Adaptacyjne wykonywanie zapytań
Wykonywanie zapytań adaptacyjnych (AQE) to ponowna optymalizacja zapytań wykonywana podczas wykonywania zapytania.
Motywacją do ponownej optymalizacji środowiska uruchomieniowego jest to, że usługa Azure Databricks ma najnowsze, dokładne statystyki na końcu wymiany przetasowania i rozgłaszania (określane jako etap zapytania w kontekście AQE). W związku z tym usługa Azure Databricks może zdecydować się na lepszą strategię fizyczną, wybrać optymalny rozmiar i liczbę partycji po przetasowaniach lub przeprowadzić optymalizacje, które wymagały wskazówek, na przykład obsługi łączeń z niesymetrycznym rozkładem.
Może to być bardzo przydatne, gdy zbieranie statystyk nie jest włączone lub gdy statystyki są nieaktualne. Jest to również przydatne w miejscach, w których statystycznie wywodzone statystyki są niedokładne, jak na przykład w środku skomplikowanego zapytania lub po wystąpieniu skośności danych.
Możliwości
Usługa AQE jest domyślnie włączona. Ma 4 główne funkcje:
- Dynamicznie zmienia połączenie z sortowaniem i scalaniem na połączenie haszowe z rozgłaszaniem.
- Dynamicznie konsoliduje partycje (łączenie małych partycji w rozsądnie duże partycje) po wymianie typu shuffle. Bardzo małe zadania mają gorszą przepływność operacji we/wy i mają tendencję do większego obciążenia związanego z planowaniem i konfiguracją zadań. Łączenie małych zadań pozwala zaoszczędzić zasoby i zwiększyć przepływność klastra.
- Dynamicznie obsługuje skos w sort merge join i shuffle hash join, poprzez podzielenie (i replikowanie w razie potrzeby) zadań o nierównomiernym obciążeniu na zadania o mniej więcej równomiernym rozmiarze.
- Dynamicznie wykrywa i propaguje puste relacje.
Aplikacja
Usługa AQE ma zastosowanie do wszystkich zapytań, które są następujące:
- Brak przesyłania strumieniowego
- Zawiera co najmniej jedną wymianę (zwykle w przypadku sprzężenia, agregacji lub okna), jedno zapytanie podrzędne lub oba te elementy.
Nie wszystkie zapytania stosowane w usłudze AQE muszą zostać ponownie zoptymalizowane. Ponowna optymalizacja może lub nie może wymyślić innego planu zapytania niż statycznie skompilowany. Aby ustalić, czy plan zapytania został zmieniony przez usługę AQE, zobacz następującą sekcję Plany zapytań.
Plany zapytań
W tej sekcji omówiono sposób analizowania planów zapytań na różne sposoby.
W tej sekcji:
Interfejs użytkownika platformy Spark
węzeł AdaptiveSparkPlan
Zapytania zastosowane w usłudze AQE zawierają co najmniej jeden węzeł AdaptiveSparkPlan, zwykle jako węzeł główny każdego zapytania głównego lub zapytania podrzędnego.
Przed uruchomieniem zapytania lub jego uruchomieniu flaga isFinalPlan odpowiedniego węzła AdaptiveSparkPlan jest wyświetlana jako false; po zakończeniu wykonywania zapytania flaga isFinalPlan zmieni się na true.
Ewoluujący plan
Diagram planu zapytania ewoluuje wraz z postępem wykonywania i odzwierciedla najbardziej bieżący plan, który jest wykonywany. Węzły, które zostały już wykonane (w których metryki są dostępne), nie ulegną zmianie, ale te, które nie zostały jeszcze wykonane, mogą się zmieniać z czasem w wyniku ponownej optymalizacji.
Poniżej przedstawiono przykład diagramu planu zapytania:
diagram planu zapytania 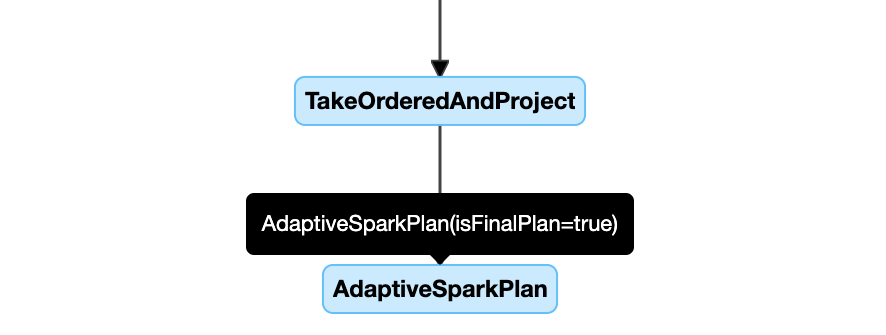
DataFrame.explain()
węzeł AdaptiveSparkPlan
Zapytania zastosowane w usłudze AQE zawierają co najmniej jeden węzeł AdaptiveSparkPlan, zwykle jako węzeł główny każdego zapytania głównego lub zapytania podrzędnego. Przed uruchomieniem zapytania lub jego uruchomieniu flaga isFinalPlan odpowiedniego węzła AdaptiveSparkPlan jest wyświetlana jako false; po zakończeniu wykonywania zapytania flaga isFinalPlan zmieni się na true.
