Przechwytywanie i wyświetlanie pochodzenia danych przy użyciu Unity Catalog
W tym artykule opisano sposób przechwytywania i wizualizowania pochodzenia danych przy użyciu Eksploratora wykazu, tabel systemu pochodzenia danych i interfejsu API REST.
Unity Catalog umożliwia przechwytywanie danych dotyczących ścieżki przetwarzania danych w ramach zapytań uruchamianych w usłudze Azure Databricks. Śledzenie danych jest obsługiwane dla wszystkich języków i jest zapisywane aż do poziomu kolumn. Dane pochodzenia obejmują notesy, zadania i pulpity nawigacyjne związane z zapytaniem. Linia pochodzenia można wizualizować w Eksploratorze Katalogu prawie w czasie rzeczywistym i pobierać programowo, używając systemowych tabel linii pochodzenia oraz interfejsu Databricks REST API.
Linia pochodzenia jest agregowana we wszystkich obszarach roboczych połączonych z magazynem metadanych Unity Catalog. Oznacza to, że pochodzenie zarejestrowane w jednym obszarze roboczym jest widoczne w dowolnym innym obszarze roboczym, który korzysta z tego samego magazynu metadanych. W szczególności tabele i inne obiekty danych zarejestrowane w magazynie metadanych są widoczne dla użytkowników, którzy mają co najmniej BROWSE uprawnienia do tych obiektów we wszystkich obszarach roboczych dołączonych do magazynu metadanych. Szczegółowe informacje o obiektach na poziomie obszaru roboczego, takich jak notesy i pulpity nawigacyjne w innych obszarach roboczych, są maskowane (zobacz Ograniczenia i uprawnienia dotyczące pochodzenia danych).
Dane rodowodowe są przechowywane przez jeden rok.
Na poniższej ilustracji przedstawiono przykładowy wykres pochodzenia. Konkretne funkcje pochodzenia danych i przykłady zostały omówione w dalszej części tego artykułu.
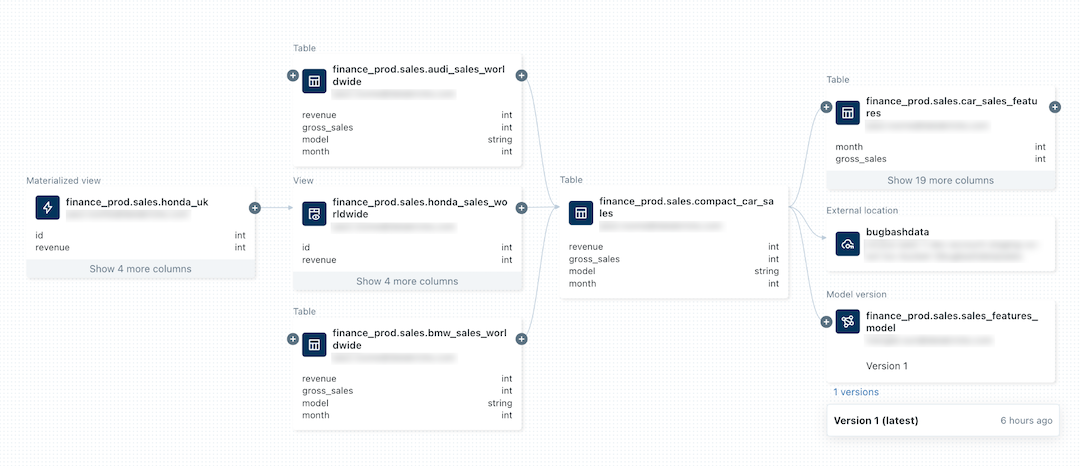
Aby uzyskać informacje na temat śledzenia rodowodu modelu uczenia maszynowego, zobacz Śledzenie rodowodu danych modelu w Unity Catalog.
Wymagania
Do śledzenia rodowodu danych przy użyciu Unity Catalog wymagane są następujące elementy:
- Obszar roboczy musi mieć włączony Katalog Unity.
- Tabele muszą być zarejestrowane w metastore Unity Catalog.
