Samouczek: migrowanie serwera aplikacji WebSphere do usługi Azure Virtual Machines z wysoką dostępnością i odzyskiwaniem po awarii
W tym samouczku przedstawiono prosty i skuteczny sposób implementowania wysokiej dostępności i odzyskiwania po awarii (HA/DR) dla języka Java przy użyciu serwera aplikacji WebSphere na maszynach wirtualnych platformy Azure. Rozwiązanie ilustruje sposób osiągnięcia niskiego celu czasu odzyskiwania (RTO) i celu punktu odzyskiwania (RPO) przy użyciu prostej opartej na bazie danych aplikacji Jakarta EE działającej na serwerze aplikacji WebSphere. Wysoka dostępność/odzyskiwanie po awarii to złożony temat z wieloma możliwymi rozwiązaniami. Najlepsze rozwiązanie zależy od unikatowych wymagań. Aby uzyskać inne sposoby implementowania wysokiej dostępności/odzyskiwania po awarii, zobacz zasoby na końcu tego artykułu.
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Użyj najlepszych rozwiązań zoptymalizowanych pod kątem platformy Azure, aby uzyskać wysoką dostępność i odzyskiwanie po awarii.
- Skonfiguruj grupę trybu failover usługi Microsoft Azure SQL Database w sparowanych regionach.
- Skonfiguruj podstawowy klaster WebSphere na maszynach wirtualnych platformy Azure.
- Konfigurowanie odzyskiwania po awarii dla klastra przy użyciu usługi Azure Site Recovery.
- Konfigurowanie usługi Azure Traffic Manager.
- Przetestuj tryb failover z podstawowego do pomocniczego.
Na poniższym diagramie przedstawiono utworzoną architekturę:

Usługa Azure Traffic Manager sprawdza kondycję regionów i kieruje ruch odpowiednio do warstwy aplikacji. Region podstawowy ma pełne wdrożenie klastra WebSphere. Gdy region podstawowy jest chroniony przez usługę Azure Site Recovery, możesz przywrócić region pomocniczy podczas pracy w trybie failover. W związku z tym region podstawowy aktywnie obsługuje żądania sieciowe od użytkowników, podczas gdy region pomocniczy jest pasywny i aktywowany w celu odbierania ruchu tylko wtedy, gdy region podstawowy doświadcza przerw w działaniu usługi.
Usługa Azure Traffic Manager wykrywa kondycję aplikacji wdrożonej na serwerze HTTP IBM w celu zaimplementowania routingu warunkowego. Cel czasu odzyskiwania geograficznego trybu failover warstwy aplikacji zależy od czasu zamknięcia klastra podstawowego, przywrócenia klastra pomocniczego, uruchomienia maszyn wirtualnych i uruchomienia pomocniczego klastra WebSphere. Cel punktu odzyskiwania zależy od zasad replikacji usług Azure Site Recovery i Azure SQL Database. Ta zależność jest taka, ponieważ dane klastra są przechowywane i replikowane w lokalnym magazynie maszyn wirtualnych, a dane aplikacji są utrwalane i replikowane w grupie trybu failover usługi Azure SQL Database.
Na powyższym diagramie przedstawiono region podstawowy i region pomocniczy jako dwa regiony składające się z architektury wysokiej dostępności/odzyskiwania po awarii. Te regiony muszą być sparowane z platformą Azure. Aby uzyskać więcej informacji na temat sparowanych regionów, zobacz Replikacja między regionami platformy Azure. W artykule użyto regionów Wschodnie stany USA i Zachodnie stany USA jako dwa regiony, ale mogą to być wszystkie sparowane regiony, które mają sens w danym scenariuszu. Aby uzyskać listę par regionów, zobacz sekcję Regiony sparowane platformy Azure w ramach replikacji między regionami platformy Azure.
Warstwa bazy danych składa się z grupy trybu failover usługi Azure SQL Database z serwerem podstawowym i serwerem pomocniczym. Punkt końcowy odbiornika odczytu/zapisu zawsze wskazuje serwer podstawowy i jest połączony z klastrem WebSphere w każdym regionie. Tryb failover geograficznego przełącza wszystkie pomocnicze bazy danych w grupie na rolę podstawową. Aby uzyskać informacje na temat celu punktu odzyskiwania w trybie failover i celu punktu odzyskiwania usługi Azure SQL Database, zobacz Overview of business continuity with Azure SQL Database (Omówienie ciągłości działania w usłudze Azure SQL Database).
Ten samouczek został napisany za pomocą usługi Azure Site Recovery i usługi Azure SQL Database, ponieważ samouczek opiera się na funkcjach wysokiej dostępności tych usług. Inne opcje bazy danych są możliwe, ale należy wziąć pod uwagę funkcje wysokiej dostępności dowolnej wybranej bazy danych.
Wymagania wstępne
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
- Upewnij się, że masz
Contributorrolę w subskrypcji. Przypisanie można sprawdzić, wykonując kroki opisane w temacie Wyświetlanie listy przypisań ról platformy Azure przy użyciu witryny Azure Portal. - Przygotuj maszynę lokalną z zainstalowanym systemem Windows, Linux lub macOS.
- Instalowanie i konfigurowanie usługi Git.
- Zainstaluj implementację środowiska Java SE w wersji 17 lub nowszej — na przykład kompilację microsoft openJDK.
- Zainstaluj program Maven w wersji 3.9.3 lub nowszej.
Konfigurowanie grupy trybu failover usługi Azure SQL Database w sparowanych regionach
W tej sekcji utworzysz grupę trybu failover usługi Azure SQL Database w sparowanych regionach do użycia z klastrami i aplikacjami WebSphere. W późniejszej sekcji skonfigurujesz składnik WebSphere do przechowywania danych sesji w tej bazie danych. Ta praktyka odwołuje się do tworzenia tabeli dla trwałości sesji.
Najpierw utwórz podstawową bazę danych Azure SQL Database, wykonując kroki w witrynie Azure Portal w przewodniku Szybki start: Tworzenie pojedynczej bazy danych — Azure SQL Database. Wykonaj kroki, które należy wykonać, ale nie uwzględniaj sekcji "Czyszczenie zasobów". Podczas pracy z artykułem skorzystaj z poniższych wskazówek, a następnie wróć do tego artykułu po utworzeniu i skonfigurowaniu bazy danych Azure SQL Database:
Po dotarciu do sekcji Tworzenie pojedynczej bazy danych wykonaj następujące kroki:
- W kroku 4 tworzenia nowej grupy zasobów zapisz wartość nazwy grupy zasobów — na przykład
myResourceGroup. - W kroku 5 dla nazwy bazy danych zapisz wartość Nazwa bazy danych — na przykład
mySampleDatabase. - W kroku 6 tworzenia serwera wykonaj następujące kroki:
- Wypełnij unikatową nazwę serwera — na przykład
sqlserverprimary-mjg022624. - W polu Lokalizacja wybierz pozycję (STANY USA) Wschodnie stany USA.
- W polu Metoda uwierzytelniania wybierz pozycję Użyj uwierzytelniania SQL.
-
Zapisz wartość logowania administratora serwera — na przykład
azureuser. - Zapisz wartość Password ( Hasło ).
- Wypełnij unikatową nazwę serwera — na przykład
- W kroku 8 w polu Środowisko obciążenia wybierz pozycję Programowanie. Przyjrzyj się opisowi i rozważ inne opcje obciążenia.
- W kroku 11 w polu Nadmiarowość magazynu kopii zapasowych wybierz pozycję Magazyn kopii zapasowych lokalnie nadmiarowy. Rozważ inne opcje tworzenia kopii zapasowych. Aby uzyskać więcej informacji, zobacz sekcję Nadmiarowość magazynu kopii zapasowych w usłudze Azure SQL Database.
- W kroku 14 w konfiguracji reguł zapory dla pozycji Zezwalaj usługom i zasobom platformy Azure na dostęp do tego serwera wybierz pozycję Tak.
- W kroku 4 tworzenia nowej grupy zasobów zapisz wartość nazwy grupy zasobów — na przykład
Gdy dotrzesz do sekcji Wykonywanie zapytań dotyczących bazy danych, wykonaj następujące kroki:
W kroku 3 wprowadź informacje logowania administratora serwera uwierzytelniania SQL, aby się zalogować.
Uwaga
Jeśli logowanie nie powiedzie się z komunikatem o błędzie podobnym do klienta z adresem IP "xx.xx.xx.xx.xx" nie może uzyskać dostępu do serwera, wybierz pozycję Allowlist IP xx.xx.xx.xx na serwerze <nazwa-serwera-sql na> końcu komunikatu o błędzie. Poczekaj, aż reguły zapory serwera zakończą aktualizowanie, a następnie ponownie wybierz przycisk OK .
Po uruchomieniu przykładowego zapytania w kroku 5 wyczyść edytor i wprowadź następujące zapytanie, a następnie wybierz pozycję Uruchom ponownie:
CREATE TABLE sessions ( ID VARCHAR(128) NOT NULL, PROPID VARCHAR(128) NOT NULL, APPNAME VARCHAR(128) NOT NULL, LISTENERCNT SMALLINT, LASTACCESS BIGINT, CREATIONTIME BIGINT, MAXINACTIVETIME INT, USERNAME VARCHAR(256), SMALL VARBINARY(MAX), MEDIUM VARCHAR(MAX), LARGE VARBINARY(MAX) );Po pomyślnym uruchomieniu powinien zostać wyświetlony komunikat Zapytanie powiodło się: wiersze, których dotyczy problem: 0.
Tabela
sessionsbazy danych służy do przechowywania danych sesji dla aplikacji WebSphere. Dane klastra WebSphere, w tym dzienniki transakcji, są utrwalane w lokalnym magazynie maszyn wirtualnych, na których jest wdrażany klaster.
