Plik binarny
Środowisko Databricks Runtime obsługuje źródło danych plików binarnych, które odczytuje pliki binarne i konwertuje każdy plik na pojedynczy rekord zawierający nieprzetworzonej zawartości i metadanych pliku. Źródło danych pliku binarnego tworzy ramkę danych z następującymi kolumnami i prawdopodobnie kolumnami partycji:
-
path (StringType): ścieżka pliku. -
modificationTime (TimestampType): czas modyfikacji pliku. W niektórych implementacjach systemu plików Hadoop ten parametr może być niedostępny, a wartość zostanie ustawiona na wartość domyślną. -
length (LongType): długość pliku w bajtach. -
content (BinaryType): zawartość pliku.
Aby odczytać pliki binarne, określ źródło format danych jako binaryFile.
Obrazy
Usługa Databricks zaleca użycie źródła danych pliku binarnego do załadowania danych obrazu.
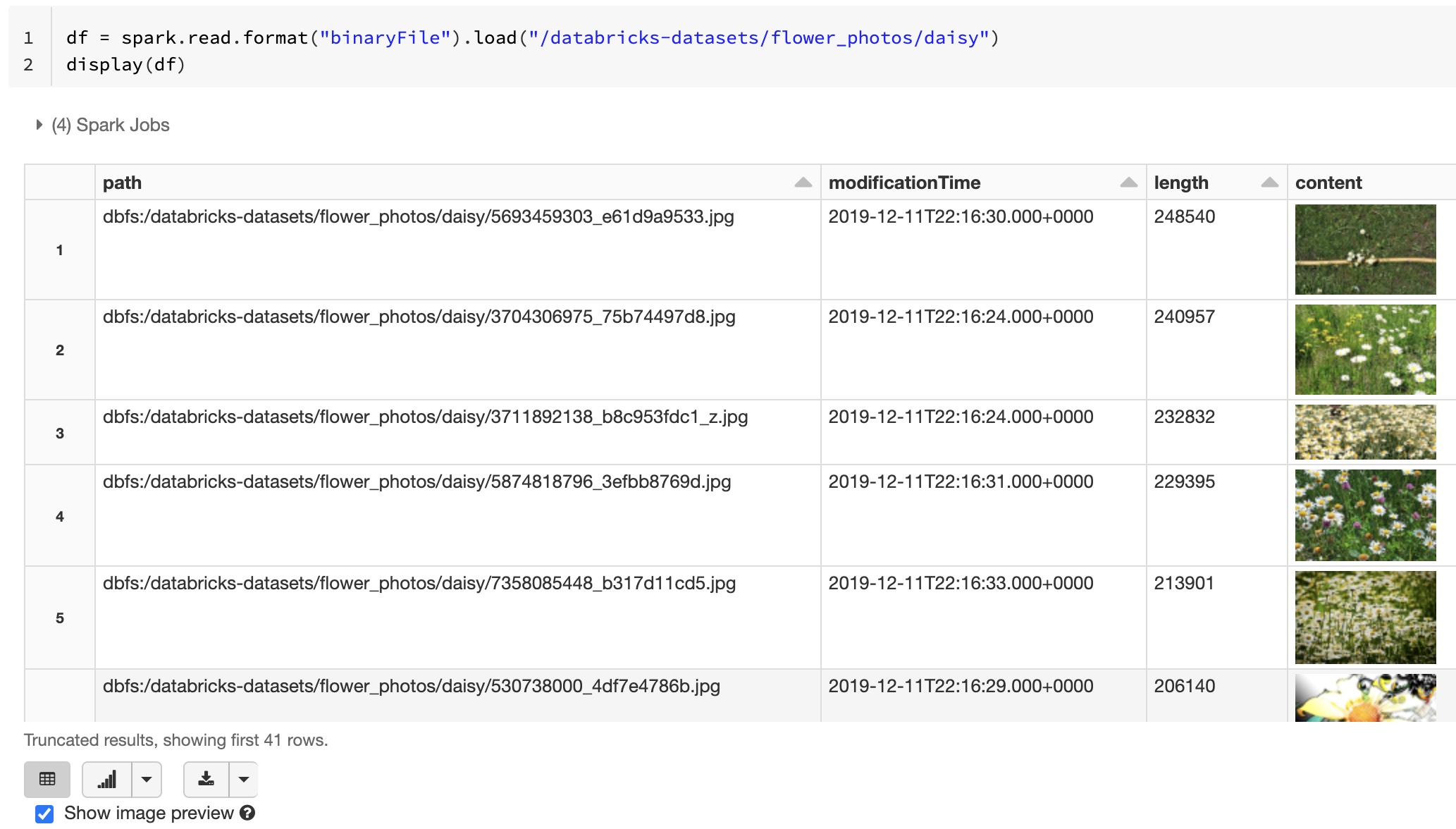
Funkcja Databricks display obsługuje wyświetlanie danych obrazów załadowanych przy użyciu binarnego źródła danych.
