Samouczek: migrowanie serwera aplikacji JBoss EAP do usługi Azure Virtual Machines z wysoką dostępnością i odzyskiwaniem po awarii
W tym samouczku przedstawiono prosty i skuteczny sposób implementowania wysokiej dostępności i odzyskiwania po awarii (HA/DR) dla języka Java przy użyciu protokołu JBoss EAP na maszynach wirtualnych platformy Azure. Rozwiązanie ilustruje sposób osiągnięcia niskiego celu czasu odzyskiwania (RTO) i celu punktu odzyskiwania (RPO) przy użyciu prostej opartej na bazie danych aplikacji Jakarta EE działającej na serwerze aplikacji JBoss EAP. Wysoka dostępność i odtwarzanie po awarii to złożony temat z wieloma możliwymi rozwiązaniami. Najlepsze rozwiązanie zależy od unikatowych wymagań. Aby uzyskać inne sposoby implementowania wysokiej dostępności/odzyskiwania po awarii, zobacz zasoby na końcu tego artykułu.
Z tego samouczka dowiesz się, jak wykonywać następujące działania:
- Skonfiguruj klaster JBoss EAP na maszynach wirtualnych platformy Azure.
- Użyj najlepszych rozwiązań zoptymalizowanych pod kątem platformy Azure, aby uzyskać wysoką dostępność i odzyskiwanie po awarii.
- Skonfiguruj grupę trybu failover usługi Microsoft Azure SQL Database w sparowanych regionach.
- Konfigurowanie odzyskiwania po awarii dla klastra przy użyciu usługi Azure Site Recovery.
- Konfigurowanie usługi Azure Traffic Manager.
- Przetestuj tryb failover z podstawowego do pomocniczego.
Na poniższym diagramie przedstawiono architekturę, którą tworzysz:

Usługa Azure Traffic Manager sprawdza kondycję regionów i kieruje ruch odpowiednio do warstwy aplikacji. Region podstawowy ma pełne wdrożenie klastra JBoss EAP. Gdy region podstawowy jest chroniony przez usługę Azure Site Recovery, możesz przywrócić region pomocniczy podczas przełączania awaryjnego. W związku z tym region podstawowy aktywnie obsługuje żądania sieciowe od użytkowników, podczas gdy region pomocniczy jest pasywny i aktywowany w celu odbierania ruchu tylko wtedy, gdy region podstawowy doświadcza przerw w działaniu usługi.
Usługa Azure Traffic Manager wykrywa kondycję aplikacji wdrożonej w klastrze JBoss EAP w celu zaimplementowania routingu warunkowego. Czas odzyskiwania geograficznego w trybie awaryjnym dla warstwy aplikacji zależy od czasu potrzebnego na zamknięcie pierwszorzednego klastra, przywrócenie klastra pomocniczego, uruchomienie maszyn wirtualnych oraz działanie pomocniczego klastra JBoss EAP. Cel punktu odzyskiwania zależy od zasad replikacji usług Azure Site Recovery i Azure SQL Database, ponieważ dane klastra są przechowywane i replikowane w lokalnym magazynie maszyn wirtualnych, podczas gdy dane aplikacji są utrwalane i replikowane w grupie trybu failover usługi Azure SQL Database.
Na powyższym diagramie przedstawiono region podstawowy i region pomocniczy jako dwa regiony składające się z architektury wysokiej dostępności/odzyskiwania po awarii. Te regiony muszą być sparowane z platformą Azure. Aby uzyskać więcej informacji na temat sparowanych regionów, zobacz replikacji między regionami platformy Azure. W artykule użyto regionów Wschodnie stany USA i Zachodnie stany USA jako dwa regiony, ale mogą to być wszystkie sparowane regiony, które mają sens w danym scenariuszu. Aby uzyskać listę par regionów, zobacz sekcję sparowanych regionów platformy Azurereplikacji między regionami platformy Azure.
Warstwa bazy danych składa się z grupy przełączania awaryjnego w usłudze Azure SQL Database, obejmującej serwer podstawowy i serwer pomocniczy. Punkt końcowy odbiornika odczytu/zapisu zawsze wskazuje serwer podstawowy i jest połączony z klastrem EAP JBoss w każdym regionie. Gdy dojdzie do failoveru geograficznego, wszystkie pomocnicze bazy danych w grupie zostają przełączone do roli podstawowej. Aby uzyskać informacje o RPO (celu punktu odzyskiwania) i RTO (celu czasu odzyskiwania) w przypadku failoveru geograficznego usługi Azure SQL Database, zobacz Overview of Business Continuity.
Ten samouczek został napisany za pomocą usług Azure Site Recovery i Azure SQL Database, ponieważ samouczek opiera się na funkcjach wysokiej dostępności tych usług. Inne opcje bazy danych są możliwe, ale należy rozważyć funkcje wysokiej dostępności dowolnej wybranej bazy danych.
Warunki wstępne
- Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto .
- Upewnij się, że masz rolę
Contributorw subskrypcji. Aby zweryfikować przypisanie, postępuj zgodnie z krokami opisanymi w Listą przypisania ról Azure przy użyciu portalu Azure. - Przygotuj maszynę lokalną z zainstalowanym systemem Windows, GNU/Linux lub macOS.
- Zainstaluj i skonfiguruj git.
- Zainstaluj implementację środowiska Java SE w wersji 17 lub nowszej — na przykład wersję OpenJDK od Microsoftu.
- Zainstaluj mavenw wersji 3.9.3 lub nowszej.
Konfigurowanie grupy przełączania awaryjnego Azure SQL Database w sparowanych regionach
W tej sekcji utworzysz grupę przełączania awaryjnego usługi Azure SQL Database w sparowanych regionach do użycia z klastrami i aplikacjami JBoss EAP.
Najpierw utwórz podstawową bazę danych Azure SQL Database, wykonując kroki opisane w portalu Azure w Szybki start: Utwórz pojedynczą bazę danych — Azure SQL Database. Wykonaj kroki z wyjątkiem Czyszczenie zasobów. Podczas pracy z artykułem skorzystaj z poniższych wskazówek, a następnie wróć do tego artykułu po utworzeniu i skonfigurowaniu usługi Azure SQL Database.
Po dotarciu do sekcji Tworzenie pojedynczej bazy danychwykonaj następujące kroki:
W kroku 4 tworzenia nowej grupy zasobów zapisz wartość Nazwa grupy zasobów — na przykład
sqlserver-rg-gzh032124.W kroku 5 dla nazwy bazy danych zapisz wartość Nazwa bazy danych — na przykład
mySampleDatabase.W kroku 6 tworzenia serwera wykonaj następujące kroki:
- Wypełnij unikatową nazwę serwera — na przykład
sqlserverprimary-gzh032124. - W obszarze Locationwybierz pozycję (US) East US (Wschodnie stany USA).
- W przypadku metody uwierzytelniania wybierz opcję Użyj uwierzytelniania SQL.
- Zanotuj wartość logowania administratora serwera Server — na przykład
azureuser. - Zanotuj wartość Password.
- Wypełnij unikatową nazwę serwera — na przykład
W kroku 8, dla środowiska obciążenia , wybierz pozycję Development. Przyjrzyj się opisowi i rozważ inne opcje obciążenia.
W kroku 10 dla warstwy obliczeniowejwybierz Przydzielone.
W kroku 11, dla Redundancji magazynu kopii zapasowych, wybierz Lokalnie redundantny magazyn kopii zapasowych. Rozważ inne opcje tworzenia kopii zapasowych. Aby uzyskać więcej informacji, zobacz sekcję
Backup nadmiarowości magazynu automatyczne kopie zapasowe w usłudze Azure SQL Database .W kroku 14, w konfiguracji reguł zapory , dla Zezwalaj usługom i zasobom platformy Azure na dostęp do tego serwera, wybierz Tak.
Po dotarciu do sekcji Wykonywanie zapytań dotyczących bazy danychwykonaj następujące kroki zamiast kroków w innym artykule:
W kroku 3 wprowadź dane logowania administratora serwera do uwierzytelniania SQL , aby się zalogować.
Notatka
Jeśli logowanie nie powiedzie się z komunikatem o błędzie podobnym do Klient z adresem IP "xx.xx.xx.xx" nie może uzyskać dostępu do serwera, wybierz dodaj IP xx.xx.xx.xx do listy dozwolonych na serwerze <your-sqlserver-name> na końcu komunikatu o błędzie. Poczekaj, aż reguły zapory serwera zakończą aktualizowanie, a następnie ponownie wybierz pozycję OK.
Po uruchomieniu przykładowego zapytania w kroku 5 wyczyść edytor i wprowadź następujące zapytanie, a następnie ponownie wybierz pozycję Uruchom:
CREATE TABLE ispn_entry_sessions_javaee_cafe_war ( id VARCHAR(255) PRIMARY KEY, -- ID Column to hold cache entry ids data VARBINARY(MAX), -- Data Column to hold cache entry data timestamp BIGINT, -- Timestamp Column to hold cache entry timestamps segment INT );Po pomyślnym uruchomieniu powinien zostać wyświetlony komunikat Zapytanie powiodło się: Dotknięte wiersze: 0.
Tabela bazy danych
ispn_entry_sessions_javaee_cafe_warsłuży do przechowywania danych sesji dla klastra JBoss EAP.
Następnie utwórz grupę trybu failover usługi Azure SQL Database, wykonując kroki opisane w artykule Konfigurowanie grupy trybu failover dla usługi Azure SQL Database. Potrzebujesz tylko następujących sekcji: Tworzenie grupy trybu failover i Testowanie planowanego trybu failover. Wykonaj następujące kroki, wykonując czynności opisane w artykule, a następnie wróć do tego artykułu po utworzeniu i skonfigurowaniu grupy trybu failover usługi Azure SQL Database:
Kiedy dojdziesz do sekcji Tworzenie grupy trybu failover, wykonaj następujące czynności:
W kroku 5 tworzenia grupy failover wprowadź i zapisz unikatową nazwę grupy — na przykład
failovergroup-gzh032124.W kroku 5 konfigurowania serwera wybierz opcję utworzenia nowego serwera pomocniczego, a następnie wykonaj następujące czynności:
- Wprowadź unikatową nazwę serwera — na przykład
sqlserversecondary-gzh032124. - Wprowadź tego samego administratora serwera i to samo hasło co na serwerze podstawowym.
- W obszarze Locationwybierz pozycję (USA) Zachodnie stany USA 2.
- Upewnij się, że wybrano opcję Zezwalaj usługom platformy Azure na dostęp do serwera.
- Wprowadź unikatową nazwę serwera — na przykład
W kroku 5 konfigurowania baz danych w grupiewybierz bazę danych utworzoną na serwerze podstawowym — na przykład
mySampleDatabase.
Po wykonaniu wszystkich kroków w sekcji Test planowanego przełączenia awaryjnego, zachowaj otwartą stronę grupy przełączenia awaryjnego i użyj jej do testowania przełączenia awaryjnego klastrów JBoss EAP w późniejszym czasie.
Notatka
Ten artykuł pomaga stworzyć pojedynczą bazę danych usługi Azure SQL Database z uwierzytelnianiem SQL dla uproszczenia, ponieważ konfiguracja wysokiej dostępności i odzyskiwania po awarii, na której skupia się ten artykuł, jest już bardzo złożona. Bezpieczniejszą praktyką jest użycie uwierzytelniania microsoft Entra dla usługi Azure SQL do uwierzytelniania połączenia serwera bazy danych.
Konfigurowanie podstawowego klastra JBoss EAP na maszynach wirtualnych platformy Azure
W tej sekcji utworzysz główne klastry JBoss EAP na maszynach wirtualnych platformy Azure, korzystając z oferty JBoss EAP Cluster na maszynach wirtualnych. Klaster pomocniczy zostanie przywrócony z klastra podstawowego podczas przełączenia awaryjnego przy użyciu usługi Azure Site Recovery.
Wdrażanie podstawowego klastra JBoss EAP
Najpierw otwórz w przeglądarce ofertę klastra JBoss EAP na maszynach wirtualnych i wybierz opcję Utwórz. Powinno zostać wyświetlone okienko Podstawy oferty.
Wykonaj następujące kroki, aby uzupełnić panel Podstawy:
- Upewnij się, że wartość wyświetlana dla Subscription to ta sama, która ma role wymienione w sekcji dotyczącej wymagań wstępnych.
- Należy wdrożyć ofertę w pustej grupie zasobów. W polu grupa zasobów wybierz Utwórz nowy i wprowadź unikatową wartość dla grupy zasobów — na przykład
jboss-eap-cluster-eastus-gzh032124. - W sekcji szczegóły instancji , wybierz Region, wybierz Wschodnie Stany USA.
- Podaj hasło dla Password i użyj tej samej wartości dla Potwierdź hasło.
- Dla liczba maszyn wirtualnych do utworzenia, wprowadź 3.
- Pozostaw wartości domyślne innych pól.
- Wybierz pozycję Dalej, aby przejść do panelu ustawień JBoss EAP.

