Co to jest obsługa funkcji usługi Databricks?
Funkcja usługi Databricks udostępnia dane na platformie Databricks modelom lub aplikacjom wdrożonym poza usługą Azure Databricks. Automatyczne skalowanie punktów końcowych obsługujących funkcje w celu dostosowania do ruchu w czasie rzeczywistym i zapewnienia wysokiej dostępności i małych opóźnień na potrzeby obsługi funkcji. Na tej stronie opisano sposób konfigurowania i używania funkcji obsługujących. Aby zapoznać się z samouczkiem krok po kroku, zobacz Wdrażanie i wykonywanie zapytań względem punktu końcowego obsługującego funkcję.
Gdy używasz usługi Mosaic AI Model Serving do obsługi modelu utworzonego przy użyciu funkcji z usługi Databricks, model automatycznie wyszukuje i przekształca funkcje żądań wnioskowania. Usługa Databricks Feature Serving umożliwia udostępnianie danych strukturalnych dla aplikacji generacji rozszerzonej (RAG), a także funkcji wymaganych dla innych aplikacji, takich jak modele obsługiwane poza usługą Databricks lub dowolną inną aplikacją, która wymaga funkcji opartych na danych w wykazie aparatu Unity.
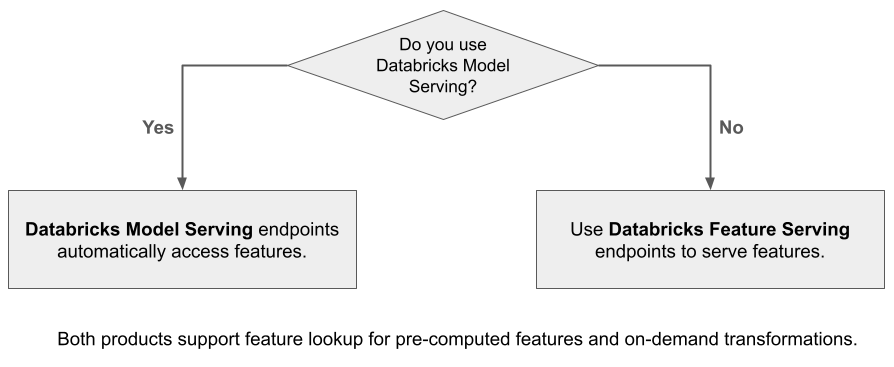
Dlaczego warto używać funkcji obsługujących?
Funkcja usługi Databricks udostępnia jeden interfejs, który obsługuje funkcje wstępnie zmaterializowane i na żądanie. Obejmuje również następujące korzyści:
- Prostota. Usługa Databricks obsługuje infrastrukturę. W przypadku pojedynczego wywołania interfejsu API usługa Databricks tworzy środowisko obsługujące gotowe do produkcji.
- Wysoka dostępność i skalowalność. Funkcje obsługujące punkty końcowe są automatycznie skalowane w górę i w dół, aby dostosować się do liczby obsługujących żądań.
- Zabezpieczenia. Punkty końcowe są wdrażane w bezpiecznej granicy sieci i używają dedykowanych obliczeń, które kończą się po usunięciu punktu końcowego lub skalowaniu do zera.
Wymagania
- Databricks Runtime 14.2 ML lub nowszy.
- Aby korzystać z interfejsu API języka Python, obsługa funkcji wymaga
databricks-feature-engineeringwersji 0.1.2 lub nowszej, która jest wbudowana w środowisko Databricks Runtime 14.2 ML. W przypadku wcześniejszych wersji uczenia maszynowego środowiska Databricks Runtime ręcznie zainstaluj wymaganą wersję przy użyciu polecenia%pip install databricks-feature-engineering>=0.1.2. Jeśli używasz notesu usługi Databricks, musisz ponownie uruchomić jądro języka Python, uruchamiając to polecenie w nowej komórce:dbutils.library.restartPython(). - Aby korzystać z zestawu SDK usługi Databricks, obsługa funkcji wymaga
databricks-sdkwersji 0.18.0 lub nowszej. Aby ręcznie zainstalować wymaganą wersję, użyj polecenia%pip install databricks-sdk>=0.18.0. Jeśli używasz notesu usługi Databricks, musisz ponownie uruchomić jądro języka Python, uruchamiając to polecenie w nowej komórce:dbutils.library.restartPython().