- Zapytania muszą używać DataFrame Spark (na przykład funkcji Spark SQL, które zwracają DataFrame) lub interfejsów Databricks SQL. Przykłady zapytań SQL i PySpark w usłudze Databricks znajdziesz w sekcji Przykłady.
- Aby wyświetlić pochodzenie tabeli lub widoku, użytkownicy muszą mieć co najmniej
BROWSEuprawnienia do katalogu nadrzędnego tabeli lub widoku. Katalog nadrzędny musi być również dostępny z wnętrza obszaru roboczego. Zobacz Ograniczanie dostępu katalogu do określonych obszarów roboczych. - Aby wyświetlić informacje o pochodzeniu notesów, zadań lub pulpitów nawigacyjnych, użytkownicy muszą mieć uprawnienia do tych obiektów zgodnie z ustawieniami kontroli dostępu w obszarze roboczym. Zobacz Uprawnienia linii danych.
- Aby podglądać pochodzenie potoku powiązanego z Unity Catalog , musisz mieć uprawnienia
CAN_VIEWdo potoku. - Śledzenie pochodzenia danych przesyłanych strumieniowo między tabelami Delta wymaga środowiska Databricks Runtime 11.3 LTS lub nowszego.
- Śledzenie pochodzenia kolumn dla obciążeń DLT wymaga środowiska Databricks Runtime 13.3 LTS lub nowszego.
- Może być konieczne zaktualizowanie reguł zapory ruchu wychodzącego, aby umożliwić łączność z punktem końcowym usługi Event Hubs na płaszczyźnie sterowania usługi Azure Databricks. Zwykle ma to zastosowanie, jeśli obszar roboczy usługi Azure Databricks jest wdrażany we własnej sieci wirtualnej (nazywanej również iniekcją sieci wirtualnej). Aby uzyskać adres IP punktu końcowego Event Hubs dla regionu obszaru roboczego, zobacz Magazyn metadanych, magazyn obiektów blob artefaktów, magazyn tabel systemowych, magazyn obiektów blob dzienników i adresy IP punktów końcowych Event Hubs. Aby uzyskać informacje na temat konfigurowania tras zdefiniowanych przez użytkownika (UDR) dla usługi Azure Databricks, zobacz Ustawienia trasy zdefiniowanej przez użytkownika dla usługi Azure Databricks.
Przykłady
Uwaga
W poniższych przykładach użyto nazwy katalogu
lineage_datai nazwy schematulineagedemo. Aby użyć innego wykazu i schematu, zmień nazwy używane w przykładach.Aby ukończyć ten przykład, musisz mieć uprawnienia
CREATEiUSE SCHEMAw schemacie. Administrator magazynu metadanych, właściciel wykazu, właściciel schematu lub użytkownik z uprawnieniamiMANAGEw schemacie może przyznać te uprawnienia. Aby na przykład przyznać wszystkim użytkownikom w grupie uprawnienie "data_engineers" do tworzenia tabel w schemacielineagedemow katalogulineage_data, użytkownik z jednym z powyższych uprawnień lub ról może uruchamiać następujące zapytania:CREATE SCHEMA lineage_data.lineagedemo; GRANT USE SCHEMA, CREATE on SCHEMA lineage_data.lineagedemo to `data_engineers`;
Uchwycenie i eksplorowanie pochodzenia
Aby przechwycić dane pochodzenia:
Przejdź do strony docelowej usługi Azure Databricks, kliknij pozycję
 Nowy na pasku bocznym, a następnie wybierz pozycję Notatnik z menu.
Nowy na pasku bocznym, a następnie wybierz pozycję Notatnik z menu.Wprowadź nazwę notesu i wybierz SQL w Język domyślny.
W Clusterwybierz klaster z dostępem do katalogu Unity.
Kliknij pozycję Utwórz.
W pierwszej komórce notesu wprowadź następujące zapytania:
CREATE TABLE IF NOT EXISTS lineage_data.lineagedemo.menu ( recipe_id INT, app string, main string, dessert string ); INSERT INTO lineage_data.lineagedemo.menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); CREATE TABLE lineage_data.lineagedemo.dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM lineage_data.lineagedemo.menuAby uruchomić zapytania, kliknij komórkę i naciśnij shift+enter lub kliknij
 i wybierz pozycję Uruchom komórkę.
i wybierz pozycję Uruchom komórkę.