Aby wypełnić okienko ustawień protokołu EAP
- Podaj hasło JBoss EAP do , hasła JBoss EAP. Użyj tej samej wartości dla Potwierdź hasło. Zapisz wartość do późniejszego użycia.
- Pozostaw wartości domyślne innych pól.
- Wybierz pozycję Dalej, aby przejść do okienka usługi Azure Application Gateway.

Wykonaj następujące kroki, aby wypełnić okienko Azure Application Gateway:
- Aby nawiązać połączenie z usługą Azure Application Gateway?wybierz pozycję Tak.
- Pozostaw wartości domyślne innych pól.
- Wybierz Dalej, aby przejść do okienka Sieć.

Powinieneś zobaczyć, że wszystkie pola są wstępnie wypełnione wartościami domyślnymi w okienku Sieć . Wybierz pozycję Dalej, aby przejść do okienka Database.

Wykonaj następujące kroki w celu wypełnienia panelu Database:
- W przypadku Nawiązywania połączenia z bazą danych?wybierz Tak.
- Dla Wybierz typ bazy danych, wybierz Microsoft SQL Server.
- Dla nazwy JNDIwprowadź java:jboss/datasources/JavaEECafeDB.
- W przypadku parametrów połączenia źródła danych (jdbc:sqlserver://<host>:<port>; database=<database>), zastąp symbole zastępcze wartościami napisanymi w poprzedniej sekcji dla grupy trybu failover usługi Azure SQL Database — na przykład
jdbc:sqlserver://failovergroup-gzh032124.database.windows.net:1433;database=mySampleDatabase. - W przypadku Nazwa użytkownika bazy danychwprowadź nazwę logowania administratora serwera i nazwę grupy failover, którą zanotowałeś z poprzedzającej sekcji — na przykład
azureuser@failovergroup-gzh032124. - Wprowadź hasło administratora serwera, które zanotowałeś wcześniej, dla hasło bazy danych. Wprowadź tę samą wartość dla Potwierdź hasło.
- Wybierz pozycję Przejrzyj i stwórz.
- Zaczekaj, aż do chwili, gdy Ostateczne sprawdzanie poprawności... zakończy się pomyślnie, a następnie wybierz Utwórz.

Po pewnym czasie powinna zostać wyświetlona strona wdrażania, na której widoczne jest, że wdrażanie jest w toku.
Notatka
Jeśli podczas ostatecznego sprawdzania poprawności są widoczne jakiekolwiek problemy..., rozwiąż je i spróbuj ponownie.
W zależności od warunków sieciowych i innych działań w wybranym regionie wdrożenie może potrwać do 35 minut. Następnie powinien zostać wyświetlony tekst Wdrożenie zostało ukończone wyświetlane na stronie wdrożenia.
Weryfikowanie funkcjonalności wdrożenia
Wykonaj następujące kroki, aby zweryfikować funkcjonalność wdrożenia klastra JBoss EAP na maszynach wirtualnych platformy Azure z konsoli zarządzania platformy Red Hat JBoss Enterprise Application Platform:
Na stronie Twoje wdrożenie zostało zakończonewybierz pozycję Wyniki.
Wybierz ikonę kopiowania obok adminConsole.
Wklej adres URL do przeglądarki internetowej połączonej z Internetem i naciśnij Enter. Powinien zostać wyświetlony znajomy ekran logowania do konsoli zarządzania Red Hat JBoss Enterprise Application Platform, jak pokazano na poniższym zrzucie ekranu.
Wypełnij jbossadmin dla JBoss EAP Admin username Podaj wartość hasła JBoss EAP określonego wcześniej dla hasło, a następnie wybierz pozycję Zaloguj się.
Powinieneś zobaczyć znaną stronę powitalną konsoli zarządzania Red Hat JBoss Enterprise Application Platform, jak przedstawiono na poniższym zrzucie ekranu.
Wybierz kartę Runtime. W okienku nawigacji wybierz Topology. Powinien zostać wyświetlony komunikat, że klaster zawiera jeden kontroler domeny główny i dwa węzły robocze, jak pokazano na poniższym zrzucie ekranu:
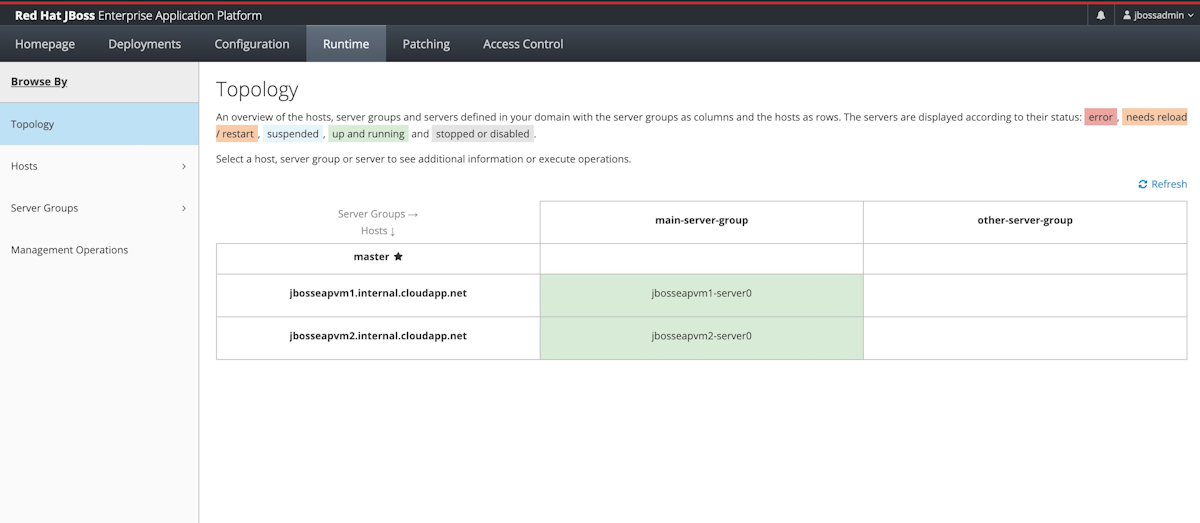




