Jak utworzyć indeks wyszukiwania wektorowego i wykonywać względem tego zapytania
W tym artykule opisano sposób tworzenia i wykonywania zapytań względem indeksu wyszukiwania wektora przy użyciu Mosaic AI Vector Search.
Możesz tworzyć składniki wyszukiwania wektorów i zarządzać nimi, takie jak punkt końcowy wyszukiwania wektorów i indeksy wyszukiwania wektorów, przy użyciu interfejsu użytkownika, zestawu SDK pythonlub interfejsu API REST .
Wymagania
- Obszar roboczy z obsługą Catalog w Unity.
- Włączono bezserwerowe obliczenia. Aby uzyskać instrukcje, zobacz Connect to serverless compute.
- Źródło table musi mieć włączony strumień zmian danych. Aby uzyskać instrukcje, zobacz Wykorzystanie strumienia danych zmiany w Delta Lake na platformie Azure Databricks.
- Aby utworzyć indeks wyszukiwania wektorowego, musisz mieć uprawnienia CREATE TABLE w catalogschemawhere indeks zostanie utworzony.
- Aby wykonać zapytanie dotyczące indeksu należącego do innego użytkownika, musisz mieć dodatkowe uprawnienia. Zobacz Zapytanie wektorowego punktu końcowego wyszukiwania.
Uprawnienia do tworzenia punktów końcowych wyszukiwania wektorów i zarządzania nimi są konfigurowane przy użyciu list kontroli dostępu. Zobacz listy ACL punktu końcowego wyszukiwania wektorów .
Instalacja
Aby użyć zestawu SDK wyszukiwania wektorowego, należy zainstalować go w notesie. Użyj następującego kodu, aby zainstalować pakiet:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
Następnie użyj następującego polecenia, aby zaimportować VectorSearchClient:
from databricks.vector_search.client import VectorSearchClient
Uwierzytelnianie
Zobacz Ochrona danych i uwierzytelnianie.
Tworzenie punktu końcowego wyszukiwania wektorów
Punkt końcowy wyszukiwania wektorów można utworzyć przy użyciu interfejsu użytkownika usługi Databricks, zestawu SDK języka Python lub interfejsu API.
Tworzenie punktu końcowego wyszukiwania wektorów przy użyciu interfejsu użytkownika
Wykonaj następujące kroki, aby utworzyć punkt końcowy wyszukiwania wektorów przy użyciu interfejsu użytkownika.
Na lewym pasku bocznym kliknij pozycję Compute.
Kliknij kartę wyszukiwania wektorowego i kliknij Utwórz.

Otwiera się formularz tworzenia punktu końcowego . Wprowadź nazwę tego punktu końcowego.
Kliknij Potwierdź.
Tworzenie punktu końcowego wyszukiwania wektorów przy użyciu zestawu SDK języka Python
W poniższym przykładzie użyto funkcji zestawu SDK create_endpoint() w celu utworzenia punktu końcowego wyszukiwania wektorów.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
Tworzenie punktu końcowego wyszukiwania wektorów przy użyciu interfejsu API REST
Zobacz dokumentację referencyjną interfejsu API REST: POST /api/2.0/vector-search/endpoints.
(Opcjonalnie) Tworzenie i konfigurowanie punktu końcowego w celu obsługi modelu osadzania
Jeśli zdecydujesz się, aby usługa Databricks obliczała wektory, możesz użyć wstępnie skonfigurowanego punktu końcowego interfejsów API modelu bazowego lub utworzyć punkt końcowy obsługujący wybrany model osadzania. Aby uzyskać instrukcje, zobacz interfejsy API modelu modelu z płatnością za token lub Tworzenie modelu podstawowego obsługującego punkty końcowe. Aby uzyskać przykładowe notesy, zobacz przykłady Notebook dotyczące wywoływania modelu osadzania.
Podczas konfigurowania punktu końcowego osadzania usługa Databricks zaleca remove domyślny wybór opcji skalowania do zera. Obsługa punktów końcowych może potrwać kilka minut, a początkowe zapytanie dotyczące indeksu ze skalowanym w dół punktem końcowym może spowodować przekroczenie limitu czasu.
Notatka
Inicjowanie indeksu wyszukiwania wektorowego może upłynąć limit czasu, jeśli punkt końcowy osadzania wektorów nie został odpowiednio skonfigurowany dla zestawu danych. W przypadku małych zestawów danych i testów należy używać tylko punktów końcowych procesora CPU. W przypadku większych zestawów danych użyj punktu końcowego procesora GPU w celu uzyskania optymalnej wydajności.