Aby wyświetlić pochodzenie wygenerowane przez te zapytania za pomocą Eksploratora wykazu:
W polu Wyszukaj na górnym pasku obszaru roboczego usługi Azure Databricks wyszukaj tabelę
lineage_data.lineagedemo.dinneri wybierz ją.Wybierz kartę pochodzenia. Panel pochodzenia zostanie wyświetlony i będzie pokazywać powiązane tabele (w tym przypadku jest to tabela
menu).Aby wyświetlić interaktywny wykres pochodzenia danych, kliknij pozycję Zobacz wykres pochodzenia danych. Domyślnie jeden poziom jest wyświetlany na grafie. Kliknij ikonę znaku plusa
 na węźle, aby wyświetlić więcej połączeń, jeśli są dostępne.
na węźle, aby wyświetlić więcej połączeń, jeśli są dostępne.Kliknij strzałkę łączącą węzły na wykresie rodowodowym, aby otworzyć panel połączenia rodowodowego. Panel połączenia Lineage pokazuje szczegóły dotyczące połączenia, w tym tabele źródłowe i docelowe, notesy i zadania.
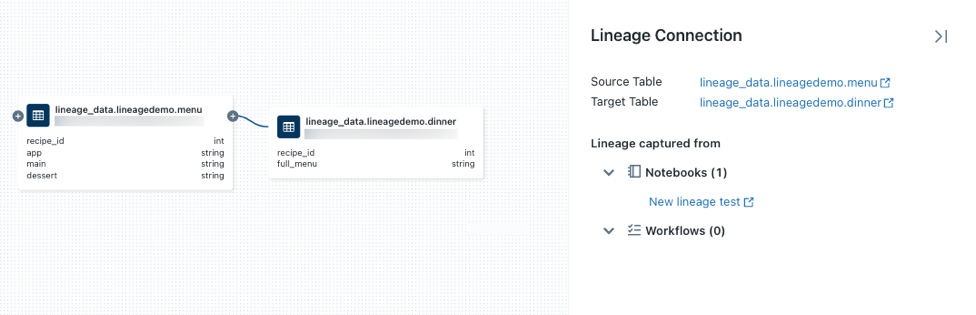
Aby wyświetlić notes skojarzony z tabelą
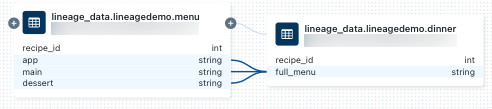
dinner, wybierz notes w panelu połączenia linii połączeń lub zamknij wykres linii połączeń, a następnie kliknij Notesy. Aby otworzyć notes na nowej karcie, kliknij nazwę notesu.Aby wyświetlić pochodzenie na poziomie kolumny, kliknij kolumnę na wykresie, aby wyświetlić łącza do powiązanych kolumn. Na przykład kliknięcie kolumny "full_menu" spowoduje wyświetlenie kolumn nadrzędnych, z których pochodzi kolumna:
Aby wyświetlić pochodzenie przy użyciu innego języka, na przykład Python:
Otwórz utworzony wcześniej notes, utwórz nową komórkę i wprowadź następujący kod w języku Python:
%python from pyspark.sql.functions import rand, round df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") df.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.price") dinner = spark.read.table("lineage_data.lineagedemo.dinner") price = spark.read.table("lineage_data.lineagedemo.price") dinner_price = dinner.join(price, on="recipe_id") dinner_price.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.dinner_price")Uruchom komórkę, klikając komórkę i naciskając shift+enter lub klikając
i wybierając pozycję Uruchom komórkę.W polu Wyszukaj na górnym pasku obszaru roboczego usługi Azure Databricks wyszukaj tabelę
lineage_data.lineagedemo.pricei wybierz ją.Przejdź do karty pochodzenie i kliknij Zobacz wykres pochodzenia. Kliknij
, aby eksplorować pochodzenie danych wygenerowane przez zapytania.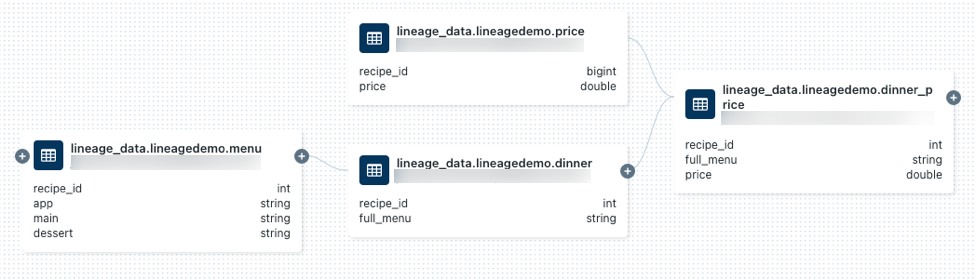
Kliknij strzałkę, która łączy węzły na wykresie pochodzenia, żeby otworzyć panel połączenia linii. Panel połączenia Lineage pokazuje szczegółowe informacje o połączeniu, w tym tabele źródłowe i docelowe, notesy i zadania.
