Zalecenia dotyczące oczekiwań i zaawansowane wzorce
Ten artykuł zawiera zalecenia dotyczące implementowania oczekiwań na dużą skalę i przykłady zaawansowanych wzorców obsługiwanych przez oczekiwania. Te wzorce używają wielu zestawów danych w połączeniu z oczekiwaniami i wymagają, aby użytkownicy rozumieli składnię i semantyka zmaterializowanych widoków, tabel przesyłania strumieniowego i oczekiwań.
Aby zapoznać się z podstawowym omówieniem zachowania i składni oczekiwań, zobacz sekcję Zarządzanie jakością danych za pomocą oczekiwań w potokach.
oczekiwania dotyczące przenośności i wielokrotnego użytku
Usługa Databricks zaleca następujące najlepsze rozwiązania dotyczące wdrażania oczekiwań w celu zwiększenia przenośności i zmniejszenia obciążeń związanych z konserwacją:
| Zalecenie | Wpływ |
|---|---|
| Przechowuj specyfikacje oczekiwań oddzielnie od logiki procesu. | Łatwe stosowanie oczekiwań do wielu zestawów danych lub potoków. Aktualizowanie, przeprowadzanie inspekcji i utrzymywanie oczekiwań bez modyfikowania kodu źródłowego potoku. |
| Dodaj tagi niestandardowe, aby utworzyć grupy powiązanych oczekiwań. | Filtruj oczekiwania na podstawie tagów. |
| Stosuj oczekiwania konsekwentnie w podobnych zestawach danych. | Użyj tych samych oczekiwań w wielu zestawach danych i potokach, aby ocenić identyczną logikę. |
W poniższych przykładach pokazano użycie tabeli delty lub słownika w celu utworzenia centralnego repozytorium oczekiwań. Niestandardowe funkcje języka Python następnie stosują te oczekiwania do zestawów danych w przykładowym potoku:
Tabela delty
Poniższy przykład tworzy tabelę o nazwie rules w celu zachowania reguł:
CREATE OR REPLACE TABLE
rules
AS SELECT
col1 AS name,
col2 AS constraint,
col3 AS tag
FROM (
VALUES
("website_not_null","Website IS NOT NULL","validity"),
("fresh_data","to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'","maintained"),
("social_media_access","NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)","maintained")
)
Poniższy przykład w języku Python definiuje oczekiwania dotyczące jakości danych na podstawie reguł w tabeli rules. Funkcja get_rules() odczytuje reguły z tabeli rules i zwraca słownik języka Python zawierający reguły pasujące do argumentu tag przekazanego do funkcji.
W tym przykładzie słownik jest stosowany przy użyciu @dlt.expect_all_or_drop() dekoratorów w celu wymuszania ograniczeń jakości danych.
Na przykład wszystkie rekordy zakończone niepowodzeniem reguł oznaczonych validity zostaną usunięte z tabeli raw_farmers_market:
import dlt
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
df = spark.read.table("rules").filter(col("tag") == tag).collect()
return {
row['name']: row['constraint']
for row in df
}
@dlt.table
@dlt.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dlt.table
@dlt.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
dlt.read("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Moduł języka Python
W poniższym przykładzie tworzony jest moduł języka Python do obsługi reguł. W tym przykładzie zapisz ten kod w pliku o nazwie rules_module.py w tym samym folderze co notes używany jako kod źródłowy potoku:
def get_rules_as_list_of_dict():
return [
{
"name": "website_not_null",
"constraint": "Website IS NOT NULL",
"tag": "validity"
},
{
"name": "fresh_data",
"constraint": "to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'",
"tag": "maintained"
},
{
"name": "social_media_access",
"constraint": "NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)",
"tag": "maintained"
}
]
Poniższy przykład w języku Python definiuje oczekiwania dotyczące jakości danych na podstawie reguł zdefiniowanych w pliku rules_module.py. Funkcja get_rules() zwraca słownik języka Python zawierający reguły pasujące do argumentu tag przekazanego do niego.
W tym przykładzie słownik jest wykorzystywany z użyciem dekoratorów @dlt.expect_all_or_drop() do narzucania ograniczeń dotyczących jakości danych.