Bieżący i początkowy plan
W każdym węźle AdaptiveSparkPlan będzie istnieć zarówno plan początkowy (plan przed zastosowaniem optymalizacji AQE), jak i bieżący lub końcowy plan, w zależności od tego, czy wykonanie zostało ukończone. Bieżący plan będzie ewoluował w miarę postępu wykonywania.
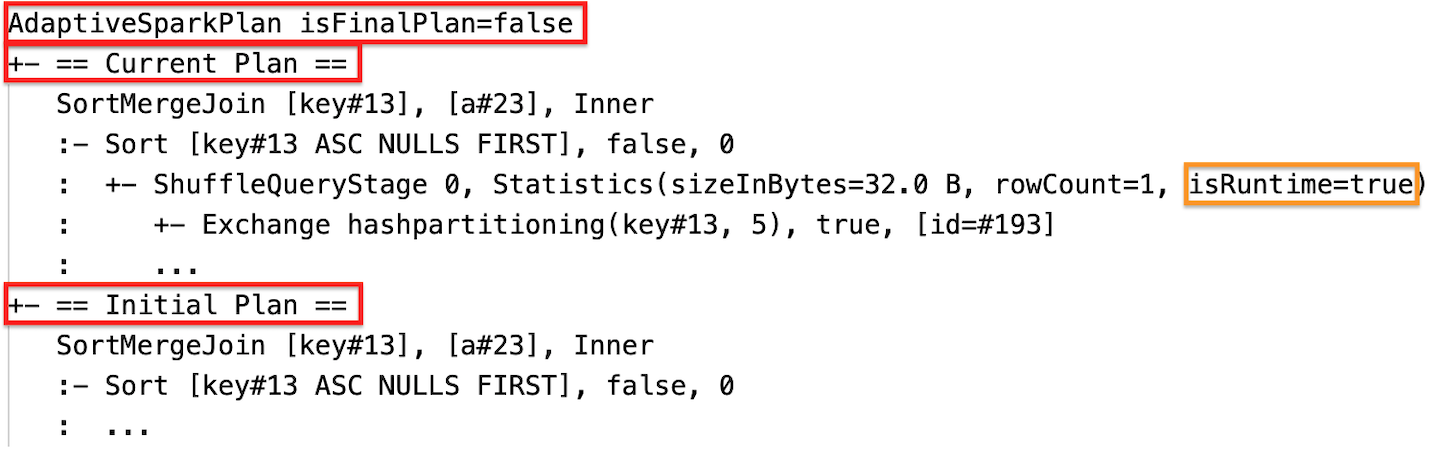
Statystyki środowiska uruchomieniowego
Każdy etap mieszania i emisji zawiera statystyki danych.
Przed uruchomieniem etapu lub po uruchomieniu etapu statystyki są szacowane w czasie kompilacji, a flaga isRuntime jest false, na przykład: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
Po zakończeniu wykonywania etapu, statystyki to te zebrane w czasie wykonywania, a flaga isRuntime zmieni się na true, na przykład: Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true).