Przechwytywanie i wyświetlanie linii przepływu pracy
Linia pochodzenia jest również przechwytywana dla dowolnego przepływu pracy, który odczytuje lub zapisuje w Unity Catalog. Aby wyświetlić powiązania dla przepływu pracy usługi Azure Databricks:
Kliknij
na pasku bocznym i wybierz Notatnik z menu.Wprowadź nazwę notesu i wybierz SQL w Język domyślny.
Kliknij pozycję Utwórz.
W pierwszej komórce notesu wprowadź następujące zapytanie:
SELECT * FROM lineage_data.lineagedemo.menuKliknij pozycję Harmonogram na górnym pasku. W oknie dialogowym harmonogramu wybierz opcję Ręczne, wybierz klaster z dostępem do Unity Catalog, a następnie kliknij Utwórz.
Kliknij przycisk Uruchom teraz.
W polu Wyszukaj na górnym pasku obszaru roboczego usługi Azure Databricks wyszukaj tabelę
lineage_data.lineagedemo.menui wybierz ją.Na karcie Lineage kliknij Workflows i wybierz kartę Downstream. Nazwa zadania pojawi się pod Job Name jako konsument tabeli
menu.
Przechwytywanie i wyświetlanie pochodzenia pulpitu nawigacyjnego
Aby utworzyć pulpit nawigacyjny i wyświetlić jego linię danych:
Przejdź do strony docelowej usługi Azure Databricks i otwórz Eksploratora wykazu, klikając pozycję Catalog na pasku bocznym.
Kliknij nazwę katalogu, kliknij lineagedemo, a następnie wybierz tabelę
menu. Możesz również użyć pola wyszukiwania na górnym pasku, aby znaleźć tabelęmenu.Kliknij pozycję Otwórz na pulpicie nawigacyjnym.
Wybierz kolumny, które chcesz dodać do pulpitu nawigacyjnego, a następnie kliknij pozycję Utwórz.
Opublikuj pulpit nawigacyjny.
Tylko opublikowane dashboardy są śledzone w pochodzeniu danych.
W polu Wyszukaj na górnym pasku wyszukaj tabelę
lineage_data.lineagedemo.menui wybierz ją.Na karcie Pochodzenie kliknij pozycję Pulpity nawigacyjne. Pulpit nawigacyjny jest wyświetlany w obszarze nazwa pulpitu nawigacyjnego jako użytkownik tabeli menu.
Uprawnienia dziedziczenia
Grafy pochodzenia dzielą ten sam model uprawnień co Unity Catalog. Tabele i inne obiekty danych zarejestrowane w metaskładzie Katalogu Unity są widoczne tylko dla użytkowników, którzy mają co najmniej uprawnienia BROWSE do tych obiektów. Jeśli użytkownik nie ma uprawnień BROWSE lub SELECT w tabeli, nie może eksplorować jej linii pochodzenia. Wykresy pochodzenia wyświetlają obiekty z Unity Catalog we wszystkich obszarach roboczych dołączonych do magazynu metadanych, pod warunkiem że użytkownik ma odpowiednie uprawnienia do tych obiektów.