Na przykład wszystkie rekordy zakończone niepowodzeniem reguł oznaczonych validity zostaną usunięte z tabeli raw_farmers_market:
import dlt
from rules_module import *
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
return {
row['name']: row['constraint']
for row in get_rules_as_list_of_dict()
if row['tag'] == tag
}
@dlt.table
@dlt.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dlt.table
@dlt.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
dlt.read("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Sprawdzanie liczby wierszy
Poniższy przykład weryfikuje równość liczby wierszy między table_a i table_b, aby sprawdzić, czy żadne dane nie zostaną utracone podczas przekształceń:
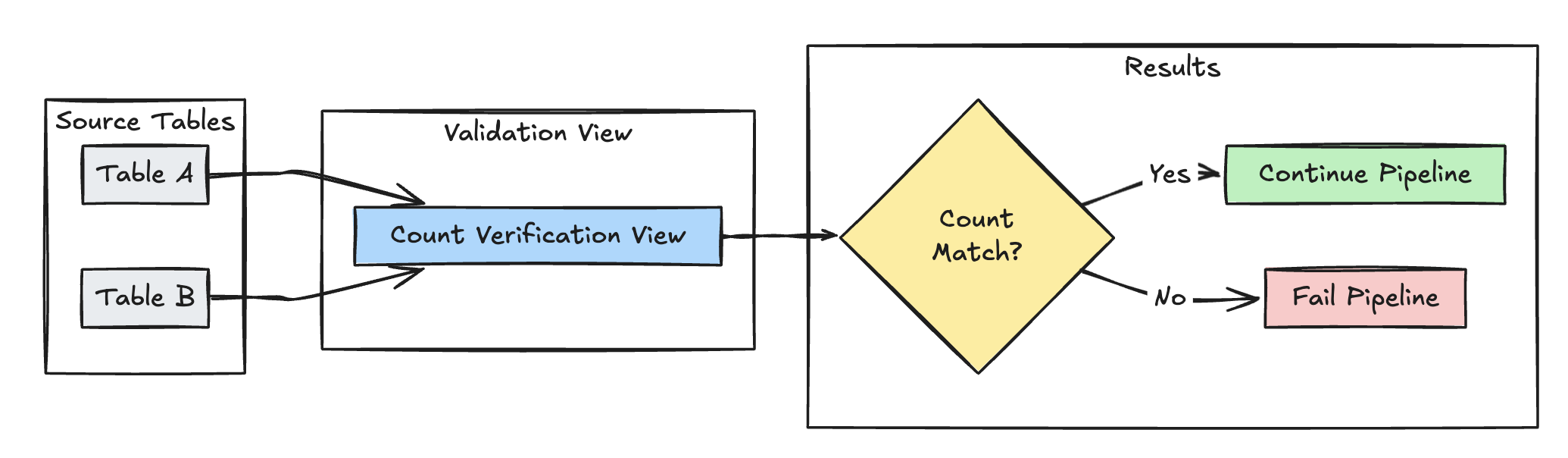
Pyton
@dlt.view(
name="count_verification",
comment="Validates equal row counts between tables"
)
@dlt.expect_or_fail("no_rows_dropped", "a_count == b_count")
def validate_row_counts():
return spark.sql("""
SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)""")
SQL
CREATE OR REFRESH MATERIALIZED VIEW count_verification(
CONSTRAINT no_rows_dropped EXPECT (a_count == b_count)
) AS SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)
wykrywanie brakujących rekordów
Poniższy przykład sprawdza, czy wszystkie oczekiwane rekordy znajdują się w tabeli report:
