Typy wizualizacji
W tym artykule opisano typy wizualizacji dostępnych do użycia w notesach usługi Azure Databricks i w usłudze Databricks SQL oraz pokazano, jak utworzyć przykład każdego typu wizualizacji.
Uwaga
Aby dowiedzieć się więcej o typach wizualizacji dostępnych dla pulpitów nawigacyjnych AI/BI, zobacz Typy wizualizacji pulpitu nawigacyjnego.
Wykres słupkowy
Wykresy słupkowe reprezentują zmianę metryk w czasie lub pokazujące proporcjonalność, podobnie jak wykres kołowy.
Uwaga
Wykresy słupkowe obsługują agregacje zaplecza, zapewniając obsługę zapytań zwracających ponad 64 000 wierszy danych bez obcinania zestawu wyników.
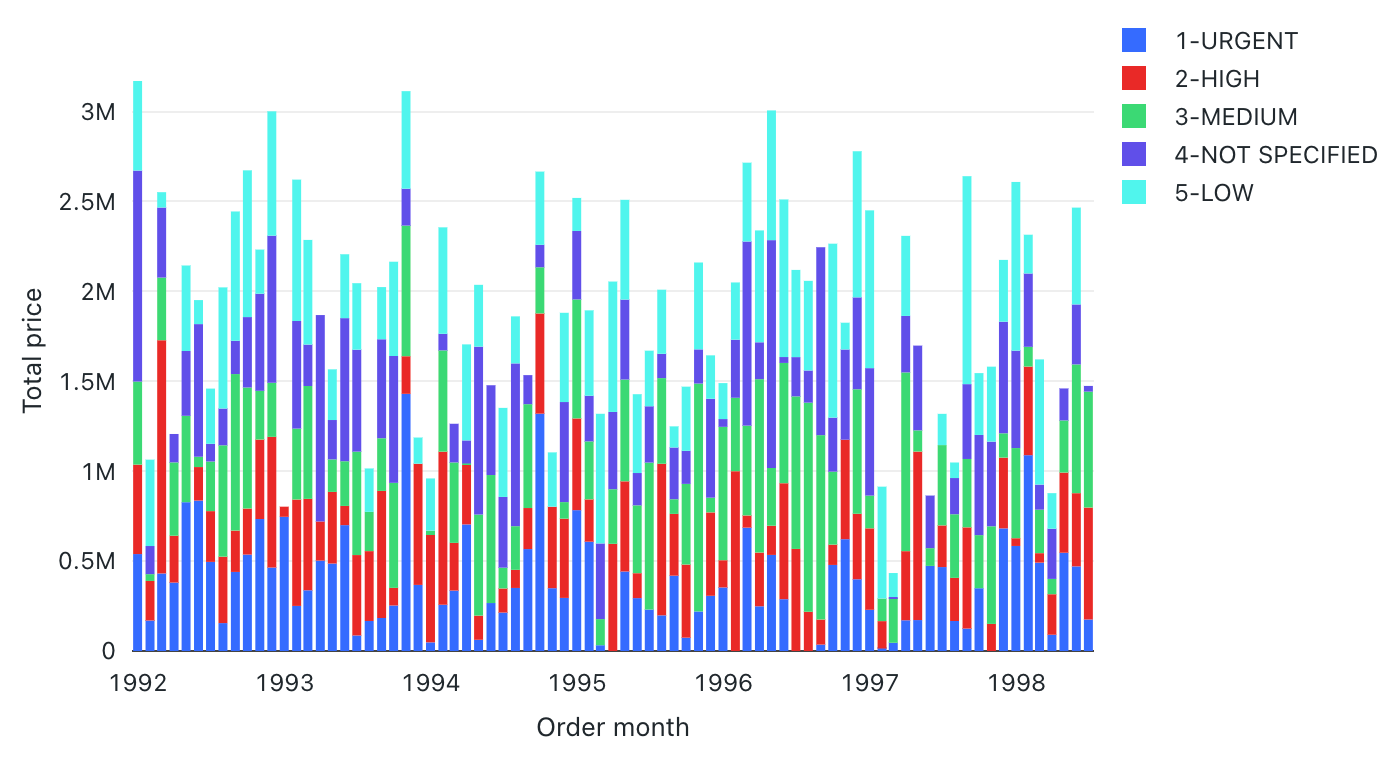
Wartości konfiguracji: dla tej wizualizacji wykresu słupkowego ustawiono następujące wartości:
- Kolumna X:
- Kolumna zestawu danych:
o_orderdate - Poziom daty:
Months
- Kolumna zestawu danych:
- Kolumny Y:
- Kolumna zestawu danych:
o_totalprice - Typ agregacji:
Sum
- Kolumna zestawu danych:
- Grupuj według (kolumna zestawu danych):
o_orderpriority - Układania:
Stack - Nazwa osi X (zastąpij wartość domyślną):
Order month - Nazwa osi Y (zastąpij wartość domyślną):
Total price
Opcje konfiguracji: aby uzyskać opcje konfiguracji wykresu słupkowego, zobacz opcje konfiguracji wykresu.
Zapytanie SQL: w przypadku tej wizualizacji wykresu słupkowego do wygenerowania zestawu danych użyto następującego zapytania SQL.
select * from samples.tpch.orders
Wykres liniowy
Wykresy liniowe przedstawiają zmianę w co najmniej jednej metryce w czasie.
Uwaga
Wykresy liniowe obsługują agregacje zaplecza, zapewniając obsługę zapytań zwracających ponad 64 000 wierszy danych bez obcinania zestawu wyników.
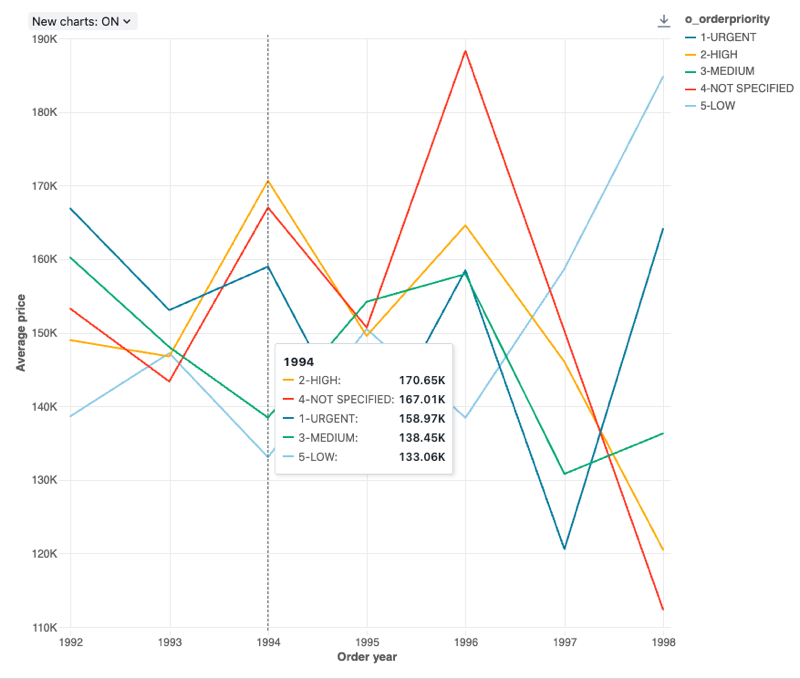
Wartości konfiguracji: dla tej wizualizacji wykresu liniowego ustawiono następujące wartości:
- Kolumna X:
- Kolumna zestawu danych:
o_orderdate - Poziom daty:
Years
- Kolumna zestawu danych:
- Kolumny Y:
- Kolumna zestawu danych:
o_totalprice - Typ agregacji:
Average
- Kolumna zestawu danych:
- Grupuj według (kolumna zestawu danych):
o_orderpriority - Nazwa osi X (zastąpij wartość domyślną):
Order year - Nazwa osi Y (zastąpij wartość domyślną):
Average price
Opcje konfiguracji: aby uzyskać opcje konfiguracji wykresu liniowego, zobacz Opcje konfiguracji wykresu.
Zapytanie SQL: w przypadku tej wizualizacji wykresu liniowego do wygenerowania zestawu danych użyto następującego zapytania SQL.
select * from samples.tpch.orders
Wykres warstwowy
Wykresy warstwowe łączą wykres liniowy i słupkowy, aby pokazać, jak wartości liczbowe jednej lub większej liczby grup zmieniają się w czasie progresji drugiej zmiennej. Są one często używane do pokazywania zmian lejka sprzedaży w czasie.
Uwaga
Wykresy warstwowe obsługują agregacje zaplecza, zapewniając obsługę zapytań zwracających ponad 64 000 wierszy danych bez obcinania zestawu wyników.
