Databricks Connect dla języka Python
Uwaga
W tym artykule opisano usługę Databricks Connect dla środowiska Databricks Runtime 13.3 LTS lub nowszego.
Databricks Connect umożliwia łączenie popularnych środowisk IDE, takich jak PyCharm, serwery notebooków i inne aplikacje niestandardowe z obliczeniami Azure Databricks. Zobacz Co to jest usługa Databricks Connect?.
W tym artykule pokazano, jak szybko rozpocząć pracę z programem Databricks Connect dla języka Python przy użyciu PyCharm.
- Aby zapoznać się z wersją języka R tego artykułu, zobacz Databricks Connect for R.
- Aby zapoznać się z wersją języka Scala tego artykułu, zobacz Databricks Connect for Scala.
Samouczek
W poniższym samouczku utworzysz projekt w narzędziu PyCharm, zainstaluj program Databricks Connect dla środowiska Databricks Runtime 13.3 LTS lub nowszego, a następnie uruchomisz prosty kod dotyczący obliczeń w obszarze roboczym usługi Databricks z poziomu rozwiązania PyCharm. Aby uzyskać dodatkowe informacje i przykłady, zobacz Następne kroki.
Wymagania
Aby ukończyć ten samouczek, musisz spełnić następujące wymagania:
- Docelowy obszar roboczy usługi Azure Databricks musi mieć włączony Unity Catalog.
- Masz zainstalowany pakiet PyCharm. Ten samouczek został przetestowany z wersją PyCharm Community Edition 2023.3.5. Jeśli używasz innej wersji lub wydania pakietu PyCharm, poniższe instrukcje mogą się różnić.
- Środowisko lokalne i obliczenia spełniają wymagania dotyczące wersji instalacji programu Databricks Connect dla języka Python .
- Jeśli używasz klasycznych obliczeń, będziesz potrzebować identyfikatora klastra. Aby uzyskać identyfikator klastra, w swoim obszarze roboczym kliknij pozycję Obliczenia na pasku bocznym, a następnie kliknij nazwę klastra. Na pasku adresu przeglądarki internetowej skopiuj ciąg znaków między
clustersiconfigurationw adresie URL.
Krok 1. Konfigurowanie uwierzytelniania usługi Azure Databricks
W tym samouczku używane jest uwierzytelnianie użytkownika do komputera usługi Azure Databricks OAuth (U2M) oraz profil konfiguracji usługi Azure Databricks do uwierzytelniania w obszarze roboczym usługi Azure Databricks. Aby użyć innego typu uwierzytelniania, zobacz Konfigurowanie właściwości połączenia.
Konfigurowanie uwierzytelniania OAuth U2M wymaga Databricks CLI. Aby uzyskać informacje na temat instalowania interfejsu wiersza polecenia usługi Databricks, zobacz Instalowanie lub aktualizowanie interfejsu wiersza polecenia usługi Databricks.
Zainicjuj uwierzytelnianie OAuth U2M w następujący sposób:
Użyj Databricks CLI, aby lokalnie zainicjować zarządzanie tokenami OAuth, uruchamiając następujące polecenie dla każdej docelowej przestrzeni roboczej.
W poniższym poleceniu zastąp
<workspace-url>adresem URL dotyczący usługi Azure Databricks przypisanym do konkretnego obszaru roboczego, na przykładhttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>Napiwek
Aby używać bezserwerowych obliczeń z usługą Databricks Connect, zobacz Konfigurowanie połączenia z bezserwerowymi obliczeniami.
