenę:
python -m evaltools evaluate --config=my_config.json --numquestions=14Ten skrypt utworzył nowy folder eksperymentu w programie
my_results/z oceną. Folder zawiera wyniki oceny, w tym:Nazwa pliku opis config.jsonKopia pliku konfiguracji używanego do oceny. evaluate_parameters.jsonParametry używane do oceny. Bardzo podobne do config.json, ale zawiera dodatkowe metadane, takie jak sygnatura czasowa.eval_results.jsonlKażde pytanie i odpowiedź wraz z metrykami GPT dla każdej pary KONTROLI jakości. summary.jsonOgólne wyniki, takie jak średnie metryki GPT.
Uruchamianie drugiej oceny przy użyciu słabego monitu
my_config.jsonEdytuj właściwości pliku konfiguracji:Właściwości Nowa wartość results_dir my_results/experiment_weakprompt_template <READFILE>my_input/prompt_weak.txtTen słaby monit nie ma kontekstu dotyczącego domeny podmiotu:
You are a helpful assistant.W terminalu uruchom następujące polecenie, aby uruchomić ocenę:
python -m evaltools evaluate --config=my_config.json --numquestions=14
Uruchamianie trzeciej oceny z określoną temperaturą
Użyj monitu, który pozwala na większą kreatywność.
my_config.jsonEdytuj właściwości pliku konfiguracji:Istniejący Właściwości Nowa wartość Istniejący results_dir my_results/experiment_ignoresources_temp09Istniejący prompt_template <READFILE>my_input/prompt_ignoresources.txtNowe temperature 0.9Wartość domyślna
temperatureto 0,7. Im wyższa temperatura, tym bardziej kreatywne odpowiedzi.Monit
ignorejest krótki:Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!Obiekt konfiguracji powinien wyglądać podobnie do następującego z wyjątkiem zastąpić
results_dirścieżką:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/prompt_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }W terminalu uruchom następujące polecenie, aby uruchomić ocenę:
python -m evaltools evaluate --config=my_config.json --numquestions=14
Przejrzenie wyników oceny
Wykonano trzy oceny na podstawie różnych monitów i ustawień aplikacji. Wyniki są przechowywane w folderze my_results . Sprawdź, jak wyniki różnią się w zależności od ustawień.
Użyj narzędzia do przeglądu, aby wyświetlić wyniki ocen:
python -m evaltools summary my_resultsWyniki wyglądają mniej więcej tak:

Każda wartość jest zwracana jako liczba i wartość procentowa.
Skorzystaj z poniższej tabeli, aby zrozumieć znaczenie wartości.
Wartość Opis Uziemienie Odnosi się to do tego, jak dobrze odpowiedzi modelu są oparte na rzeczywistych, weryfikowalnych informacjach. Odpowiedź jest uważana za uziemioną, jeśli jest ona faktycznie dokładna i odzwierciedla rzeczywistość. Stopień zgodności Mierzy to, jak ściśle odpowiedzi modelu są zgodne z kontekstem lub monitem. Odpowiednia odpowiedź bezpośrednio odpowiada na zapytanie lub instrukcję użytkownika. Spójności Odnosi się to do tego, jak logicznie spójne są odpowiedzi modelu. Spójna odpowiedź utrzymuje przepływ logiczny i nie zaprzecza samemu sobie. Odsyłacz bibliograficzny Wskazuje to, czy odpowiedź została zwrócona w formacie żądanym w wierszu polecenia. Długość Mierzy długość odpowiedzi. Wyniki powinny wskazywać, że wszystkie trzy oceny miały duże znaczenie, podczas gdy
experiment_ignoresources_temp09miało najniższe znaczenie.Wybierz folder, aby wyświetlić konfigurację oceny.
Naciśnij Ctrl + C, aby zamknąć aplikację i wrócić do terminalu.
Porównanie odpowiedzi
Porównaj zwrócone odpowiedzi z ocen.
Wybierz dwie oceny do porównania, a następnie użyj tego samego narzędzia do przeglądu, aby porównać odpowiedzi:
python -m evaltools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09Przejrzyj wyniki. Wyniki mogą się różnić.

Naciśnij Ctrl + C, aby zamknąć aplikację i wrócić do terminalu.
Sugestie dotyczące dalszych ocen
- Zmodyfikuj monity,
my_inputaby dostosować odpowiedzi, takie jak domena podmiotu, długość i inne czynniki. - Zmodyfikuj plik,
my_config.jsonaby zmienić parametry, takie jaktemperature, isemantic_rankerponownie uruchomić eksperymenty. - Porównaj różne odpowiedzi, aby zrozumieć, jak monit i pytanie wpływają na jakość odpowiedzi.