Poniżej przedstawiono przykład DataFrame.explain:
Przed wykonaniem
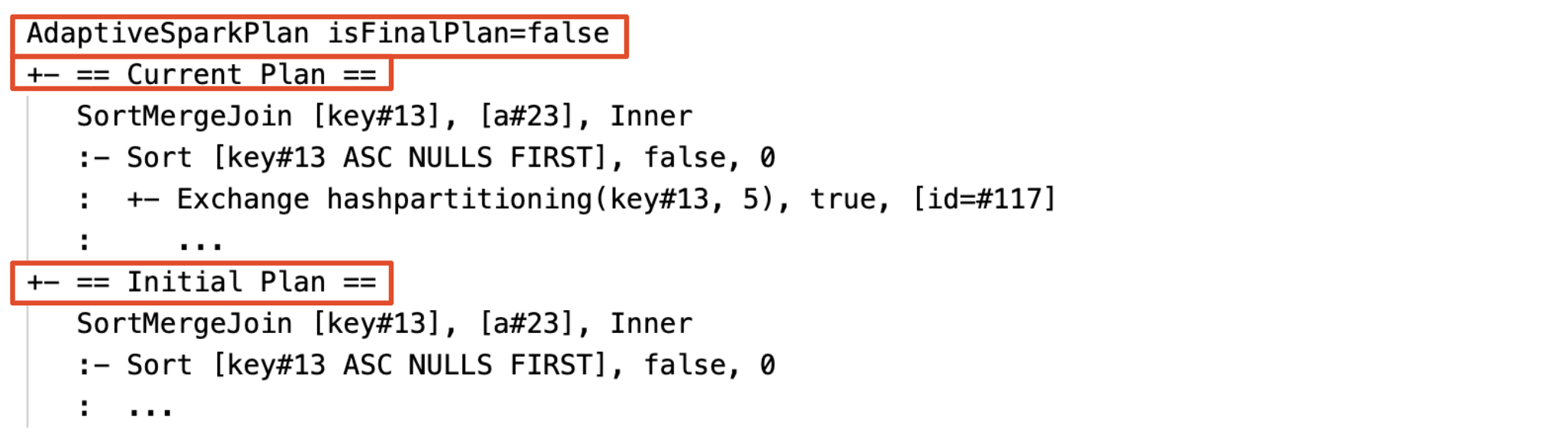
Podczas wykonywania
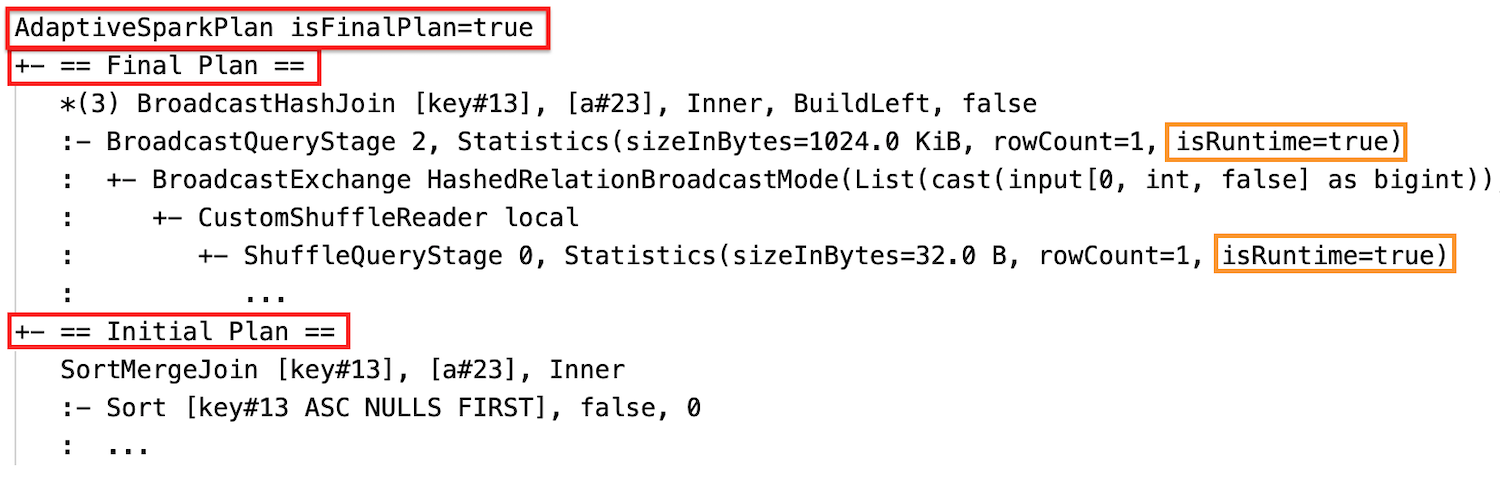
Po wykonaniu
SQL EXPLAIN
węzeł AdaptiveSparkPlan
Zapytania stosujące AQE zawierają co najmniej jeden węzeł AdaptiveSparkPlan, zazwyczaj jako węzeł główny każdego głównego zapytania lub podzapytania.
Brak bieżącego planu
Ponieważ SQL EXPLAIN nie wykonuje zapytania, bieżący plan jest zawsze taki sam jak plan początkowy i nie odzwierciedla tego, co ostatecznie zostanie wykonane przez usługę AQE.
Poniżej przedstawiono przykład objaśnienia sql:

Skuteczność
Plan zapytania zmieni się, jeśli co najmniej jedna optymalizacja AQE zostanie zastosowana. Efekt tych optymalizacji AQE jest przedstawiony przez różnicę między bieżącymi i końcowymi planami oraz początkowym planem i określonymi węzłami planu w bieżących i końcowych planach.