Następnie utwórz grupę trybu failover usługi Azure SQL Database, wykonując kroki opisane w temacie Konfigurowanie grupy trybu failover dla usługi Azure SQL Database. Potrzebne są tylko następujące sekcje: Tworzenie grupy trybu failover i Testowanie planowanego przejścia w tryb failover. Wykonaj następujące kroki, wykonując czynności opisane w artykule, a następnie wróć do tego artykułu po utworzeniu i skonfigurowaniu grupy trybu failover usługi Azure SQL Database:
W sekcji Tworzenie grupy trybu failover wykonaj następujące czynności:
- W kroku 5 tworzenia grupy trybu failover wprowadź i zapisz unikatową nazwę grupy trybu failover — na przykład
failovergroup-mjg022624. - W kroku 5 konfigurowania serwera wybierz opcję utworzenia nowego serwera pomocniczego, a następnie wykonaj następujące czynności:
- Wprowadź unikatową nazwę serwera — na przykład
sqlserversecondary-mjg022624. - Wprowadź ten sam administrator serwera i hasło co serwer podstawowy.
- W polu Lokalizacja wybierz pozycję (STANY USA) Zachodnie stany USA.
- Upewnij się, że wybrano opcję Zezwalaj usługom platformy Azure na dostęp do serwera .
- Wprowadź unikatową nazwę serwera — na przykład
- W kroku 5 na potrzeby konfigurowania baz danych w grupie wybierz bazę danych utworzoną na serwerze podstawowym — na przykład
mySampleDatabase.
- W kroku 5 tworzenia grupy trybu failover wprowadź i zapisz unikatową nazwę grupy trybu failover — na przykład
Po wykonaniu wszystkich kroków w sekcji Testowanie planowanego trybu failover pozostaw otwartą stronę grupy trybu failover i użyj jej do testowania trybu failover klastrów WebSphere później.
Uwaga
Ten artykuł zawiera instrukcje tworzenia pojedynczej bazy danych usługi Azure SQL Database z uwierzytelnianiem SQL. Bezpieczniejszą praktyką jest użycie uwierzytelniania microsoft Entra dla usługi Azure SQL do uwierzytelniania połączenia serwera bazy danych. Uwierzytelnianie SQL jest wymagane, aby klaster WebSphere łączył się z bazą danych na potrzeby trwałości sesji później. Aby uzyskać więcej informacji, zobacz Konfigurowanie trwałości sesji bazy danych.
Konfigurowanie podstawowego klastra WebSphere na maszynach wirtualnych platformy Azure
W tej sekcji utworzysz podstawowe klastry WebSphere na maszynach wirtualnych platformy Azure przy użyciu oferty IBM WebSphere Application Server Server na maszynach wirtualnych platformy Azure. Klaster pomocniczy zostanie przywrócony z klastra podstawowego podczas pracy w trybie failover przy użyciu usługi Azure Site Recovery później.
Wdrażanie podstawowego klastra WebSphere
Najpierw otwórz ofertę IBM WebSphere Application Server Cluster on Azure VMs (Klaster serwera aplikacji IBM WebSphere na maszynach wirtualnych platformy Azure) w przeglądarce i wybierz pozycję Utwórz. Powinno zostać wyświetlone okienko Podstawy oferty.
Aby wypełnić okienko Podstawy , wykonaj następujące kroki:
- Upewnij się, że wartość wyświetlana dla subskrypcji jest taka sama, która ma role wymienione w sekcji wymagań wstępnych.
-
W polu Grupa zasobów wybierz pozycję Utwórz nową i wprowadź unikatową wartość dla grupy zasobów — na przykład
was-cluster-eastus-mjg022624. - W obszarze Szczegóły wystąpienia w obszarze Region wybierz pozycję Wschodnie stany USA.
- W obszarze Wdróż przy użyciu istniejącego uprawnienia webSphere lub licencji ewaluacyjnej?, wybierz pozycję Ocena dla tego samouczka. Możesz również wybrać pozycję Uprawniony i podać swoje poświadczenie IBMid.
- Wybierz pozycję Czytałem i akceptuję umowę licencyjną IBM.
- Pozostaw wartości domyślne dla innych pól.
- Wybierz przycisk Dalej , aby przejść do okienka Konfiguracja klastra.

Aby wypełnić okienko Konfiguracja klastra, wykonaj następujące kroki:
- W polu Hasło dla administratora maszyny wirtualnej podaj hasło. Aby uzyskać lepsze zabezpieczenia, rozważ użycie klucza publicznego SSH jako typu uwierzytelniania maszyny wirtualnej.
- W polu Hasło dla administratora WebSphere podaj hasło. Zapisz nazwę użytkownika i hasło dla administratora WebSphere.
- Pozostaw wartości domyślne dla innych pól.
- Wybierz pozycję Dalej, aby przejść do okienka Moduł równoważenia obciążenia.

Aby wypełnić okienko modułu równoważenia obciążenia, wykonaj następujące czynności:
- W polu Hasło dla administratora maszyny wirtualnej podaj hasło. Aby uzyskać lepsze zabezpieczenia, rozważ użycie klucza publicznego SSH jako uwierzytelniania maszyny wirtualnej.
- W polu Password for IBM HTTP Server administrator (Hasło dla administratora serwera HTTP IBM) podaj hasło.
- Pozostaw wartości domyślne dla innych pól.
- Wybierz przycisk Dalej , aby przejść do okienka Sieć .

Wszystkie pola powinny być wstępnie wypełnione wartościami domyślnymi w okienku Sieć . Wybierz przycisk Dalej , aby przejść do okienka Baza danych .

W poniższych krokach pokazano, jak wypełnić okienko Baza danych :
- W obszarze Połącz z bazą danych? wybierz pozycję Tak.
- W obszarze Wybierz typ bazy danych wybierz pozycję Microsoft SQL Server .
- W polu Nazwa JNDI wprowadź wartość jdbc/WebSphereCafeDB.
- W przypadku parametry połączenia źródła danych (jdbc:sqlserver://<host>:<port>; database=<database>), zastąp symbole zastępcze wartościami zapisanymi w poprzedniej sekcji dla grupy trybu failover dla usługi Azure SQL Database — na przykład
jdbc:sqlserver://failovergroup-mjg022624.database.windows.net:1433;database=mySampleDatabase. - W polu Nazwa użytkownika bazy danych wprowadź nazwę logowania administratora serwera i nazwę grupy trybu failover zapisaną w poprzedniej sekcji — na przykład
azureuser@failovergroup-mjg022624.Uwaga
Należy zachować ostrożność, używając poprawnej nazwy hosta serwera bazy danych i nazwy użytkownika bazy danych dla grupy trybu failover, zamiast nazwy hosta serwera i nazwy użytkownika z podstawowej bazy danych lub bazy danych kopii zapasowej. Używając wartości z grupy trybu failover, w efekcie informujesz aplikację WebSphere o rozmowie z grupą trybu failover. Jednak jeśli chodzi o websphere, to tylko normalne połączenie z bazą danych.
- Wprowadź hasło logowania administratora serwera zapisane wcześniej w polu Hasło bazy danych. Wprowadź tę samą wartość w polu Potwierdź hasło.
- Pozostaw wartości domyślne dla innych pól.
- Wybierz pozycję Przejrzyj i utwórz.
- Poczekaj na pomyślne zakończenie ostatniej weryfikacji, a następnie wybierz pozycję Utwórz.

Uwaga
Ten artykuł zawiera instrukcje dotyczące nawiązywania połączenia z usługą Azure SQL Database przy użyciu uwierzytelniania SQL. Bezpieczniejszą praktyką jest użycie uwierzytelniania microsoft Entra dla usługi Azure SQL do uwierzytelniania połączenia serwera bazy danych. Uwierzytelnianie SQL jest wymagane, aby klaster WebSphere łączył się z bazą danych na potrzeby trwałości sesji później. Aby uzyskać więcej informacji, zobacz Konfigurowanie trwałości sesji bazy danych.
Po pewnym czasie powinna zostać wyświetlona strona Wdrażanie , na której jest w toku wdrażanie.
Uwaga
Jeśli podczas ostatecznej weryfikacji wystąpią jakiekolwiek problemy, rozwiąż je i spróbuj ponownie.
W zależności od warunków sieciowych i innych działań w wybranym regionie wdrożenie może potrwać do 25 minut. Następnie powinien zostać wyświetlony tekst Wdrożenie zostało ukończone na stronie wdrożenia.
Weryfikowanie wdrożenia klastra
Wdrożono serwer IBM HTTP Server (IHS) i program WebSphere Deployment Manager (Dmgr) w klastrze. Usługa IHS działa jako moduł równoważenia obciążenia dla wszystkich serwerów aplikacji w klastrze. Program Dmgr udostępnia konsolę internetową na potrzeby konfiguracji klastra.
Wykonaj następujące kroki, aby sprawdzić, czy konsola IHS i Dmgr działa przed przejściem do następnego kroku:
Wróć do strony Wdrożenie , a następnie wybierz pozycję Dane wyjściowe.
Skopiuj wartość właściwości ihsConsole. Otwórz ten adres URL na nowej karcie przeglądarki. Pamiętaj, że w tym przykładzie nie używamy
httpsfunkcji IHS. Powinna zostać wyświetlona strona powitalna IHS bez żadnego komunikatu o błędzie. Jeśli tego nie zrobisz, przed kontynuowaniem musisz rozwiązać problem i rozwiązać go. Pozostaw konsolę otwartą i użyj jej do późniejszego zweryfikowania wdrożenia aplikacji klastra.