- Wygeneruj oddzielny zestaw pytań i odpowiedzi na podstawowe informacje dla każdego dokumentu w indeksie usługi Azure AI Search . Następnie ponownie uruchom oceny, aby zobaczyć, jak różnią się odpowiedzi.
- Zmień monity, aby wskazać krótsze lub dłuższe odpowiedzi, dodając wymaganie na końcu monitu. Na przykład
Please answer in about 3 sentences..
Czyszczenie zasobów i zależności
Czyszczenie zasobów platformy Azure
Zasoby platformy Azure utworzone w tym artykule są rozliczane z subskrypcją platformy Azure. Jeśli nie spodziewasz się, że te zasoby będą potrzebne w przyszłości, usuń je, aby uniknąć naliczania dodatkowych opłat.
Aby usunąć zasoby platformy Azure i usunąć kod źródłowy, uruchom następujące polecenie interfejsu wiersza polecenia dla deweloperów platformy Azure:
azd down --purge
Czyszczenie usługi GitHub Codespaces
Usunięcie środowiska Usługi GitHub Codespaces gwarantuje, że możesz zmaksymalizować ilość bezpłatnych godzin na godziny korzystania z konta.
Ważne
Aby uzyskać więcej informacji na temat uprawnień konta usługi GitHub, zobacz Artykuł GitHub Codespaces monthly included storage and core hours (Miesięczne miejsca do magazynowania i godzin rdzeni w usłudze GitHub).
Zaloguj się do pulpitu nawigacyjnego usługi GitHub Codespaces (https://github.com/codespaces).
Znajdź aktualnie uruchomione środowisko Codespaces pochodzące z
Azure-Samples/ai-rag-chat-evaluatorrepozytorium GitHub.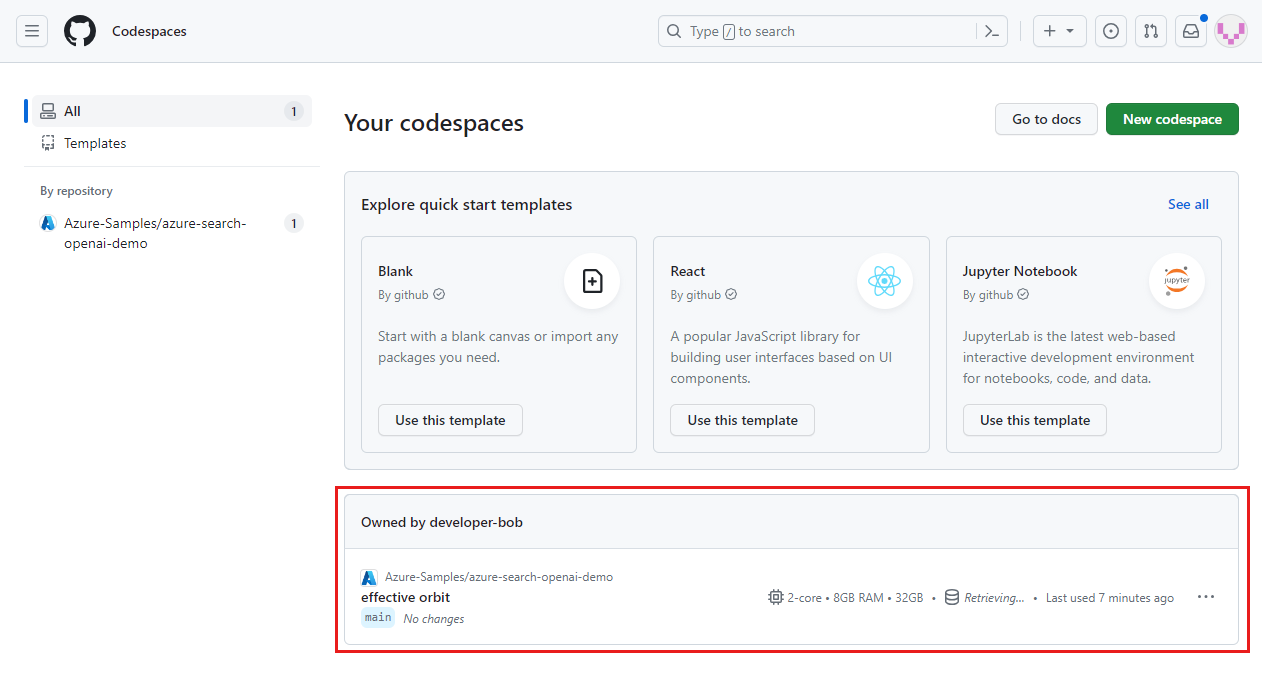
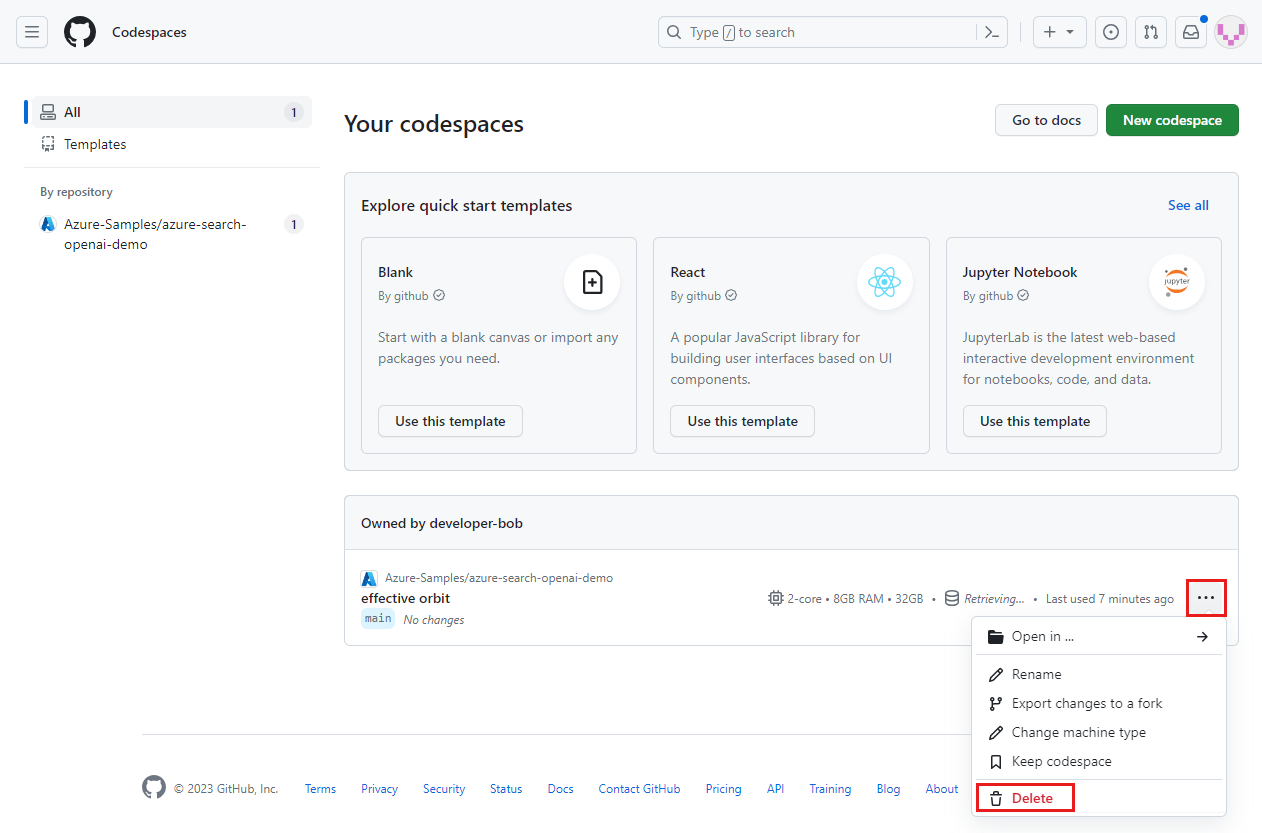
Otwórz menu kontekstowe dla przestrzeni kodu, a następnie wybierz pozycję Usuń.
Wróć do artykułu aplikacji czatu, aby wyczyścić te zasoby.
Następne kroki
- Repozytorium ocen
- Repozytorium GitHub aplikacji do czatów dla przedsiębiorstw
- Tworzenie aplikacji do czatu przy użyciu architektury rozwiązania najlepszych rozwiązań usługi Azure OpenAI
- Kontrola dostępu w aplikacjach generacyjnych sztucznej inteligencji za pomocą usługi Azure AI Search
- Tworzenie gotowego do użycia rozwiązania OpenAI dla przedsiębiorstw za pomocą usługi Azure API Management
- Wyszukiwanie wektorów przewyższających przy użyciu funkcji pobierania hybrydowego i klasyfikowania