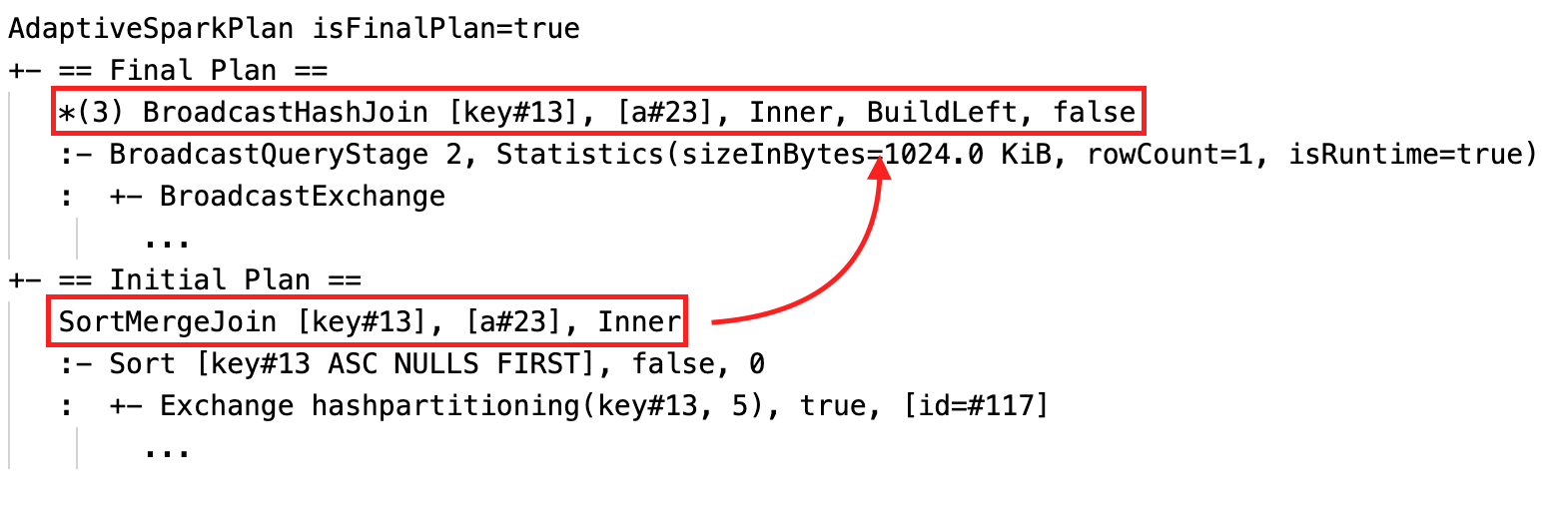
Dynamicznie zmieniaj łączenie przez sortowanie i scalanie na łączenie rozgłoszeniowe z funkcją haszującą: różne fizyczne węzły łączenia między bieżącym/końcowym planem a planem początkowym.
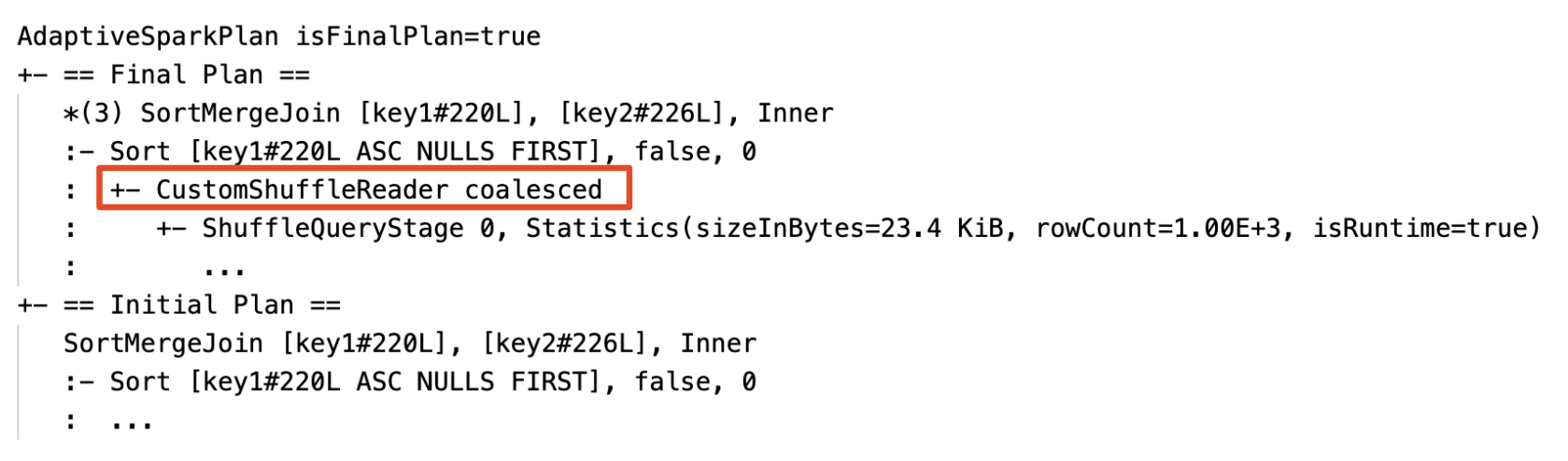
Dynamiczne łączenie partycji: węzeł
CustomShuffleReaderz właściwościąCoalesced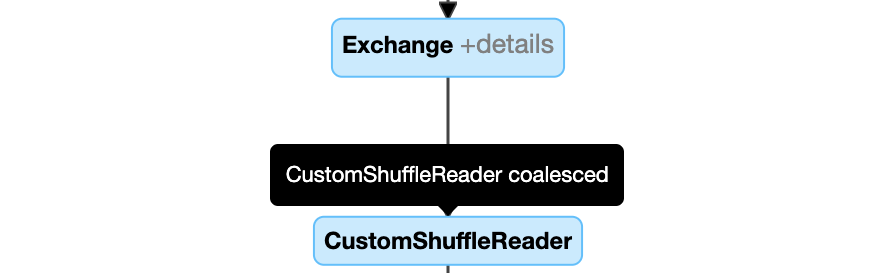
Dynamiczne obsługiwanie sprzężenia niesymetrycznego: węzeł
SortMergeJoinz polemisSkewjako wartość true.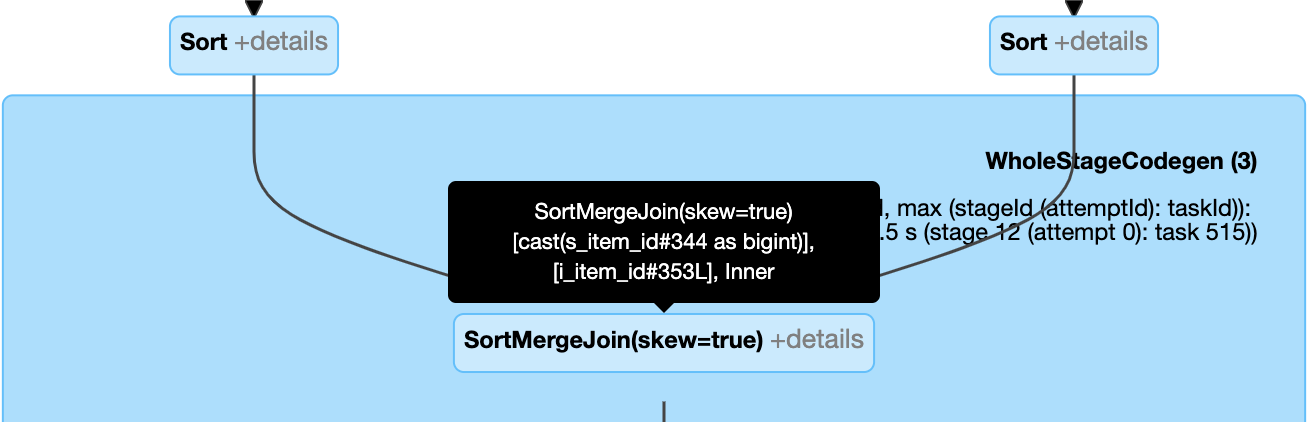
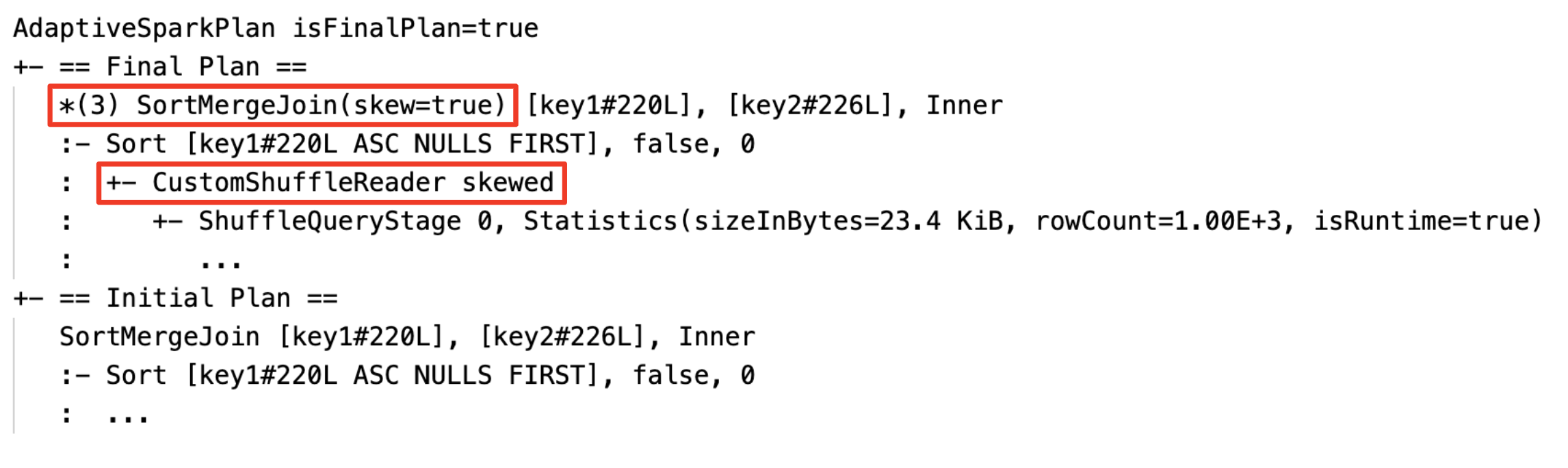
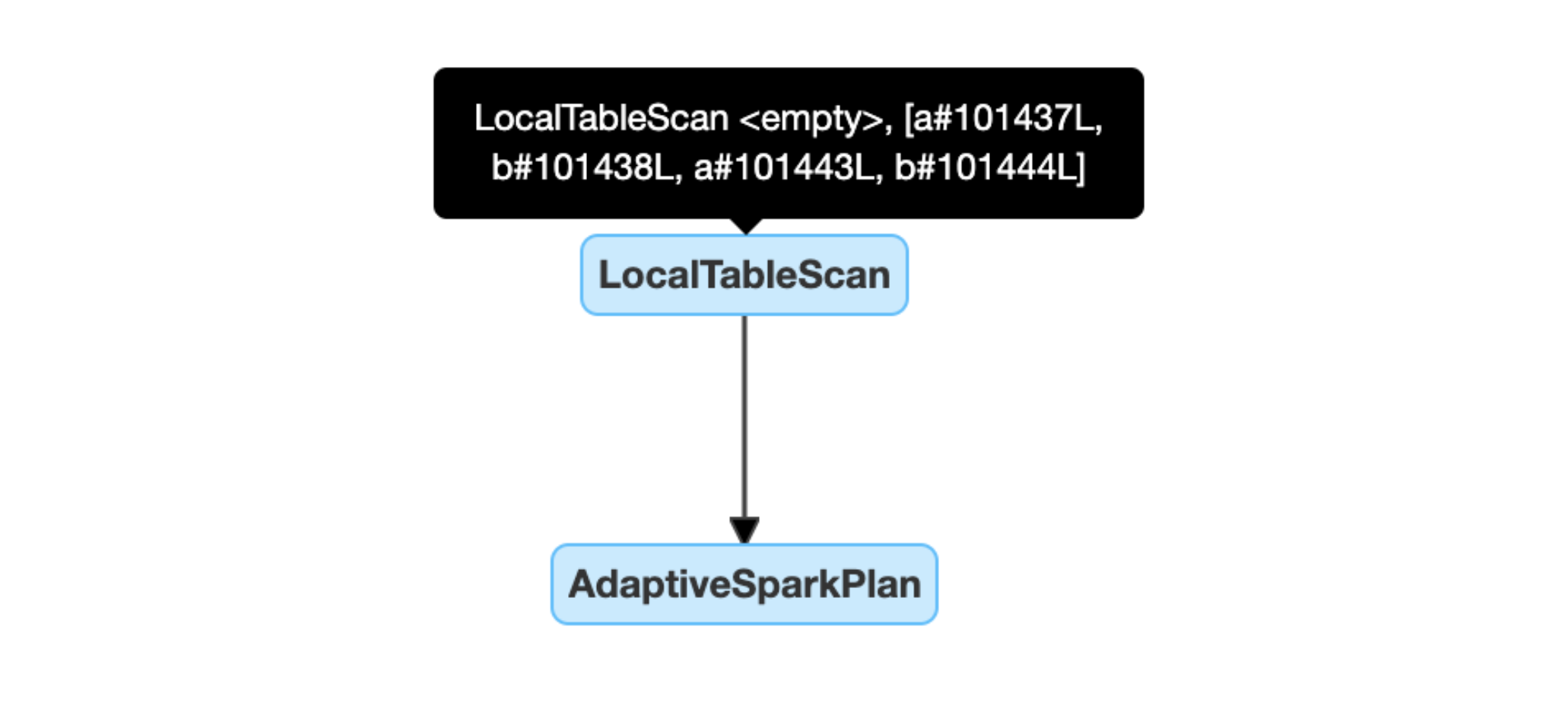
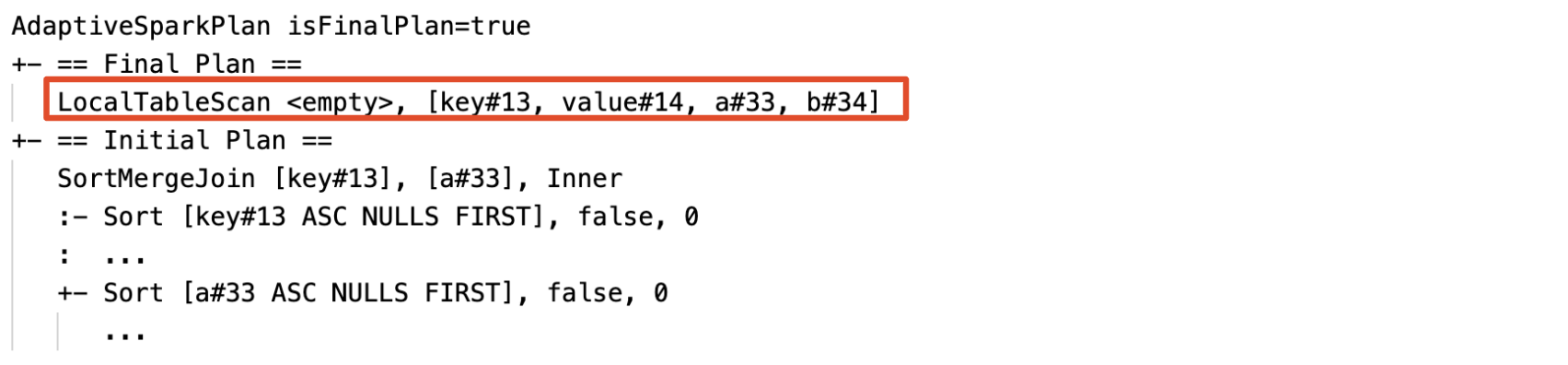
Dynamiczne wykrywanie i propagowanie pustych relacji: część (lub całość) planu jest zastępowana przez węzeł LocalTableScan z pustym polem relacji.
Konfiguracja
W tej sekcji:
- włączanie i wyłączanie wykonywania zapytań adaptacyjnych
- Włącz zoptymalizowane automatyczne mieszanie