Tworzenie indeksu wyszukiwania wektorów
Indeks wyszukiwania wektorowego można utworzyć przy użyciu interfejsu użytkownika, zestawu SDK języka Python lub interfejsu API REST. Interfejs użytkownika jest najprostszym podejściem.
Istnieją dwa typy indeksów:
- Indeks Sync Delta automatycznie synchronizuje się ze źródłowym Delta Table, automatycznie i przyrostowo aktualizując indeks, gdy dane bazowe w Delta Table się zmieniają.
- Bezpośredni Indeks Dostępu do Wektorów umożliwia bezpośrednie odczytywanie i zapisywanie wektorów oraz metadanych. Użytkownik jest odpowiedzialny za zaktualizowanie tego table przy użyciu interfejsu API REST lub zestawu SDK języka Python. Nie można utworzyć tego typu indeksu przy użyciu interfejsu użytkownika. Musisz użyć interfejsu API REST lub zestawu SDK.
Tworzenie indeksu przy użyciu interfejsu użytkownika
Na pasku bocznym po lewej stronie kliknij Catalog, aby otworzyć interfejs użytkownika eksploratora Catalog.
Przejdź do Delta table, której chcesz użyć.
Kliknij przycisk Utwórz w prawym górnym rogu, a następnie wybierz selectindeks wyszukiwania wektorów z listy rozwijanej.
Użyj selektorów w oknie dialogowym, aby skonfigurować indeks.
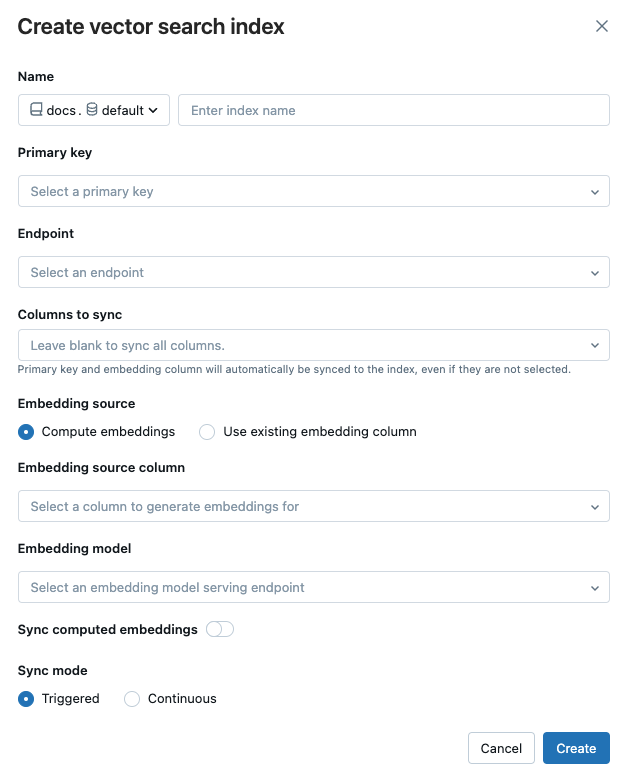
Nazwa: nazwa do użycia w table online w Unity Catalog. Nazwa wymaga trzypoziomowej przestrzeni nazw,
<catalog>.<schema>.<name>. Dozwolone są tylko znaki alfanumeryczne i podkreślenia.klucz podstawowy: Column do użycia jako klucz podstawowy.
Endpoint: Select punkt końcowy wyszukiwania wektorów, którego chcesz użyć.
Columns do sync: Selectcolumns do sync z indeksem wektorowym. Jeśli to pole pozostanie puste, wszystkie columns ze źródła table zostaną zsynchronizowane z indeksem. Klucz podstawowy column oraz wektor osadzania źródłowego column lub wektor osadzania column są zawsze synchronizowane.
Źródło osadzania: Wskaż, czy chcesz, aby Databricks obliczał osadzanie dla column tekstu w Delcie table (Oblicz osadzanie), czy twoja Delta table zawiera wstępnie obliczone osadzanie (Użyj istniejącego osadzania column).
- W przypadku wybrania obliczania osadzeń, określ select oraz column, dla których chcesz obliczyć osadzenia, oraz punkt końcowy obsługujący model osadzeniowy. Obsługiwane są tylko teksty columns.
- W przypadku wybrania Użyj istniejącego osadzenia column, selectcolumn, który zawiera wstępnie obliczone osadzenia oraz wymiar osadzenia. Format wstępnie obliczonego osadzenia column powinien być
array[float].