Pozostaw otwartą konsolę zarządzania. Służy do wdrażania przykładowej aplikacji w klastrze JBoss EAP w następnej sekcji.
Konfigurowanie klastra
Wykonaj następujące kroki, aby skonfigurować sesje rozproszone bazy danych dla wszystkich serwerów aplikacji:
Wybierz pozycję Konfiguracja na panelu nawigacyjnym. Następnie wybierz pozycję Profiles >>Infinspan>Web.
W kolumnie Pamięć podręczna wybierz pozycję Dodaj pamięć podręczną rozproszoną.
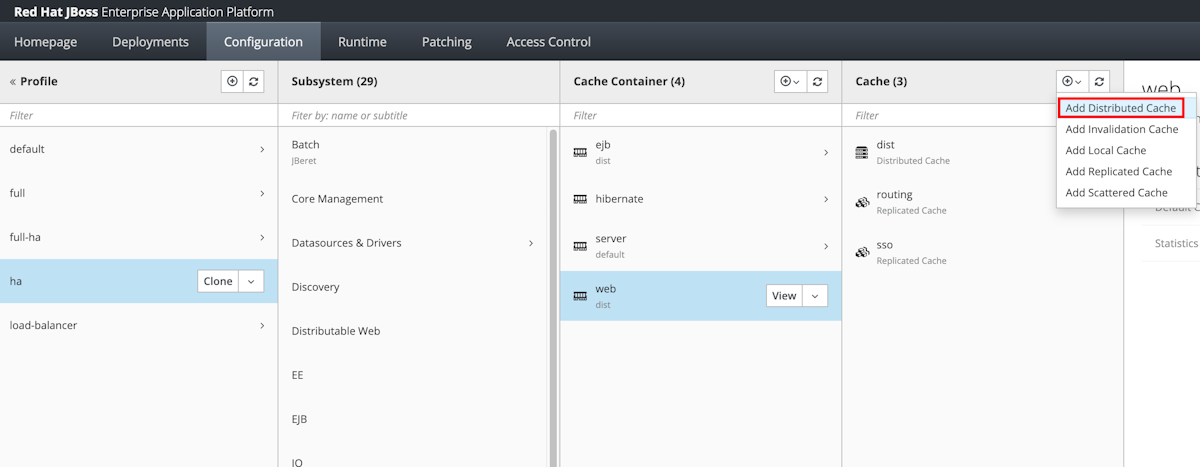
Dla Nazwa, wprowadź azure-session, a następnie wybierz pozycję Dodaj.
Powinien zostać wyświetlony komunikat „Rozproszona Pamięć Podręczna azure-session” został pomyślnie dodany. Jeśli ten komunikat nie jest widoczny, sprawdź centrum powiadomień. Przed kontynuowaniem musisz zobaczyć ten komunikat.
Po dodaniu pamięci podręcznej wybierz azure-session>View.
Wybierz pozycję Store.
Zmień menu rozwijane, aby wyświetlić JDBC , a następnie wybierz Dodaj.
W przypadkuźródła danych
wybierz pozycję dataSource-mssqlserver , a następnie wybierz pozycjęDodaj .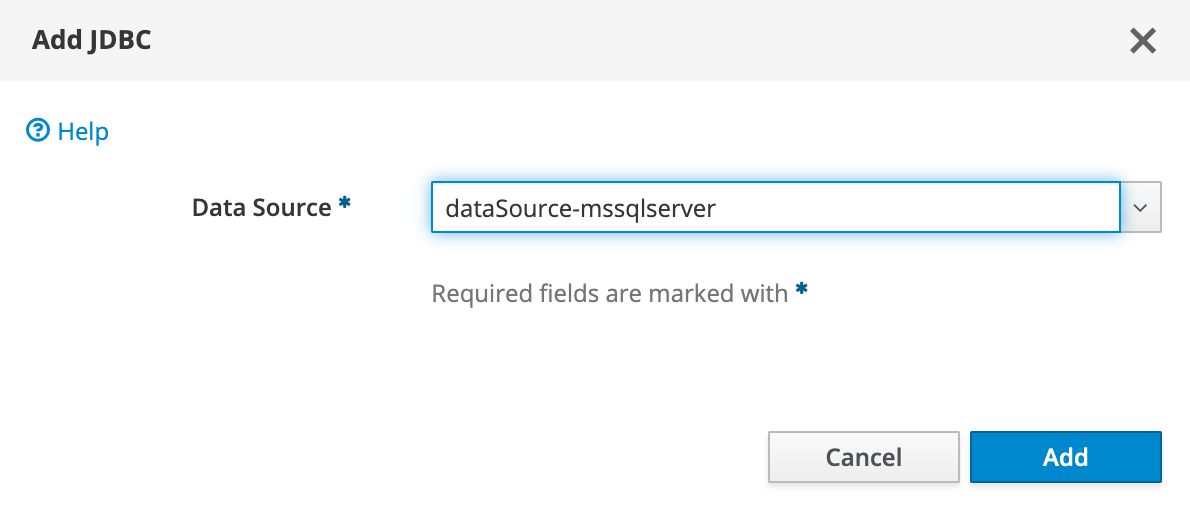
Powinien zostać wyświetlony komunikat o pomyślnym dodaniu JDBC. Jeśli ten komunikat nie jest widoczny, sprawdź centrum powiadomień. Przed kontynuowaniem musisz zobaczyć ten komunikat.
Na stronie Store: JDBC wybierz pozycję Edytuj. Ustaw następujące wartości właściwości:
- Ustaw dialekt na SQL_SERVER.
- Ustaw passivation na wartość OFF.
- Ustaw przeczyszczanie na OFF.
- Ustaw udostępnione na wartość ON.
Wybierz pozycję Zapisz.
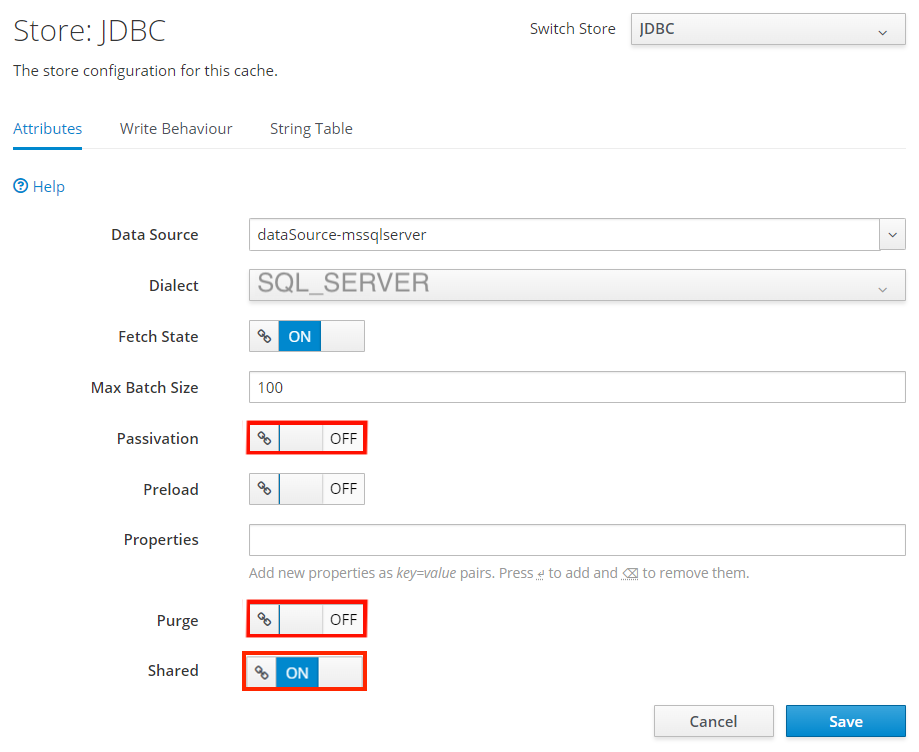
Powinien zostać wyświetlony komunikat o pomyślnym zmodyfikowaniu JDBC. Jeśli ten komunikat nie jest widoczny, sprawdź centrum powiadomień. Przed kontynuowaniem musisz zobaczyć ten komunikat.
Edytuj tabelę ciągów, wybierając Tabela ciągów >Edytuj. Wypełnij następujące wartości, a następnie wybierz Zapisz:
- Ustaw prefiks na w ispn_entry_sessions.
- Ustaw kolumnę identyfikatora/nazwę kolumny identyfikatora na identyfikator.
- Ustaw kolumnę identyfikatora / typ kolumny identyfikatora na VARCHAR(255).
- Ustaw kolumnę danych / nazwę kolumny danych na dane .
- Ustaw typ kolumny danych/kolumny danychVARBINARY(MAX).
- Ustaw kolumnę sygnatury czasowej/nazwę kolumny sygnatury czasowej na znacznik czasu.
- Ustaw typ kolumny sygnatury czasowej/znacznika czasu na BIGINT.

