Wprowadzenie do programu RAG w tworzeniu sztucznej inteligencji
Ten artykuł stanowi wprowadzenie do generacji wspomaganej wyszukiwaniem (RAG): co to jest, jak to działa i kluczowe pojęcia.
Co to jest generacja wspomagana wyszukiwaniem?
RAG to technika, która umożliwia dużemu modelowi językowemu generowanie wzbogaconych odpowiedzi przez rozszerzenie monitu użytkownika o obsługę danych pobranych ze źródła informacji zewnętrznych. Dzięki włączeniu tych pobranych informacji system RAG umożliwia LLM generowanie dokładniejszych i bardziej jakościowych odpowiedzi w porównaniu do sytuacji, gdy monit nie jest wzbogacony o dodatkowy kontekst.
Załóżmy na przykład, że tworzysz czatbota z pytaniami i odpowiedziami, aby pomóc pracownikom w odpowiadaniu na pytania dotyczące zastrzeżonych dokumentów firmy. Samodzielny model LLM nie będzie mógł dokładnie odpowiedzieć na pytania dotyczące zawartości tych dokumentów, jeśli nie został specjalnie wytrenowany przy ich użyciu. LLM może odmówić odpowiedzi z powodu braku informacji lub, co gorsza, może dać niepoprawną odpowiedź.
PROGRAM RAG rozwiązuje ten problem, pobierając najpierw odpowiednie informacje z dokumentów firmy na podstawie zapytania użytkownika, a następnie podając pobrane informacje do programu LLM jako dodatkowy kontekst. Dzięki temu usługa LLM może wygenerować dokładniejszą odpowiedź, korzystając z określonych szczegółów znajdujących się w odpowiednich dokumentach. W istocie RAG umożliwia LLM zapoznanie się z pobranymi informacjami, aby sformułować odpowiedź.
Podstawowe składniki aplikacji RAG
Aplikacja RAG jest przykładem złożonego systemu sztucznej inteligencji: rozszerza możliwości językowe modelu, łącząc go z innymi narzędziami i procedurami.
W przypadku korzystania z autonomicznego rozwiązania LLM użytkownik przesyła żądanie, takie jak pytanie, do usługi LLM, a usługa LLM odpowiada na odpowiedź wyłącznie na podstawie danych treningowych.
W najbardziej podstawowej formie następujące kroki są wykonywane w aplikacji RAG:
- Pobieranie: żądanie użytkownika jest używane do wykonywania zapytań dotyczących niektórych informacji spoza źródła informacji. Może to oznaczać wykonywanie zapytań względem magazynu wektorów, przeprowadzanie wyszukiwania słów kluczowych przez jakiś tekst lub wykonywanie zapytań względem bazy danych SQL. Celem kroku pobierania jest uzyskanie danych pomocniczych, które pomagają usłudze LLM zapewnić przydatną odpowiedź.
- Rozszerzenie: dane pomocnicze z kroku pobierania są łączone z żądaniem użytkownika, często przy użyciu szablonu z dodatkowym formatowaniem i instrukcjami dla modelu LLM w celu utworzenia polecenia.
- Generowanie: wynikowy monit jest przekazywany do usługi LLM, a usługa LLM generuje odpowiedź na żądanie użytkownika.
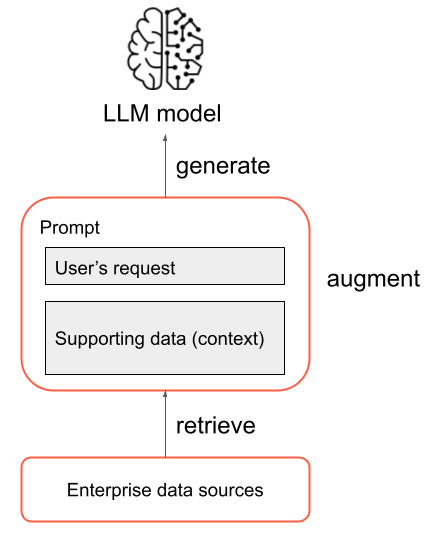
Jest to uproszczony przegląd procesu RAG, ale należy pamiętać, że implementacja aplikacji RAG obejmuje wiele złożonych zadań. Wstępne przetwarzanie danych źródłowych w celu przygotowania ich do użycia w narzędziu RAG, efektywne pobieranie danych, formatowanie rozszerzonego monitu i ocenianie wygenerowanych odpowiedzi wymaga starannego rozważenia i nakładu pracy. Te tematy zostaną szczegółowo omówione w kolejnych sekcjach tego przewodnika.
Dlaczego warto używać programu RAG?