Funkcja usługi Databricks udostępnia interfejs użytkownika i kilka opcji programistycznych do tworzenia, aktualizowania, wykonywania zapytań i usuwania punktów końcowych. Ten artykuł zawiera instrukcje dotyczące każdej z następujących opcji:
- Interfejs użytkownika usługi Databricks
- Interfejs API REST
- Interfejs API języka Python
- Databricks SDK
Aby korzystać z interfejsu API REST lub zestawu MLflow Deployments SDK, musisz mieć token interfejsu API usługi Databricks.
Ważne
Najlepszym rozwiązaniem w zakresie zabezpieczeń w scenariuszach produkcyjnych usługa Databricks zaleca używanie tokenów OAuth maszyny do maszyny podczas uwierzytelniania w środowisku produkcyjnym.
W przypadku testowania i programowania usługa Databricks zaleca używanie osobistego tokenu dostępu należącego do jednostek usługi zamiast użytkowników obszaru roboczego. Aby utworzyć tokeny dla jednostek usługi, zobacz Zarządzanie tokenami dla jednostki usługi.
Uwierzytelnianie dla obsługi funkcji
Aby uzyskać informacje na temat uwierzytelniania, zobacz Autoryzowanie dostępu do zasobów usługi Azure Databricks.
Utwórz FeatureSpec
A FeatureSpec to zdefiniowany przez użytkownika zestaw funkcji i funkcji. Funkcje i funkcje można łączyć w obiekcie FeatureSpec.
FeatureSpecs są przechowywane w wykazie aparatu Unity i zarządzane przez program i są wyświetlane w Eksploratorze wykazu.
Tabele określone w obiekcie FeatureSpec muszą być publikowane w tabeli online lub w sklepie online innej firmy. Zobacz Używanie tabel online na potrzeby obsługi funkcji w czasie rzeczywistym lub sklepów online innych firm.
Należy użyć databricks-feature-engineering pakietu, aby utworzyć element FeatureSpec.
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates a - b.
input_bindings={"a": "ytd_spend", "b": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
Tworzenie punktu końcowego
Element FeatureSpec definiuje punkt końcowy. Aby uzyskać więcej informacji, zobacz Tworzenie niestandardowych punktów końcowych obsługujących model, dokumentację interfejsu API języka Python lub dokumentację zestawu SDK usługi Databricks, aby uzyskać szczegółowe informacje.
Uwaga
W przypadku obciążeń, które są wrażliwe na opóźnienia lub wymagają wysokich zapytań na sekundę, usługa Model Serving oferuje optymalizację tras w punktach końcowych obsługujących niestandardowy model, zobacz Konfigurowanie optymalizacji tras w punktach końcowych obsługujących obsługę.
Interfejs API REST
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
Zestaw SDK usługi Databricks — Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
Interfejs API języka Python
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
Aby wyświetlić punkt końcowy, kliknij pozycję Obsługa na lewym pasku bocznym interfejsu użytkownika usługi Databricks. Gdy stan jest gotowy, punkt końcowy jest gotowy do odpowiadania na zapytania. Aby dowiedzieć się więcej na temat serwowania modeli mozaiki sztucznej inteligencji, zobacz Mozaika AI Model Serving (Obsługa modeli mozaiki sztucznej inteligencji).
Uzyskiwanie punktu końcowego
Aby uzyskać metadane i stan punktu końcowego, możesz użyć zestawu SDK usługi Databricks lub interfejsu API języka Python.
Zestaw SDK usługi Databricks — Python
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
Interfejs API języka Python
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
Pobieranie schematu punktu końcowego
Aby uzyskać schemat punktu końcowego, możesz użyć interfejsu API REST. Aby uzyskać więcej informacji na temat schematu punktu końcowego, zobacz Pobieranie schematu punktu końcowego obsługującego model.
ACCESS_TOKEN=<token>
ENDPOINT_NAME=<endpoint name>
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
Wykonywanie zapytań względem punktu końcowego
Do wykonywania zapytań dotyczących punktu końcowego można użyć interfejsu API REST, zestawu SDK wdrożeń MLflow lub interfejsu użytkownika obsługującego.
Poniższy kod pokazuje, jak skonfigurować poświadczenia i utworzyć klienta podczas korzystania z zestawu MLflow Deployments SDK.
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Uwaga
Najlepszym rozwiązaniem w zakresie zabezpieczeń w przypadku uwierzytelniania za pomocą zautomatyzowanych narzędzi, systemów, skryptów i aplikacji usługa Databricks zaleca używanie osobistych tokenów dostępu należących do jednostek usługi zamiast użytkowników obszaru roboczego. Aby utworzyć tokeny dla jednostek usługi, zobacz Zarządzanie tokenami dla jednostki usługi.