Wszystkie literówki w tym miejscu powodują niepowodzenie całego systemu. Przed kontynuowaniem dokładnie sprawdź wypełnione wartości.
Wybierz pozycję Zapisz.
Powinien zostać wyświetlony komunikat Tabela ciągów pomyślnie zmodyfikowana. Jeśli ten komunikat nie jest widoczny, sprawdź centrum powiadomień. Przed kontynuowaniem musisz zobaczyć ten komunikat.
Wybierz pozycję Konfiguracja w górnym panelu nawigacyjnym. Następnie wybierz pozycję profile >>widoku sieci Web>dystrybucyjnej.
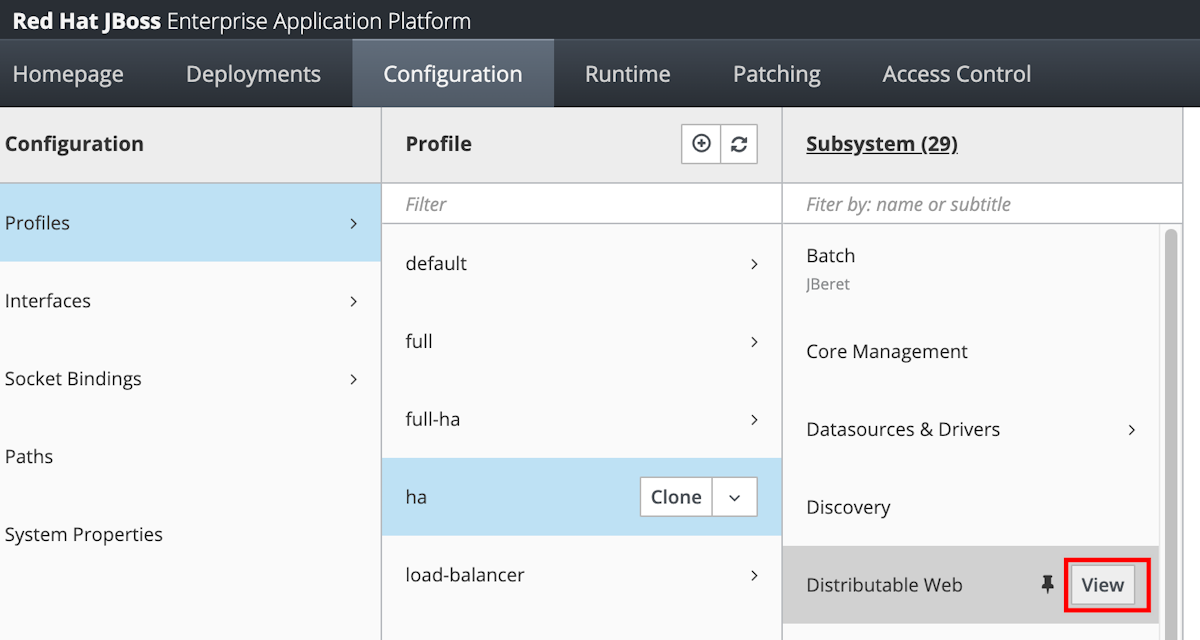
Wybierz Infinspan SSO>domyślnie>Edytuj.
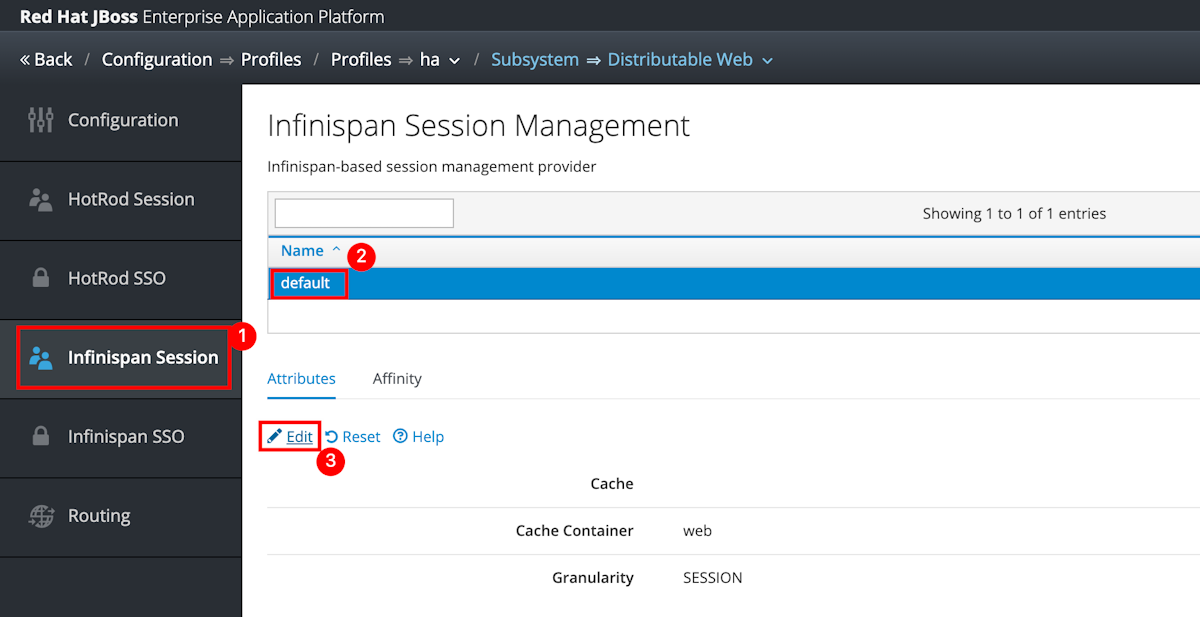
Ustaw wartość Cache na azure-session, a następnie wybierz Zapisz.
Powinien zostać wyświetlony komunikat Infinispan Single Sign On Management pomyślnie zmodyfikowany domyślnie. Jeśli ten komunikat nie jest widoczny, sprawdź centrum powiadomień. Przed kontynuowaniem musisz zobaczyć ten komunikat.
Użyj topologii, aby ponownie załadować lub ponownie uruchomić serwery, których dotyczy problem.
Wybierz pozycję Runtime na panelu nawigacyjnym, a następnie wybierz pozycję Topologia.
Dla każdego wiersza w kolumnie głównej grupy serwerów wybierz serwer, a następnie wybierz pozycję Załaduj ponownie.
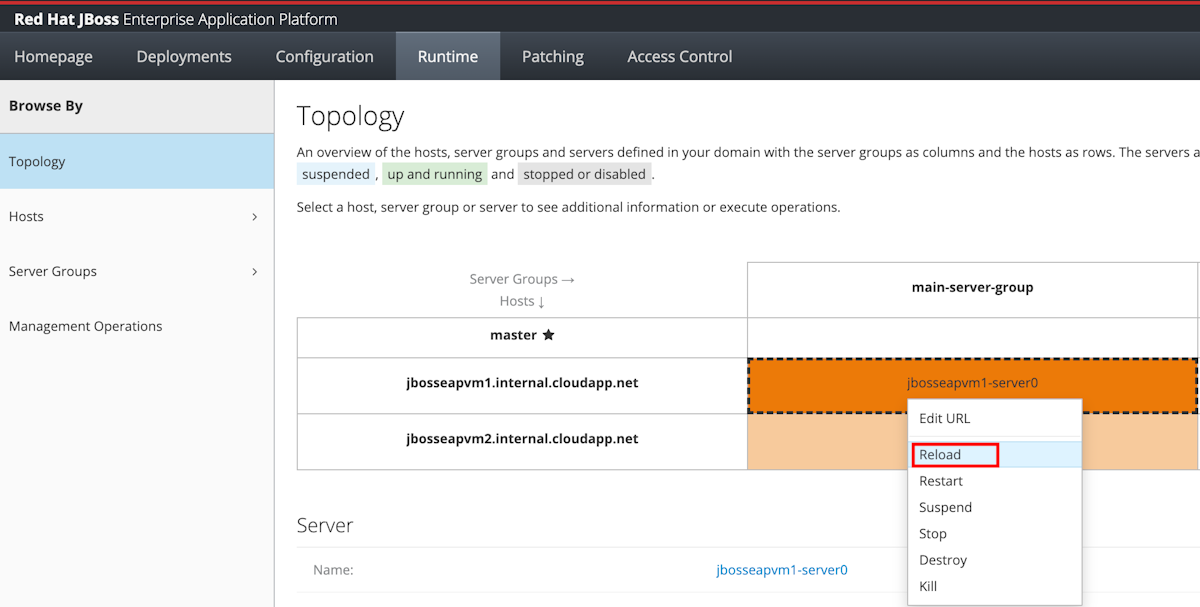
Ponownie załadowane komórki powinny teraz wyświetlać kolor zielony.