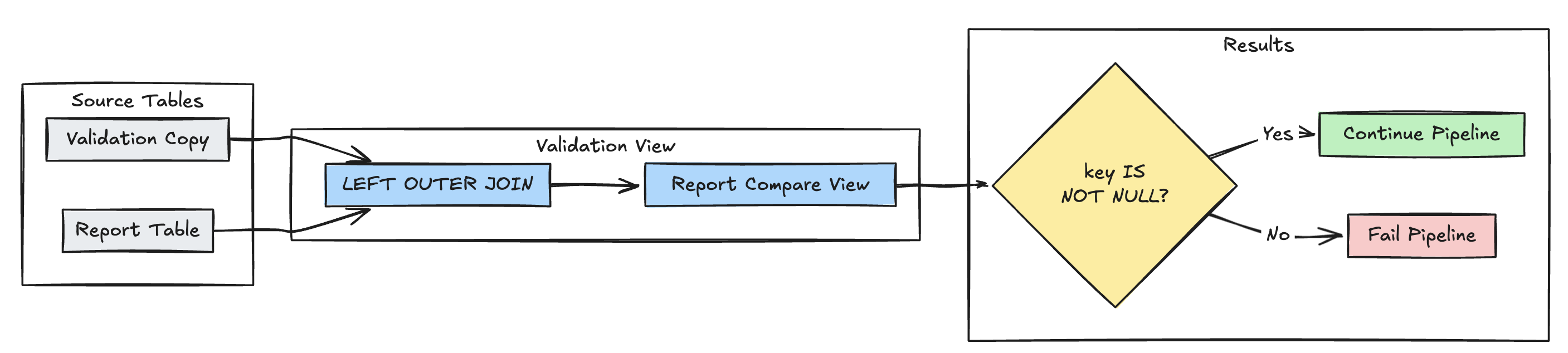
Pyton
@dlt.view(
name="report_compare_tests",
comment="Validates no records are missing after joining"
)
@dlt.expect_or_fail("no_missing_records", "r_key IS NOT NULL")
def validate_report_completeness():
return (
dlt.read("validation_copy").alias("v")
.join(
dlt.read("report").alias("r"),
on="key",
how="left_outer"
)
.select(
"v.*",
"r.key as r_key"
)
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_compare_tests(
CONSTRAINT no_missing_records EXPECT (r_key IS NOT NULL)
)
AS SELECT v.*, r.key as r_key FROM validation_copy v
LEFT OUTER JOIN report r ON v.key = r.key
unikatowość klucza podstawowego
Poniższy przykład weryfikuje ograniczenia klucza podstawowego w tabelach:
wykres dotyczący unikalności klucza głównego DLT 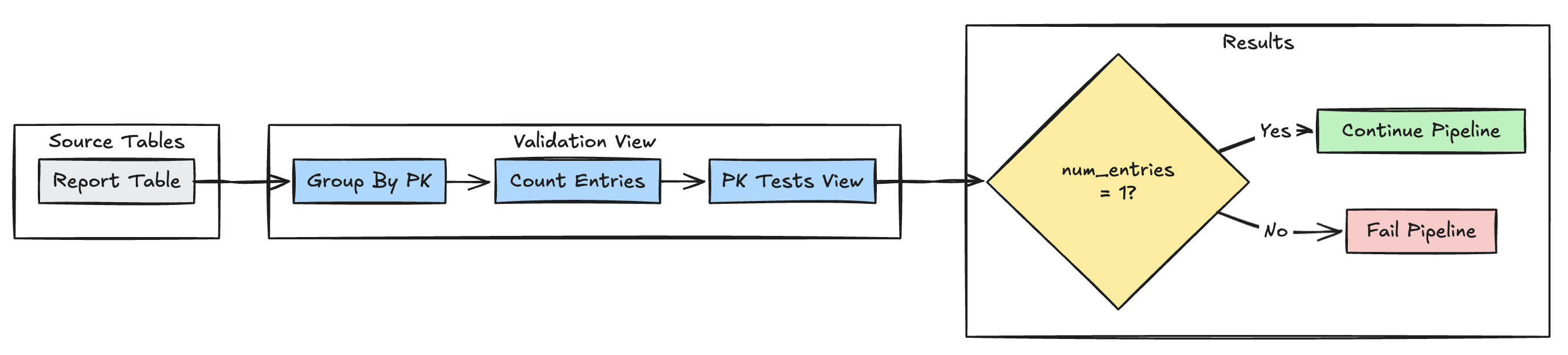
Pyton
@dlt.view(
name="report_pk_tests",
comment="Validates primary key uniqueness"
)
@dlt.expect_or_fail("unique_pk", "num_entries = 1")
def validate_pk_uniqueness():
return (
dlt.read("report")
.groupBy("pk")
.count()
.withColumnRenamed("count", "num_entries")
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_pk_tests(
CONSTRAINT unique_pk EXPECT (num_entries = 1)
)
AS SELECT pk, count(*) as num_entries
FROM report
GROUP BY pk
wzorzec ewolucji schematu
