Dlaczego przetwarzanie strumieni przyrostowych?
Dzisiejsze firmy oparte na danych stale tworzą dane, co wymaga potoków danych inżynieryjnych, które stale pozyskiwają i przekształcają te dane. Te potoki powinny być w stanie przetwarzać i dostarczać dane dokładnie raz, generować wyniki z opóźnieniami mniejszymi niż 200 milisekund i zawsze starać się zminimalizować koszty.
W tym artykule opisano metody przetwarzania strumieniowego wsadowego i przyrostowego dla potoków danych inżynieryjnych, dlaczego przetwarzanie strumieni przyrostowych jest lepszą opcją, a następnie kolejne kroki umożliwiające rozpoczęcie pracy z ofertami przetwarzania przyrostowego strumienia w usłudze Databricks, Przesyłanie strumieniowe w usłudze Azure Databricks i Co to jest tabela delta live tables?. Te funkcje umożliwiają szybkie zapisywanie i uruchamianie potoków, które gwarantują semantyka dostarczania, opóźnienie, koszty i nie tylko.
Pułapki powtarzających się zadań wsadowych
Podczas konfigurowania potoku danych można najpierw zapisywać powtarzające się zadania wsadowe w celu pozyskiwania danych. Na przykład co godzinę można uruchomić zadanie platformy Spark, które odczytuje ze źródła i zapisuje dane w ujściu, takim jak usługa Delta Lake. Wyzwanie związane z tym podejściem polega na przyrostowym przetwarzaniu źródła, ponieważ zadanie platformy Spark uruchamiane co godzinę musi rozpocząć, gdzie zakończyło się ostatnie. Możesz zarejestrować najnowszy znacznik czasu przetworzonych danych, a następnie wybrać wszystkie wiersze ze znacznikami czasu nowszymi niż ten znacznik czasu, ale istnieją pułapki:
Aby uruchomić ciągły potok danych, możesz spróbować zaplanować zadanie wsadowe godzinowe, które przyrostowo odczytuje ze źródła, wykonuje przekształcenia i zapisuje wynik do ujścia, takiego jak usługa Delta Lake. Takie podejście może mieć pułapki:
- Zadanie platformy Spark, które wykonuje zapytania dotyczące wszystkich nowych danych po znaczniku czasu, spowoduje pominięcie opóźnionych danych.
- Zadanie platformy Spark, które kończy się niepowodzeniem, może prowadzić do przerwania dokładnie raz gwarancji, jeśli nie jest dokładnie obsługiwane.
- Zadanie platformy Spark zawierające listę zawartości lokalizacji magazynu w chmurze w celu znalezienia nowych plików stanie się kosztowne.
Następnie nadal trzeba wielokrotnie przekształcać te dane. Możesz napisać powtarzające się zadania wsadowe, które następnie agregują dane lub stosują inne operacje, co jeszcze bardziej komplikuje i zmniejsza wydajność potoku.
Przykład wsadowy
Aby w pełni zrozumieć pułapki pozyskiwania i przekształcania partii dla potoku, rozważ następujące przykłady.
Nieodebrane dane
Biorąc pod uwagę temat platformy Kafka z danymi użycia, który określa, ile opłaty mają klienci, a potok jest pozyskiwany w partiach, sekwencja zdarzeń może wyglądać następująco:
- Pierwsza partia ma dwa rekordy o godzinie 8:30 i 8:30.
- Zaktualizuj najnowszy znacznik czasu do godziny 8:30.
- Otrzymasz kolejny rekord o godzinie 8:15.
- Druga partia wysyła zapytania o wszystko po 8:30, więc przegap rekord o 8:15.
Ponadto nie chcesz przeładować ani nie obciążać użytkowników, więc musisz upewnić się, że pozyskujesz każdy rekord dokładnie raz.