Skopiuj i zapisz wartość właściwości adminSecuredConsole. Otwórz go na nowej karcie przeglądarki. Zaakceptuj ostrzeżenie przeglądarki dotyczące certyfikatu TLS z podpisem własnym. Nie należy przechodzić do środowiska produkcyjnego przy użyciu certyfikatu TLS z podpisem własnym.
Powinna zostać wyświetlona strona logowania konsoli rozwiązania zintegrowanego WebSphere. Zaloguj się do konsoli przy użyciu nazwy użytkownika i hasła dla administratora WebSphere zapisanego wcześniej. Jeśli nie możesz się zalogować, przed kontynuowaniem musisz rozwiązać problem i rozwiązać ten problem. Pozostaw konsolę otwartą i użyj jej do dalszej konfiguracji klastra WebSphere później.

Wykonaj poniższe kroki, aby uzyskać nazwę publicznego adresu IP IHS. Używasz go podczas konfigurowania usługi Azure Traffic Manager później.
- Otwórz grupę zasobów, w której wdrożono klaster — na przykład wybierz pozycję Przegląd , aby wrócić do okienka Przegląd strony wdrożenia, a następnie wybierz pozycję Przejdź do grupy zasobów.
- W tabeli zasobów znajdź kolumnę Typ . Wybierz ją, aby sortować według typu zasobu.
-
Znajdź zasób Publicznego adresu IP poprzedzony prefiksem
ihs, a następnie skopiuj i zapisz jego nazwę.
Skonfiguruj klaster
Najpierw wykonaj następujące kroki, aby włączyć opcję Synchronizuj zmiany z węzłami , aby dowolna konfiguracja mogła być automatycznie synchronizowana ze wszystkimi serwerami aplikacji:
- Wróć do konsoli rozwiązania zintegrowanego webSphere i zaloguj się ponownie, jeśli się wylogowasz.
- W okienku nawigacji wybierz pozycję Preferencje konsoli administracyjnej>systemu.
- W okienku Preferencje konsoli wybierz pozycję Synchronizuj zmiany z węzłami, a następnie wybierz pozycję Zastosuj. Powinien zostać wyświetlony komunikat Twoje preferencje zostały zmienione.
Następnie wykonaj następujące kroki, aby skonfigurować sesje rozproszone bazy danych dla wszystkich serwerów aplikacji:
- W okienku nawigacji wybierz pozycję aplikacji.
- W okienku Serwery aplikacji powinien zostać wyświetlonych 3 serwery aplikacji. Dla każdego serwera aplikacji skorzystaj z poniższych instrukcji, aby skonfigurować sesje rozproszone bazy danych:
- W tabeli pod tekstem Możesz administrować następującymi zasobami, wybierz hiperlink serwera aplikacji, który zaczyna się od
MyCluster. - W sekcji Ustawienia kontenera wybierz pozycję Zarządzanie sesjami.
- W sekcji Dodatkowe właściwości wybierz pozycję Ustawienia środowiska rozproszonego.
- W obszarze Sesje rozproszone wybierz pozycję Baza danych (obsługiwana tylko dla kontenera sieci Web).
- Wybierz pozycję Baza danych i wykonaj następujące kroki:
- W polu Nazwa JNDI źródła danych wprowadź wartość jdbc/WebSphereCafeDB.
- W polu Identyfikator użytkownika wprowadź nazwę logowania administratora serwera i nazwę grupy trybu failover zapisaną w poprzedniej sekcji — na przykład
azureuser@failovergroup-mjg022624. - Wypełnij hasło logowania administratora programu Azure SQL Server zapisane wcześniej w polu Hasło.
- W polu Nazwa obszaru tabeli wprowadź sesje.
- Wybierz pozycję Użyj schematu z wieloma wierszami.
- Wybierz przycisk OK. Wróć do okienka Ustawienia środowiska rozproszonego.
- W sekcji Dodatkowe właściwości wybierz pozycję Parametry dostrajania niestandardowego.
- W obszarze Poziom dostrajania wybierz pozycję Niski (optymalizuj pod kątem trybu failover).
- Wybierz przycisk OK.
- W obszarze Wiadomości wybierz pozycję Zapisz. Zaczekaj na zakończenie.
- Wybierz pozycję Serwery aplikacji na górnym pasku nadrzędnym. Zostanie przekierowany z powrotem do okienka Serwery aplikacji.
- W tabeli pod tekstem Możesz administrować następującymi zasobami, wybierz hiperlink serwera aplikacji, który zaczyna się od
- W okienku nawigacji wybierz pozycję Serwery>> aplikacji WebSphere.
- W okienku Klastry serwerów aplikacji WebSphere powinien zostać wyświetlony klaster
MyCluster. Zaznacz pole wyboru obok pozycji MyCluster. - Wybierz pozycję Ripplestart.
- Poczekaj na ponowne uruchomienie klastra. Możesz wybrać ikonę Stan , a jeśli nowe okno nie zawiera pozycji Uruchomiono, wróć do konsoli i odśwież stronę internetową po pewnym czasie. Powtarzaj operację do momentu wyświetlenia komunikatu Rozpoczęto. Przed dotarciem do stanu Rozpoczęto może zostać wyświetlony komunikat Początek częściowy
Pozostaw konsolę otwartą i użyj jej do późniejszego wdrożenia aplikacji.
Wdrażanie przykładowej aplikacji
W tej sekcji pokazano, jak wdrożyć i uruchomić przykładową aplikację CRUD Java/Jakarta EE w klastrze WebSphere na potrzeby testowania trybu failover odzyskiwania po awarii później.
Serwery aplikacji zostały skonfigurowane do używania źródła jdbc/WebSphereCafeDB danych do przechowywania wcześniej danych sesji, co umożliwia przechodzenie w tryb failover i równoważenie obciążenia w klastrze serwerów aplikacji WebSphere. Przykładowa aplikacja konfiguruje również schemat trwałości w celu utrwalania danych coffee aplikacji w tym samym źródle jdbc/WebSphereCafeDBdanych.
Najpierw użyj następujących poleceń, aby pobrać, skompilować i spakować przykład:
git clone https://github.com/Azure-Samples/websphere-cafe
cd websphere-cafe
git checkout 20240326
mvn clean package
Jeśli zostanie wyświetlony komunikat o stanie Detached HEAD , ten komunikat jest bezpieczny do zignorowania.
Pakiet powinien zostać pomyślnie wygenerowany i zlokalizowany w <lokalizacji parent-path-to-your-local-clone>/websphere-café/websphere-café-application/target/websphere-café.ear. Jeśli nie widzisz pakietu, przed kontynuowaniem musisz rozwiązać problem i rozwiązać ten problem.
Następnie wykonaj następujące kroki, aby wdrożyć przykładową aplikację w klastrze:
- Wróć do konsoli rozwiązania zintegrowanego webSphere i zaloguj się ponownie, jeśli się wylogowasz.
- W okienku nawigacji wybierz pozycję >>
- W okienku Aplikacje dla przedsiębiorstw wybierz pozycję Zainstaluj>wybierz pozycję Wybierz plik. Następnie znajdź pakiet znajdujący się w <folderze parent-path-to-your-local-clone>/websphere-café/websphere-café-application/target/websphere-café.ear i wybierz pozycję Otwórz. Wybierz przycisk Dalej>Dalej.>
- W okienku Mapuj moduły na serwery naciśnij Ctrl i zaznacz wszystkie elementy wymienione w obszarze Klastry i serwery. Zaznacz pole wyboru obok pliku websphere-café.war. Wybierz Zastosuj. Wybierz przycisk Dalej , dopóki nie zostanie wyświetlony przycisk Zakończ .
- Wybierz pozycję Zakończ>zapisz, a następnie zaczekaj na ukończenie. Wybierz przycisk OK.
- Wybierz zainstalowaną aplikację
websphere-cafe, a następnie wybierz pozycję Uruchom. Poczekaj, aż zobaczysz komunikaty wskazujące, że aplikacja została pomyślnie uruchomiona. Jeśli nie widzisz pomyślnego komunikatu, przed kontynuowaniem musisz rozwiązać problem i rozwiązać ten problem.
Teraz wykonaj następujące kroki, aby sprawdzić, czy aplikacja działa zgodnie z oczekiwaniami:
Wróć do konsoli IHS. Dołącz katalog główny
/websphere-cafe/kontekstu wdrożonej aplikacji na pasku adresu — na przykładhttp://ihs70685e.eastus.cloudapp.azure.com/websphere-cafe/, a następnie naciśnij Enter. Powinna zostać wyświetlona strona powitalna przykładowej aplikacji.Utwórz nową kawę o nazwie i cenie — na przykład Kawa 1 z ceną $10 — która jest utrwalana zarówno w tabeli danych aplikacji, jak i w tabeli sesji bazy danych. Widoczny interfejs użytkownika powinien być podobny do poniższego zrzutu ekranu:
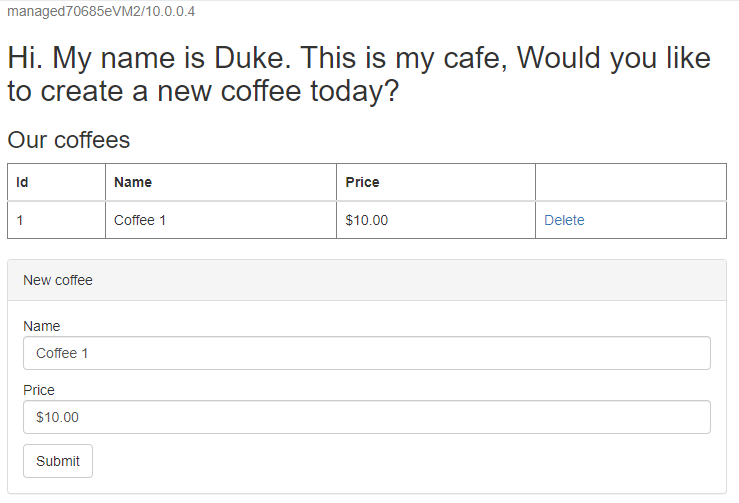

Jeśli interfejs użytkownika nie wygląda podobnie, rozwiąż problem i rozwiąż problem, który będziesz kontynuować.