Wdrażanie aplikacji w klastrze JBoss EAP
Wykonaj następujące kroki, aby wdrożyć przykładową aplikację JavaEE Cafe w klastrze Red Hat JBoss EAP:
Wykonaj poniższe kroki, aby utworzyć przykład Java EE Cafe. W tych krokach przyjęto założenie, że masz zainstalowane środowisko lokalne z zainstalowanymi usługami Git i Maven.
Użyj następującego polecenia, aby sklonować kod źródłowy z usługi GitHub i wyewidencjonować tag odpowiadający tej wersji artykułu:
git clone https://github.com/Azure/rhel-jboss-templates.git --branch 20240904 --single-branchJeśli zostanie wyświetlony komunikat o błędzie z tekstem
You are in 'detached HEAD' state, możesz bezpiecznie go zignorować.Użyj następującego polecenia, aby skompilować kod źródłowy:
mvn clean install --file rhel-jboss-templates/eap-coffee-app/pom.xmlTo polecenie tworzy plik rhel-jboss-templates/eap-coffee-app/target/javaee-cafe.war. Prześlesz ten plik w następnym kroku.
Wykonaj następujące kroki w konsoli zarządzania Red Hat JBoss Enterprise Application Platform, aby przekazać javaee-cafe.war do repozytorium zawartości:
Na karcie Wdrożenia konsoli zarządzania Red Hat JBoss EAP wybierz pozycję Repozytorium Zawartości na panelu nawigacyjnym.
Wybierz Dodaj, a następnie wybierz Przekaż zawartość.
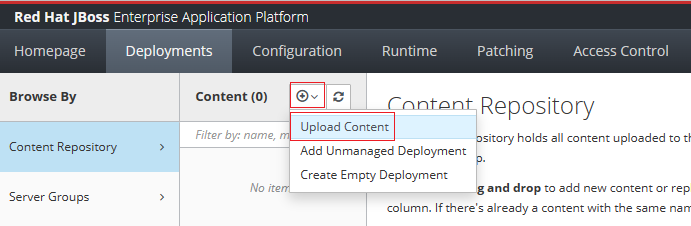
Użyj selektora plików przeglądarki, aby wybrać plik javaee-café.war.
Wybierz pozycję Dalej.
Zaakceptuj wartości domyślne na następnym ekranie, a następnie wybierz pozycję Zakończ.
Wybierz , aby wyświetlić zawartość.
Aby wdrożyć aplikację w
main-server-group, wykonaj następujące kroki:Z witryny Content Repositorywybierz pozycję javaee-café.war.
Otwórz menu rozwijane, a następnie wybierz pozycję Wdróż.
Wybierz main-server-group jako grupę serwerów do wdrożenia javaee-cafe.war.
Wybierz pozycję Wdróż, aby rozpocząć wdrażanie. Powinna zostać wyświetlona informacja podobna do poniższego zrzutu ekranu:



Zakończono wdrażanie aplikacji JavaEE. Wykonaj następujące kroki, aby uzyskać dostęp do aplikacji i zweryfikować wszystkie ustawienia:
W polu wyszukiwania w górnej części portalu Azure wprowadź Grupy zasobów i wybierz Grupy zasobów w wynikach wyszukiwania.
Wybierz nazwę grupy zasobów — na przykład
jboss-eap-cluster-eastus-gzh032124.Wybierz zasób usługi Application Gateway w grupie zasobów.
Skopiuj adres IP publiczny Frontendu z okienka Przegląd .
Skonstruuj adres URL przy użyciu adresu IP i ścieżki — na przykład
http://40.88.26.22/javaee-cafe.Wklej adres URL na pasku nawigacyjnym przeglądarki internetowej, a następnie naciśnij Enter. Powinna zostać wyświetlona strona główna aplikacji JavaEE Cafe.
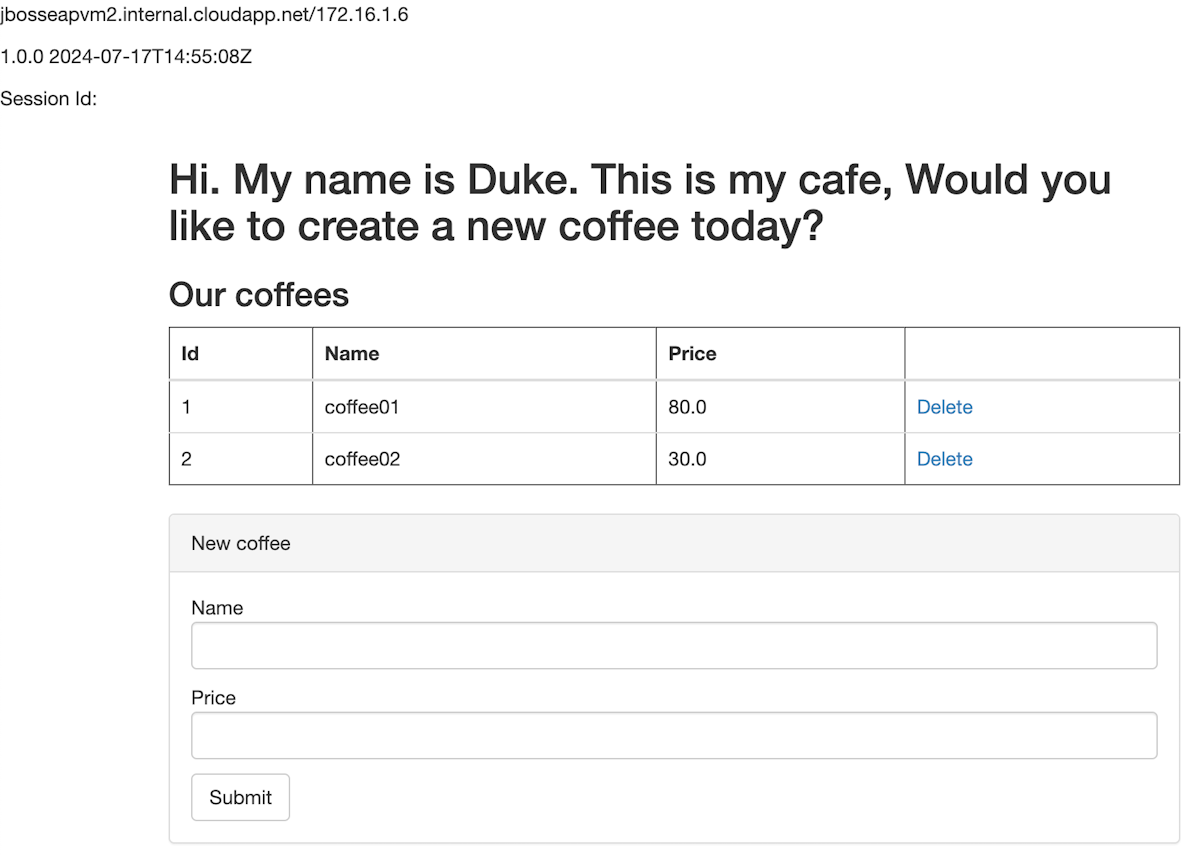
Utwórz dwie kawy o różnych nazwach i cenach. Powinna zostać wyświetlona strona podobna na poniższym zrzucie ekranu:

Konfigurowanie pomocniczego klastra JBoss EAP na maszynach wirtualnych platformy Azure
Wdrażanie pomocniczego klastra JBoss EAP
Wykonaj kroki opisane w Wdrażanie podstawowego klastra JBoss EAP, aby wdrożyć pomocniczy klaster JBoss EAP w sparowanym regionie. W tym przykładzie użyto zachodnich stanów USA 2. W przypadku korzystania z oferty pomocniczy klaster JBoss EAP jest skonfigurowany tak, aby można było przywrócić topologię za pomocą usługi Azure Site Recovery.
Otwórz ofertę klastra JBoss EAP na VM w przeglądarce i wybierz pozycję Utwórz. Powinno zostać wyświetlone okienko Podstawy oferty.
Wykonaj następujące kroki, aby uzupełnić panel Podstawy:
W polu grupa zasobów wybierz Utwórz nowy i wprowadź unikatową wartość dla grupy zasobów — na przykład
jboss-eap-cluster-westus-gzh032124.W sekcji szczegóły instancji, dla pola Region, wybierz West US 2.
Pozostaw inne te same elementy co klaster podstawowy.
W przypadku okienka ustawień protokołu EAP
W przypadku okienka usługi Azure Application Gateway
W panelu Sieci otwórz ustawienie Sieć Wirtualna i wprowadź przestrzeń adresową, która odpowiada wartości klastra podstawowego.