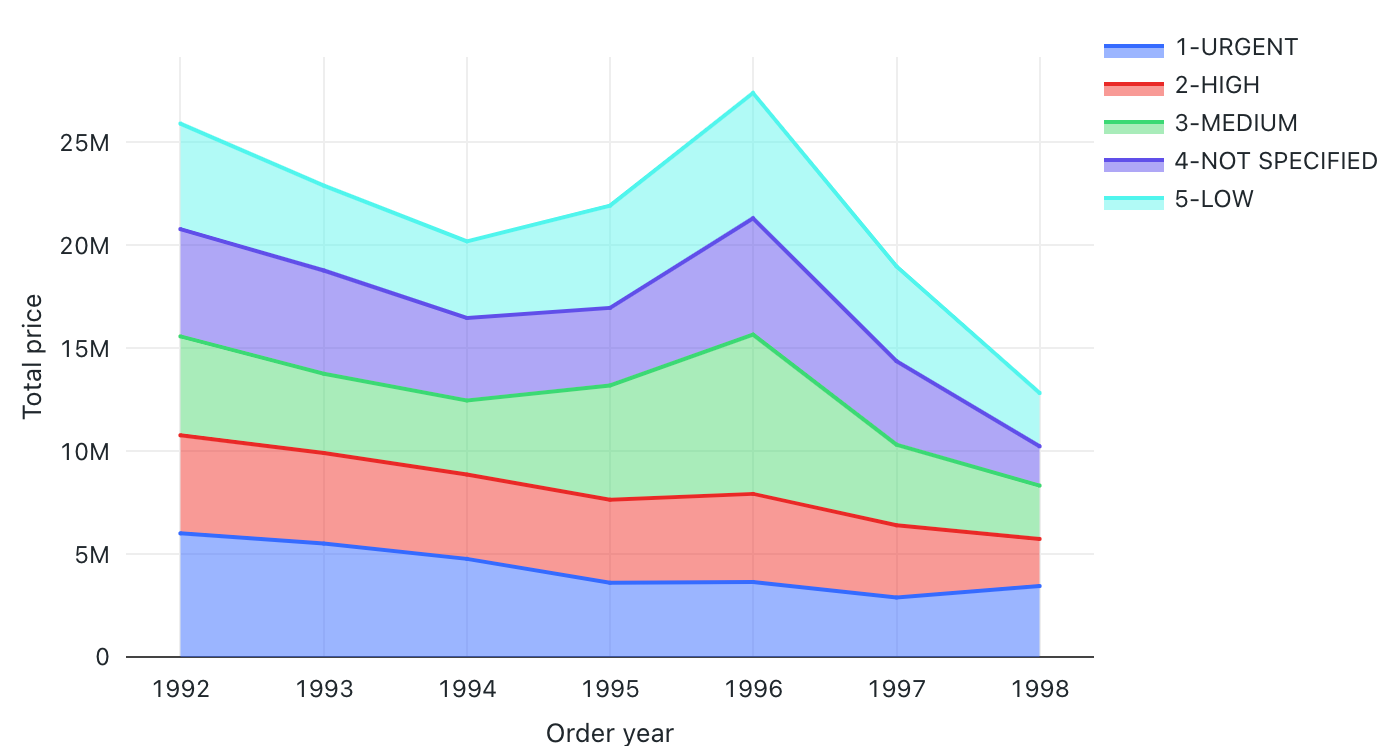
Wartości konfiguracji: dla tej wizualizacji wykresu warstwowego ustawiono następujące wartości:
- Kolumna X:
- Kolumna zestawu danych:
o_orderdate - Poziom daty:
Years
- Kolumna zestawu danych:
- Kolumny Y:
- Kolumna zestawu danych:
o_totalprice - Typ agregacji:
Sum
- Kolumna zestawu danych:
- Grupuj według (kolumna zestawu danych):
o_orderpriority - Układania:
Stack - Nazwa osi X (zastąpij wartość domyślną):
Order year - Nazwa osi Y (zastąpij wartość domyślną):
Total price
Opcje konfiguracji: aby uzyskać opcje konfiguracji wykresu warstwowego, zobacz Opcje konfiguracji wykresu.
Zapytanie SQL: w przypadku tej wizualizacji wykresu warstwowego do wygenerowania zestawu danych użyto następującego zapytania SQL.
select * from samples.tpch.orders
Wykresy kołowe
Wykresy kołowe pokazują proporcjonalność między metrykami. Nie są one przeznaczone do przekazywania danych szeregów czasowych.
Uwaga
Wykresy kołowe obsługują agregacje zaplecza, zapewniając obsługę zapytań zwracających ponad 64 000 wierszy danych bez obcinania zestawu wyników.
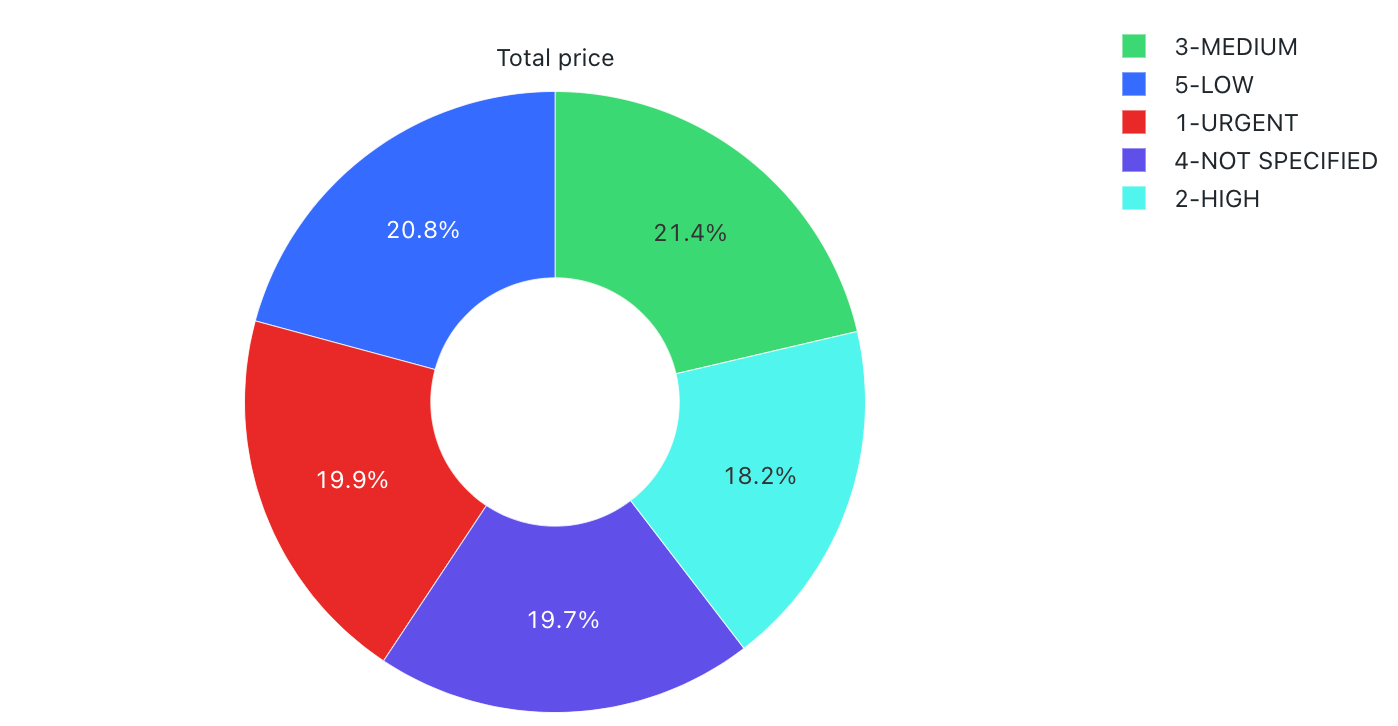
Wartości konfiguracji: dla tej wizualizacji wykresu kołowego ustawiono następujące wartości:
- Kolumna X (kolumna zestawu danych):
o_orderpriority - Kolumny Y:
- Kolumna zestawu danych:
o_totalprice - Typ agregacji:
Sum
- Kolumna zestawu danych:
- Etykieta (przesłaniaj wartość domyślną):
Total price
Opcje konfiguracji: w przypadku opcji konfiguracji wykresu kołowego zobacz opcje konfiguracji wykresu.
Zapytanie SQL: w przypadku tej wizualizacji wykresu kołowego do wygenerowania zestawu danych użyto następującego zapytania SQL.
select * from samples.tpch.orders
Wykresy histogramu
Histogram kreśli częstotliwość występowania danej wartości w zestawie danych. Histogram pomaga zrozumieć, czy zestaw danych zawiera wartości, które są grupowane wokół niewielkiej liczby zakresów, czy są bardziej rozłożone. Histogram jest wyświetlany jako wykres słupkowy, w którym kontrolujesz liczbę odrębnych słupków (nazywanych również pojemnikami).