Konfigurowanie odzyskiwania po awarii dla klastra przy użyciu usługi Azure Site Recovery
W tej sekcji skonfigurujesz odzyskiwanie po awarii dla maszyn wirtualnych platformy Azure w klastrze podstawowym przy użyciu usługi Azure Site Recovery, wykonując kroki opisane w artykule Samouczek: konfigurowanie odzyskiwania po awarii dla maszyn wirtualnych platformy Azure. Potrzebne są tylko następujące sekcje: Tworzenie magazynu usługi Recovery Services i Włączanie replikacji. Zwróć uwagę na następujące kroki, wykonując czynności opisane w artykule, a następnie wróć do tego artykułu po ochronie klastra podstawowego:
W sekcji Tworzenie magazynu usługi Recovery Services wykonaj następujące czynności:
W kroku 5 dla grupy zasobów utwórz nową grupę zasobów o unikatowej nazwie w subskrypcji — na przykład
was-cluster-westus-mjg022624.W kroku 6 w polu Nazwa magazynu podaj nazwę magazynu — na przykład
recovery-service-vault-westus-mjg022624.W kroku 7 dla pozycji Region wybierz pozycję Zachodnie stany USA.
Przed wybraniem pozycji Przejrzyj i utwórz w kroku 8 wybierz pozycję Dalej: nadmiarowość. W okienku Nadmiarowość wybierz pozycję Geograficznie nadmiarowa dla opcji Nadmiarowość magazynu kopii zapasowych i Włącz dla przywracania między regionami.
Uwaga
Upewnij się, że w okienku Nadmiarowość magazynu kopii zapasowych wybrano opcję Geograficznie nadmiarowa i Włącz dla przywracania między regionami. W przeciwnym razie nie można replikować magazynu klastra podstawowego do regionu pomocniczego.
Włącz usługę Site Recovery, wykonując kroki opisane w sekcji Włączanie usługi Site Recovery.
Po dotarciu do sekcji Włączanie replikacji wykonaj następujące kroki:
- W sekcji Wybierz ustawienia źródła wykonaj następujące czynności:
W obszarze Region wybierz pozycję Wschodnie stany USA.
W polu Grupa zasobów wybierz zasób, w którym wdrożono klaster podstawowy — na przykład
was-cluster-eastus-mjg022624.Uwaga
Jeśli żądana grupa zasobów nie znajduje się na liście, możesz najpierw wybrać pozycję Zachodnie stany USA dla regionu, a następnie przełączyć się z powrotem do regionu Wschodnie stany USA.
Pozostaw wartości domyślne dla innych pól. Wybierz Dalej.
- W sekcji Wybierz maszyny wirtualne dla pozycji Maszyny wirtualne wybierz wszystkie pięć maszyn wirtualnych na liście, a następnie wybierz pozycję Dalej.
- W sekcji Przejrzyj ustawienia replikacji wykonaj następujące czynności:
- W polu Lokalizacja docelowa wybierz pozycję Zachodnie stany USA.
- W polu Docelowa grupa zasobów wybierz grupę zasobów, w której wdrożono magazyn odzyskiwania usługi — na przykład
was-cluster-westus-mjg022624. - Zanotuj nową sieć wirtualną trybu failover i podsieć trybu failover, która jest mapowana z tych w regionie podstawowym.
- Pozostaw wartości domyślne dla innych pól.
- Wybierz Dalej.
- W sekcji Zarządzanie wykonaj następujące czynności:
- W przypadku zasad replikacji użyj zasad domyślnych 24-godzinnego przechowywania. Możesz również utworzyć nowe zasady dla swojej firmy.
- Pozostaw wartości domyślne dla innych pól.
- Wybierz Dalej.
- W sekcji Przegląd wykonaj następujące czynności:
Po wybraniu pozycji Włącz replikację zwróć uwagę na komunikat Tworzenie zasobów platformy Azure. Nie zamykaj tego bloku. wyświetlany w dolnej części strony. Nie rób nic i zaczekaj na automatyczne zamknięcie okienka. Nastąpi przekierowanie do strony usługi Site Recovery .
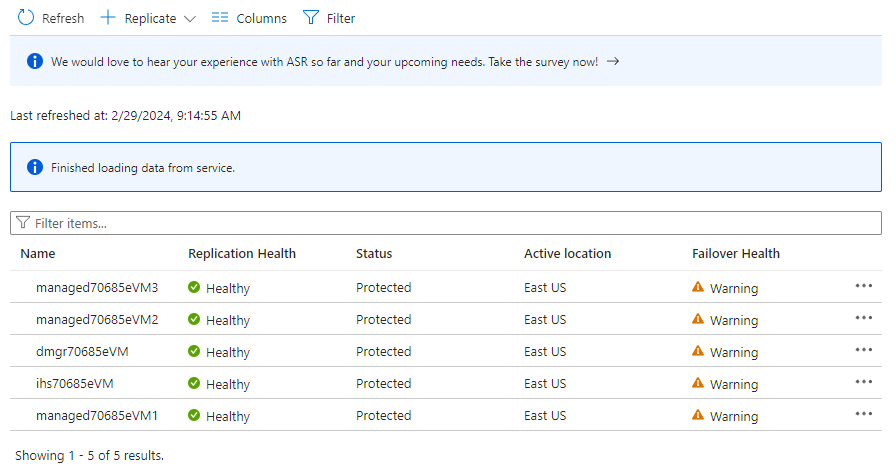
W obszarze Chronione elementy wybierz pozycję Replikowane elementy. Początkowo nie ma żadnych elementów na liście, ponieważ replikacja jest nadal w toku. Ukończenie replikacji trwa około godziny. Odśwież stronę okresowo, dopóki nie zobaczysz, że wszystkie maszyny wirtualne znajdują się w stanie Chronione , jak pokazano na poniższym przykładowym zrzucie ekranu:
- W sekcji Wybierz ustawienia źródła wykonaj następujące czynności:

Następnie utwórz plan odzyskiwania, aby uwzględnić wszystkie zreplikowane elementy, aby umożliwić ich przełączanie w tryb failover. Skorzystaj z instrukcji w temacie Tworzenie planu odzyskiwania z następującymi dostosowaniami:
- W kroku 2 wprowadź nazwę planu — na przykład
recovery-plan-mjg022624. - W kroku 3 w polu Źródło wybierz pozycję Wschodnie stany USA, a w polu Cel wybierz pozycję Zachodnie stany USA.
- W kroku 4 dla pozycji Wybierz elementy wybierz wszystkie pięć chronionych maszyn wirtualnych na potrzeby tego samouczka.
Następnie utworzysz plan odzyskiwania. Pozostaw otwartą stronę, aby można było jej użyć do testowania trybu failover później.
Dalsza konfiguracja sieci dla regionu pomocniczego
Potrzebna jest również dalsza konfiguracja sieci w celu włączenia i ochrony dostępu zewnętrznego do regionu pomocniczego w zdarzeniu trybu failover. Wykonaj następujące kroki dla tej konfiguracji:
Utwórz publiczny adres IP programu Dmgr w regionie pomocniczym, postępując zgodnie z instrukcjami w przewodniku Szybki start: Tworzenie publicznego adresu IP przy użyciu witryny Azure Portal z następującymi dostosowaniami:
- W obszarze Grupa zasobów wybierz grupę zasobów, w której wdrożono magazyn odzyskiwania usługi — na przykład
was-cluster-westus-mjg022624. - W obszarze Region wybierz pozycję (STANY USA) Zachodnie stany USA.
- W polu Nazwa wprowadź wartość — na przykład
dmgr-public-ip-westus-mjg022624. - W polu Etykieta nazwy DNS wprowadź unikatową wartość — na przykład
dmgrmjg022624.
- W obszarze Grupa zasobów wybierz grupę zasobów, w której wdrożono magazyn odzyskiwania usługi — na przykład
Utwórz kolejny publiczny adres IP dla IHS w regionie pomocniczym, postępując zgodnie z tym samym przewodnikiem, korzystając z następujących dostosowań:
- W obszarze Grupa zasobów wybierz grupę zasobów, w której wdrożono magazyn odzyskiwania usługi — na przykład
was-cluster-westus-mjg022624. - W obszarze Region wybierz pozycję (STANY USA) Zachodnie stany USA.
- W polu Nazwa wprowadź wartość — na przykład
ihs-public-ip-westus-mjg022624. Zapisz go. - W polu Etykieta nazwy DNS wprowadź unikatową wartość — na przykład
ihsmjg022624.
- W obszarze Grupa zasobów wybierz grupę zasobów, w której wdrożono magazyn odzyskiwania usługi — na przykład
Utwórz sieciową grupę zabezpieczeń w regionie pomocniczym, postępując zgodnie z instrukcjami w sekcji Tworzenie, zmienianie lub usuwanie sieciowej grupy zabezpieczeń przy użyciu następujących dostosowań:
- W obszarze Grupa zasobów wybierz grupę zasobów, w której wdrożono magazyn odzyskiwania usługi — na przykład
was-cluster-westus-mjg022624. - W polu Nazwa wprowadź wartość — na przykład
nsg-westus-mjg022624. - W obszarze Region wybierz pozycję Zachodnie stany USA.