W poniższym przykładzie pokazano, jak obsługiwać ewolucję schematu dla dodatkowych kolumn. Użyj tego wzorca podczas migrowania źródeł danych lub obsługi wielu wersji danych nadrzędnych, zapewniając zgodność z poprzednimi wersjami podczas wymuszania jakości danych:
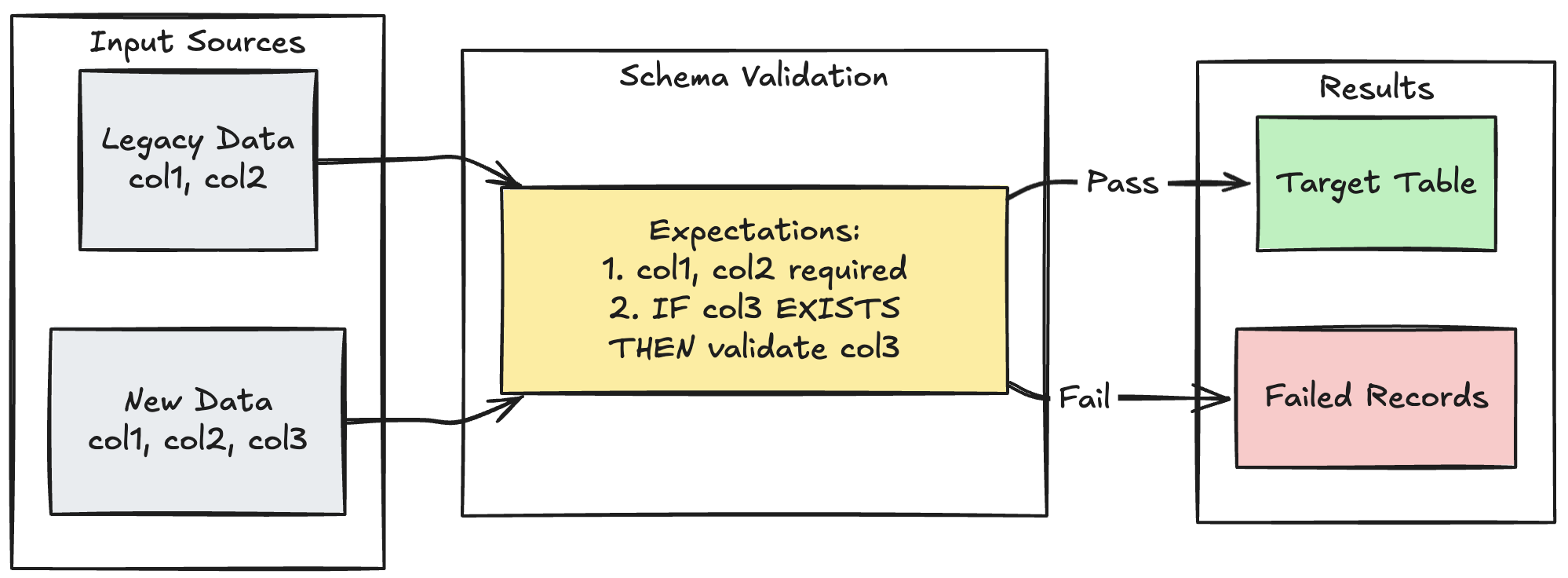
Pyton
@dlt.table
@dlt.expect_all_or_fail({
"required_columns": "col1 IS NOT NULL AND col2 IS NOT NULL",
"valid_col3": "CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END"
})
def evolving_table():
# Legacy data (V1 schema)
legacy_data = spark.read.table("legacy_source")
# New data (V2 schema)
new_data = spark.read.table("new_source")
# Combine both sources
return legacy_data.unionByName(new_data, allowMissingColumns=True)
SQL
CREATE OR REFRESH MATERIALIZED VIEW evolving_table(
-- Merging multiple constraints into one as expect_all is Python-specific API
CONSTRAINT valid_migrated_data EXPECT (
(col1 IS NOT NULL AND col2 IS NOT NULL) AND (CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END)
) ON VIOLATION FAIL UPDATE
) AS
SELECT * FROM new_source
UNION
SELECT *, NULL as col3 FROM legacy_source;
wzorzec weryfikacji oparty na zakresie
W poniższym przykładzie pokazano, jak weryfikować nowe punkty danych względem historycznych zakresów statystycznych, pomagając identyfikować wartości odstające i anomalie w przepływie danych:
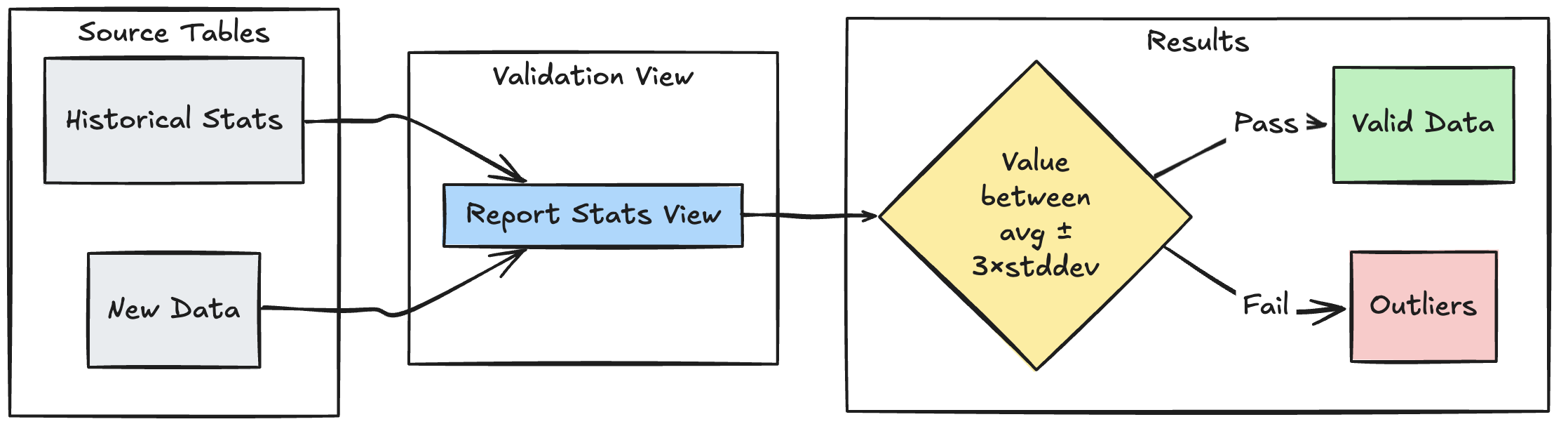
Pyton
@dlt.view
def stats_validation_view():
# Calculate statistical bounds from historical data
bounds = spark.sql("""
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE
date >= CURRENT_DATE() - INTERVAL 30 DAYS
""")
# Join with new data and apply bounds
return spark.read.table("new_data").crossJoin(bounds)
@dlt.table
@dlt.expect_or_drop(
"within_statistical_range",
"amount BETWEEN lower_bound AND upper_bound"
)
def validated_amounts():
return dlt.read("stats_validation_view")
SQL
CREATE OR REFRESH MATERIALIZED VIEW stats_validation_view AS
WITH bounds AS (
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE date >= CURRENT_DATE() - INTERVAL 30 DAYS
)
SELECT
new_data.*,
bounds.*
FROM new_data
CROSS JOIN bounds;
CREATE OR REFRESH MATERIALIZED VIEW validated_amounts (
CONSTRAINT within_statistical_range EXPECT (amount BETWEEN lower_bound AND upper_bound)
)
AS SELECT * FROM stats_validation_view;
Kwarantanna nieprawidłowych rekordów
Ten wzorzec łączy oczekiwania z tabelami tymczasowymi i widokami, aby śledzić metryki jakości danych podczas aktualizacji w potoku oraz umożliwiać oddzielne ścieżki przetwarzania dla prawidłowych i nieprawidłowych rekordów w dalszych operacjach.