Uwaga
Wykresy histogramu obsługują agregacje zaplecza, zapewniając obsługę zapytań zwracających ponad 64 000 wierszy danych bez obcinania zestawu wyników.
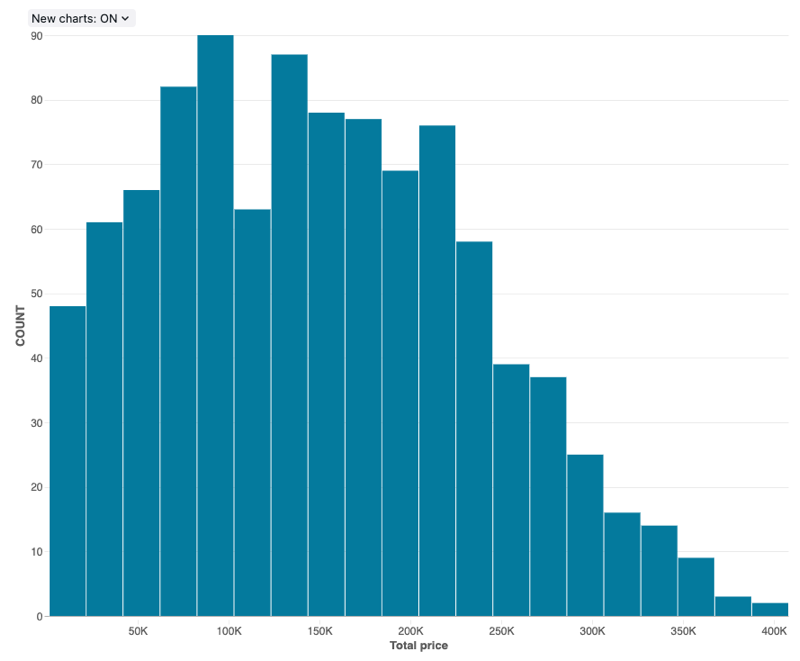
Wartości konfiguracji: dla tej wizualizacji wykresu histogramu ustawiono następujące wartości:
- Kolumna X (kolumna zestawu danych):
o_totalprice - Liczba pojemników: 20
- Nazwa osi X (zastąpij wartość domyślną):
Total price
Opcje konfiguracji: Aby uzyskać opcje konfiguracji wykresu histogramu, zobacz opcje konfiguracji wykresu histogramu.
Zapytanie SQL: na potrzeby tej wizualizacji wykresu histogramu do wygenerowania zestawu danych użyto następującego zapytania SQL.
select * from samples.tpch.orders
Wykres mapy cieplnej
Wykresy cieplne łączą funkcje wykresów słupkowych, stosów i wykresów bąbelkowych, które umożliwiają wizualizowanie danych liczbowych przy użyciu kolorów. Wspólna paleta kolorów mapy cieplnej pokazuje najwyższe wartości przy użyciu cieplejszych kolorów, takich jak pomarańczowy lub czerwony, a najniższe wartości przy użyciu chłodniejszych kolorów, takich jak niebieski lub fioletowy.
Rozważmy na przykład następującą mapę cieplną, która wizualizuje najczęściej występujące odległości przejazdów taksówką każdego dnia i grupuje wyniki według dnia tygodnia, odległości i całkowitej taryfy.
Uwaga
Wykresy mapy cieplnej obsługują agregacje zaplecza, zapewniając obsługę zapytań zwracających ponad 64 000 wierszy danych bez obcinania zestawu wyników.
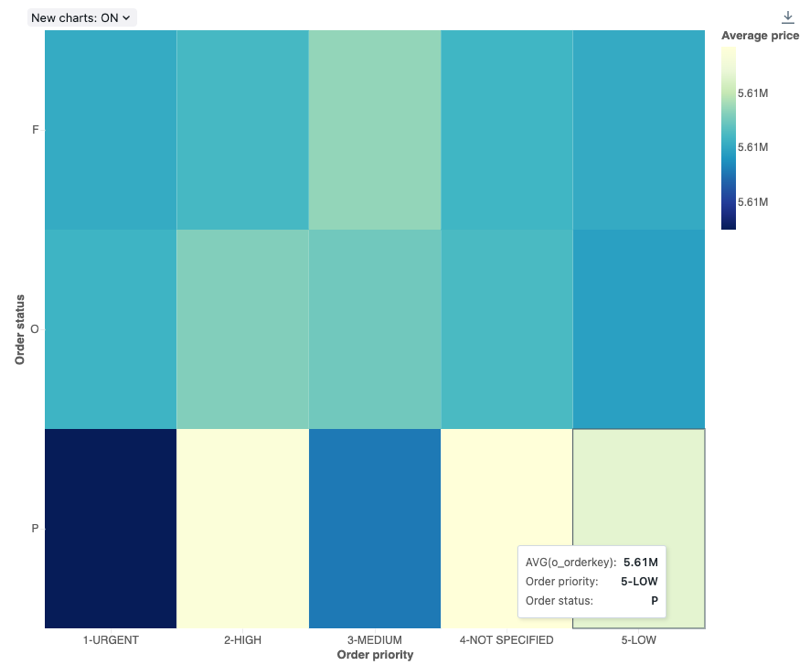
Wartości konfiguracji: dla tej wizualizacji wykresu mapy cieplnej ustawiono następujące wartości:
- Kolumna X (kolumna zestawu danych):
o_orderpriority - Kolumny Y (kolumna zestawu danych):
o_orderstatus - Kolumna koloru:
- Kolumna zestawu danych:
o_totalprice - Typ agregacji:
Average
- Kolumna zestawu danych:
- Nazwa osi X (zastąpij wartość domyślną):
Order priority - Nazwa osi Y (zastępowanie wartości domyślnej):
Order status - Nazwa koloru (zmiana wartości domyślnej):
Average price - Schemat kolorów (przesłaniaj wartość domyślną):
YIGnBu
Opcje konfiguracji: w przypadku opcji konfiguracji mapy cieplnej zobacz opcje konfiguracji wykresu cieplnego.
Zapytanie SQL: w przypadku tej wizualizacji wykresu mapy cieplnej do wygenerowania zestawu danych użyto następującego zapytania SQL.
select * from samples.tpch.orders
Wykres punktowy
Wizualizacje punktowe są często używane do pokazywania relacji między dwiema zmiennymi liczbowymi. Ponadto trzeci wymiar można kodować za pomocą koloru, aby pokazać, jak zmienne liczbowe różnią się między grupami.
Uwaga
Wykresy punktowe obsługują agregacje zaplecza, zapewniając obsługę zapytań zwracających ponad 64 000 wierszy danych bez obcinania zestawu wyników.