Jeśli wszystkie załadowane pliki mają nazwę pliku z rozszerzeniem obrazu, podgląd obrazu jest automatycznie włączony:
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
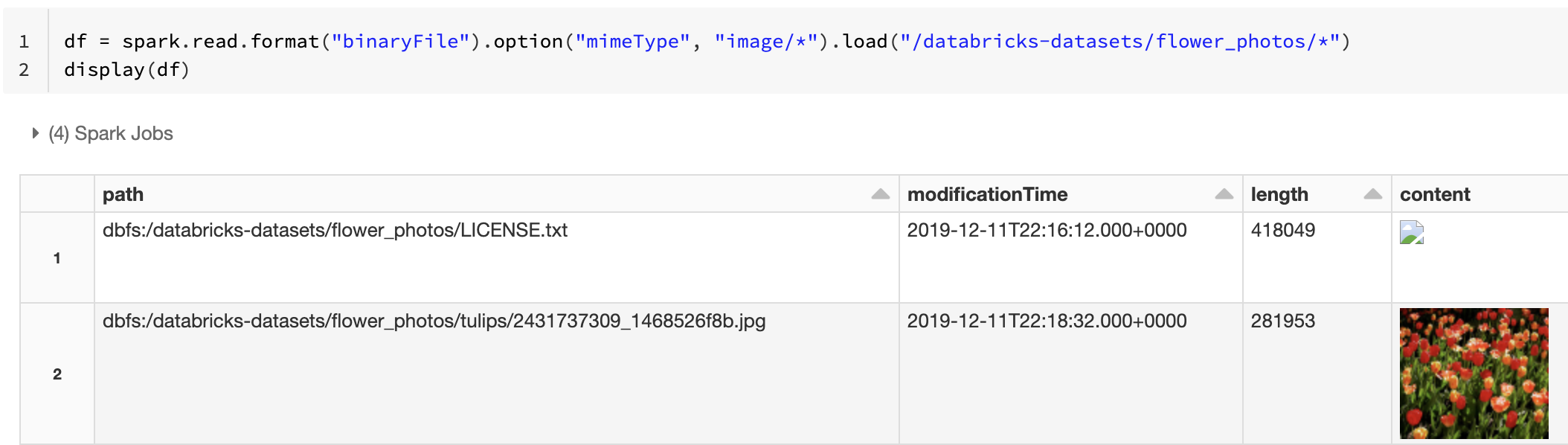
Alternatywnie możesz wymusić korzystanie z funkcji podglądu obrazu przy użyciu mimeType opcji z wartością "image/*" ciągu, aby dodać adnotację do kolumny binarnej. Obrazy są dekodowane na podstawie ich informacji o formacie w zawartości binarnej. Obsługiwane typy obrazów to bmp, , gifjpegi png. Nieobsługiwane pliki są wyświetlane jako uszkodzona ikona obrazu.
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
Zobacz Rozwiązanie referencyjne dla aplikacji obrazów dla zalecanego przepływu pracy do obsługi danych obrazów.
Opcje
Aby załadować pliki ze ścieżkami pasującymi do danego wzorca globu przy zachowaniu zachowania odnajdywania partycji, możesz użyć pathGlobFilter opcji . Poniższy kod odczytuje wszystkie pliki JPG z katalogu wejściowego z odnajdywaniem partycji:
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
Jeśli chcesz zignorować odnajdywanie partycji i cyklicznie przeszukiwać pliki w katalogu wejściowym recursiveFileLookup , użyj opcji . Ta opcja wyszukuje katalogi zagnieżdżone, nawet jeśli ich nazwy nie są zgodne ze schematem nazewnictwa partycji, takim jak date=2019-07-01.
Poniższy kod odczytuje wszystkie pliki JPG rekursywnie z katalogu wejściowego i ignoruje odnajdywanie partycji:
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
Podobne interfejsy API istnieją dla języków Scala, Java i R.
Uwaga
Aby zwiększyć wydajność odczytu podczas ładowania danych z powrotem, usługa Azure Databricks zaleca zapisywanie danych załadowanych z plików binarnych przy użyciu tabel różnicowych:
df.write.save("<path-to-table>")