- Dynamicznie zmieniać łączenie sortowania i scalania w rozgłaszane łączenie skrótu
- dynamicznie łączą partycje
- dynamicznie obsłuż sprzężenia niesymetryczne
- Dynamicznie wykrywaj i propaguj puste relacje
Włączanie i wyłączanie wykonywania zapytań adaptacyjnych
| Własność |
|---|
|
spark.databricks.optimizer.adaptive.enabled Typ: BooleanCzy włączyć lub wyłączyć wykonywanie zapytań adaptacyjnych. Wartość domyślna: true |
Włącz auto-optymalizowane tasowanie
| Własność |
|---|
|
spark.sql.shuffle.partitions Typ: IntegerDomyślna liczba partycji do użycia podczas mieszania danych dla sprzężeń lub agregacji. Ustawienie wartości auto umożliwia automatyczną optymalizację mieszania, która automatycznie określa tę liczbę na podstawie planu zapytania i rozmiaru danych wejściowych zapytania.Uwaga: w przypadku przesyłania strumieniowego ze strukturą tej konfiguracji nie można zmienić między ponownymi uruchomieniami zapytania z tej samej lokalizacji punktu kontrolnego. Wartość domyślna: 200 |
Dynamicznie zmieniaj sprzężenia scalania sortowania w sprzężenia skrótu emisji
| Własność |
|---|
|
spark.databricks.adaptive.autoBroadcastJoinThreshold Typ: Byte StringPróg wyzwalający przejście na połączenie rozgłoszeniowe w czasie wykonywania. Wartość domyślna: 30MB |
Dynamiczne scalanie partycji
| Własność |
|---|
|
spark.sql.adaptive.coalescePartitions.enabled Typ: BooleanCzy należy włączyć lub wyłączyć łączenie partycji. Wartość domyślna: true |
|
spark.sql.adaptive.advisoryPartitionSizeInBytes Typ: Byte StringRozmiar docelowy po połączeniu. Rozmiary połączonych partycji będą zbliżone do docelowego rozmiaru, ale nie większe niż on. Wartość domyślna: 64MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionSize Typ: Byte StringMinimalny rozmiar partycji po scaleniu. Rozmiary scalonych partycji nie będą mniejsze niż tego rozmiaru. Wartość domyślna: 1MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionNum Typ: IntegerMinimalna liczba partycji po scaleniu. Nie jest zalecane, ponieważ jawne ustawienie nadpisuje wcześniejsze ustawienia. spark.sql.adaptive.coalescePartitions.minPartitionSize.Wartość domyślna: 2x nr. rdzeni klastra |
Dynamiczna obsługa łączenia skośnego
| Własność |
|---|
|
spark.sql.adaptive.skewJoin.enabled Typ: BooleanCzy włączyć lub wyłączyć obsługę sprzężenia niesymetrycznego. Wartość domyślna: true |
|
spark.sql.adaptive.skewJoin.skewedPartitionFactor Typ: IntegerCzynnik, który po pomnożeniu przez rozmiar centralnej partycji przyczynia się do określenia, czy partycja jest niesymetryczna. Wartość domyślna: 5 |
|
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes Typ: Byte StringPróg, który przyczynia się do określenia, czy partycja jest niesymetryczna. Wartość domyślna: 256MB |
Partycja jest uważana za niesymetryczną, gdy (partition size > skewedPartitionFactor * median partition size) i (partition size > skewedPartitionThresholdInBytes) są true.
Dynamiczne wykrywanie i propagowanie pustych relacji
| Własność |
|---|
|
spark.databricks.adaptive.emptyRelationPropagation.enabled Typ: BooleanCzy włączyć lub wyłączyć dynamiczną propagację pustych relacji. Wartość domyślna: true |
Często zadawane pytania
W tej sekcji:
- Dlaczego AQE nie emitowała małej tabeli sprzężenia?
- czy nadal należy używać wskazówki strategii sprzężenia emisji z włączoną funkcją AQE?
- Jaka jest różnica między niesymetryczną wskazówką sprzężenia a optymalizacją sprzężenia niesymetrycznego AQE? Którego z nich należy użyć?
- Dlaczego AQE nie dostosowało automatycznie kolejności łączenia?
- Dlaczego usługa AQE nie wykryła niesymetryczności danych?
Dlaczego AQE nie emitowała małej tabeli sprzężenia?
Jeśli rozmiar relacji, która ma być nadana, jest poniżej tego progu, ale nadal nie jest nadawana:
- Sprawdź typ sprzężenia. Broadcastowanie nie jest obsługiwane dla niektórych typów łączeń, na przykład lewa relacja typu
LEFT OUTER JOINnie może być broadcastowana. - Może się również zdarzyć, że relacja zawiera wiele pustych partycji, w takim przypadku większość zadań może zakończyć się szybko za pomocą łączenia przez sortowanie i scalanie lub może być potencjalnie zoptymalizowana za pomocą obsługi łączenia niesymetrycznego. AQE unika zmiany takich sprzężeń scalających sortowanie na rozgłoszeniowe połączenia z haszowaniem, jeśli procent niepustych partycji jest niższy niż
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin.
Czy nadal powinienem używać wskazówki dotyczącej strategii łączenia rozgłoszeniowego przy włączonej funkcji AQE?
Tak. Łączenie na potrzeby emisji planowane statycznie jest zwykle bardziej wydajne niż dynamicznie planowane przy użyciu AQE, ponieważ AQE może nie wybrać opcji łączenia na potrzeby emisji, dopóki nie zostanie wykonane przetasowanie danych dla obu stron łączenia (do tego czasu uzyskano rzeczywiste rozmiary relacji). Użycie podpowiedzi nadawania może nadal być dobrym wyborem, jeśli dobrze znasz swoje zapytanie. AQE będzie przestrzegać wskazówek dotyczących zapytań w taki sam sposób jak optymalizacja statyczna, ale nadal może stosować optymalizacje dynamiczne, na które wskazówki nie mają wpływu.
Jaka jest różnica między niesymetryczną wskazówką sprzężenia a optymalizacją sprzężenia niesymetrycznego AQE? Którego z nich należy użyć?
Zaleca się poleganie na obsłudze sprzężenia niesymetrycznego AQE, a nie używanie wskazówki dotyczącej sprzężenia niesymetrycznego, ponieważ sprzężenie niesymetryczne AQE jest całkowicie automatyczne i ogólnie działa lepiej niż odpowiednik wskazówki.
Dlaczego AQE nie zmieniło kolejności łączeń automatycznie?
Zmiana kolejności sprzężeń dynamicznych nie jest częścią AQE.
Dlaczego usługa AQE nie wykryła niesymetryczności danych?
Istnieją dwa warunki rozmiaru, które muszą zostać spełnione, aby usługa AQE wykryła partycję jako niesymetryczną partycję:
- Rozmiar partycji jest większy niż
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes(domyślnie 256 MB) - Rozmiar partycji jest większy niż mediana rozmiaru wszystkich partycji w przypadku niesymetrycznego współczynnika partycji
spark.sql.adaptive.skewJoin.skewedPartitionFactor(wartość domyślna 5)
Ponadto obsługa odchylenia jest ograniczona dla niektórych typów łączeń, na przykład w LEFT OUTER JOINmożna zoptymalizować tylko odchylenie po lewej stronie.
Dziedzictwo
Termin "Wykonywanie adaptacyjne" istnieje od wersji Spark 1.6, ale nowa AQE na platformie Spark 3.0 jest zasadniczo inna. Pod względem funkcjonalności, Spark 1.6 wykonuje tylko dynamiczne scalanie partycji. Jeśli chodzi o architekturę techniczną, nowa AQE to struktura dynamicznego planowania i ponownego planowania zapytań na podstawie statystyk środowiska uruchomieniowego, która obsługuje różne optymalizacje, takie jak te opisane w tym artykule i można rozszerzyć, aby umożliwić bardziej potencjalne optymalizacje.