Przetwarzanie nadmiarowe
Następnie załóżmy, że dane zawierają wiersze zakupów użytkowników i chcesz agregować sprzedaż na godzinę, aby poznać najbardziej popularne czasy w sklepie. Jeśli zakupy dla tej samej godziny docierają do różnych partii, będziesz mieć wiele partii, które generują dane wyjściowe dla tej samej godziny:
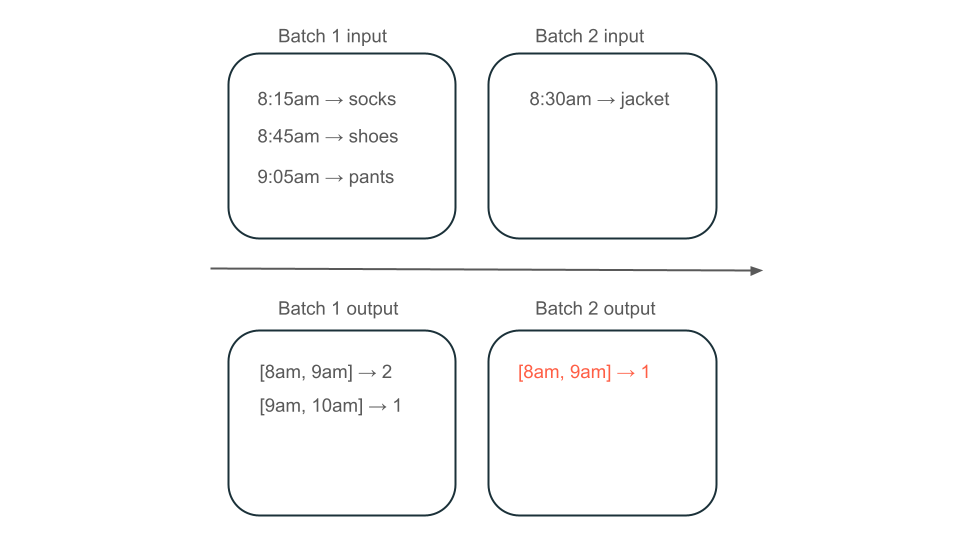
Czy okno od 8:00 do 9am ma dwa elementy (dane wyjściowe partii 1), jeden element (dane wyjściowe partii 2) lub trzy (dane wyjściowe żadnej z partii)? Dane wymagane do utworzenia danego przedziału czasu pojawiają się w wielu partiach transformacji. Aby rozwiązać ten problem, możesz podzielić dane na partycje według dnia i ponownie przetworzyć całą partycję, gdy trzeba obliczyć wynik. Następnie możesz zastąpić wyniki w ujściu:
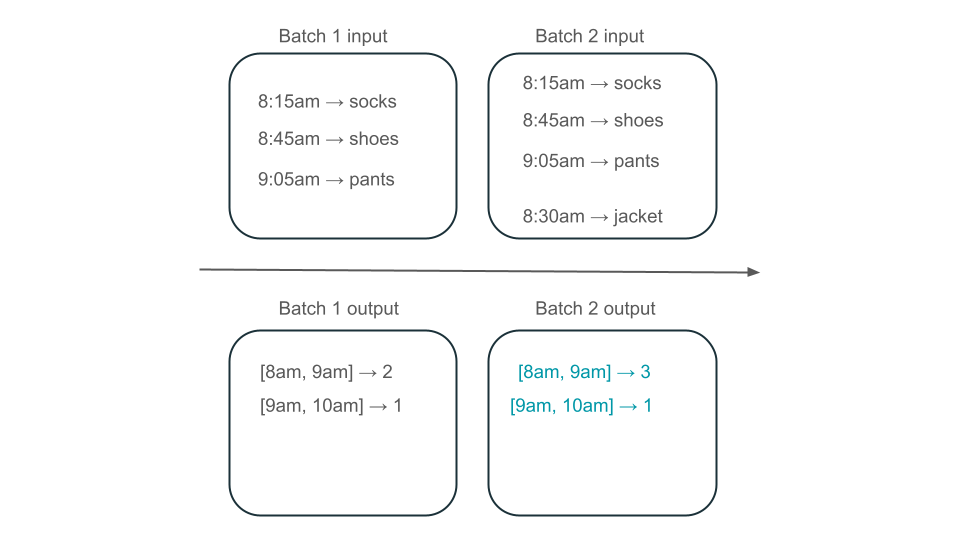
Jednak wiąże się to z kosztem opóźnień i kosztów, ponieważ druga partia musi wykonać niepotrzebną pracę nad przetwarzaniem danych, które mogły już zostać przetworzone.