- W obszarze Grupa zasobów wybierz grupę zasobów, w której wdrożono magazyn odzyskiwania usługi — na przykład
Utwórz regułę zabezpieczeń dla ruchu przychodzącego dla sieciowej grupy zabezpieczeń, postępując zgodnie z instrukcjami w sekcji Tworzenie reguły zabezpieczeń w tym samym artykule z następującymi dostosowaniami:
- W kroku 2 wybierz utworzoną sieciową grupę zabezpieczeń — na przykład
nsg-westus-mjg022624. - W kroku 3 wybierz pozycję Reguły zabezpieczeń dla ruchu przychodzącego.
- W kroku 4 dostosuj następujące ustawienia:
- W polu Zakresy portów docelowych wprowadź wartość 9060,9080,9043,9443,80.
- W polu Protokół wybierz TCP.
- W polu Nazwa wprowadź ALLOW_HTTP_ACCESS.
- W kroku 2 wybierz utworzoną sieciową grupę zabezpieczeń — na przykład
Skojarz sieciową grupę zabezpieczeń z podsiecią, postępując zgodnie z instrukcjami w sekcji Kojarzenie lub usuwanie skojarzenia sieciowej grupy zabezpieczeń z podsiecią tego samego artykułu z następującymi dostosowaniami:
- W kroku 2 wybierz utworzoną sieciową grupę zabezpieczeń — na przykład
nsg-westus-mjg022624. - Wybierz pozycję Skojarz , aby skojarzyć sieciowa grupa zabezpieczeń z zanotowaną wcześniej podsiecią trybu failover.
- W kroku 2 wybierz utworzoną sieciową grupę zabezpieczeń — na przykład
Konfigurowanie usługi Azure Traffic Manager
W tej sekcji utworzysz usługę Azure Traffic Manager do dystrybucji ruchu do publicznych aplikacji w globalnych regionach świadczenia usługi Azure. Podstawowy punkt końcowy wskazuje publiczny adres IP IHS w regionie podstawowym. Pomocniczy punkt końcowy wskazuje publiczny adres IP IHS w regionie pomocniczym.
Utwórz profil usługi Azure Traffic Manager, postępując zgodnie z instrukcjami w przewodniku Szybki start: tworzenie profilu usługi Traffic Manager przy użyciu witryny Azure Portal. Potrzebne są tylko następujące sekcje: Tworzenie profilu usługi Traffic Manager i Dodawanie punktów końcowych usługi Traffic Manager. Musisz pominąć sekcje, w których nastąpi przekierowanie do tworzenia zasobów usługi App Service. Wykonaj poniższe kroki, przechodząc przez te sekcje, a następnie wróć do tego artykułu po utworzeniu i skonfigurowaniu usługi Azure Traffic Manager.
W sekcji Tworzenie profilu usługi Traffic Manager w kroku 2 w sekcji Tworzenie profilu usługi Traffic Manager wykonaj następujące czynności:
- Zapisz unikatową nazwę profilu usługi Traffic Manager dla pola Nazwa — na przykład
tmprofile-mjg022624. - Zapisz nową nazwę grupy zasobów dla grupy zasobów — na przykład
myResourceGroupTM1.
- Zapisz unikatową nazwę profilu usługi Traffic Manager dla pola Nazwa — na przykład
Po dotarciu do sekcji Dodawanie punktów końcowych usługi Traffic Manager wykonaj następujące kroki:
- Po otwarciu profilu usługi Traffic Manager w kroku 2 na stronie Konfiguracja wykonaj następujące kroki:
- W przypadku czasu wygaśnięcia (TTL) dns wprowadź wartość 10.
- W obszarze Ustawienia monitora punktu końcowego w polu Ścieżka wprowadź ciąg /websphere-café/, który jest katalogem głównym kontekstu wdrożonej przykładowej aplikacji.
- W obszarze Ustawienia trybu failover szybkiego punktu końcowego użyj następujących wartości:
- W obszarze Sondowanie wewnętrzne wybierz pozycję 10.
- W polu Tolerowana liczba awarii wprowadź wartość 3.
- W przypadku limitu czasu sondy użyj wartości 5.
- Wybierz pozycję Zapisz. Zaczekaj na jego zakończenie.
- W kroku 4 dodawania podstawowego punktu końcowego
myPrimaryEndpointwykonaj następujące kroki:- W polu Typ zasobu docelowego wybierz pozycję Publiczny adres IP.
- Wybierz listę rozwijaną Wybierz publiczny adres IP i wprowadź nazwę publicznego adresu IP IHS w regionie Wschodnie stany USA, które zostały zapisane wcześniej. Powinien zostać wyświetlony jeden wpis dopasowany. Wybierz go jako publiczny adres IP.
- W kroku 6 dodawania punktu końcowego
myFailoverEndpointtrybu failover/pomocniczego wykonaj następujące kroki:- W polu Typ zasobu docelowego wybierz pozycję Publiczny adres IP.
- Wybierz listę rozwijaną Wybierz publiczny adres IP i wprowadź nazwę publicznego adresu IP IHS w regionie Zachodnie stany USA, które zostały zapisane wcześniej. Powinien zostać wyświetlony jeden wpis dopasowany. Wybierz go jako publiczny adres IP.
- Poczekaj chwilę. Wybierz pozycję Odśwież, dopóki stan monitora punktu końcowego to Online, a
myPrimaryEndpointmonitora punktu końcowego ma obniżonąmyFailoverEndpoint.
- Po otwarciu profilu usługi Traffic Manager w kroku 2 na stronie Konfiguracja wykonaj następujące kroki:
Następnie wykonaj następujące kroki, aby sprawdzić, czy przykładowa aplikacja wdrożona w podstawowym klastrze WebSphere jest dostępna z profilu usługi Traffic Manager:
Wybierz pozycję Przegląd dla utworzonego profilu usługi Traffic Manager.
Wybierz i skopiuj nazwę systemu nazw domen (DNS) profilu usługi Traffic Manager, a następnie dołącz go za
/websphere-cafe/pomocą polecenia — na przykładhttp://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/.Otwórz adres URL na nowej karcie przeglądarki. Na stronie powinna zostać wyświetlona utworzona wcześniej kawa.
Utwórz inną kawę o innej nazwie i cenie — na przykład Kawa 2 z ceną 20 — która jest utrwalana zarówno w tabeli danych aplikacji, jak i w tabeli sesji bazy danych. Widoczny interfejs użytkownika powinien być podobny do poniższego zrzutu ekranu:
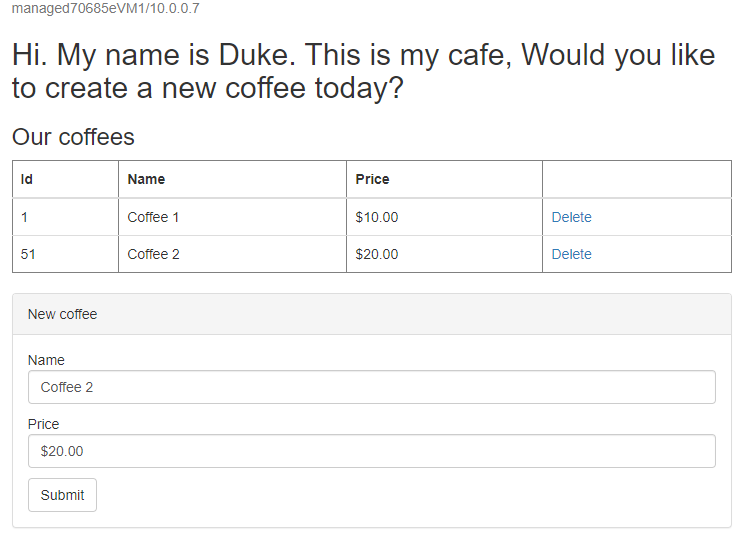

Jeśli interfejs użytkownika nie wygląda podobnie, przed kontynuowaniem rozwiąż problem i rozwiąż go. Pozostaw konsolę otwartą i użyj jej do późniejszego testowania trybu failover.
Teraz skonfigurujesz profil usługi Traffic Manager. Pozostaw otwartą stronę i użyj jej do monitorowania zmian stanu punktu końcowego w zdarzeniu trybu failover później.
Testowanie trybu failover z podstawowego do pomocniczego
Aby przetestować tryb failover, należy ręcznie przewrócić serwer i klaster usługi Azure SQL Database, a następnie wrócić po awarii przy użyciu witryny Azure Portal.
Przechodzenie w tryb failover do lokacji dodatkowej
Najpierw wykonaj następujące kroki, aby przejść w tryb failover usługi Azure SQL Database z serwera podstawowego do serwera pomocniczego:
- Przejdź do karty przeglądarki grupy trybu failover usługi Azure SQL Database — na przykład
failovergroup-mjg022624. - Wybierz pozycję Tryb failover>Tak.
- Zaczekaj na jego zakończenie.
Następnie wykonaj następujące kroki, aby przejść w tryb failover klastra WebSphere z planem odzyskiwania:
W polu wyszukiwania w górnej części witryny Azure Portal wprowadź magazyny usługi Recovery Services, a następnie wybierz pozycję Magazyny usługi Recovery Services w wynikach wyszukiwania.
Wybierz nazwę magazynu usługi Recovery Services — na przykład
recovery-service-vault-westus-mjg022624.W obszarze Zarządzanie wybierz pozycję Plany odzyskiwania (Site Recovery). Wybierz utworzony plan odzyskiwania — na przykład
recovery-plan-mjg022624.Wybierz pozycję Tryb failover. Wybierz pozycję Rozumiem ryzyko. Pomiń test pracy w trybie failover. Pozostaw wartości domyślne dla innych pól i wybierz przycisk OK.