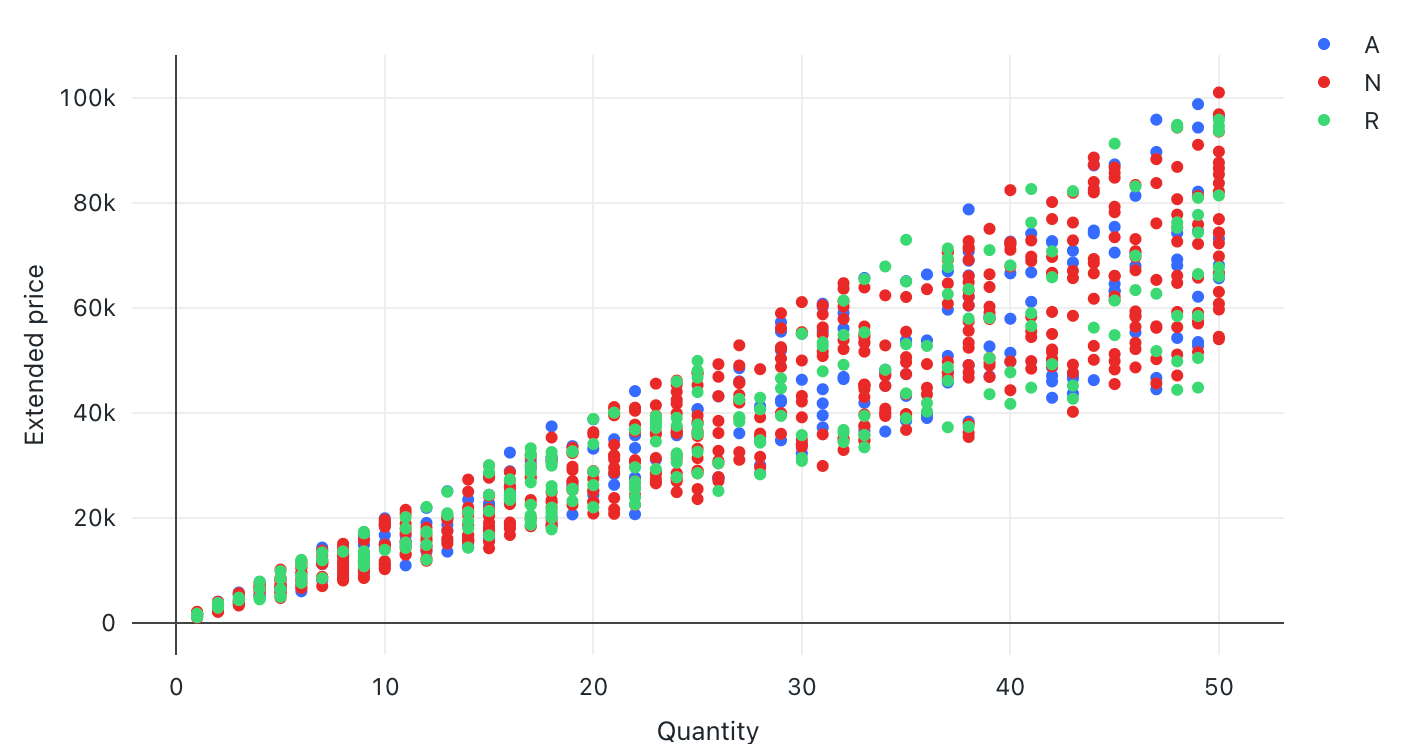
Wartości konfiguracji: dla tej wizualizacji wykresu punktowego ustawiono następujące wartości:
- Kolumna X (kolumna zestawu danych):
l_quantity - Kolumna Y (kolumna zestawu danych):
l_extendedprice - Grupuj według (kolumna zestawu danych):
l_returnflag - Nazwa osi X (zastąpij wartość domyślną):
Quantity - Nazwa osi Y (zastąpij wartość domyślną):
Extended price
Opcje konfiguracji: aby uzyskać opcje konfiguracji wykresu punktowego, zobacz Opcje konfiguracji wykresu.
Zapytanie SQL: w przypadku tej wizualizacji wykresu punktowego do wygenerowania zestawu danych użyto następującego zapytania SQL.
select * from samples.tpch.lineitem
Bąbelkowym
Wykresy bąbelkowe to wykresy punktowe, w których rozmiar każdego znacznika punktu odzwierciedla odpowiednią metrykę.
Uwaga
Wykresy bąbelkowe obsługują agregacje zaplecza, zapewniając obsługę zapytań zwracających ponad 64 000 wierszy danych bez obcinania zestawu wyników.
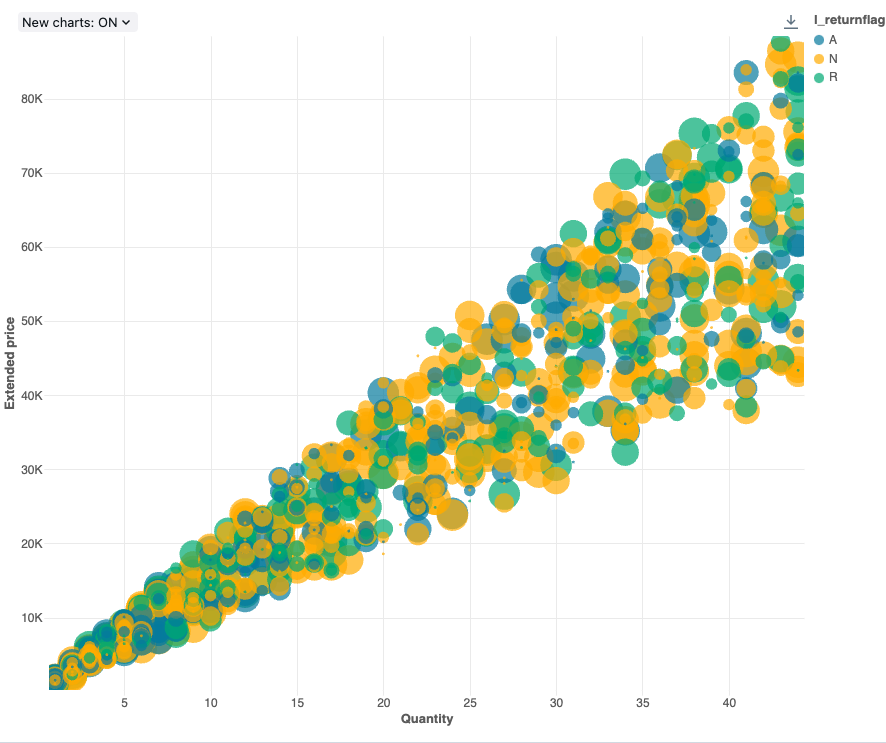
Wartości konfiguracji: dla tej wizualizacji wykresu bąbelkowego ustawiono następujące wartości:
- X (kolumna zestawu danych):
l_quantity - Kolumny Y (kolumna zestawu danych):
l_extendedprice - Grupuj według (kolumna zestawu danych):
l_returnflag - Kolumna rozmiaru bąbelka (kolumna zestawu danych):
l_tax - Współczynnik rozmiaru bąbelka: 20
- Rozmiar bąbelka proporcjonalny do:
Area - Nazwa osi X (zastąpij wartość domyślną):
Quantity - Nazwa osi Y (zastąpij wartość domyślną):
Extended price
Opcje konfiguracji: w przypadku opcji konfiguracji wykresu bąbelkowego zobacz opcje konfiguracji wykresu.
Zapytanie SQL: w przypadku tej wizualizacji wykresu bąbelkowego do wygenerowania zestawu danych użyto następującego zapytania SQL.
select * from samples.tpch.lineitem where l_quantity < 45
Wykres skrzynkowy
Wizualizacja wykresu skrzynkowego przedstawia podsumowanie rozkładu danych liczbowych, opcjonalnie pogrupowane według kategorii. Korzystając z wizualizacji wykresu skrzynkowego, można szybko porównać zakresy wartości między kategoriami i wizualizować lokalność, rozkładać i niesymetryczności grup wartości za pomocą ich kwartylów. W każdym polu ciemniejszy wiersz pokazuje zakres międzykwartylowy. Aby uzyskać więcej informacji na temat interpretowania wizualizacji wykresu skrzynkowego, zobacz artykuł Box chart w witrynie Wikipedia.
Uwaga
Wykresy skrzynkowe obsługują tylko agregację dla maksymalnie 64 000 wierszy. Jeśli zestaw danych jest większy niż 64 000 wierszy, dane zostaną obcięte.
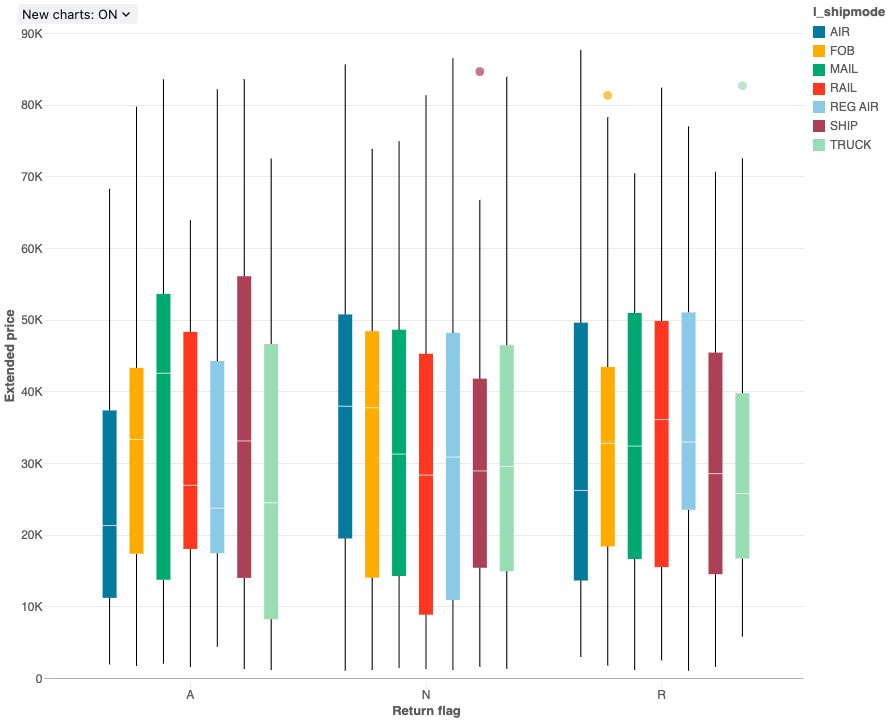
Wartości konfiguracji: dla tej wizualizacji wykresu pola ustawiono następujące wartości:
- Kolumna X (kolumna zestawu danych):
l_returnflag - Kolumny Y (kolumna zestawu danych):
l_extendedprice - Grupuj według (kolumna zestawu danych):
l_shipmode - Nazwa osi X (zastąpij wartość domyślną):
Return flag - Nazwa osi Y (zastąpij wartość domyślną):
Extended price
Opcje konfiguracji: aby uzyskać opcje konfiguracji wykresu skrzynkowego, zobacz opcje konfiguracji wykresu skrzynkowego.