W okienku usługi Database wykonaj następujące czynności:
- Zachowaj to samo co klaster podstawowy.
- Wybierz pozycję Przejrzyj i stwórz.
- Zaczekaj, aż do chwili, gdy Ostateczne sprawdzanie poprawności... zakończy się pomyślnie, a następnie wybierz Utwórz.
Po pewnym czasie powinna zostać wyświetlona strona wdrażania, na której widoczne jest, że wdrażanie jest w toku.
Czyszczenie nieużywanych zasobów w regionie pomocniczym
Wykonaj poniższe kroki, aby wyczyścić zasoby w grupie zasobów o nazwie jboss-eap-cluster-westus-gzh032124, które nie są używane i będą replikowane przez usługę Azure Site Recovery w regionie podstawowym później. Takie podejście może wydawać się marnotrawne, ale gwarantuje, że grupa zasobów pomocniczych ma identyczną konfigurację z podstawową. Rozwiązanie klasy produkcyjnej używałoby większej liczby technologii infrastruktury jako kodu w celu zapewnienia identycznej konfiguracji, ale wykracza poza zakres tego artykułu.
W polu wyszukiwania w górnej części portalu Azure wprowadź Grupy zasobów, a następnie wybierz pozycję Grupy zasobów w wynikach wyszukiwania.
Wybierz nazwę grupy zasobów dla nowo utworzonego regionu pomocniczego.
Obok obszaru tekstowego oznaczonego Filtr dla dowolnego pola...wybierz X, aby usunąć wszystkie filtry.
Wybierz pozycję Dodaj filtr. Ustaw filtru
na typ . Ustaw operator na równa się. Wybierz menu rozwijane obok pola Wartość.
Przełącz pole wyboru Zaznacz wszystkie, dopóki nie zostaną zaznaczone żadne wartości.
Upewnij się, że wybrano wszystkie następujące typy:
- maszyna wirtualna
- dysku
- prywatny punkt końcowy
- interfejs sieciowy
- konto magazynu
Wybierz menu rozwijane obok pola Wartość, aby zamknąć menu rozwijane. Musisz zobaczyć 5 typów zasobów jako wartość Value.
Wybierz i zastosuj.
Zaznacz pole wyboru obok etykiety Nazwa na górze filtrowanej listy.
Wybierz pozycję Usuń.
Wprowadź usuń, aby potwierdzić usunięcie, a następnie wybierz pozycję Usuń. Monitoruj proces w powiadomieniach, dopóki nie zostanie ukończony.
Konfigurowanie odzyskiwania po awarii dla klastra przy użyciu usługi Azure Site Recovery
W tej sekcji skonfigurujesz odzyskiwanie po awarii dla maszyn wirtualnych platformy Azure w klastrze podstawowym przy użyciu usługi Azure Site Recovery, wykonując kroki opisane w Samouczek: Konfigurowanie odzyskiwania po awarii dla maszyn wirtualnych platformy Azure. Potrzebne są tylko następujące sekcje: Tworzenie magazynu usługi Recovery Services, oraz Włączanie replikacji. Zwróć uwagę na następujące kroki, wykonując czynności opisane w artykule, a następnie wróć do tego artykułu po ochronie klastra podstawowego:
Po dotarciu do sekcji Tworzenie magazynu Recovery Serviceswykonaj następujące czynności:
W kroku 5 dla grupy zasobów utwórz nową grupę zasobów o unikatowej nazwie w swojej subskrypcji, na przykład
recovery-service-westus-gzh032124.W kroku 6 dla nazwy magazynu podaj nazwę magazynu — na przykład
recovery-service-vault-westus-gzh032124.W kroku 7 dla Regionu wybierz pozycję Zachodnia USA 2.
Przed wybraniem pozycji Przejrzyj i utwórz w kroku 8 wybierz pozycję Następne: Nadmiarowość. W panelu Nadmiarowość wybierz Geograficznie nadmiarowe dla Nadmiarowości magazynowania kopii zapasowych i Włącz dla Przywracania między regionami.
Notatka
Upewnij się, że wybrano georedundantne dla nadmiarowości magazynu kopii zapasowych i Włącz opcję dla przywracania między regionami w okienku redundancji. W przeciwnym razie magazyn klastra podstawowego nie może być replikowany do regionu pomocniczego.
Włącz usługę Site Recovery, wykonując kroki opisane w sekcji Włączanie usługi Site Recovery.
Po dotarciu do sekcji Włącz replikację, wykonaj następujące kroki:
Aby wybrać ustawienia źródłowe, wykonaj następujące czynności:
W obszarze Regionwybierz pozycję Wschodnie stany USA.
Dla grupy zasobówwybierz zasób, w którym wdrożono główny klaster — na przykład
jboss-eap-cluster-eastus-gzh032124.Notatka
Jeśli żądana grupa zasobów nie znajduje się na liście, możesz najpierw wybrać pozycję Zachodnie stany USA 2 dla regionu , a następnie przełączyć się z powrotem na Wschodnie stany USA.
Pozostaw wartości domyślne innych pól
Wybierz maszyny wirtualne. W sekcji maszyny wirtualne, wybierz wszystkie wymienione maszyny wirtualne (VM) — na przykład, dla celów tego samouczka, w głównym klastrze wdrożono 3 maszyny wirtualne (VM).
Podczas przeglądania ustawień replikacji wykonaj następujące czynności:
Dla lokalizacji docelowej , wybierz pozycję West US 2.
W przypadku docelowej grupy zasobówwybierz grupę zasobów, w której wdrożono magazyn odzyskiwania usługi — na przykład
jboss-eap-cluster-westus-gzh032124.Jeśli oczekiwana grupa zasobów nie jest wyświetlana, wybierz inny region, a następnie wróć do Zachodnie USA 2.
Zanotuj nową sieć wirtualną trybu failover i podsieć trybu failover, która jest mapowana z tej w regionie podstawowym.
Pozostaw wartości domyślne dla innych pól.
Aby zarządzać , wykonaj następujące kroki:
W przypadku polityki replikacji użyj polityki domyślnej 24-godzinnej polityki przechowywania. Możesz również utworzyć nowe zasady dla swojej firmy.
Pozostaw wartości domyślne dla innych pól.
Użyj następujących kroków, aby recenzowaćw
: Po wybraniu Włącz replikację, zwróć uwagę na komunikat Tworzenie zasobów platformy Azure. Ten komunikat wyświetlany jest w dolnej części strony. Nie zamykaj tego panelu. Nie rób nic i zaczekaj na automatyczne zamknięcie okienka. Zostajesz przekierowany na stronę Site Recovery.
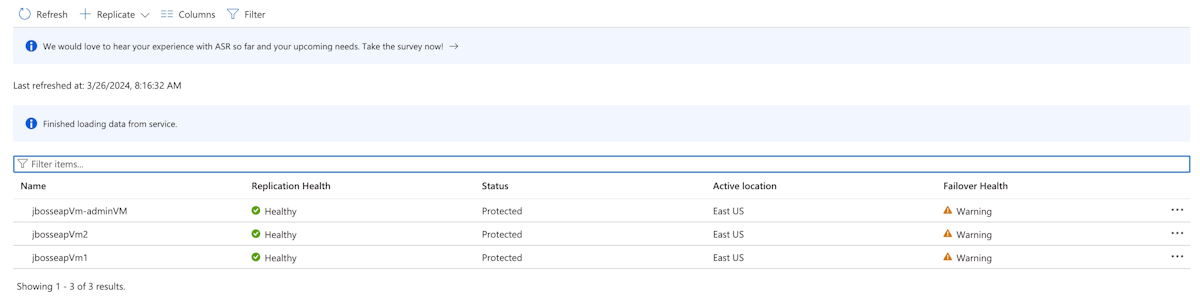
W obszarze Chronione elementywybierz pozycję Zreplikowane elementy. Początkowo nie ma żadnych elementów na liście, ponieważ replikacja jest nadal w toku. Ukończenie replikacji zajmuje około 1 godziny dla tego samouczka. Odświeżaj stronę okresowo, aż zobaczysz, że wszystkie maszyny wirtualne są Chronione, jak pokazano na poniższym zrzucie ekranu.