Uwaga
Opcjonalnie możesz wykonać test pracy w trybie failover i przeczyść test pracy w trybie failover , aby upewnić się, że wszystko działa zgodnie z oczekiwaniami przed przetestowaniem trybu failover. Aby uzyskać więcej informacji, zobacz Samouczek: uruchamianie próbnego odzyskiwania po awarii dla maszyn wirtualnych platformy Azure. Ten samouczek testuje tryb failover bezpośrednio, aby uprościć ćwiczenie.
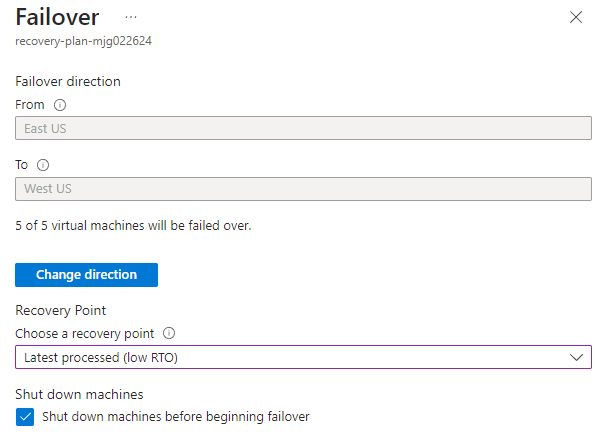
Monitoruj tryb failover w powiadomieniach, dopóki nie zostanie ukończony. Wykonanie ćwiczenia w tym samouczku zajmuje około 10 minut.
Opcjonalnie możesz wyświetlić szczegóły zadania trybu failover, wybierając zdarzenie trybu failover — na przykład tryb failover "recovery-plan-mjg02262624" jest w toku... — z powiadomień.
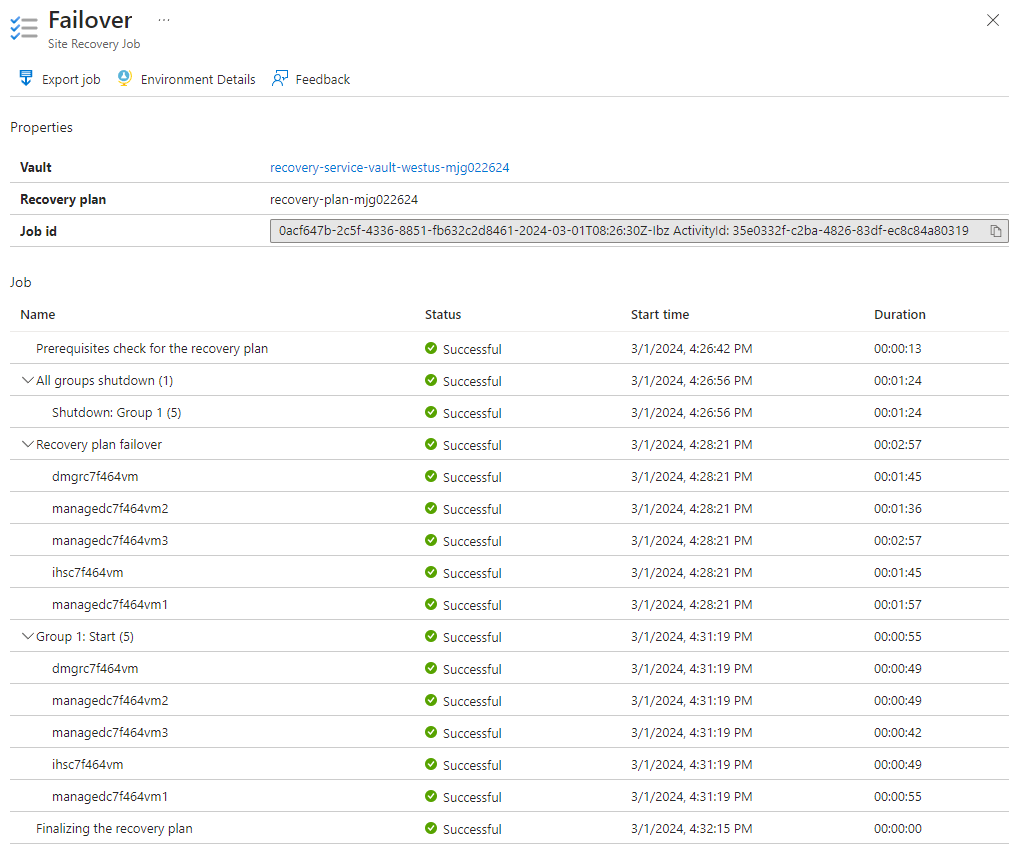




Następnie wykonaj następujące kroki, aby włączyć dostęp zewnętrzny do konsoli rozwiązania zintegrowanego WebSphere i przykładowej aplikacji w regionie pomocniczym:
- W polu wyszukiwania w górnej części witryny Azure Portal wprowadź ciąg Grupy zasobów , a następnie wybierz pozycję Grupy zasobów w wynikach wyszukiwania.
- Wybierz nazwę grupy zasobów dla regionu pomocniczego — na przykład
was-cluster-westus-mjg022624. Sortuj elementy według typu na stronie Grupa zasobów. - Wybierz pozycję Interfejs sieciowy z prefiksem
dmgr. Wybierz pozycję Konfiguracje adresów>IP ipconfig1. Wybierz pozycję Skojarz publiczny adres IP. W polu Publiczny adres IP wybierz publiczny adres IP poprzedzony prefiksemdmgr. Ten adres jest utworzony wcześniej. W tym artykule adres ma nazwędmgr-public-ip-westus-mjg022624. Wybierz pozycję Zapisz, a następnie zaczekaj na jego zakończenie. - Wróć do grupy zasobów i wybierz interfejs sieciowy poprzedzony prefiksem
ihs. Wybierz pozycję Konfiguracje adresów>IP ipconfig1. Wybierz pozycję Skojarz publiczny adres IP. W polu Publiczny adres IP wybierz publiczny adres IP poprzedzony prefiksemihs. Ten adres jest utworzony wcześniej. W tym artykule adres ma nazwęihs-public-ip-westus-mjg022624. Wybierz pozycję Zapisz, a następnie zaczekaj na jego zakończenie.
Teraz wykonaj następujące kroki, aby sprawdzić, czy tryb failover działa zgodnie z oczekiwaniami:
Znajdź etykietę nazwy DNS dla publicznego adresu IP utworzonego wcześniej programu Dmgr. Otwórz adres URL konsoli rozwiązań zintegrowanych Dmgr WebSphere na nowej karcie przeglądarki. Nie zapomnij użyć polecenia
https. Na przykładhttps://dmgrmjg022624.westus.cloudapp.azure.com:9043/ibm/console. Odśwież stronę do momentu wyświetlenia strony powitalnej na potrzeby logowania.Zaloguj się do konsoli przy użyciu nazwy użytkownika i hasła administratora WebSphere zapisanego wcześniej, a następnie wykonaj następujące kroki:
W okienku nawigacji wybierz pozycję Serwery>Wszystkie serwery. W okienku Serwery oprogramowania pośredniczącego powinny zostać wyświetlone 4 serwery, w tym 3 serwery aplikacji WebSphere składające się z klastra
MyClusterWebSphere i 1 serwera sieci Web, który jest serwerem IHS. Odśwież stronę, aż zobaczysz, że wszystkie serwery są uruchomione.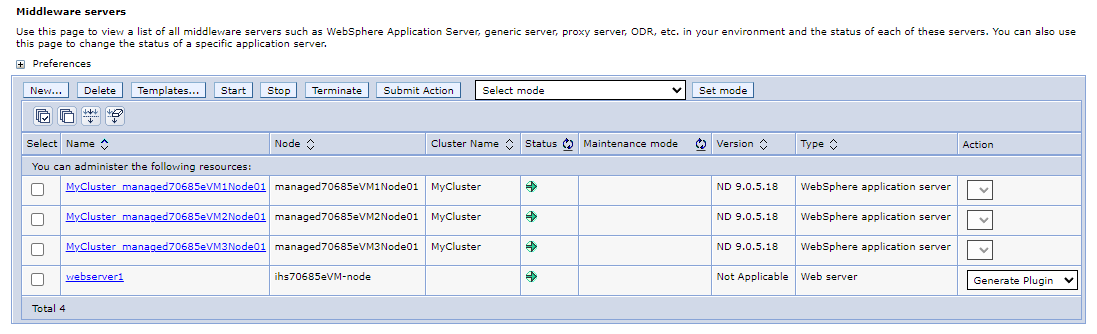
W okienku nawigacji wybierz pozycję >> W okienku Aplikacje dla przedsiębiorstw powinna zostać wyświetlona 1 aplikacja —
websphere-cafewyświetlana i uruchomiona.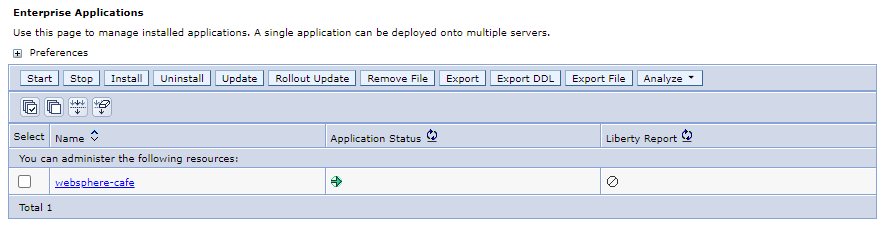
Aby zweryfikować konfigurację klastra w regionie pomocniczym, wykonaj kroki opisane w sekcji Konfigurowanie klastra . Powinny zostać wyświetlone ustawienia synchronizacji zmian z węzłami i sesjami rozproszonymi są replikowane do klastra trybu failover, jak pokazano na poniższych zrzutach ekranu:
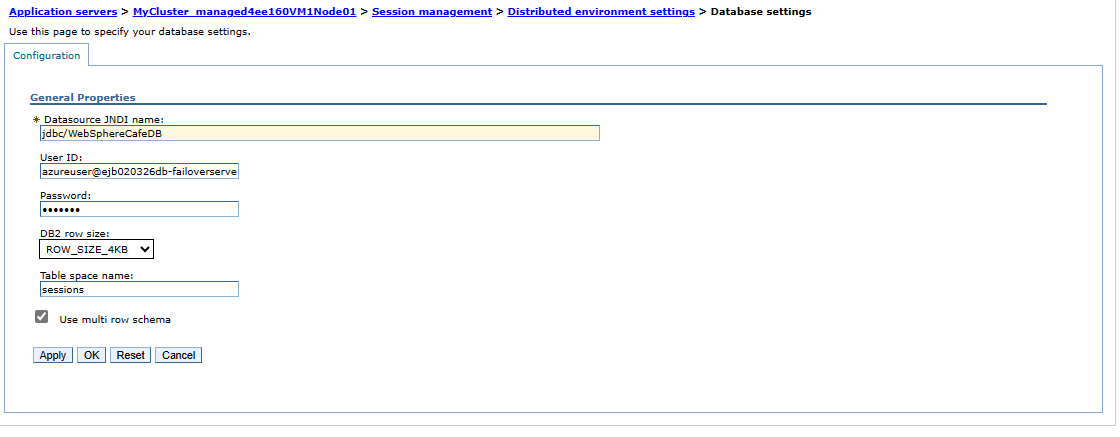
Znajdź etykietę nazwy DNS dla publicznego adresu IP utworzonego wcześniej protokołu IHS. Otwórz adres URL konsoli IHS dołączony z kontekstem
/websphere-cafe/głównym . Należy pamiętać, że nie można użyć poleceniahttps. W tym przykładzie nie jest używanahttpsfunkcja IHS — na przykładhttp://ihsmjg022624.westus.cloudapp.azure.com/websphere-cafe/. Na stronie powinny zostać wyświetlone dwie utworzone wcześniej kawy.Przejdź do karty przeglądarki profilu usługi Traffic Manager, a następnie odśwież stronę, aż zobaczysz, że wartość stanu monitora punktu końcowego