Zapytanie SQL: w przypadku tej wizualizacji wykresu pola do wygenerowania zestawu danych użyto następującego zapytania SQL.
select * from samples.tpch.lineitem
Wykres kombi
Wykresy kombi łączą wykresy liniowe i słupkowe , aby przedstawić zmiany w czasie z proporcjonalnością.
Uwaga
Wykresy kombi obsługują agregacje zaplecza, zapewniając obsługę zapytań zwracających ponad 64 000 wierszy danych bez obcinania zestawu wyników.
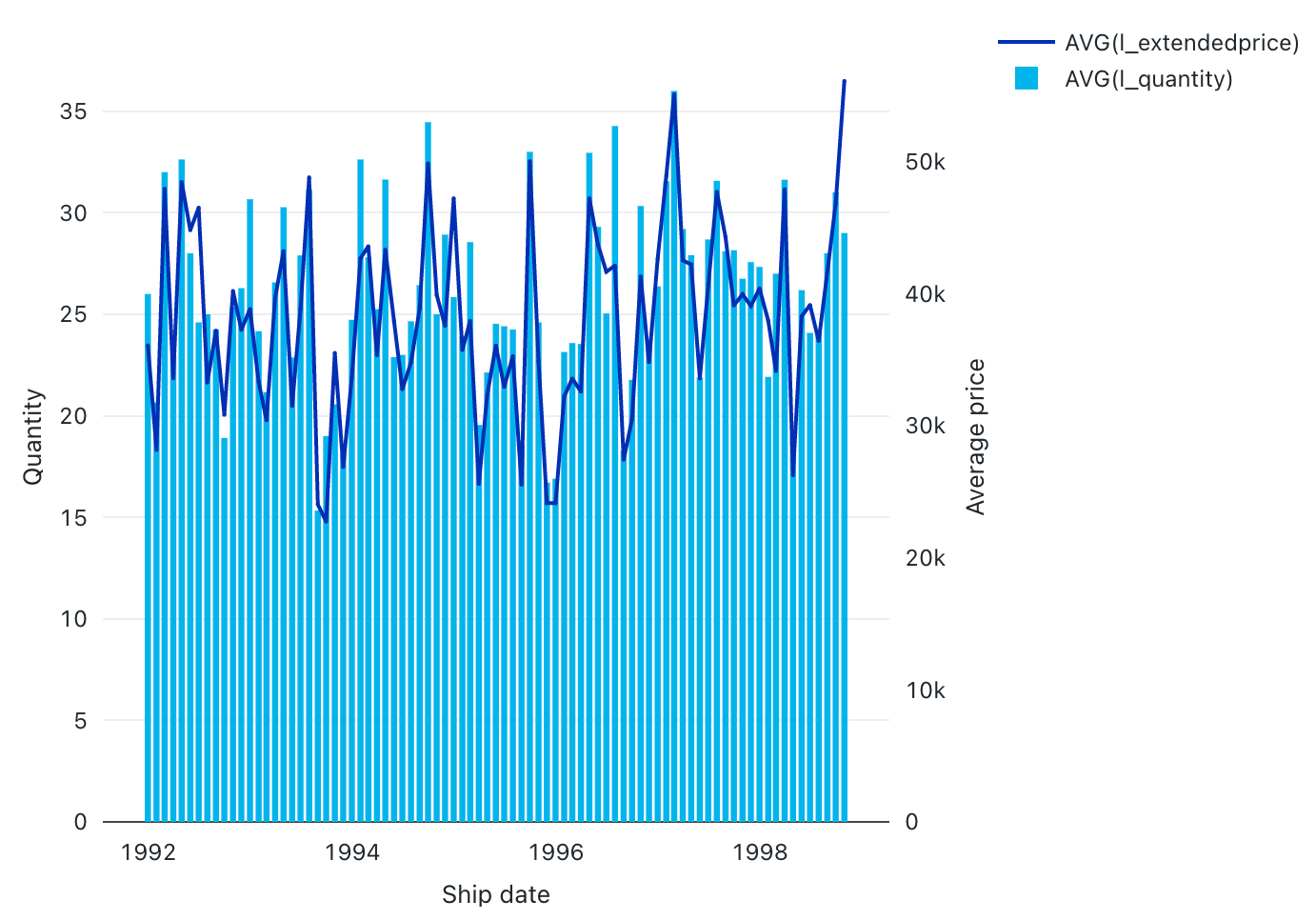
Wartości konfiguracji: dla tej wizualizacji wykresu kombi ustawiono następujące wartości:
- Kolumna X:
- Kolumna zestawu danych:
l_shipdate - Poziom daty:
Months
- Kolumna zestawu danych:
- Kolumny Y:
- Pierwsza kolumna zestawu danych:
l_extendedprice - Typ agregacji: średnia
- Druga kolumna zestawu danych:
l_quantity - Typ agregacji: średnia
- Pierwsza kolumna zestawu danych:
- Nazwa osi X (zastąpij wartość domyślną):
Ship date - Nazwa osi lewej Y (zastąpij wartość domyślną):
Quantity - Nazwa prawej osi Y (zastąpij wartość domyślną):
Average price - Seria:
- Order1 (kolumna zestawu danych):
AVG(l_extendedprice) - Oś Y: prawa
- Typ: Linia
- Order2 (kolumna zestawu danych):
AVG(l_quantity) - Oś Y: po lewej
- Typ: pasek
- Order1 (kolumna zestawu danych):
Opcje konfiguracji: Aby uzyskać opcje konfiguracji wykresu kombi, zobacz opcje konfiguracji wykresu.
Zapytanie SQL: w przypadku tej wizualizacji wykresu kombi następujące zapytanie SQL zostało użyte do wygenerowania zestawu danych.
select * from samples.tpch.lineitem
Analiza kohorty
Analiza kohorty analizuje wyniki wstępnie określonych grup, nazywanych kohortami, gdy przechodzą przez zestaw etapów. Wizualizacja kohorty agreguje tylko daty (umożliwia agregacje miesięczne). Nie wykonuje żadnych innych agregacji danych w zestawie wyników. Wszystkie inne agregacje są wykonywane w obrębie samego zapytania.