Sync obliczone wektory osadzeń: Włącz to ustawienie, aby zapisać wygenerowane wektory osadzeń w Unity Catalogtable. Aby uzyskać więcej informacji, zobacz Zapisz wygenerowane osadzenie table.
Sync tryb: Ciągły utrzymuje indeks w sync z opóźnieniem wynoszącym kilka sekund. Jednak wiąże się z nim wyższy koszt, ponieważ klaster obliczeniowy jest konfigurowany do uruchamiania nieprzerwanego potoku przesyłania strumieniowego sync. W przypadku ciągłych i wyzwalanychupdate są przyrostowe — są przetwarzane tylko dane, które uległy zmianie od czasu ostatniego sync.
W trybie wyzwalanymsync użyjesz zestawu SDK języka Python lub interfejsu API REST, aby uruchomić sync. Zobacz Update indeks Delta Sync.
Po zakończeniu konfigurowania indeksu kliknij pozycję Utwórz.
Tworzenie indeksu przy użyciu zestawu SDK języka Python
Poniższy przykład tworzy indeks Delta Sync z osadzonych obliczeń wykonanych przez Databricks.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
Poniższy przykład tworzy indeks Delta Sync z samodzielnie zarządzanymi osadzeniami. W tym przykładzie pokazano również użycie opcjonalnego columns_to_sync parametru w celu select tylko podzestawu columns do użycia w indeksie.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Domyślnie wszystkie columns ze źródła table są synchronizowane z indeksem. Aby użyć tylko podzbioru sync, użyj columnsdla columns_to_sync. Klucz podstawowy i osadzanie columns są zawsze uwzględniane w indeksie.
Aby synctylko klucz podstawowy i osadzanie column, należy określić je w columns_to_sync, jak pokazano poniżej:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Aby dodać sync do columns, określ je tak, jak pokazano. Nie musisz dołączać klucza podstawowego oraz wskaźnika column, ponieważ są one zawsze synchronizowane.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
Poniższy przykład tworzy indeks bezpośredniego dostępu do wektora.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Tworzenie indeksu przy użyciu interfejsu API REST
Zobacz dokumentację referencyjną interfejsu API REST: POST /api/2.0/vector-search/indexes.
Zapisz wygenerowane embedowanie table
Jeśli usługa Databricks generuje reprezentacje, możesz zapisać wygenerowane reprezentacje w table w środowisku Unity Catalog. Ten table jest tworzony w tym samym schema co indeks wektorowy i jest połączony ze strony indeksu wektorowego.
Nazwa table to nazwa indeksu wyszukiwania wektorowego, dołączana przez _writeback_table. Nazwa nie jest edytowalna.
Możesz uzyskiwać dostęp do table i przeprowadzać zapytania, podobnie jak do innych table w środowisku Unity Catalog. Nie należy jednak usuwać ani modyfikować table, ponieważ nie jest ona przeznaczona do ręcznej aktualizacji. table jest usuwany automatycznie, jeśli indeks zostanie usunięty.
Update indeks wyszukiwania wektorowego
Update indeks Delta Sync
Indeksy utworzone za pomocą trybu ciągłegosync automatycznie update, gdy źródłowa Delta table ulegnie zmianie. Jeśli używasz trybu wyzwalanegosync, użyj Python SDK lub interfejsu API REST, aby uruchomić sync.
Python SDK
index.sync()
REST API
Zobacz dokumentację referencyjną interfejsu API REST: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Update indeksu dostępu bezpośredniego wektora
Można użyć SDK języka Python lub interfejsu API REST do insert, updatelub usunięcia danych z bezpośredniego indeksu dostępu wektorowego.
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
REST API
Zobacz dokumentację referencyjną interfejsu API REST: POST /api/2.0/vector-search/indexes.
Poniższy przykład kodu ilustruje sposób update indeksu przy użyciu osobistego tokenu dostępu (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
Poniższy przykład kodu ilustruje sposób update indeksu przy użyciu jednostki usługi.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Zapytanie wektorowego punktu końcowego wyszukiwania
Zapytania do punktu końcowego wyszukiwania wektorów można wykonywać tylko za pomocą SDK dla języka Python, API REST lub funkcji SQL AI vector_search().
Notatka
Jeśli użytkownik wykonujący zapytanie dotyczące punktu końcowego nie jest właścicielem indeksu wyszukiwania wektorowego, użytkownik musi mieć następujące uprawnienia UC:
- USE CATALOG na catalog, który zawiera wektorowy indeks wyszukiwania.