myFailoverEndpointstanie się w trybie online , a wartość stanu monitora punktu końcowegomyPrimaryEndpointstanie się obniżona.Przejdź do karty przeglądarki z nazwą DNS profilu usługi Traffic Manager — na przykład
http://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/. Odśwież stronę i powinny być widoczne te same dane utrwalone w tabeli danych aplikacji i wyświetlonej tabeli sesji. Widoczny interfejs użytkownika powinien być podobny do poniższego zrzutu ekranu: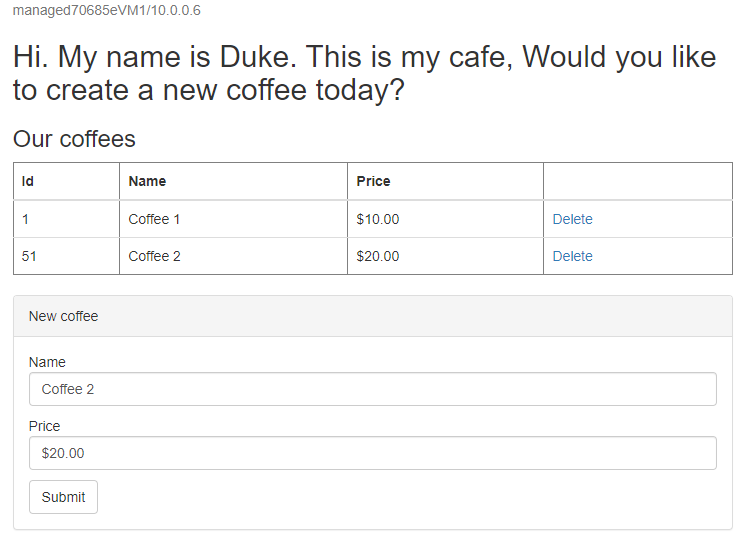
Jeśli nie obserwujesz tego zachowania, może to być spowodowane tym, że aktualizacja dns przez usługę Traffic Manager zajmuje więcej czasu, aby wskazywała lokację trybu failover. Problem może być również taki, że przeglądarka buforowała wynik rozpoznawania nazw DNS wskazujący witrynę, która zakończyła się niepowodzeniem. Poczekaj chwilę i odśwież stronę ponownie.





Zatwierdzanie trybu failover
Wykonaj następujące kroki, aby zatwierdzić tryb failover po spełnieniu wyniku przejścia w tryb failover:
W polu wyszukiwania w górnej części witryny Azure Portal wprowadź magazyny usługi Recovery Services, a następnie wybierz pozycję Magazyny usługi Recovery Services w wynikach wyszukiwania.
Wybierz nazwę magazynu usługi Recovery Services — na przykład
recovery-service-vault-westus-mjg022624.W obszarze Zarządzanie wybierz pozycję Plany odzyskiwania (Site Recovery). Wybierz utworzony plan odzyskiwania — na przykład
recovery-plan-mjg022624.Wybierz pozycję Zatwierdź>OK.
Monitoruj zatwierdzenie w powiadomieniach, dopóki nie zostanie ukończone.
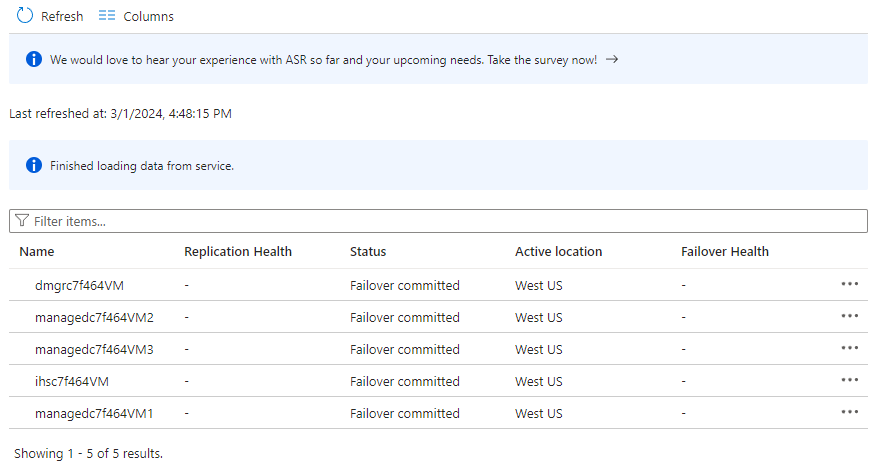
Wybierz pozycję Elementy w planie odzyskiwania. Powinien zostać wyświetlonych 5 elementów jako zatwierdzonych trybu failover.



Wyłączanie replikacji
Wykonaj następujące kroki, aby wyłączyć replikację dla elementów w planie odzyskiwania, a następnie usunąć plan odzyskiwania:
Dla każdego elementu w planie odzyskiwania wybierz przycisk wielokropka (...), a następnie wybierz pozycję Wyłącz replikację.
Jeśli zostanie wyświetlony monit o podanie przyczyny wyłączenia ochrony dla tej maszyny wirtualnej, wybierz preferowaną opcję — na przykład zakończono migrację mojej aplikacji. Wybierz przycisk OK.
Powtórz krok 1, dopóki nie wyłączysz replikacji dla wszystkich elementów.
Monitoruj proces w powiadomieniach, dopóki nie zostanie ukończony.
Wybierz pozycję Przegląd>Usuń. Wybierz pozycję Tak , aby potwierdzić usunięcie.

Przygotowanie do powrotu po awarii: ponowne włączanie ochrony lokacji trybu failover
Region pomocniczy to teraz lokacja trybu failover i aktywna. Należy ponownie chronić ją w regionie podstawowym.
Najpierw wykonaj następujące kroki, aby wyczyścić nieużywane zasoby i że usługa Azure Site Recovery będzie replikować w regionie podstawowym później. Nie można po prostu usunąć grupy zasobów, ponieważ usługa Site Recovery przywraca zasoby do istniejącej grupy zasobów.
- W polu wyszukiwania w górnej części witryny Azure Portal wprowadź ciąg Grupy zasobów , a następnie wybierz pozycję Grupy zasobów w wynikach wyszukiwania.
- Wybierz nazwę grupy zasobów dla regionu podstawowego — na przykład
was-cluster-eastus-mjg022624. Sortuj elementy według typu na stronie Grupa zasobów. - Aby usunąć maszyny wirtualne, wykonaj następujące czynności:
- Wybierz filtr Typ, a następnie z listy rozwijanej Wartość wybierz pozycję Maszyna wirtualna.
- Wybierz Zastosuj.
- Wybierz wszystkie maszyny wirtualne, wybierz pozycję Usuń, a następnie wprowadź polecenie usuń, aby potwierdzić usunięcie.
- Wybierz Usuń.
- Monitoruj proces w powiadomieniach, dopóki nie zostanie ukończony.
- Aby usunąć dyski, wykonaj następujące czynności:
- Wybierz filtr Typ, a następnie wybierz pozycję Dyski z listy rozwijanej Wartość.
- Wybierz Zastosuj.
- Wybierz wszystkie dyski, wybierz pozycję Usuń, a następnie wprowadź polecenie usuń, aby potwierdzić usunięcie.
- Wybierz Usuń.
- Monitoruj proces w powiadomieniach i zaczekaj na jego zakończenie.
- Aby usunąć punkty końcowe, wykonaj następujące czynności:
- Wybierz filtr Typ, wybierz pozycję Prywatny punkt końcowy z listy rozwijanej Wartość.