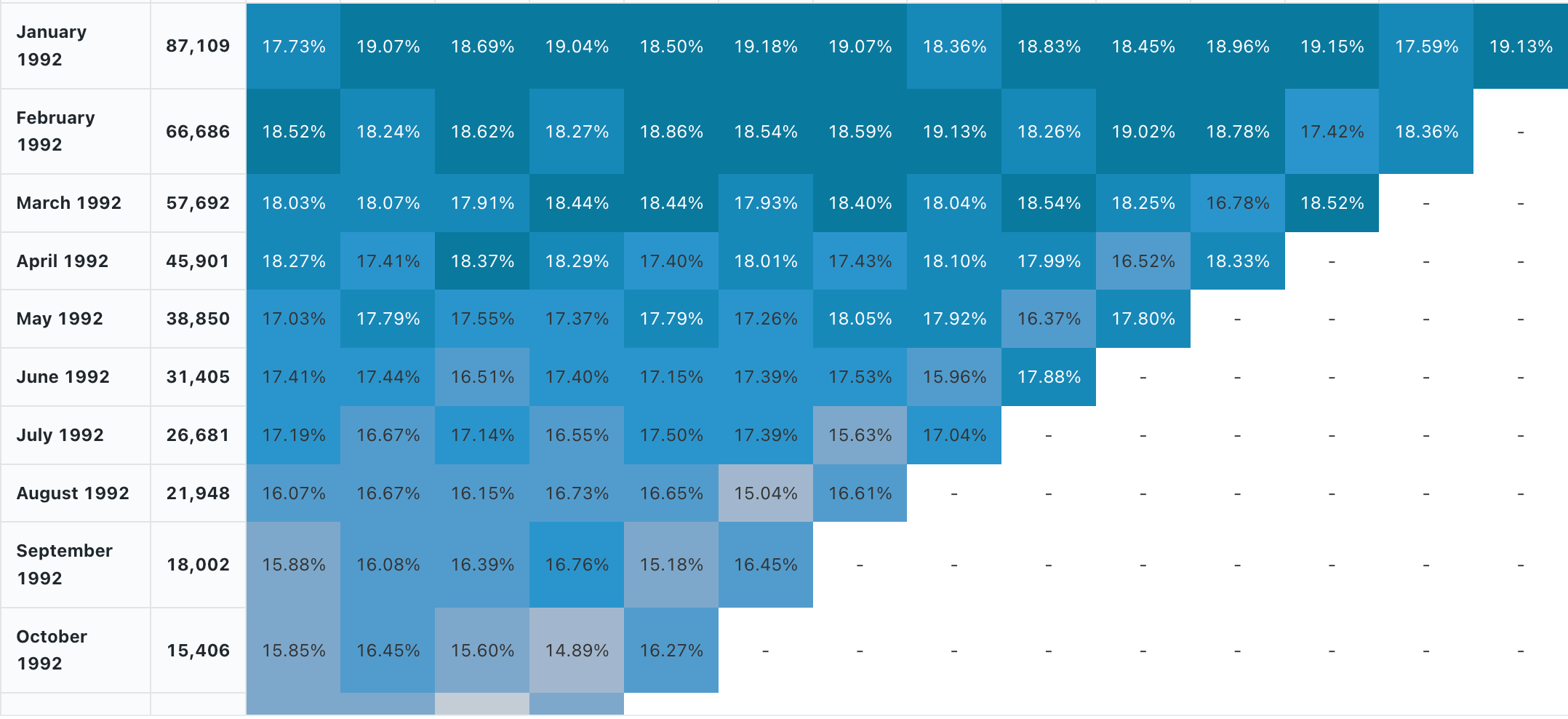
Wartości konfiguracji: dla tej wizualizacji kohorty ustawiono następujące wartości:
- Data (zasobnik) (kolumna bazy danych):
cohort_month - Etap (kolumna bazy danych):
months - Rozmiar populacji zasobnika (kolumna bazy danych):
size - Wartość etapu (kolumna bazy danych):
active - Interwał czasu:
monthly
Opcje konfiguracji: aby uzyskać opcje konfiguracji kohorty, zobacz opcje konfiguracji wykresu kohortowego.
Zapytanie SQL: w przypadku tej wizualizacji kohorty następujące zapytanie SQL zostało użyte do wygenerowania zestawu danych.
-- match each customer with its cohort by month
with cohort_dates as (
SELECT o_custkey, min(date_trunc('month', o_orderdate)) as cohort_month
FROM samples.tpch.orders
GROUP BY 1
),
-- find the size of each cohort
cohort_size as (
SELECT cohort_month, count(distinct o_custkey) as size
FROM cohort_dates
GROUP BY 1
)
-- for each cohort and month thereafter, find the number of active customers
SELECT
cohort_dates.cohort_month,
ceil(months_between(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month)) as months,
count(distinct samples.tpch.orders.o_custkey) as active,
first(size) as size
FROM samples.tpch.orders
left join cohort_dates on samples.tpch.orders.o_custkey = cohort_dates.o_custkey
left join cohort_size on cohort_dates.cohort_month = cohort_size.cohort_month
WHERE datediff(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month) != 0
GROUP BY 1, 2
ORDER BY 1, 2
Wyświetlanie licznika
Liczniki wyświetlają pojedynczą wartość z opcją porównywania ich z wartością docelową. Aby użyć liczników, określ wiersz danych do wyświetlenia na wizualizacji licznika kolumny wartości i kolumny docelowej.
Uwaga
Licznik obsługuje tylko agregację dla maksymalnie 64 000 wierszy. Jeśli zestaw danych jest większy niż 64 000 wierszy, dane zostaną obcięte.
Wartości konfiguracji: dla tej wizualizacji licznika ustawiono następujące wartości:
- Kolumna wartości
- Kolumna zestawu danych:
avg(o_totalprice) - Wiersz 1:
- Kolumna zestawu danych:
- Kolumna docelowa:
- Kolumna zestawu danych:
avg(o_totalprice) - Wiersz 2:
- Kolumna zestawu danych:
- Formatuj wartość docelową: Włącz
Zapytanie SQL: w przypadku tej wizualizacji licznika użyto następującego zapytania SQL do wygenerowania zestawu danych.
select o_orderdate, avg(o_totalprice)
from samples.tpch.orders
GROUP BY 1
ORDER BY 1 DESC
Wizualizacja lejka
Wizualizacja lejka ułatwia analizowanie zmian w metryce na różnych etapach. Aby użyć lejka, określ kolumnę stepvalue i .
Uwaga
Lejek obsługuje tylko agregację dla maksymalnie 64 000 wierszy. Jeśli zestaw danych jest większy niż 64 000 wierszy, dane zostaną obcięte.
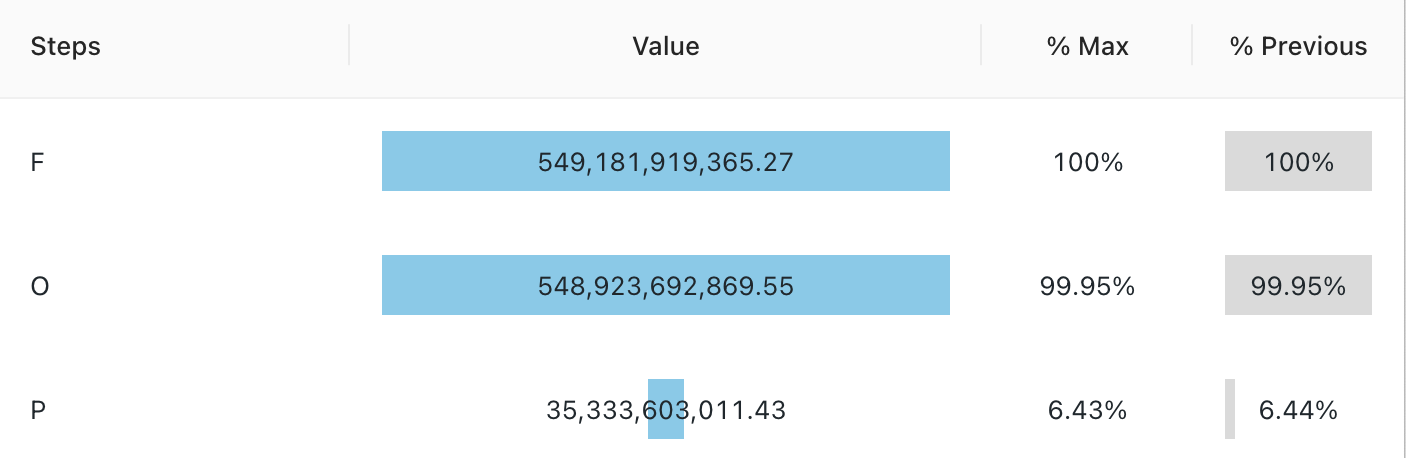
Wartości konfiguracji: dla tej wizualizacji lejka ustawiono następujące wartości:
- Kolumna kroku (kolumna zestawu danych):
o_orderstatus - Kolumna wartości (kolumna zestawu danych):
Revenue
Zapytanie SQL: w przypadku tej wizualizacji lejka do wygenerowania zestawu danych użyto następującego zapytania SQL.
SELECT o_orderstatus, sum(o_totalprice) as Revenue
FROM samples.tpch.orders
GROUP BY 1
wizualizacja mapy (Choropleth)
W wizualizacjach choropleth lokalizacje geograficzne, takie jak kraje lub stany, są kolorowane zgodnie z zagregowanymi wartościami każdej kolumny klucza. Zapytanie musi zwracać lokalizacje geograficzne według nazwy.
Uwaga
Wizualizacje choropleth nie wykonują żadnych agregacji danych w zestawie wyników. Wszystkie agregacje muszą być obliczane w obrębie samego zapytania.