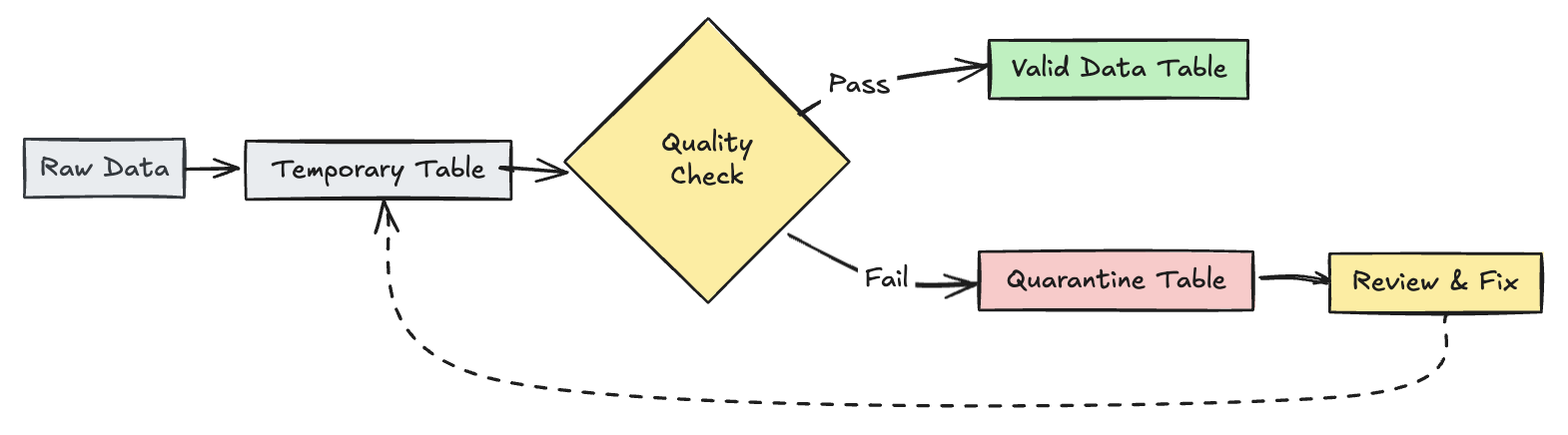
Pyton
import dlt
from pyspark.sql.functions import expr
rules = {
"valid_pickup_zip": "(pickup_zip IS NOT NULL)",
"valid_dropoff_zip": "(dropoff_zip IS NOT NULL)",
}
quarantine_rules = "NOT({0})".format(" AND ".join(rules.values()))
@dlt.view
def raw_trips_data():
return spark.readStream.table("samples.nyctaxi.trips")
@dlt.table(
temporary=True,
partition_cols=["is_quarantined"],
)
@dlt.expect_all(rules)
def trips_data_quarantine():
return (
dlt.readStream("raw_trips_data").withColumn("is_quarantined", expr(quarantine_rules))
)
@dlt.view
def valid_trips_data():
return dlt.read("trips_data_quarantine").filter("is_quarantined=false")
@dlt.view
def invalid_trips_data():
return dlt.read("trips_data_quarantine").filter("is_quarantined=true")
SQL
CREATE TEMPORARY STREAMING LIVE VIEW raw_trips_data AS
SELECT * FROM STREAM(samples.nyctaxi.trips);
CREATE OR REFRESH TEMPORARY STREAMING TABLE trips_data_quarantine(
-- Option 1 - merge all expectations to have a single name in the pipeline event log
CONSTRAINT quarantined_row EXPECT (pickup_zip IS NOT NULL OR dropoff_zip IS NOT NULL),
-- Option 2 - Keep the expectations separate, resulting in multiple entries under different names
CONSTRAINT invalid_pickup_zip EXPECT (pickup_zip IS NOT NULL),
CONSTRAINT invalid_dropoff_zip EXPECT (dropoff_zip IS NOT NULL)
)
PARTITIONED BY (is_quarantined)
AS
SELECT
*,
NOT ((pickup_zip IS NOT NULL) and (dropoff_zip IS NOT NULL)) as is_quarantined
FROM STREAM(raw_trips_data);
CREATE TEMPORARY LIVE VIEW valid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=FALSE;
CREATE TEMPORARY LIVE VIEW invalid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=TRUE;