- Wybierz Zastosuj.
- Wybierz wszystkie prywatne punkty końcowe, wybierz pozycję Usuń, a następnie wprowadź polecenie Usuń, aby potwierdzić usunięcie.
- Wybierz Usuń.
- Monitoruj proces w powiadomieniach, dopóki nie zostanie ukończony. Zignoruj ten krok, jeśli typ Prywatny punkt końcowy nie znajduje się na liście.
- Aby usunąć interfejsy sieciowe, wykonaj następujące czynności:
- wybierz pozycję > sieciowy z listy rozwijanej Wartość.
- Wybierz Zastosuj.
- Wybierz wszystkie interfejsy sieciowe, wybierz pozycję Usuń, a następnie wprowadź polecenie usuń, aby potwierdzić usunięcie.
- Wybierz Usuń. Monitoruj proces w powiadomieniach, dopóki nie zostanie ukończony.
- Aby usunąć konta magazynu, wykonaj następujące czynności:
- wybierz pozycję > magazynu z listy rozwijanej Wartość.
- Wybierz Zastosuj.
- Wybierz wszystkie konta magazynu, wybierz pozycję Usuń, a następnie wprowadź polecenie Usuń, aby potwierdzić usunięcie.
- Wybierz Usuń. Monitoruj proces w powiadomieniach, dopóki nie zostanie ukończony.
Następnie wykonaj te same kroki w sekcji Konfigurowanie odzyskiwania po awarii dla klastra przy użyciu usługi Azure Site Recovery dla regionu podstawowego, z wyjątkiem następujących różnic:
-
W sekcji Tworzenie magazynu usługi Recovery Services wykonaj następujące kroki:
- Wybierz grupę zasobów wdrożona w regionie podstawowym — na przykład
was-cluster-eastus-mjg022624. - Wprowadź inną nazwę magazynu usługi — na przykład
recovery-service-vault-eastus-mjg022624. - W obszarze Region wybierz pozycję Wschodnie stany USA.
- Wybierz grupę zasobów wdrożona w regionie podstawowym — na przykład
- W obszarze Włącz replikację wykonaj następujące czynności:
- W obszarze Region w źródle wybierz pozycję Zachodnie stany USA.
- W obszarze Ustawienia replikacji wykonaj następujące czynności:
- W obszarze Docelowa grupa zasobów wybierz istniejącą grupę zasobów wdrożona w regionie podstawowym — na przykład
was-cluster-eastus-mjg022624. - W obszarze Sieć wirtualna trybu failover wybierz istniejącą sieć wirtualną w regionie podstawowym.
- W obszarze Docelowa grupa zasobów wybierz istniejącą grupę zasobów wdrożona w regionie podstawowym — na przykład
- W obszarze Utwórz plan odzyskiwania w polu Źródło wybierz pozycję Zachodnie stany USA, a w polu Cel wybierz pozycję Wschodnie stany USA.
- Pomiń kroki opisane w sekcji Dalsza konfiguracja sieci dla regionu pomocniczego, ponieważ zostały utworzone i skonfigurowane wcześniej te zasoby.
Uwaga
Możesz zauważyć, że usługa Azure Site Recovery obsługuje ponowne włączanie ochrony maszyny wirtualnej, gdy istnieje docelowa maszyna wirtualna. Aby uzyskać więcej informacji, zobacz sekcję Ponowne włączanie ochrony maszyny wirtualnej w temacie Samouczek: przełączanie maszyn wirtualnych platformy Azure w tryb failover do regionu pomocniczego. Ze względu na podejście, które przyjmujemy dla platformy WebSphere, ta funkcja nie działa. Przyczyną jest to, że jedyne zmiany między dyskiem źródłowym a dyskiem docelowym są synchronizowane dla klastra WebSphere na podstawie wyniku weryfikacji. Aby zastąpić funkcje funkcji ponownej ochrony maszyny wirtualnej, ten samouczek ustanawia nową replikację z lokacji dodatkowej do lokacji głównej po przejściu w tryb failover. Wszystkie dyski są kopiowane z regionu przełączonego w tryb failover do regionu podstawowego. Aby uzyskać więcej informacji, zobacz sekcję Co się stanie podczas ponownej ochrony? w sekcji Ponowne włączanie ochrony maszyn wirtualnych platformy Azure w trybie failover do regionu podstawowego.
Powrót po awarii do lokacji głównej
Wykonaj te same kroki w sekcji Tryb failover w lokacji dodatkowej, aby powrócić po awarii do lokacji głównej, w tym do serwera bazy danych i klastra, z wyjątkiem następujących różnic:
- Wybierz magazyn usługi Recovery Service wdrożony w regionie podstawowym — na przykład
recovery-service-vault-eastus-mjg022624. - Wybierz grupę zasobów wdrożona w regionie podstawowym — na przykład
was-cluster-eastus-mjg022624. - Po włączeniu dostępu zewnętrznego do konsoli rozwiązania zintegrowanego WebSphere i przykładowej aplikacji w regionie podstawowym ponownie przejdź do kart przeglądarki dla konsoli rozwiązania zintegrowanego WebSphere i przykładowej aplikacji dla klastra podstawowego, który został wcześniej otwarty. Sprawdź, czy działają zgodnie z oczekiwaniami. W zależności od tego, ile czasu zajęło powrót po awarii, dane sesji mogą nie być wyświetlane w sekcji Nowa kawa w interfejsie użytkownika przykładowej aplikacji, jeśli upłynął więcej niż jedna godzina wcześniej.
-
W sekcji Commit the failover (Zatwierdzanie trybu failover) wybierz magazyn usługi Recovery Services wdrożony w podstawowym magazynie — na przykład
recovery-service-vault-eastus-mjg022624. - W profilu usługi Traffic Manager powinien zostać wyświetlony, że punkt końcowy
myPrimaryEndpointstanie się w trybie online , a punkt końcowymyFailoverEndpointstanie się obniżony. -
W sekcji Przygotowanie do powrotu po awarii: ponownie chroń witrynę trybu failover, wykonaj następujące kroki:
- Region podstawowy to lokacja trybu failover i jest aktywna, dlatego należy ponownie chronić ją w regionie pomocniczym.
- Wyczyść zasób wdrożony w regionie pomocniczym — na przykład zasoby wdrożone w programie
was-cluster-westus-mjg022624. - Wykonaj te same kroki w sekcji Konfigurowanie odzyskiwania po awarii dla klastra przy użyciu usługi Azure Site Recovery w celu ochrony regionu podstawowego w regionie pomocniczym, z wyjątkiem następujących zmian:
- Pomiń kroki opisane w sekcji Tworzenie magazynu usługi Recovery Services, ponieważ utworzono go wcześniej — na przykład
recovery-service-vault-westus-mjg022624. - W obszarze wirtualnej trybu failover wybierz istniejącą sieć wirtualną w regionie pomocniczym.
- Pomiń kroki opisane w sekcji Dalsza konfiguracja sieci dla regionu pomocniczego, ponieważ zostały utworzone i skonfigurowane wcześniej te zasoby.
- Pomiń kroki opisane w sekcji Tworzenie magazynu usługi Recovery Services, ponieważ utworzono go wcześniej — na przykład
Czyszczenie zasobów
Jeśli nie zamierzasz nadal korzystać z klastrów WebSphere i innych składników, wykonaj następujące kroki, aby usunąć grupy zasobów, aby wyczyścić zasoby używane w tym samouczku:
- Wprowadź nazwę grupy zasobów serwerów usługi Azure SQL Database — na przykład
myResourceGroup— w polu wyszukiwania w górnej części witryny Azure Portal i wybierz dopasowaną grupę zasobów z wyników wyszukiwania. - Wybierz pozycję Usuń grupę zasobów.
- W polu Wprowadź nazwę grupy zasobów, aby potwierdzić usunięcie, wprowadź nazwę grupy zasobów.
- Wybierz Usuń.
- Powtórz kroki 1–4 dla grupy zasobów usługi Traffic Manager — na przykład
myResourceGroupTM1. - W polu wyszukiwania w górnej części witryny Azure Portal wprowadź magazyny usługi Recovery Services, a następnie wybierz pozycję Magazyny usługi Recovery Services w wynikach wyszukiwania.
- Wybierz nazwę magazynu usługi Recovery Services — na przykład
recovery-service-vault-westus-mjg022624. - W obszarze Zarządzanie wybierz pozycję Plany odzyskiwania (Site Recovery). Wybierz utworzony plan odzyskiwania — na przykład
recovery-plan-mjg022624. - Wykonaj te same kroki w sekcji Wyłączanie replikacji , aby usunąć blokady na replikowanych elementach.
- Powtórz kroki 1–4 dla grupy zasobów podstawowego klastra WebSphere — na przykład
was-cluster-westus-mjg022624. - Powtórz kroki 1–4 dla grupy zasobów pomocniczego klastra WebSphere — na przykład
was-cluster-eastus-mjg022624.
Następne kroki
W tym samouczku skonfigurujesz rozwiązanie wysokiej dostępności/odzyskiwania po awarii składające się z warstwy infrastruktury aplikacji aktywne-pasywne z warstwą bazy danych aktywne-pasywne i w którym obie warstwy obejmują dwa geograficznie różne lokacje. W pierwszej lokacji zarówno warstwa infrastruktury aplikacji, jak i warstwa bazy danych są aktywne. W drugiej lokacji domena pomocnicza jest przywracana za pomocą usługi Azure Site Recovery, a pomocnicza baza danych jest w stanie wstrzymania.
Zapoznaj się z następującymi odwołaniami, aby uzyskać więcej opcji tworzenia rozwiązań wysokiej dostępności/odzyskiwania po awarii i uruchamiania platformy WebSphere na platformie Azure: