Śledzenie MLflow dla agentów
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
W tym artykule opisano MLflow Tracing w usłudze Databricks i sposób używania go do dodawania obserwowalności do aplikacji generatywnej sztucznej inteligencji.
Co to jest śledzenie MLflow?
Śledzenie MLflow przechwytuje szczegółowe informacje o wykonywaniu aplikacji sztucznej inteligencji generatywnej. Śledzenie rejestruje dane wejściowe, wyjściowe i metadane skojarzone z każdym pośrednim krokiem żądania, dzięki czemu można wskazać źródło usterek i nieoczekiwane zachowanie. Na przykład jeśli model halucynuje, możesz szybko sprawdzić każdy krok, który doprowadził do halucynacji.
Śledzenie MLflow jest zintegrowane z narzędziami i infrastrukturą usługi Databricks, umożliwiając przechowywanie i wyświetlanie śladów w notesach usługi Databricks lub interfejsie użytkownika eksperymentu MLflow.
śledzenie liniowe 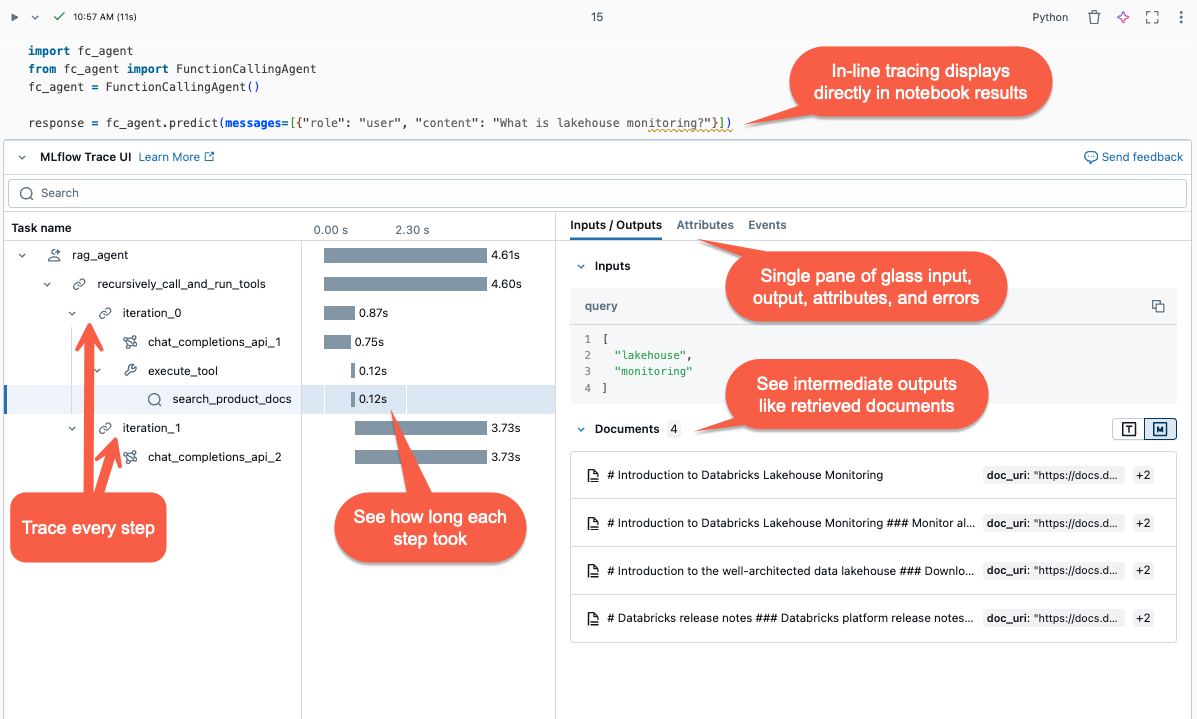
Dlaczego warto używać śledzenia MLflow?
Śledzenie MLflow zapewnia kilka korzyści:
- Przejrzyj interaktywną wizualizację śledzenia i użyj narzędzia do badania, aby zdiagnozować problemy.
- Sprawdź, czy szablony monitów i bariery ochronne generują uzasadnione wyniki.
- Przeanalizuj opóźnienie różnych struktur, modeli i rozmiarów fragmentów.
- Szacowanie kosztów aplikacji przez mierzenie użycia tokenu w różnych modelach.
- Ustanów zestawy danych testu porównawczego "golden", aby ocenić wydajność różnych wersji.
- Przechowywanie śladów z punktów końcowych modelu produkcyjnego w celu debugowania problemów i przeprowadzania przeglądu i oceny w trybie offline.
Dodawanie śladów do agenta
MLflow Tracing obsługuje trzy metody dodawania śladów do aplikacji generatywnych AI. Aby uzyskać szczegółowe informacje o interfejsie API, zobacz dokumentację platformy MLflow.
| interfejs API | Zalecany przypadek użycia | opis |
|---|---|---|
| automatycznego rejestrowania MLflow | Programowanie za pomocą zintegrowanych bibliotek GenAI | Automatyczne rejestrowanie automatycznie rejestruje ślady obsługiwanych struktur typu open source, takich jak LangChain, LlamaIndex i OpenAI. |
| interfejsy API Fluent | Agent niestandardowy z funkcją Pyfunc | Interfejsy API z małą ilością kodu do dodawania śladów bez obaw o zarządzanie strukturą drzewa śledzenia. MLflow automatycznie określa odpowiednie relacje nadrzędno-podrzędne, korzystając z stacku języka Python. |
| interfejsy API klienta MLflow | Zaawansowane przypadki użycia, takie jak wielowątkowy |
MLflowClient zapewnia szczegółowe, bezpieczne wątkowo interfejsy API dla zaawansowanych przypadków użycia. Należy ręcznie zarządzać relacją nadrzędno-podrzędną zakresów. Zapewnia to lepszą kontrolę nad cyklem życia danych śledzenia, szczególnie dla przypadków użycia wielowątkowego. |
Instalowanie śledzenia MLflow
Śledzenie MLflow jest dostępne w wersji 2.13.0 lub nowszej, która jest wstępnie zainstalowana w <DBR< 15.4 LTS ML i nowszych. W razie potrzeby zainstaluj aplikację MLflow przy użyciu następującego kodu:
%pip install mlflow>=2.13.0 -qqqU
%restart_python
Alternatywnie możesz zainstalować najnowszą wersję databricks-agents, która zawiera zgodną wersję platformy MLflow:
%pip install databricks-agents
Użyj automatycznego logowania, aby dodać ślady do swoich agentów
Jeśli biblioteka GenAI obsługuje śledzenie, takie jak LangChain lub OpenAI, włącz automatyczne rejestrowanie, dodając mlflow.<library>.autolog() do kodu. Na przykład:
mlflow.langchain.autolog()
Uwaga
Od środowiska Databricks Runtime 15.4 LTS ML śledzenie MLflow jest domyślnie włączone w notesach. Aby wyłączyć śledzenie, na przykład za pomocą biblioteki LangChain, możesz wykonać mlflow.langchain.autolog(log_traces=False) w notatniku.
Biblioteka MLflow obsługuje dodatkowe biblioteki do automatycznego rejestrowania śledzenia. Pełna lista zintegrowanych bibliotek znajduje się w dokumentacji dotyczącej śledzenia MLflow.
Ręcznie dodaj ślady do swojego agenta przy użyciu Fluent API
Interfejsy API Fluent w rozwiązaniu MLflow automatycznie tworzą hierarchie śledzenia na podstawie przepływu wykonywania kodu.
Dekorowanie funkcji
Użyj dekoratora @mlflow.trace, aby utworzyć zakres obejmujący funkcję dekorowaną.
Obiekt MLflow Span organizuje etapy śledzenia. Span zawiera informacje o pojedynczych operacjach lub krokach, takich jak wywołania interfejsu API lub zapytania do magazynu wektorów, w ramach przepływu pracy.
Zakres rozpoczyna się po wywołaniu funkcji i kończy się po jej powrocie. MLflow rejestruje dane wejściowe i wyjściowe funkcji oraz wszelkie wyjątki zgłoszone z funkcji.
Na przykład poniższy kod tworzy zakres o nazwie my_function, który przechwytuje argumenty wejściowe x i y oraz dane wyjściowe.
@mlflow.trace(name="agent", span_type="TYPE", attributes={"key": "value"})
def my_function(x, y):
return x + y
Korzystaj z menedżera kontekstu śledzenia
Jeśli chcesz utworzyć zakres dla dowolnego bloku kodu, a nie tylko funkcji, możesz użyć mlflow.start_span() jako menedżera kontekstu, który opakowuje blok kodu. Zakres rozpoczyna się po wejściu w kontekst i kończy się po wyjściu z kontekstu. Dane wejściowe i wyjściowe dla obiektu span powinny być podawane ręcznie, przy użyciu metod ustawiających tego obiektu uzyskanego przez menedżera kontekstu.
with mlflow.start_span("my_span") as span:
span.set_inputs({"x": x, "y": y})
result = x + y
span.set_outputs(result)
span.set_attribute("key", "value")
Owiń funkcję zewnętrzną
Aby śledzić funkcje biblioteki zewnętrznej, otocz funkcję za pomocą mlflow.trace.
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
traced_accuracy_score = mlflow.trace(accuracy_score)
traced_accuracy_score(y_true, y_pred)
### Fluent API example
The following example shows how to use the Fluent APIs `mlflow.trace` and `mlflow.start_span` to trace the `quickstart-agent`:
```python
import mlflow
from mlflow.deployments import get_deploy_client
class QAChain(mlflow.pyfunc.PythonModel):
def __init__(self):
self.client = get_deploy_client("databricks")
@mlflow.trace(name="quickstart-agent")
def predict(self, model_input, system_prompt, params):
messages = [
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": model_input[0]["query"]
}
]
traced_predict = mlflow.trace(self.client.predict)
output = traced_predict(
endpoint=params["model_name"],
inputs={
"temperature": params["temperature"],
"max_tokens": params["max_tokens"],
"messages": messages,
},
)
with mlflow.start_span(name="_final_answer") as span:
# Initiate another span generation
span.set_inputs({"query": model_input[0]["query"]})
answer = output["choices"][0]["message"]["content"]
span.set_outputs({"generated_text": answer})
# Attributes computed at runtime can be set using the set_attributes() method.
span.set_attributes({
"model_name": params["model_name"],
"prompt_tokens": output["usage"]["prompt_tokens"],
"completion_tokens": output["usage"]["completion_tokens"],
"total_tokens": output["usage"]["total_tokens"]
})
return answer
Po dodaniu śladu uruchom funkcję. Kontynuujemy omawiany wcześniej przykład z funkcją predict() z poprzedniej sekcji. Ślady są wyświetlane automatycznie podczas uruchamiania metody wywołania predict().
SYSTEM_PROMPT = """
You are an assistant for Databricks users. You answer Python, coding, SQL, data engineering, spark, data science, DW and platform, API, or infrastructure administration questions related to Databricks. If the question is unrelated to one of these topics, kindly decline to answer. If you don't know the answer, say that you don't know; don't try to make up an answer. Keep the answer as concise as possible. Use the following pieces of context to answer the question at the end:
"""
model = QAChain()
prediction = model.predict(
[
{"query": "What is in MLflow 5.0"},
],
SYSTEM_PROMPT,
{
# Using Databricks Foundation Model for easier testing, feel free to replace it.
"model_name": "databricks-dbrx-instruct",
"temperature": 0.1,
"max_tokens": 1000,
}
)
interfejsy API klienta MLflow
MlflowClient uwidacznia szczegółowe, bezpieczne wątkowo interfejsy API do uruchamiania i kończenia śladów, zarządzania spanami i ustawiania pól spanów. Zapewnia pełną kontrolę nad cyklem życia i strukturą śledzenia. Te interfejsy API są przydatne, gdy Fluent APIs nie są wystarczające dla Twoich wymagań, takich jak aplikacje wielowątkowe i wywołania zwrotne.
Poniżej przedstawiono kroki tworzenia pełnego śledzenia przy użyciu klienta MLflow.
Utwórz wystąpienie klasy MLflowClient przez
client = MlflowClient().Rozpocznij śledzenie przy użyciu metody
client.start_trace(). Spowoduje to zainicjowanie kontekstu śledzenia, uruchomienie bezwzględnego zakresu głównego i zwrócenie obiektu zakresu głównego. Ta metoda musi zostać uruchomiona przed APIstart_span().- Ustaw atrybuty, dane wejściowe i wyjściowe dla śledzenia w
client.start_trace().
Uwaga
W interfejsach API Fluent nie istnieje odpowiednik metody
start_trace(). Dzieje się tak, ponieważ interfejsy API Fluent automatycznie inicjują kontekst śledzenia i określają, czy jest to zakres główny oparty na stanie zarządzanym.- Ustaw atrybuty, dane wejściowe i wyjściowe dla śledzenia w
Interfejs API start_trace() zwraca zakres. Pobierz identyfikator żądania, a także unikatowy identyfikator śladu określany jako
trace_id, oraz identyfikator zwróconego zakresu, używającspan.request_idispan.span_id.Rozpocznij zakres podrzędny przy użyciu
client.start_span(request_id, parent_id=span_id), aby ustawić atrybuty, dane wejściowe i wyjściowe dla zakresu.- Ta metoda wymaga
request_idiparent_iddo skojarzenia zakresu z prawidłową pozycją w hierarchii śledzenia. Zwraca kolejny obiekt typu span.
- Ta metoda wymaga
Zakończ zakres podrzędny, wywołując
client.end_span(request_id, span_id).Powtórz kroki 3– 5 dla wszystkich zakresów podrzędnych, które chcesz utworzyć.
Po zakończeniu wszystkich elementów podrzędnych wywołaj
client.end_trace(request_id), aby zamknąć ślad i zarejestrować go.
from mlflow.client import MlflowClient
mlflow_client = MlflowClient()
root_span = mlflow_client.start_trace(
name="simple-rag-agent",
inputs={
"query": "Demo",
"model_name": "DBRX",
"temperature": 0,
"max_tokens": 200
}
)
request_id = root_span.request_id
# Retrieve documents that are similar to the query
similarity_search_input = dict(query_text="demo", num_results=3)
span_ss = mlflow_client.start_span(
"search",
# Specify request_id and parent_id to create the span at the right position in the trace
request_id=request_id,
parent_id=root_span.span_id,
inputs=similarity_search_input
)
retrieved = ["Test Result"]
# You must explicitly end the span
mlflow_client.end_span(request_id, span_id=span_ss.span_id, outputs=retrieved)
root_span.end_trace(request_id, outputs={"output": retrieved})
Przeglądanie śladów
Aby przejrzeć ślady po uruchomieniu agenta, użyj jednej z następujących opcji:
- Wizualizacja śledzenia jest renderowana w tekście w danych wyjściowych komórki.
- Ślady są rejestrowane w eksperymencie MLflow. Pełną listę śladów historycznych można przeglądać i przeszukiwać na karcie Ślady na stronie Eksperyment. Gdy agent działa w ramach aktywnego przebiegu platformy MLflow, ślady są wyświetlane na stronie Uruchom.
- Programowe pobieranie śladów przy użyciu interfejsu API search_traces().
Korzystanie z śledzenia MLflow w środowisku produkcyjnym
Śledzenie MLflow jest również zintegrowane z usługą Mozaika AI Model Serving, umożliwiając wydajne debugowanie problemów, monitorowanie wydajności i tworzenie złotego zestawu danych na potrzeby oceny w trybie offline. Gdy śledzenie MLflow jest włączone dla punktu końcowego obsługującego, ślady są rejestrowane w tabeli wnioskowania w kolumnie response.
Aby włączyć śledzenie MLflow dla punktu końcowego serwowania, należy ustawić zmienną środowiskową ENABLE_MLFLOW_TRACING w konfiguracji punktu końcowego na True. Aby dowiedzieć się, jak wdrożyć punkt końcowy z niestandardowymi zmiennymi środowiskowymi, zobacz Dodawanie zmiennych środowiskowych w postaci zwykłego tekstu. Jeśli agent został wdrożony przy użyciu interfejsu API deploy(), ślady są automatycznie rejestrowane w tabeli wnioskowania. Zobacz Wdrażanie agenta na potrzeby generowania aplikacji sztucznej inteligencji.
Uwaga
Zapisywanie śladów w tabeli wnioskowania odbywa się asynchronicznie, dlatego nie powoduje dodania tego samego obciążenia, co w środowisku notesu podczas programowania. Może jednak nadal wprowadzać pewne obciążenie szybkości odpowiedzi punktu końcowego, szczególnie gdy rozmiar śledzenia dla każdego żądania wnioskowania jest duży. Usługa Databricks nie gwarantuje żadnej umowy dotyczącej poziomu usług (SLA) dla rzeczywistego wpływu opóźnienia na punkt końcowy modelu, ponieważ w dużym stopniu zależy od środowiska i implementacji modelu. Usługa Databricks zaleca przetestowanie wydajności punktu końcowego i uzyskanie wglądu w obciążenie śledzenia przed wdrożeniem w aplikacji produkcyjnej.
Poniższa tabela zawiera przybliżone wskazanie wpływu opóźnienia wnioskowania dla różnych rozmiarów śledzenia.
| Rozmiar śledzenia na żądanie | Wpływ na opóźnienie (ms) |
|---|---|
| ~10 KB | ~ 1 ms |
| ~ 1 MB | 50 ~ 100 ms |
| 10 MB | 150 ms ~ |
Ograniczenia
- Śledzenie MLflow jest dostępne w notesach usługi Databricks, zadaniach notesu i obsłudze modeli.
Automatyczne rejestrowanie langchain może nie obsługiwać wszystkich interfejsów API przewidywania LangChain. Pełną listę obsługiwanych interfejsów API można znaleźć w dokumentacji MLflow.