sparklyr
Usługa Azure Databricks obsługuje interfejs sparklyr w notesach, zadaniach i programie RStudio Desktop. W tym artykule opisano sposób używania interfejsu sparklyr i przedstawiono przykładowe skrypty, które można uruchomić. Aby uzyskać więcej informacji, zobacz Interfejs języka R na platformie Apache Spark .
Wymagania
Usługa Azure Databricks dystrybuuje najnowszą stabilną wersję interfejsu sparklyr z każdą wersją środowiska Databricks Runtime. Możesz użyć interfejsu sparklyr w notesach języka R usługi Azure Databricks lub w programie RStudio Server hostowanym w usłudze Azure Databricks, importując zainstalowaną wersję interfejsu sparklyr.
W programie RStudio Desktop usługa Databricks Connect umożliwia łączenie interfejsu sparklyr z komputera lokalnego z klastrami usługi Azure Databricks i uruchamianie kodu platformy Apache Spark. Zobacz Use sparklyr and RStudio Desktop with Databricks Connect (Używanie interfejsu sparklyr i programu RStudio Desktop z usługą Databricks Connect).
Łączenie interfejsu sparklyr z klastrami usługi Azure Databricks
Aby ustanowić połączenie sparklyr, można użyć "databricks" jako metody połączenia w pliku spark_connect().
Nie są potrzebne żadne dodatkowe parameters do spark_connect() ani też wywoływanie spark_install() nie jest konieczne, ponieważ Spark jest już zainstalowany w klastrze usługi Azure Databricks.
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
Paski postępu i interfejs użytkownika platformy Spark za pomocą interfejsu użytkownika sparklyr
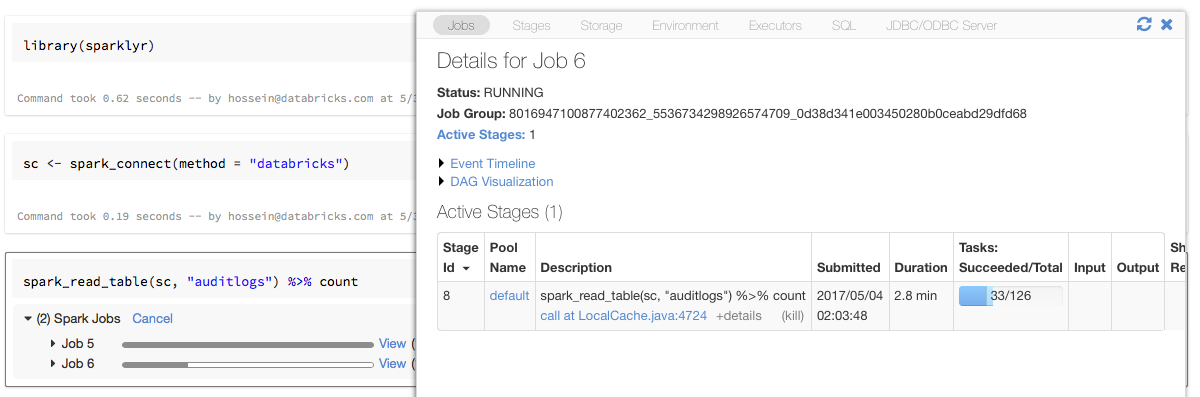
Jeśli przypiszesz obiekt połączenia sparklyr do zmiennej o nazwie w sc powyższym przykładzie, paski postępu platformy Spark będą widoczne w notesie po każdym poleceniu, które wyzwala zadania platformy Spark.
Ponadto możesz kliknąć link obok paska postępu, aby wyświetlić interfejs użytkownika platformy Spark skojarzony z danym zadaniem platformy Spark.
Korzystanie z interfejsu sparklyr
Po zainstalowaniu interfejsu sparklyr i nawiązaniu połączenia wszystkie inne interfejsy API sparklyr działają normalnie. Zobacz przykładowy notes , aby zapoznać się z przykładami.
Sparklyr jest zwykle używany wraz z innymi schludnymi pakietami , takimi jak dplyr. Większość z tych pakietów jest wstępnie zainstalowana w usłudze Databricks dla Wygody. Możesz je po prostu zaimportować i rozpocząć korzystanie z interfejsu API.
Używanie interfejsu sparklyr i sparkR razem
Aparat SparkR i sparklyr mogą być używane razem w jednym notesie lub zadaniu. Możesz zaimportować platformę SparkR wraz z interfejsem sparklyr i korzystać z jego funkcji. W notesach usługi Azure Databricks połączenie SparkR jest wstępnie skonfigurowane.
Niektóre funkcje w usłudze SparkR maskuje wiele funkcji w programie dplyr:
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
Jeśli zaimportujesz usługę SparkR po zaimportowaniu programu dplyr, możesz odwołać się do funkcji w programie dplyr przy użyciu w pełni kwalifikowanych nazw, na przykład dplyr::arrange().
Podobnie w przypadku importowania programu dplyr po usłudze SparkR funkcje w usłudze SparkR są maskowane przez program dplyr.
Alternatywnie można selektywnie odłączyć jeden z dwóch pakietów, gdy nie jest potrzebny.
detach("package:dplyr")
Zobacz też Porównanie platform SparkR i sparklyr.
Używanie interfejsu sparklyr w zadaniach przesyłania spark
Skrypty korzystające z interfejsu sparklyr w usłudze Azure Databricks można uruchamiać jako zadania przesyłania platformy Spark z drobnymi modyfikacjami kodu. Niektóre z powyższych instrukcji nie dotyczą używania interfejsu sparklyr w zadaniach przesyłania platformy Spark w usłudze Azure Databricks. W szczególności należy podać główny adres URL platformy Spark na spark_connectadres . Na przykład:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
Nieobsługiwane funkcje
Usługa Azure Databricks nie obsługuje metod sparklyr, takich jak spark_web() i spark_log() , które wymagają przeglądarki lokalnej. Jednak ponieważ interfejs użytkownika platformy Spark jest wbudowany w usłudze Azure Databricks, możesz łatwo sprawdzać zadania i dzienniki platformy Spark.
Zobacz Dzienniki sterowników obliczeniowych i procesów roboczych.
Przykładowy notes: pokaz sparklyr
Notes Sparklyr
Aby uzyskać dodatkowe przykłady, zobacz