Na przykład uruchom następujące polecenia dla userA:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
Gdy userA wyświetli wykres pochodzenia dla tabeli lineage_data.lineagedemo.menu, zobaczy tabelę menu. Nie będą oni mogli wyświetlić informacji o skojarzonych tabelach, takich jak podrzędna tabela lineage_data.lineagedemo.dinner. Tabela dinner jest wyświetlana jako węzeł masked na ekranie skierowanym do userA, a userA nie może rozwinąć wykresu, aby pokazać powiązane tabele, z których nie mają uprawnień do odczytu.
Jeśli uruchomisz następujące polecenie, aby udzielić BROWSE uprawnienia do userB, ten użytkownik będzie mógł wyświetlić graf relacji dla dowolnej tabeli w schemacie lineage_data.
GRANT BROWSE on lineage_data to `userB@company.com`;
Podobnie, użytkownicy muszą mieć określone uprawnienia do wyświetlania obiektów obszaru roboczego, takich jak notesy, zadania i pulpity. Ponadto mogą wyświetlać szczegółowe informacje o obiektach obszaru roboczego tylko po zalogowaniu się do obszaru roboczego, w którym te obiekty zostały utworzone. Szczegółowe informacje o obiektach na poziomie przestrzeni roboczej w innych obszarach roboczych są maskowane na diagramie zależności.
Aby uzyskać więcej informacji na temat zarządzania dostępem do zabezpieczanych obiektów w Unity Catalog, zobacz Zarządzanie uprawnieniami w Unity Catalog. Aby uzyskać więcej informacji na temat zarządzania dostępem do obiektów obszaru roboczego, takich jak notesy, zadania i pulpity nawigacyjne, zobacz Listy kontroli dostępu.
Usuwanie danych pochodzenia
Ostrzeżenie
Poniższe instrukcje usuwają wszystkie obiekty przechowywane w Unity Catalog. Skorzystaj z tych instrukcji tylko w razie potrzeby. Na przykład, aby spełnić wymagania dotyczące zgodności.