- USE SCHEMA na schema, który zawiera wektorowy indeks wyszukiwania.
- SELECT jest na indeksie wyszukiwania wektorowego.
Aby przeprowadzić hybrydowe wyszukiwanie podobieństwa słów kluczowych, set parametr query_type na hybrid. Wartość domyślna to ann (przybliżony najbliższy sąsiad).
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
REST API
Zobacz dokumentację referencyjną interfejsu API REST: POST /api/2.0/vector-search/indexes/{index_name}/query.
Poniższy przykład kodu ilustruje sposób wykonywania zapytań względem indeksu przy użyciu osobistego tokenu dostępu (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query Vector Search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
Poniższy przykład kodu ilustruje sposób wykonywania zapytań względem indeksu przy użyciu jednostki usługi.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint (TODO: link), then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
Ważny
Funkcja AI vector_search() znajduje się w fazie Public Preview.
Aby użyć tej funkcji sztucznej inteligencji , zobacz funkcję vector_search .
Używanie filtrów w zapytaniach
Zapytanie może definiować filtry na podstawie dowolnego column w delcie table.
similarity_search zwraca tylko wiersze zgodne z określonymi filtrami. Obsługiwane są następujące filtry:
| Operator filtru | Zachowanie | Przykłady |
|---|---|---|
NOT |
Neguje filtr. Klucz musi kończyć się ciągiem "NOT". Na przykład "color NOT" z wartością "red" pasuje do dokumentów, w których where kolor nie jest czerwony. |
{"id NOT": 2}
{“color NOT”: “red”}
|
< |
Sprawdza, czy wartość pola jest mniejsza niż wartość filtru. Klucz musi kończyć się znakiem "<". Na przykład "price <" z wartością 200 pasuje do dokumentów, where cena jest mniejsza niż 200. | {"id <": 200} |
<= |
Sprawdza, czy wartość pola jest mniejsza lub równa wartości filtru. Klucz musi kończyć się sekwencją " <=". Na przykład „price <=” z wartością 200, odpowiada dokumentom where, w których cena jest mniejsza lub równa 200. | {"id <=": 200} |
> |
Sprawdza, czy wartość pola jest większa niż wartość filtru. Klucz musi kończyć się znakiem ">". Na przykład "price >" z wartością 200 pasuje do dokumentów where cena jest większa niż 200. | {"id >": 200} |
>= |
Sprawdza, czy wartość pola jest większa lub równa wartości filtru. Klucz musi kończyć się sekwencją " >=". Na przykład "price >=" z wartością 200 pasuje do dokumentu where, w którym cena jest większa lub równa 200. | {"id >=": 200} |
OR |
Sprawdza, czy wartość pola jest zgodna z dowolnym filtrem values. Klucz musi zawierać OR, aby oddzielić wiele podkluczy. Na przykład color1 OR color2 z wartością ["red", "blue"] pasuje do dokumentów where, jeśli color1 jest red lub color2 jest blue. |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
Dopasowuje częściowe ciągi znaków. | {"column LIKE": "hello"} |
| Nie określono operatora filtru | Sprawdzanie filtru pod kątem dokładnego dopasowania. Jeśli określono wiele values, zgadza się z którymkolwiek z values. |
{"id": 200}
{"id": [200, 300]}
|
Zobacz następujące przykłady kodu:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
REST API
Zobacz POST /api/2.0/vector-search/indexes/{index_name}/query.
Przykładowe zeszyty
Przykłady w tej sekcji przedstawiają użycie SDK wyszukiwania wektorowego w języku Python.
Przykłady LangChain
Zobacz Jak używać LangChain z Mosaic AI Vector Search, aby korzystać z Mosaic AI Vector Search w integracji z pakietami LangChain.
W poniższym notesie pokazano, jak przekonwertować wyniki wyszukiwania podobieństwa na dokumenty LangChain.
Wyszukiwanie wektorowe w notesie SDK Pythona
notesu
przykłady notesu do wywoływania modelu osadzania
W poniższych notatnikach pokazano, jak skonfigurować punkt końcowy udostępniania modelu AI Mosaic do generowania osadzeń.
Wywoływanie modelu osadzania OpenAI przy użyciu notebooka Model Serving Mosaic AI
notesu
Wywołaj model osadzeń GTE przy użyciu notatnika Mosaic AI Model Serving
notesu
Rejestrowanie i obsługa notebooka modelu osadzającego OSS
notesu