Lipiec 2018
Te funkcje i ulepszenia platformy Azure Databricks zostały wydane w lipcu 2018 r.
Interfejs API bibliotek obsługuje pliki wheel języka Python
31 lipca 2018 r. 7 sierpnia 2018 r.: Wersja 2.77
Biblioteki kół można teraz instalować przy użyciu interfejsu API bibliotek. Po zainstalowaniu biblioteki kół w klastrze z uruchomionym środowiskiem Databricks Runtime 4.2 lub nowszym zostaną uwzględnione wszystkie zależności określone w pliku biblioteki setup.py . Podczas instalowania biblioteki kół w klastrze z uruchomionym środowiskiem Databricks Runtime 4.1 lub nowszym plik jest dodawany do zmiennej PYTHONPATH bez instalowania zależności.
Eksport notesu IPython
31 lipca 2018 r. 7 sierpnia 2018 r.: Wersja 2.77
Podczas eksportowania notesu usługi Azure Databricks do formatu notesu IPython wyniki są teraz uwzględniane w eksporcie.
Zakresy wpisów tajnych obsługiwane przez usługę Azure Key Vault
19-24 lipca 2018 r.: Wersja 2.76
Wpisy tajne obsługują teraz zakresy wspierane przez usługę Azure Key Vault. Po utworzeniu zakresu możesz uzyskać dostęp do wszystkich wpisów tajnych w odpowiednim magazynie Key Vault z tego zakresu. Aby uzyskać szczegółowe informacje, zobacz Zarządzanie zakresami wpisów tajnych.
Uwaga
Zakres wpisów tajnych opartych na usłudze Azure Key Vault jest interfejsem tylko do odczytu w usłudze Key Vault. Aby zarządzać sekretami w usłudze Azure Key Vault, należy użyć interfejsu API REST usługi Azure Set Secret lub interfejsu użytkownika Azure Portal.
Obszary robocze w warstwie Premium w wersji próbnej
20-24 lipca 2018 r.: Wersja 2.76
Usługa Azure Databricks oferuje teraz wersje próbne obszarów roboczych Premium. Podczas 14-dniowej wersji próbnej masz dostęp do bezpłatnych jednostek DBU usługi Azure Databricks. Aby uzyskać więcej informacji, zobacz Tworzenie obszaru roboczego.
Tryb klastra i klastry o wysokiej współbieżności
19-24 lipca 2018 r.: Wersja 2.76
Podczas tworzenia klastra nazwa opcji Typ klastra została zmieniona na Tryb klastra. Opcja Pula bezserwerowa została zastąpiona przez tryb klastra o wysokiej współbieżności. Klastry o wysokiej współbieżności są dostrojone w celu zapewnienia efektywnego wykorzystania zasobów, izolacji, zabezpieczeń i najlepszej wydajności w przypadku współużytkowania wielu współbieżnych aktywnych użytkowników. Klaster o wysokiej współbieżności obsługuje tylko języki SQL, Python i R. Klastry o wysokiej współbieżności zapewniają wszystkie korzyści płynące z pul bezserwerowych, jednocześnie zapewniając elastyczność konfiguracji platformy Spark i zasobów. Aby uzyskać więcej informacji, zobacz Klastry o wysokiej współbieżności.
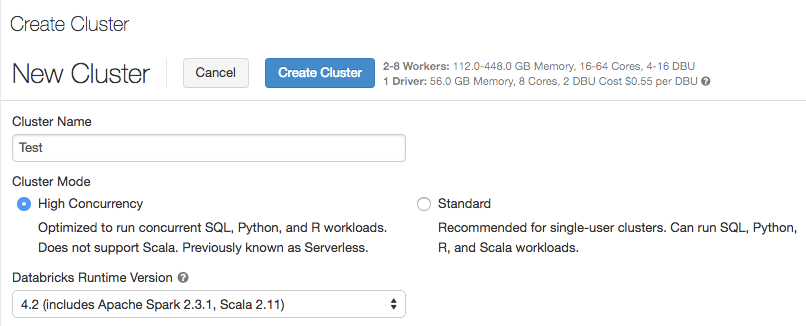
kontrola dostępu Table
19-24 lipca 2018 r.: Wersja 2.76
Pole wyboru Table Kontrola dostępu jest dostępne tylko dla klastrów o wysokiej współbieżności.

Wygaszone niedostępne typy węzłów klastra
3–10 lipca 2018 r.: Wersja 2.75
Typy węzłów klastra, które nie są dostępne dla subskrypcji i regionu, są teraz wyszarane i nie można ich select podczas tworzenia klastra.
Obsługa formatu R Markdown
3–10 lipca 2018 r.: Wersja 2.75
Notesy języka R usługi Azure Databricks można eksportować do formatu języka R Markdown, a dokumenty języka R Markdown można importować jako notesy usługi Azure Databricks.
Nowy projekt strony głównej z możliwością upuszczania plików w celu importowania danych
3–10 lipca 2018 r.: Wersja 2.75
Nowa strona główna dodaje czystszy, prostszy interfejs z linkami do ulepszonego samouczka Wprowadzenie oraz możliwość przeciągania i upuszczania plików w celu importowania danych. Zobacz Eksplorowanie i tworzenie tables w systemie plików DBFS.
Zachowanie domyślne widżetu
3–10 lipca 2018 r.: Wersja 2.75
Domyślne zachowanie wykonywania po wybraniu nowej wartości dla widżetu ma teraz wartość Nie robić nic. Musisz update ustawienia widżetu, jeśli chcesz ponownie uruchomić pełny zeszyt lub tylko polecenia związane z wartością podczas zmiany wartości widżetu. Zobacz Konfigurowanie ustawień widżetu.
interfejs użytkownika tworzenia Table
3–10 lipca 2018 r.: Wersja 2.75
Gdy tworzysz table w interfejsie użytkownika, teraz możesz selectdodać dane ze strony Dane.
![]()
Zobacz Eksplorowanie i tworzenie tables w systemie plików DBFS.
Importowanie danych wielowierszowych JSON
3–10 lipca 2018 r.: Wersja 2.75
Teraz można importować wielowierszowe pliki danych JSON podczas tworzenia tables. Wcześniej pliki danych JSON musiały zostać spłaszczone do jednego wiersza. Zobacz Eksplorowanie i tworzenie tables w systemie plików DBFS.