Aby usunąć dane genealogiczne, należy usunąć repozytorium metadanych zarządzające obiektami Unity Catalog. Aby uzyskać więcej informacji na temat usuwania magazynu metadanych, zobacz Usuwanie magazynu metadanych. Dane zostaną usunięte w ciągu 90 dni.
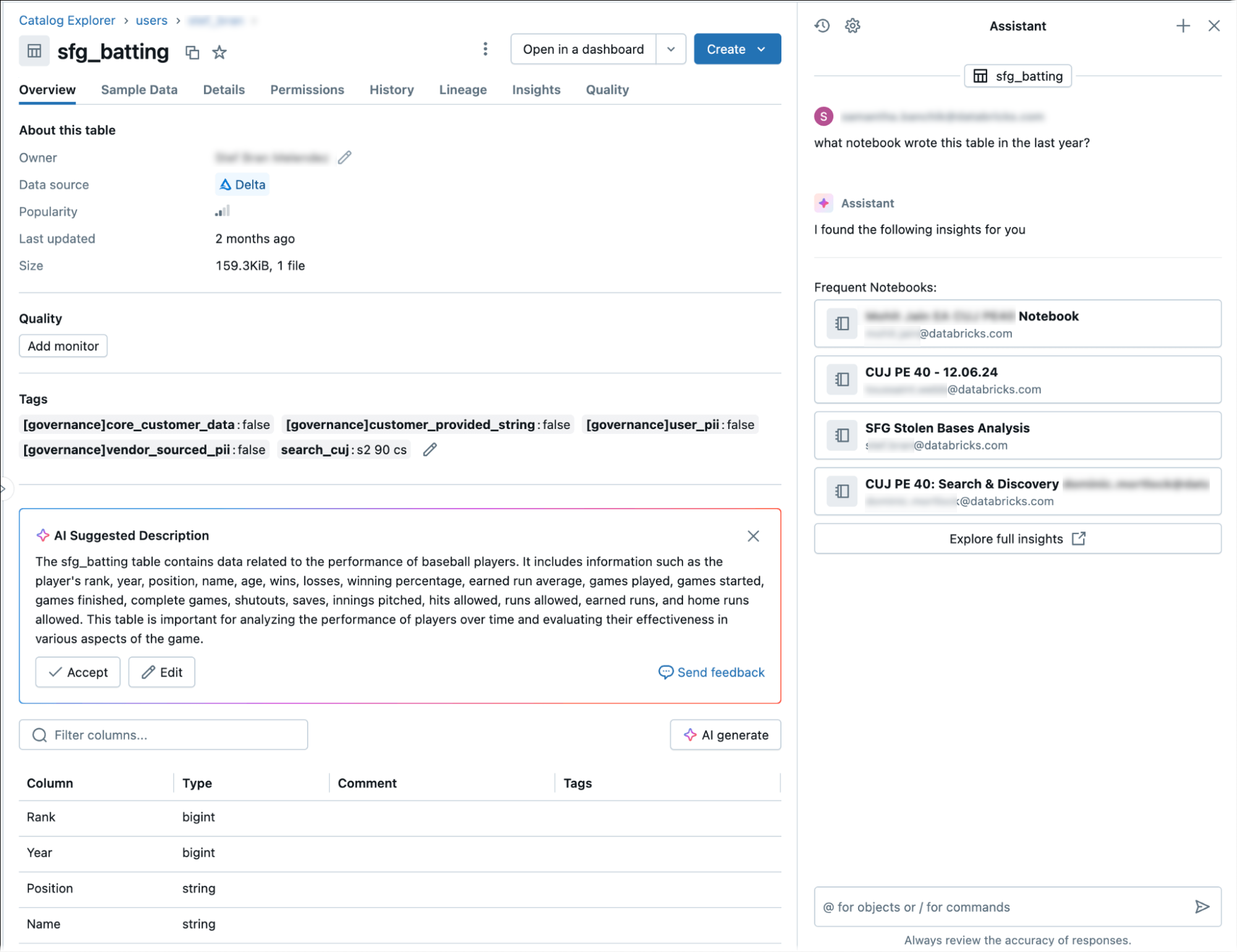
Uzyskiwanie linii pochodzenia tabel przy użyciu Asystenta Databricks
Asystent usługi Databricks udostępnia szczegółowe informacje na temat pochodzenia tabel i analizy.
Aby uzyskać informacje o pochodzeniu przy użyciu Asystenta:
- Przejdź do strony głównej Azure Databricks i otwórz Eksploratora katalogu, klikając ikonę
 na pasku bocznym.
na pasku bocznym. - Kliknij nazwę katalogu, a następnie kliknij ikonę asystenta pomocy w produkcie
 w prawym górnym rogu.
w prawym górnym rogu. - W oknie Asystenta wpisz:
- /getTableLineages, aby wyświetlić zależności nadrzędne i podrzędne.
- /getTableInsights w celu uzyskania dostępu do szczegółowych informacji opartych na metadanych, takich jak aktywność użytkownika i wzorce zapytań.
Te zapytania umożliwiają Asystentowi odpowiadanie na pytania, takie jak "pokaż mi podrzędne pochodzenie" lub "kto najczęściej wykonuje zapytania dotyczące tej tabeli".
Wykonywanie zapytań dotyczących danych pochodzenia przy użyciu tabel systemowych
Tabele systemowe pochodzenia umożliwiają programowe wykonywanie zapytań dotyczących danych pochodzenia. Aby uzyskać szczegółowe instrukcje, zobacz Monitorowanie aktywności konta za pomocą tabel systemowych oraz Systemowe tabele lineage.
Jeśli obszar roboczy znajduje się w regionie, który nie obsługuje tabel systemowych śledzenia, możesz też programistycznie pobrać dane śledzenia za pomocą interfejsu API REST do śledzenia danych.