Interfejs wiersza polecenia Databricks prosi o zapisanie wprowadzonych informacji jako profil konfiguracji Azure Databricks. Naciśnij
Enter, aby zaakceptować sugerowaną nazwę profilu lub wprowadź nazwę nowego lub istniejącego profilu. Każdy istniejący profil o tej samej nazwie zostanie zastąpiony wprowadzonymi informacjami. Profile umożliwiają szybkie przełączanie kontekstu uwierzytelniania między wieloma obszarami roboczymi.Aby uzyskać listę wszystkich istniejących profilów, w osobnym terminalu lub wierszu polecenia użyj interfejsu wiersza polecenia usługi Databricks, aby uruchomić polecenie
databricks auth profiles. Aby wyświetlić istniejące ustawienia określonego profilu, uruchom poleceniedatabricks auth env --profile <profile-name>.W przeglądarce internetowej wykonaj instrukcje na ekranie, aby zalogować się do obszaru roboczego usługi Azure Databricks.
Na liście dostępnych klastrów wyświetlanych w terminalu lub wierszu polecenia użyj strzałek w górę i w dół, aby wybrać docelowy klaster usługi Azure Databricks w obszarze roboczym, a następnie naciśnij
Enter. Możesz również wpisać dowolną część nazwy wyświetlanej klastra, aby filtrować listę dostępnych klastrów.Aby wyświetlić bieżącą wartość tokenu OAuth profilu i zbliżający się znacznik czasu wygaśnięcia tokenu, uruchom jedno z następujących poleceń:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Jeśli masz wiele profili z tą samą wartością
--host, może być konieczne określenie opcji--hosti-p, aby ułatwić CLI usługi Databricks znalezienie poprawnych informacji o pasującym tokenie OAuth.
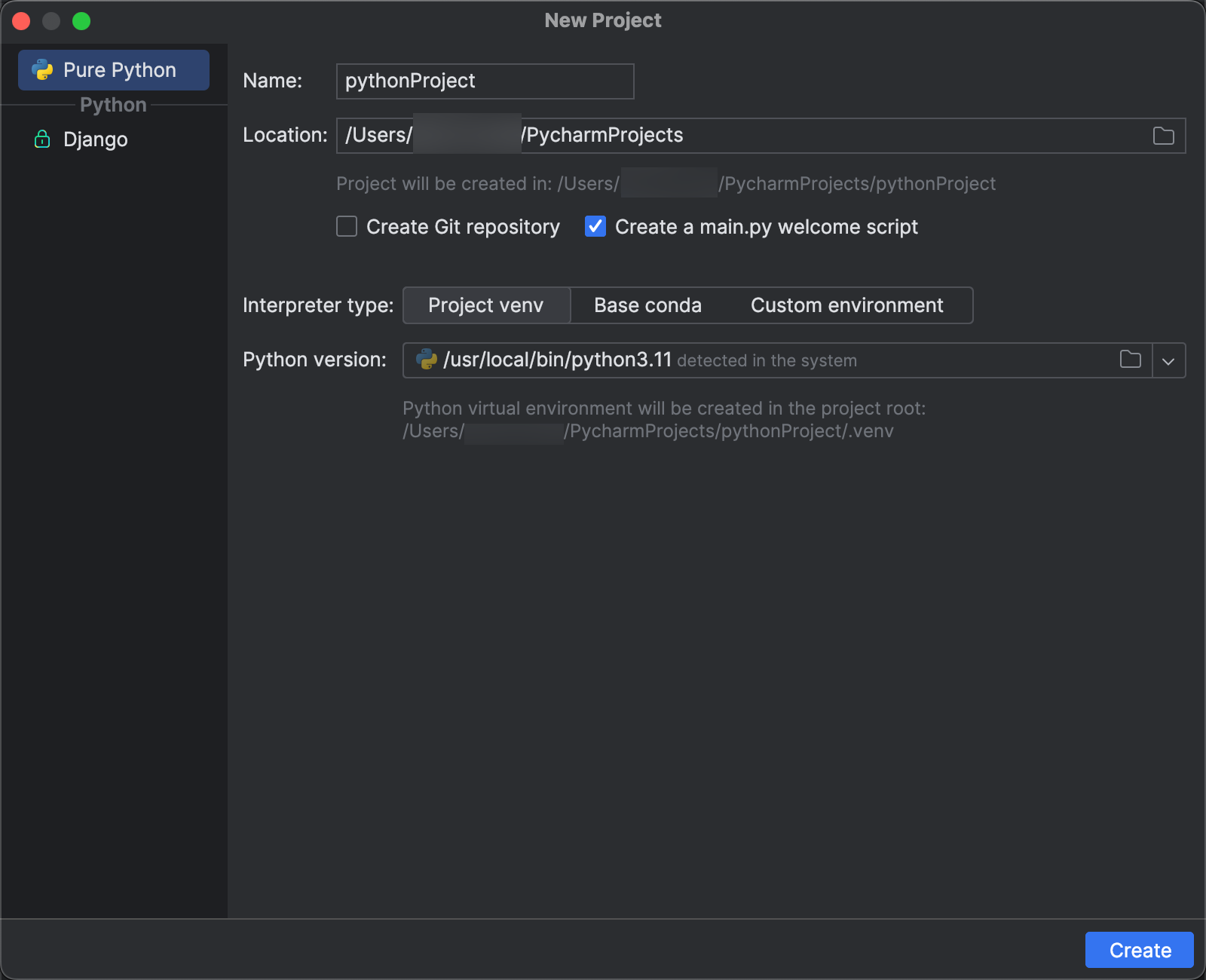
Krok 2. Tworzenie projektu
- Uruchom plik PyCharm.
- W menu głównym kliknij pozycję Plik > Nowy Projekt.
- W oknie dialogowym Nowy projekt kliknij pozycję Pure Python.
- W obszarze Lokalizacja kliknij ikonę folderu i ukończ wskazówki na ekranie, aby określić ścieżkę do nowego projektu języka Python.
- Pozostaw zaznaczoną opcję Utwórz skrypt powitalny main.py.
- W polu Typ interpretera kliknij pozycję Projekt venv.
- Rozwiń opcję Wersja Pythona i użyj ikony folderu lub listy rozwijanej, aby określić ścieżkę do interpretera Pythona z powyższych wymagań.
- Kliknij pozycję Utwórz.
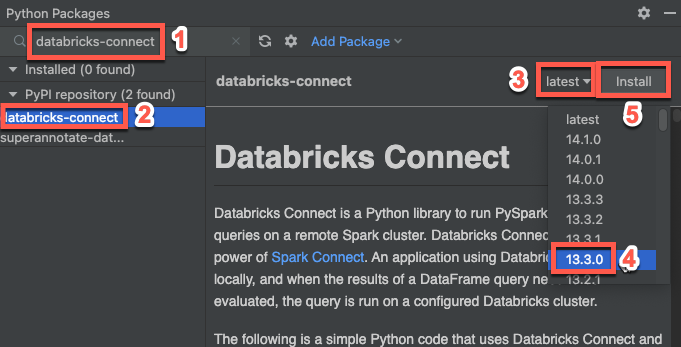
Krok 3. Dodawanie pakietu Databricks Connect
- W głównym menu PyCharm kliknij Widok > Okna narzędzi > Pakiety Python.
- W polu wyszukiwania wpisz
databricks-connect. - Na liście repozytorium PyPI kliknij pozycję databricks-connect.
- W najnowszej liście rozwijanej okienka wyników wybierz wersję, która odpowiada wersji środowiska Databricks Runtime Twojego klastra. Jeśli na przykład klaster ma zainstalowane środowisko Databricks Runtime 14.3, wybierz pozycję 14.3.1.
- Kliknij pozycję Zainstaluj pakiet.
- Po zainstalowaniu pakietu można zamknąć okno Pakiety języka Python.
Krok 4. Dodawanie kodu
W oknie narzędzia Project kliknij prawym przyciskiem myszy folder główny projektu, a następnie kliknij pozycję Nowy > plik języka Python.
Wprowadź
main.pyi kliknij dwukrotnie plik języka Python.Wprowadź następujący kod w pliku, a następnie zapisz plik w zależności od nazwy profilu konfiguracji.
Jeśli profil konfiguracji z kroku 1 nosi nazwę
DEFAULT, wprowadź następujący kod w pliku, a następnie zapisz plik:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)Jeśli profil konfiguracji z kroku 1 nie ma nazwy
DEFAULT, zamiast tego wprowadź następujący kod do pliku. Zastąp symbol zastępczy<profile-name>nazwą profilu konfiguracji z kroku 1, a następnie zapisz plik:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)
Krok 5. Uruchamianie kodu
- Uruchom klaster docelowy w zdalnym obszarze roboczym usługi Azure Databricks.
- Po uruchomieniu klastra w menu głównym kliknij opcję Uruchom > Uruchom polecenie "main".
- W oknie narzędziowym Uruchom (Widok > Okna narzędzi > Uruchom), w głównym okienku zakładki Uruchamianie, pojawi się pierwszych 5 wierszy
samples.nyctaxi.trips.
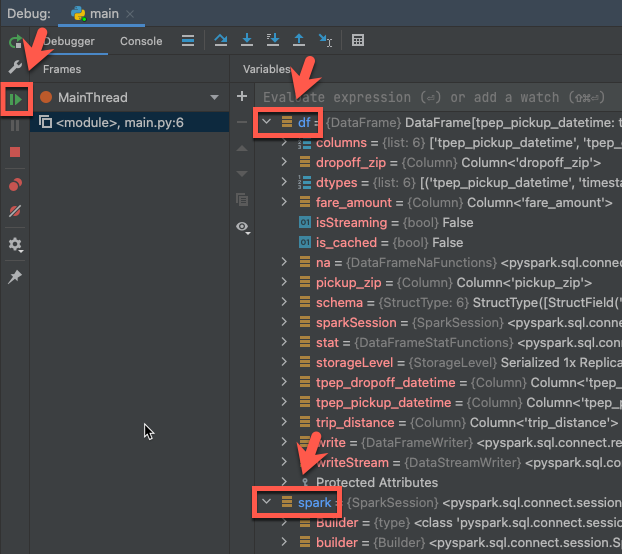
Krok 6. Debugowanie kodu
- Gdy klaster nadal działa, kliknij w marginesie obok
df.show(5), aby ustawić punkt przerwania. - W głównym menu kliknij Uruchom debugowanie "main".
- W oknie narzędzia Debug (Widok > Windows Narzędzi > Debug), na karcie Debugger w panelu Zmienne, rozwiń węzły zmiennych df i spark, aby przeglądać informacje o zmiennych w kodzie.
- Na pasku bocznym okna narzędzia debugowania kliknij ikonę zielonej strzałki (wznów program).
- W karcie Debugera w okienku Konsola pojawi się 5 pierwszych wierszy
samples.nyctaxi.trips.
Następne kroki
Aby dowiedzieć się więcej o programie Databricks Connect, zobacz artykuły, takie jak:
- Aby użyć innego typu uwierzytelniania, zobacz Konfigurowanie właściwości połączenia.
- Użyj usługi Databricks Connect z innymi środowiskami IDE, serwerami notatników i powłoką platformy Spark .
- Aby wyświetlić dodatkowe proste przykłady kodu, zobacz Przykłady kodu dla programu Databricks Connect dla języka Python.
- Aby wyświetlić bardziej złożone przykłady kodu, zobacz przykładowe aplikacje dla repozytorium Databricks Connect w usłudze GitHub, w szczególności:
- Aby użyć narzędzi usługi Databricks z usługą Databricks Connect, zobacz Databricks Utilities with Databricks Connect for Python (Narzędzia usługi Databricks Connect dla języka Python).
- Aby przeprowadzić migrację z usługi Databricks Connect dla środowiska Databricks Runtime 12.2 LTS i poniżej do usługi Databricks Connect dla środowiska Databricks Runtime 13.3 LTS lub nowszego, zobacz Migrowanie do usługi Databricks Connect dla języka Python.
- Zobacz również informacje o rozwiązywaniu problemów i ograniczeniach.