Następnie stwórz plan odzyskiwania, który uwzględni wszystkie replikowane elementy, aby umożliwić ich wspólne przełączenie w tryb awaryjny. Skorzystaj z instrukcji w Tworzenie planu odzyskiwaniaz następującym dostosowaniem:
- W kroku 2 wprowadź nazwę planu — na przykład
recovery-plan-gzh032124. - W kroku 3 wybierz East US dla źródła i West US 2 dla celu.
- W kroku 4 dla Wybierz elementywybierz wszystkie chronione elementy — na przykład 3 chronione maszyny wirtualne na potrzeby tego samouczka.
Zachowaj otwartą stronę, aby użyć jej później do testowania trybu failover.
Konfigurowanie usługi Azure Traffic Manager
W tej sekcji utworzysz usługę Azure Traffic Manager do dystrybucji ruchu do publicznych aplikacji w różnych regionach świadczenia usługi Azure. Podstawowy punkt końcowy wskazuje publiczny adres IP usługi Application Gateway w regionie podstawowym, a pomocniczy punkt końcowy wskazuje publiczny adres IP usługi Application Gateway w regionie pomocniczym.
Utwórz profil usługi Azure Traffic Manager, postępując zgodnie z instrukcjami w Szybki start: tworzenie profilu usługi Traffic Manager przy użyciu witryny Azure Portal. Potrzebne są tylko następujące sekcje: Tworzenie profilu usługi Traffic Manager i Dodawanie punktów końcowych usługi Traffic Manager. Wykonaj poniższe kroki, przechodząc przez te sekcje, a następnie wróć do tego artykułu po utworzeniu i skonfigurowaniu usługi Azure Traffic Manager.
Gdy dotrzesz do sekcji Tworzenie profilu usługi Traffic Manager, w kroku 2 Tworzenie profilu usługi Traffic Managerwykonaj następujące kroki:
- Zapisz unikatową nazwę profilu usługi Traffic Manager dla Nazwa — na przykład
tm-profile-gzh032124. - Zapisz nową nazwę grupy zasobów dla grupy zasobów ; na przykład
myResourceGroupTM1.
- Zapisz unikatową nazwę profilu usługi Traffic Manager dla Nazwa — na przykład
Po dotarciu do sekcji Dodawanie punktów końcowych usługi Traffic Managerwykonaj następujące czynności:
Po otwarciu profilu usługi Traffic Manager w kroku 2 na stronie Configuration wykonaj następujące kroki:
W przypadku DNS czasu wygaśnięcia (TTL)wprowadź 10.
W sekcji Ustawienia szybkiego przełączania awaryjnego punktu końcowegoużyj następujących wartości:
- W przypadku sondowania wewnętrznegowybierz 10.
- W przypadku Tolerowanej liczby błędówwprowadź 3.
- W przypadku limitu czasu sondy , 5.
Wybierz pozycję Zapisz. Zaczekaj na jego zakończenie.
W kroku 4 dodawania podstawowego punktu końcowego
myPrimaryEndpointwykonaj następujące kroki:Dla typu zasobu docelowegowybierz adres IP publiczny.
Wybierz z listy rozwijanej Wybierz publiczny adres IP i wprowadź nazwę publicznego adresu IP usługi Application Gateway w regionie Wschodnie USA. Powinien zostać wyświetlony jeden dopasowany wpis. Wybierz go dla adresu IP publicznego.
W kroku 6 dodawania pomocniczego punktu końcowego trybu failover
myFailoverEndpointwykonaj następujące kroki:Dla typu zasobu docelowegowybierz adres IP publiczny.
Wybierz listę rozwijaną Wybierz publiczny adres IP i wprowadź nazwę publicznego adresu IP usługi Application Gateway w regionie Zachodnie stany USA 2. Powinien zostać wyświetlony jeden dopasowany wpis. Wybierz go dla adresu IP publicznego.
Poczekaj chwilę. Wybierz pozycję
Odśwież , dopóki stan monitoramonitora dla punktu końcowego nie zostanie Online, a stan monitora monitora dla punktu końcowegojest Obniżona wydajność .
Następnie wykonaj następujące kroki, aby sprawdzić, czy można uzyskać dostęp do przykładowej aplikacji wdrożonej w podstawowym klastrze JBoss EAP z profilu usługi Traffic Manager.
Wybierz pozycję Przegląd utworzonego profilu usługi Traffic Manager.
Sprawdź i skopiuj nazwę DNS profilu usługi Traffic Manager. Dołącz /javaee-café/ do niego. Na przykład
http://tm-profile-gzh032124.trafficmanager.net/javaee-cafe/.Otwórz adres URL na nowej karcie przeglądarki. Powinieneś zobaczyć, że kawa, którą utworzyłeś wcześniej, jest wymieniona na stronie.
Jeśli interfejs użytkownika nie wygląda podobnie, rozwiąż problem przed kontynuowaniem. Pozostaw konsolę otwartą i użyj jej do późniejszego testowania trybu failover.
Teraz możesz skonfigurować profil usługi Traffic Manager. Pozostaw otwartą stronę, aby jej użyć do monitorowania zmiany stanu punktu końcowego podczas późniejszego zdarzenia failover.
Testowanie trybu failover z podstawowego do pomocniczego
Kroki opisane w tej sekcji przetestuj tryb failover przez ręczne przełączenie serwera i klastra usługi Azure SQL Database z podstawowego na pomocniczy, a następnie z powrotem przy użyciu witryny Azure Portal.
Przełączenie w tryb failover do lokacji zapasowej
Najpierw wykonaj następujące kroki, aby przejść w tryb failover usługi Azure SQL Database z serwera podstawowego do serwera pomocniczego:
- Przejdź do zakładki przeglądarki grupy przełączania awaryjnego usługi Azure SQL Database, na przykład
failovergroup-gzh032124. - Wybierz failover>tak.
- Zaczekaj na jego zakończenie.
Następnie wykonaj następujące kroki, aby przejść w tryb failover klastra JBoss EAP z planem odzyskiwania:
W polu wyszukiwania w górnej części witryny Azure Portal wprowadź magazyny usługi Recovery Services i wybierz magazyny usługi Recovery Services w wynikach wyszukiwania.
Wybierz nazwę magazynu usługi Recovery Services — na przykład
recovery-service-vault-westus-gzh032124.W obszarze Zarządzajwybierz Plany odzyskiwania (Site Recovery). Wybierz utworzony plan odzyskiwania: na przykład
recovery-plan-gzh032124.Wybierz opcję failover. Wybierz Rozumiem ryzyko. Pomiń test przełączenia awaryjnego.. Pozostaw wartości domyślne dla innych wartości. Wybierz pozycję OK.
Notatka
Opcjonalnie możesz uruchomić Test failover i Test czyszczenia failover, aby upewnić się, że wszystko działa zgodnie z oczekiwaniami przed trybem failover. Aby uzyskać więcej informacji, zobacz Samouczek : przeprowadzenie próbnego odzyskiwania po awarii dla Maszyn Wirtualnych Platformy Azure. Ten samouczek używa bezpośrednio Failover w celu uproszczenia ćwiczenia.
Monitoruj proces przełączania awaryjnego w powiadomieniach, dopóki nie zostanie zakończony. Wykonanie tego samouczka zajmuje około 10 minut.
Zatwierdzenie przełączenia awaryjnego
Upewnij się, że kroki opisane w poprzedniej sekcji zostały wykonane pomyślnie. Następnie wykonaj poniższe kroki, aby zatwierdzić operację przełączenia awaryjnego:
W polu wyszukiwania w górnej części witryny Azure Portal wpisz magazyny usługi Recovery Services i wybierz je z wyników wyszukiwania.
Wybierz skarbiec usługi Recovery Services — na przykład
recovery-service-vault-westus-gzh032124.W sekcji Zarządzanie wybierz pozycję Plany Odzyskiwania (Site Recovery).
Wybierz plan odzyskiwania — na przykład
recovery-plan-gzh032124.Wybierz Zatwierdź, a potem OK.
Monitoruj powiadomienia, aż proces zostanie ukończony.

Wybierz elementy w planie odzyskiwania. Należy zobaczyć 3 elementy oznaczone jako zatwierdzone awaryjne przełączenie.