W poniższej tabeli przedstawiono korzyści wynikające z używania programu RAG w porównaniu z autonomicznym modułem LLM:
| Z samym modułem LLM | Korzystanie z LLM z RAG |
|---|---|
| Brak własnościowej wiedzy: LLMs są zwykle trenowane na podstawie publicznie dostępnych danych, więc nie mogą dokładnie odpowiedzieć na pytania dotyczące danych wewnętrznych lub zastrzeżonych firmy. | Aplikacje RAG mogą zawierać zastrzeżone dane: aplikacja RAG może dostarczać zastrzeżone dokumenty, takie jak notatki, wiadomości e-mail i dokumenty projektowe do usługi LLM, umożliwiając mu odpowiadanie na pytania dotyczące tych dokumentów. |
| Wiedza nie jest aktualizowana w czasie rzeczywistym: llMs nie mają dostępu do informacji o zdarzeniach, które wystąpiły po ich wytrenowaniu. Na przykład samodzielny LLM nie może powiedzieć nic o ruchach giełdowych dzisiaj. | Aplikacje RAG mogą uzyskiwać dostęp do danych w czasie rzeczywistym: aplikacja RAG może dostarczyć LLM aktualne informacje z zaktualizowanego źródła danych, co pozwala na udzielanie przydatnych odpowiedzi na temat zdarzeń po dacie zakończenia szkolenia. |
| Brak cytatów: LLMs nie mogą przytaczać określonych źródeł informacji podczas odpowiadania, pozostawiając użytkownikowi brak możliwości sprawdzenia, czy odpowiedź jest poprawna w rzeczywistości, czy halucynacja. | RAG może przytaczać źródła: W przypadku użycia w ramach aplikacji RAG można poprosić LLM o przytaczanie swoich źródeł. |
| Brak kontroli dostępu do danych (ACL): sama usługa LLMs nie może niezawodnie zapewnić różnych odpowiedzi różnym użytkownikom na podstawie określonych uprawnień użytkownika. | Funkcja RAG umożliwia zabezpieczenie danych/ACL: krok pobierania można zaprojektować tak, aby znajdował wyłącznie informacje, do których użytkownik posiada odpowiednie uprawnienia dostępu, co umożliwia aplikacji RAG selektywne pobieranie informacji osobistych lub poufnych. |
Składniki aplikacji RAG
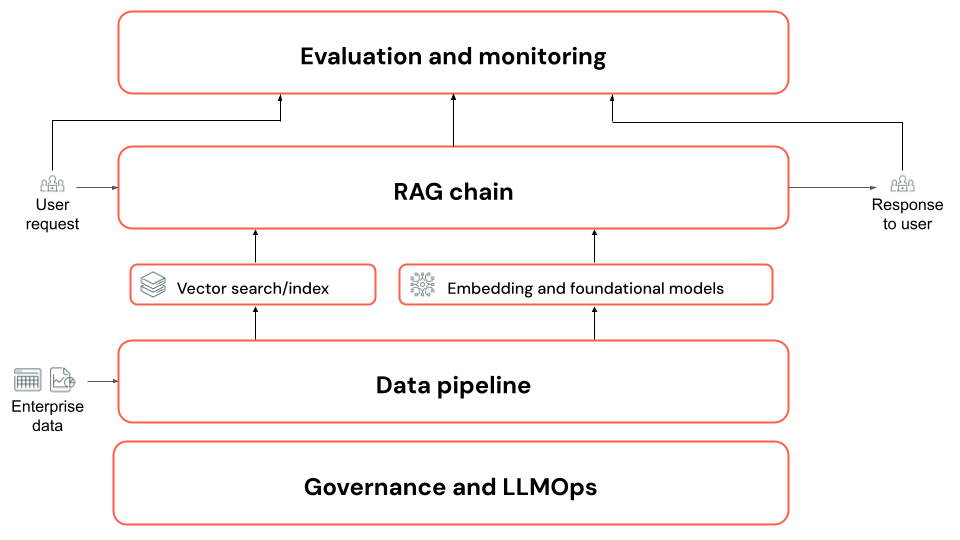
W szczególności:
- Potok danych: przekształcanie dokumentów bez struktury, takich jak kolekcje plików PDF, w format odpowiedni do pobierania przy użyciu potoku danych aplikacji RAG.
-
Pobieranie, rozszerzanie i generowanie (łańcuch RAG): Seria (lub łańcuch) kroków jest wywoływana w celu:
- Zapoznaj się z pytaniem użytkownika.
- Pobieranie danych pomocniczych.
- Wywołaj moduł LLM, aby wygenerować odpowiedź na podstawie pytania użytkownika i danych pomocniczych.
- Ocena: Ocena aplikacji RAG w celu określenia jego jakości, kosztów i opóźnień w celu zapewnienia, że spełnia wymagania biznesowe.
- Governance and LLMOps: Śledzenie i zarządzanie cyklem życia każdego składnika, w tym pochodzeniem danych i zarządzaniem (mechanizmy kontroli dostępu).
Typy rag
Architektura RAG może współdziałać z dwoma typami danych pomocniczych:
| Dane strukturalne | Dane bez struktury | |
|---|---|---|
| Definicja | Dane tabelaryczne rozmieszczone w wierszach i kolumnach z określonym schematem, na przykład tabelami w bazie danych. | Dane bez określonej struktury lub organizacji, na przykład dokumenty zawierające tekst i obrazy lub zawartość multimedialną, taką jak audio lub wideo. |
| Przykładowe źródła danych |
|
|
Twój wybór danych RAG zależy od zastosowania. W pozostałej części samouczka skupiono się na funkcji RAG dla danych bez struktury.