Pobieranie pochodzenia przy użyciu interfejsu API REST pochodzenia danych
Interfejs API pochodzenia danych umożliwia pobieranie pochodzenia tabel i kolumn. Jeśli jednak obszar roboczy znajduje się w regionie obsługującym tabele systemowe dziedziczenia, należy użyć zapytań w tabelach systemowych zamiast interfejsu API REST. Tabele systemowe to lepsza opcja programowego pobierania danych pochodzenia. Większość regionów obsługuje tabele systemowe pochodzenia.
Ważne
Aby uzyskać dostęp do interfejsów API REST Databricks, należy uwierzytelnić się.
Pobieranie pochodzenia tabeli
W tym przykładzie są pobierane dane pochodzenia dla tabeli dinner.
Żądanie
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
Zastąp element <workspace-instance>.
W tym przykładzie jest używany plik .netrc .
Odpowiedź
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
Pobierz pochodzenie kolumn
W tym przykładzie są pobierane dane kolumn dla tabeli dinner.
Żądanie
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
Zastąp element <workspace-instance>.
W tym przykładzie jest używany plik .netrc .
Odpowiedź
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
Ograniczenia
Mimo że pochodzenie danych jest agregowane dla wszystkich obszarów roboczych dołączonych do tego samego repozytorium Unity Catalog, szczegóły obiektów obszarów roboczych, takich jak notatniki i pulpity nawigacyjne, są widoczne tylko w obszarze roboczym, w którym zostały utworzone.
Ponieważ pochodzenie jest obliczane w rocznym oknie przesuwnym, dane pochodzenia zebrane ponad rok temu nie są wyświetlane. Jeśli na przykład zadanie lub zapytanie odczytuje dane z tabeli A i zapisuje w tabeli B, połączenie między tabelą A a tabelą B jest wyświetlane tylko przez jeden rok. Dane pochodzenia można filtrować według przedziału czasu w oknie jednego roku.
Zadania korzystające z żądania API Jobs
runs submitsą niedostępne podczas wyświetlania pochodzenia. Pochodzenie danych na poziomie tabeli i kolumny jest nadal przechwytywane podczas korzystania z żądaniaruns submit, ale powiązanie z przebiegiem nie jest przechwytywane.Unity Catalog przechwytuje pochodzenie na poziomie kolumny, w miarę możliwości. Jednak w niektórych przypadkach nie można przechwycić pochodzenia na poziomie kolumny.
Pochodzenie kolumn jest obsługiwane tylko wtedy, gdy zarówno źródło, jak i cel są przywoływane według nazwy tabeli (Przykład:
select * from <catalog>.<schema>.<table>). Nie można uchwycić pochodzenia kolumn, jeśli źródło lub obiekt docelowy jest adresowany za pomocą ścieżki (przykład:select * from delta."s3://<bucket>/<path>").Jeśli nazwa tabeli lub widoku zostanie zmieniona, pochodzenie nie zostanie przechwycone dla zmienionej tabeli lub widoku.
Jeśli zmieniono nazwę schematu lub wykazu, pochodzenie nie jest przechwytywane dla tabel i widoków w zmienionym wykazie lub schemacie.
Jeśli używasz punktów kontrolnych zestawu danych Spark SQL, pochodzenie nie jest przechwytywane.
Katalog Unity przechwytuje ścieżki pochodzenia w potokach DLT w większości przypadków. Jednak w niektórych przypadkach nie można zagwarantować całkowitego pokrycia procesu przepływu danych, na przykład gdy potoki używają zastosuj zmiany API lub tabel tymczasowych.
Pochodzenie nie przechwytuje funkcji stacka.
Globalne widoki tymczasowe nie są przechwytywane w rodowodzie.
Tabele w
system.information_schemanie są uwzględniane w śledzeniu pochodzenia.Pełna ścieżka danych na poziomie kolumny nie jest domyślnie przechwytywana dla operacji
MERGE.Możesz włączyć przechwytywanie pochodzenia dla
MERGEoperacji, ustawiając właściwość Sparkspark.databricks.dataLineage.mergeIntoV2Enablednatrue. Włączenie tej flagi może spowolnić wydajność zapytań, szczególnie w obciążeniach obejmujących bardzo szerokie tabele.