Wykonywanie zapytań dotyczących punktu końcowego przy użyciu interfejsów API
Ta sekcja zawiera przykłady wykonywania zapytań dotyczących punktu końcowego przy użyciu interfejsu API REST lub zestawu SDK wdrożeń MLflow.
Interfejs API REST
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
Zestaw SDK wdrożeń MLflow
Ważne
W poniższym przykładzie użyto interfejsu predict() API z zestawu SDK wdrożeń MLflow. Ten interfejs API jest eksperymentalny , a definicja interfejsu API może ulec zmianie.
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
Wykonywanie zapytań dotyczących punktu końcowego przy użyciu interfejsu użytkownika
Możesz wykonać zapytanie dotyczące punktu końcowego obsługującego bezpośrednio z poziomu interfejsu użytkownika obsługującego. Interfejs użytkownika zawiera wygenerowane przykłady kodu, których można użyć do wykonywania zapytań dotyczących punktu końcowego.
Na lewym pasku bocznym obszaru roboczego usługi Azure Databricks kliknij pozycję Obsługa.
Kliknij punkt końcowy, który chcesz wykonać zapytanie.
W prawym górnym rogu ekranu kliknij pozycję Punkt końcowy zapytania.
W polu Żądanie wpisz treść żądania w formacie JSON.
Kliknij pozycję Wyślij żądanie.
// Example of a request body.
{
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]
}
Okno dialogowe Punkt końcowy zapytania zawiera wygenerowany przykładowy kod w języku curl, Python i SQL. Kliknij karty, aby wyświetlić i skopiować przykładowy kod.
Aby skopiować kod, kliknij ikonę kopiowania w prawym górnym rogu pola tekstowego.
Aktualizowanie punktu końcowego
Punkt końcowy można zaktualizować przy użyciu interfejsu API REST, zestawu SDK usługi Databricks lub interfejsu użytkownika obsługującego.
Aktualizowanie punktu końcowego przy użyciu interfejsów API
Interfejs API REST
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
Zestaw SDK usługi Databricks — Python
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
Aktualizowanie punktu końcowego przy użyciu interfejsu użytkownika
Wykonaj następujące kroki, aby użyć interfejsu użytkownika obsługującego:
- Na lewym pasku bocznym obszaru roboczego usługi Azure Databricks kliknij pozycję Obsługa.
- W tabeli kliknij nazwę punktu końcowego, który chcesz zaktualizować. Zostanie wyświetlony ekran punktu końcowego.
- W prawym górnym rogu ekranu kliknij pozycję Edytuj punkt końcowy.
- W oknie dialogowym Edytowanie obsługującego punktu końcowego zmodyfikuj ustawienia punktu końcowego zgodnie z potrzebami.
- Kliknij przycisk Aktualizuj, aby zapisać zmiany.

Usuwanie punktu końcowego
Ostrzeżenie
Ta akcja jest nieodwracalna.
Punkt końcowy można usunąć przy użyciu interfejsu API REST, zestawu SDK usługi Databricks, interfejsu API języka Python lub interfejsu użytkownika obsługującego.
Usuwanie punktu końcowego przy użyciu interfejsów API
Interfejs API REST
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
Zestaw SDK usługi Databricks — Python
workspace.serving_endpoints.delete(name="customer-features")
Interfejs API języka Python
fe.delete_feature_serving_endpoint(name="customer-features")
Usuwanie punktu końcowego przy użyciu interfejsu użytkownika
Wykonaj następujące kroki, aby usunąć punkt końcowy przy użyciu interfejsu użytkownika obsługującego:
- Na lewym pasku bocznym obszaru roboczego usługi Azure Databricks kliknij pozycję Obsługa.
- W tabeli kliknij nazwę punktu końcowego, który chcesz usunąć. Zostanie wyświetlony ekran punktu końcowego.
- W prawym górnym rogu ekranu kliknij menu
 kebab i wybierz pozycję Usuń.
kebab i wybierz pozycję Usuń.

Monitorowanie kondycji punktu końcowego
Aby uzyskać informacje o dziennikach i metrykach dostępnych dla punktów końcowych obsługujących funkcje, zobacz Monitorowanie jakości modelu i kondycji punktu końcowego.
Kontrola dostępu
Aby uzyskać informacje o uprawnieniach do punktów końcowych obsługujących funkcje, zobacz Zarządzanie uprawnieniami w punkcie końcowym obsługującym model.
Przykładowy notes
W tym notesie pokazano, jak za pomocą zestawu SDK usługi Databricks utworzyć punkt końcowy obsługujący funkcję przy użyciu tabel online usługi Databricks.