Wyłączanie replikacji
Wykonaj następujące kroki, aby wyłączyć replikację elementów w planie odzyskiwania i usunąć plan odzyskiwania:
- Dla każdego elementu w Elementy w planie odzyskiwaniakliknij go prawym przyciskiem myszy, a następnie wybierz Wyłącz replikację.
- Jeśli zostanie wyświetlony monit o podanie przyczyny lub przyczyn wyłączenia ochrony tej maszyny wirtualnej, wybierz preferowaną opcję — na przykład zakończyłem migrację mojej aplikacji. Wybierz pozycję OK.
- Powtórz krok 1, dopóki nie wyłączysz replikacji dla wszystkich elementów.
- Monitoruj proces w powiadomieniach, dopóki nie zostanie ukończony.
- Wybierz Przegląd>Usuń. Wybierz pozycję Tak, aby potwierdzić usunięcie.
Ponowne zabezpieczenie witryny przełączania awaryjnego
Teraz region pomocniczy, będący miejscem przełączenia awaryjnego, jest aktywny, więc należy go ponownie zabezpieczyć w regionie podstawowym.
Najpierw wyczyść zasoby w grupie zasobów o nazwie jboss-eap-cluster-eastus-gzh032124, które nie są już używane.
W polu wyszukiwania w górnej części portalu Azure wprowadź Grupy zasobów, a następnie wybierz pozycję Grupy zasobów w wynikach wyszukiwania.
Wybierz nazwę grupy zasobów dla nowo utworzonego regionu pomocniczego.
Obok obszaru tekstowego oznaczonego Filtr dla dowolnego pola...wybierz X, aby usunąć wszystkie filtry.
Wybierz pozycję Dodaj filtr. Ustaw filtru
na typ . Ustaw operator na równa się. Wybierz menu rozwijane obok pola Wartość.
Przełącz pole wyboru Zaznacz wszystkie, dopóki nie zostaną zaznaczone żadne wartości.
Upewnij się, że wybrano wszystkie następujące typy:
- maszyna wirtualna
- dysku
- prywatny punkt końcowy
- interfejs sieciowy
- konto magazynu
Wybierz menu rozwijane obok pola Wartość, aby zamknąć menu rozwijane. Musisz zobaczyć 5 typów zasobów jako wartość Value.
Wybierz i zastosuj.
Zaznacz pole wyboru obok etykiety Nazwa na górze filtrowanej listy.
Wybierz pozycję Usuń.
Wprowadź usuń, aby potwierdzić usunięcie, a następnie wybierz pozycję Usuń. Monitoruj proces w powiadomieniach, dopóki nie zostanie ukończony.
Następnie wykonaj te same kroki w Konfigurowanie odzyskiwania po awarii dla klastra przy użyciu usługi Azure Site Recovery w regionie podstawowym, z wyjątkiem następujących różnic:
Aby utworzyć magazyn Recovery Services , wykonaj następujące kroki:
- Wybierz grupę zasobów, która została wdrożona w regionie podstawowym — na przykład
jboss-eap-cluster-eastus-gzh032124. - Wprowadź inną nazwę sejfu usługi — przykładowo
recovery-service-vault-eastus-gzh032124. - Wybierz Wschodnie stany USA dla regionu .
- Wybierz grupę zasobów, która została wdrożona w regionie podstawowym — na przykład
W przypadku Włączreplikacji wykonaj następujące kroki:
Dla regionu w zasobie , wybierz pozycję West US 2.
W Ustawieniach replikacji, wykonaj następujące czynności:
W przypadku docelowej grupy zasobówwybierz istniejącą grupę zasobów, wdrożoną w regionie podstawowym, na przykład
jboss-eap-cluster-eastus-gzh032124.Dla sieci wirtualnej przełączania awaryjnego, wybierz istniejącą sieć wirtualną w regionie podstawowym.
Dla Utwórz plan odzyskiwania, dla Source, wybierz Zachodnie Stany USA 2, a dla Target, wybierz Wschodnie Stany USA.
Notatka
Możesz zauważyć, że usługa Azure Site Recovery obsługuje ponowne włączanie ochrony maszyn wirtualnych, gdy istnieje docelowa maszyna wirtualna. Aby uzyskać więcej informacji, zobacz sekcję Ponowne włączanie ochrony maszyny wirtualnejSamouczek: przełączanie maszyn wirtualnych platformy Azure w tryb failover do regionu pomocniczego. Jednak nie działa, gdy jedyne zmiany między dyskiem źródłowym a dyskiem docelowym są synchronizowane dla klastra JBoss EAP na podstawie wyniku weryfikacji. Ten samouczek ustanawia nową replikację z lokalizacji dodatkowej do lokalizacji głównej po awarii, w której całe dyski są kopiowane z regionu awaryjnego do regionu podstawowego. Aby uzyskać więcej informacji, zobacz sekcję Co się dzieje podczas ponownej ochrony? w Ponowna ochrona maszyn wirtualnych w trybie failover na platformie Azure do regionu podstawowego.
Przełączenie z powrotem na główną lokalizację
Wykonaj te same kroki w sekcji Przełączenie awaryjne do witryny dodatkowej, aby przywrócić do działania w witrynie głównej, w tym serwer bazy danych i klaster, z wyjątkiem następujących różnic:
Wybierz magazyn usługi Recovery Service wdrożony w regionie podstawowym — na przykład
recovery-service-vault-eastus-gzh032124.Wybierz grupę zasobów, która została wdrożona w regionie podstawowym — na przykład
jboss-eap-cluster-eastus-gzh032124.W sekcji Zatwierdź przełączenie awaryjne, wybierz magazyn usług Recovery Services wdrożony w lokalizacji podstawowej — na przykład
recovery-service-vault-eastus-gzh032124.W profilu usługi Traffic Manager powinieneś zobaczyć, że punkt końcowy
myPrimaryEndpointstaje się Online, a punkt końcowymyFailoverEndpointstaje się Obniżona wydajność.W sekcji Przywracanie ochrony dla witryny failoverwykonaj następujące czynności:
Region podstawowy to lokacja trybu failover i aktywna, dlatego należy ponownie chronić ją w regionie pomocniczym.
Wyczyść zasób wdrożony w regionie pomocniczym, na przykład zasób wdrożony w
jboss-eap-cluster-westus-gzh032124.Wykonaj te same kroki opisane w "Konfigurowanie odzyskiwania po awarii dla klastra przy użyciu usługi Azure Site Recovery", aby chronić region podstawowy w regionie pomocniczym, z wyjątkiem następujących kroków:
Pomiń kroki opisane w Tworzenie magazynu usługi Recovery Services, ponieważ utworzono już magazyn usługi Recovery Services — na przykład
recovery-service-vault-westus-gzh032124.W przypadku Włącz replikację>ustawienia replikacji>tryb failover sieci wirtualnej, wybierz istniejącą sieć wirtualną w regionie pomocniczym.
Czyszczenie zasobów
Jeśli nie zamierzasz nadal korzystać z klastrów JBoss EAP i innych składników, wykonaj następujące kroki, aby usunąć grupy zasobów, aby wyczyścić zasoby używane w tym samouczku:
Wprowadź nazwę grupy zasobów serwerów usługi Azure SQL Database — na przykład
sqlserver-rg-gzh032124— w polu wyszukiwania w górnej części witryny Azure Portal. Następnie wybierz dopasowaną grupę zasobów z wyników wyszukiwania.Wybierz pozycję Usuń grupę zasobów.
W wprowadź nazwę grupy zasobów, aby potwierdzić usunięcie, wprowadź nazwę grupy zasobów.
Wybierz pozycję Usuń.
Powtórz kroki 1–4 dla grupy zasobów usługi Traffic Manager — na przykład
myResourceGroupTM1.W polu wyszukiwania w górnej części witryny Azure Portal wprowadź magazyny usługi Recovery Services, a następnie wybierz magazyny usługi Recovery Services w wynikach wyszukiwania.
Wybierz nazwę magazynu usługi Recovery Services — na przykład
recovery-service-vault-westus-gzh032124.W obszarze Zarządzajwybierz Plany odzyskiwania (Site Recovery). Wybierz utworzony plan odzyskiwania: na przykład
recovery-plan-gzh032124.Wykonaj te same kroki w sekcji Wyłącz replikacji, aby usunąć blokady na replikowanych elementach.
Powtórz kroki 1–4 dla grupy zasobów podstawowego klastra JBoss EAP — na przykład
jboss-eap-cluster-westus-gzh032124.Powtórz kroki 1–4 dla grupy zasobów pomocniczego klastra JBoss EAP — na przykład
jboss-eap-cluster-eastus-gzh032124.
Następne kroki
W tym samouczku skonfigurujesz rozwiązanie wysokiej dostępności i odzyskiwania po awarii, składające się z warstwy infrastruktury aplikacyjnej aktywno-pasywnej oraz warstwy bazy danych aktywno-pasywnej, w którym obie warstwy obejmują dwie różne lokalizacje geograficzne. W pierwszej lokacji zarówno warstwa infrastruktury aplikacji, jak i warstwa bazy danych są aktywne. W drugiej lokacji domena pomocnicza jest przywracana za pomocą usługi Azure Site Recovery, a pomocnicza baza danych jest w trybie oczekiwania.
Zobacz poniższe odniesienia, aby uzyskać więcej opcji tworzenia rozwiązań HA/DR i działania JBoss EAP na platformie Azure.