Brak pułapek przy przetwarzaniu strumienia przyrostowego
Przetwarzanie strumieni przyrostowych ułatwia uniknięcie wszystkich pułapek powtarzających się zadań wsadowych w celu pozyskiwania i przekształcania danych. Usługi Databricks Structured Streaming i Delta Live Tables zarządzają złożonościami implementacji przesyłania strumieniowego, aby umożliwić skoncentrowanie się tylko na logice biznesowej. Wystarczy określić źródło, z którym ma się połączyć, jakie przekształcenia należy wykonać z danymi oraz gdzie zapisać wynik.
Pozyskiwanie przyrostowe
Pozyskiwanie przyrostowe w usłudze Databricks jest obsługiwane przez przesyłanie strumieniowe ze strukturą platformy Apache Spark, które może przyrostowo wykorzystywać źródło danych i zapisywać je w ujściu. Aparat przesyłania strumieniowego ze strukturą może używać danych dokładnie raz, a aparat może obsługiwać dane poza kolejnością. Aparat można uruchomić w notesach lub przy użyciu tabel przesyłania strumieniowego w tabelach Delta Live Tables.
Aparat przesyłania strumieniowego ze strukturą w usłudze Databricks udostępnia zastrzeżone źródła przesyłania strumieniowego, takie jak AutoLoader, które mogą przyrostowo przetwarzać pliki w chmurze w ekonomiczny sposób. Usługa Databricks udostępnia również łączniki dla innych popularnych magistrali komunikatów, takich jak Apache Kafka, Amazon Kinesis, Apache Pulsar i Google Pub/Sub.
Przekształcanie przyrostowe
Przekształcanie przyrostowe w usłudze Databricks ze strukturą przesyłania strumieniowego umożliwia określenie przekształceń w ramkach danych przy użyciu tego samego interfejsu API co zapytanie wsadowe, ale śledzi dane w partiach i zagregowanych wartości w czasie, aby nie trzeba było tego robić. Nigdy nie musi ponownie przetwarzać danych, więc jest szybsze i bardziej ekonomiczne niż powtarzające się zadania wsadowe. Przesyłanie strumieniowe ze strukturą tworzy strumień danych, które mogą być dołączane do ujścia, takich jak usługa Delta Lake, kafka lub dowolny inny obsługiwany łącznik.
Zmaterializowane widoki w tabelach delta live są zasilane przez silnik enzymu. Enzym nadal przyrostowo przetwarza źródło, ale zamiast produkować strumień, tworzy zmaterializowany widok, który jest wstępnie obliczoną tabelą, która przechowuje wyniki danego zapytania. Enzym jest w stanie skutecznie określić, w jaki sposób nowe dane wpływają na wyniki zapytania, i utrzymuje wstępnie obliczoną tabelę.
Zmaterializowane widoki tworzą widok na agregację, która zawsze jest wydajnie aktualizowana tak, aby na przykład w scenariuszu opisanym powyżej wiesz, że okno od 8:00 do 9:00 ma trzy elementy.
Ustrukturyzowane tabele transmisji strumieniowej lub delta na żywo?
Znaczącą różnicą między przesyłania strumieniowego ze strukturą a tabelami delta live jest sposób, w jaki operacjonalizujesz zapytania przesyłania strumieniowego. W przypadku przesyłania strumieniowego ze strukturą ręcznie określasz wiele konfiguracji i musisz ręcznie łączyć zapytania. Musisz jawnie uruchomić zapytania, poczekać na ich zakończenie, anulować je po niepowodzeniu i inne akcje. W tabelach Delta Live Tables deklaratywnie możesz deklaratywnie nadawać tabele na żywo delty do uruchomienia potoków i nadal je uruchamiać.
Funkcja Delta Live Tables zawiera również funkcje, takie jak zmaterializowane widoki, które wydajnie i przyrostowo wstępnie skompilują przekształcenia danych.
Aby uzyskać więcej informacji na temat tych funkcji, zobacz Przesyłanie strumieniowe w usłudze Azure Databricks i Co to jest delta live tables?.
Następne kroki
Utwórz pierwszy potok przy użyciu tabel delta live. Zobacz Samouczek: uruchamianie pierwszego potoku delty tabel na żywo.
Uruchamianie pierwszych zapytań przesyłania strumieniowego ze strukturą w usłudze Databricks. Zobacz Uruchamianie pierwszego obciążenia przesyłania strumieniowego ze strukturą.
Użyj zmaterialiowanego widoku. Zobacz Używanie zmaterializowanych widoków w usłudze Databricks SQL.