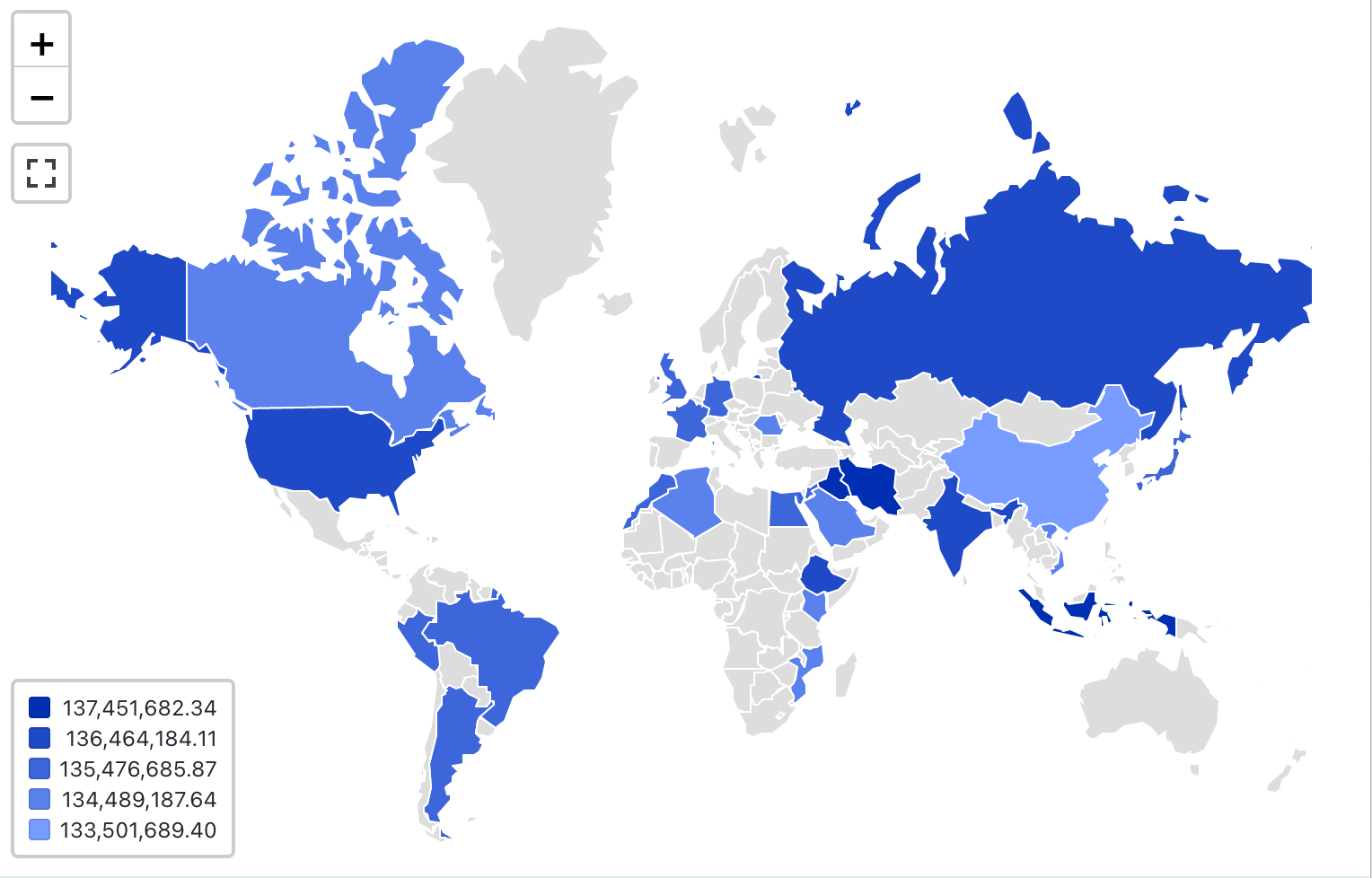
Wartości konfiguracji: dla tej wizualizacji choropleth ustawiono następujące wartości:
- Mapa (kolumna zestawu danych):
Countries - Kolumna geograficzna (kolumna zestawu danych):
Country - Typ geograficzny: krótka nazwa
- Kolumna wartości (kolumna zestawu danych):
Revenue - Tryb klastrowania: równozdecydowany
Opcje konfiguracji: w przypadku opcji konfiguracji choropleth zobacz opcje konfiguracji choropleth.
Zapytanie SQL: w przypadku tej wizualizacji choropleth do wygenerowania zestawu danych użyto następującego zapytania SQL.
SELECT
initcap(n_name) as Country,
sum(c_acctbal)
FROM samples.tpch.customer
join samples.tpch.nation where n_nationkey = c_nationkey
GROUP BY 1
Wizualizacja mapy znaczników
W wizualizacjach znaczników znacznik jest umieszczany w zestawie współrzędnych na mapie. Wynik zapytania musi zwracać pary szerokości i długości geograficznej.
Uwaga
Znacznik nie wykonuje żadnych agregacji danych w zestawie wyników. Wszystkie agregacje muszą być obliczane w obrębie samego zapytania.
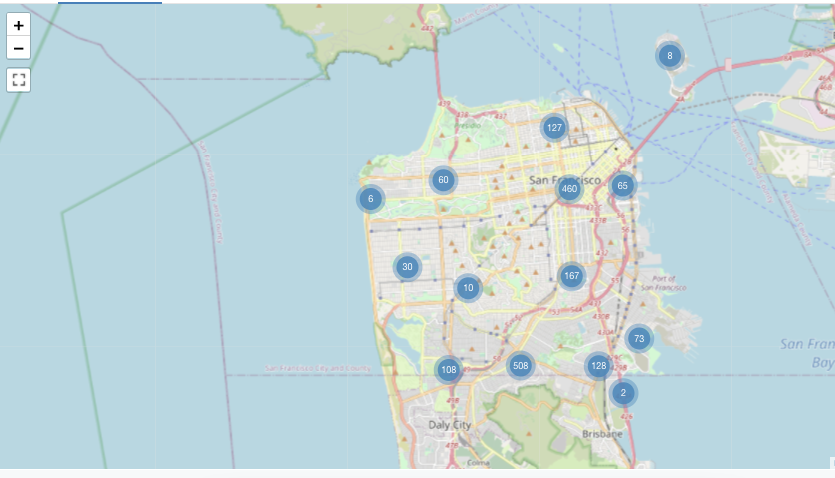
Ten przykład znacznika jest generowany na podstawie zestawu danych zawierającego zarówno wartości szerokości geograficznej, jak i długości geograficznej — które nie są dostępne w przykładowych zestawach danych usługi Databricks. Aby uzyskać informacje o opcjach konfiguracji choropleth, zobacz opcje konfiguracji znacznika.
Wizualizacja tabeli przestawnej
Wizualizacja tabeli przestawnej agreguje rekordy z wyniku zapytania do nowego wyświetlania tabelarycznego. Jest on podobny do PIVOT instrukcji lub GROUP BY w języku SQL. Wizualizację tabeli przestawnej można skonfigurować przy użyciu pól przeciągania i upuszczania.
Uwaga
Tabele przestawne obsługują agregacje zaplecza, zapewniając obsługę zapytań zwracających ponad 64 000 wierszy danych bez obcinania zestawu wyników. Jednak tabela przestawna (starsza wersja) obsługuje tylko agregację dla maksymalnie 64 000 wierszy. Jeśli zestaw danych jest większy niż 64 000 wierszy, dane zostaną obcięte.
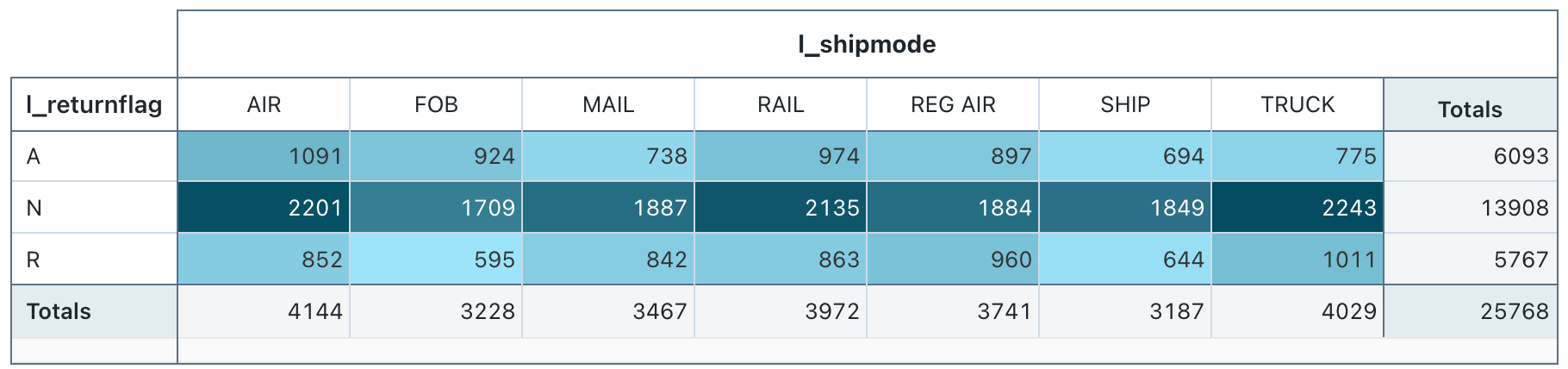
Wartości konfiguracji: dla tej wizualizacji tabeli przestawnej ustawiono następujące wartości:
- Wybierz wiersze (kolumna zestawu danych):
l_returnflag - Wybierz kolumny (kolumna zestawu danych):
l_shipmode - Komórka
- Kolumna zestawu danych:
l_quantity - Typ agregacji: Suma
- Kolorowanie komórek według wartości: Włączone
- Kolumna zestawu danych:
Zapytanie SQL: w przypadku tej wizualizacji tabeli przestawnej do wygenerowania zestawu danych użyto następującego zapytania SQL.
select * from samples.tpch.lineitem
Sankey
Diagram sankey wizualizuje przepływ z jednego zestawu wartości do innego.
Uwaga
Wizualizacje Sankey nie wykonują żadnych agregacji danych w zestawie wyników. Wszystkie agregacje muszą być obliczane w obrębie samego zapytania.

Zapytanie SQL: w przypadku tej wizualizacji Sankey do wygenerowania zestawu danych użyto następującego zapytania SQL.
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
Sekwencja sunburst
Diagram z wybuchem słońca ułatwia wizualizowanie danych hierarchicznych przy użyciu okręgów koncentrycznych.
Uwaga
Sekwencja Sunburst nie wykonuje żadnych agregacji danych w zestawie wyników. Wszystkie agregacje muszą być obliczane w obrębie samego zapytania.
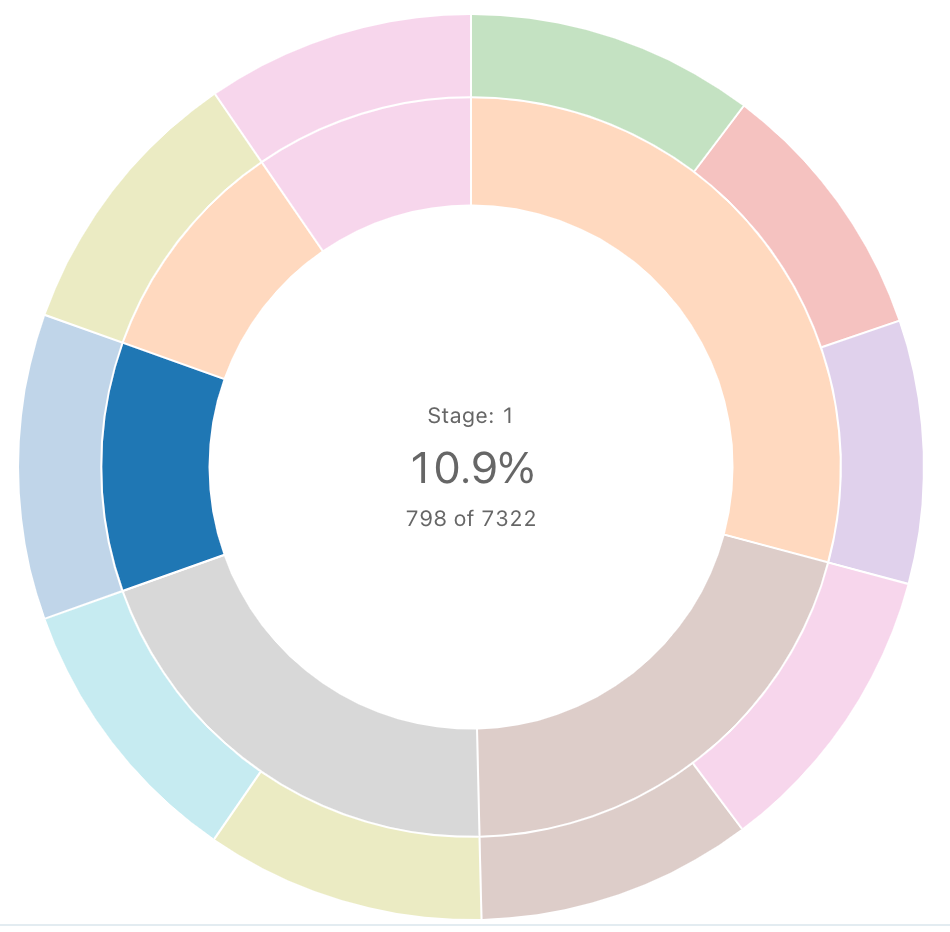
Zapytanie SQL: w przypadku tej wizualizacji sunburst następujące zapytanie SQL zostało użyte do wygenerowania zestawu danych.
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
Table
Wizualizacja tabeli wyświetla dane w standardowej tabeli, ale z możliwością ręcznego zmieniania kolejności, ukrywania i formatowania danych. Zobacz Opcje tabeli.
Uwaga
Wizualizacje tabel nie wykonują żadnych agregacji danych w zestawie wyników. Wszystkie agregacje muszą być obliczane w obrębie samego zapytania.
Aby uzyskać informacje o opcjach konfiguracji tabeli, zobacz Opcje konfiguracji tabeli.
Chmura programu Word
Chmura słów wizualnie reprezentuje częstotliwość występowania wyrazu w danych.
Uwaga
Chmura programu Word obsługuje tylko agregację dla maksymalnie 64 000 wierszy. Jeśli zestaw danych jest większy niż 64 000 wierszy, dane zostaną obcięte.
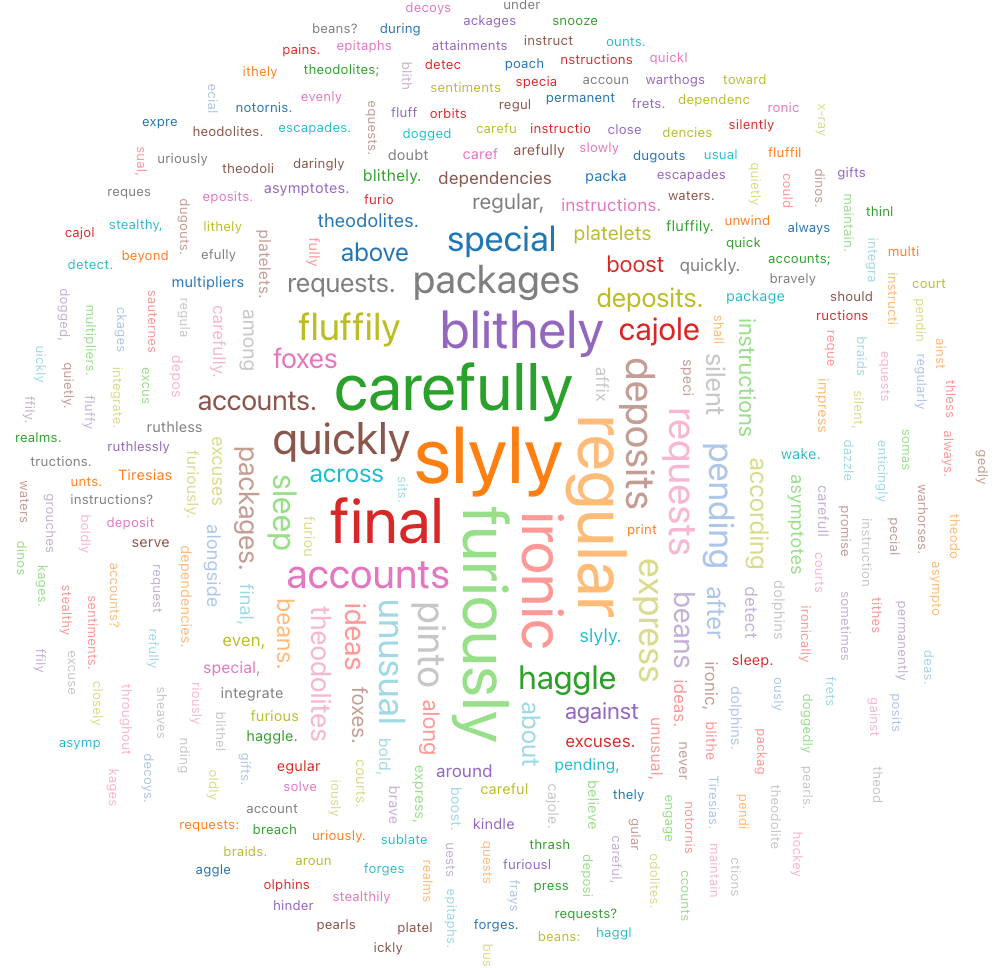
Wartości konfiguracji: dla tej wizualizacji chmury słów ustawiono następujące wartości: test
- Kolumna wyrazów (kolumna zestawu danych):
o_comment - Limit długości wyrazów: min = 5
- Limit częstotliwości: Min = 2
Zapytanie SQL: w przypadku tej wizualizacji chmury słów następujące zapytanie SQL zostało użyte do wygenerowania zestawu danych.
select * from samples.tpch.orders