Uruchamianie projektów MLflow w usłudze Azure Databricks
Notatka
Projekty MLflow nie są już obsługiwane.
Ta dokumentacja została wycofana i może nie zostać zaktualizowana. Produkty, usługi lub technologie wymienione w tej zawartości nie są już obsługiwane.
projekt
W tym artykule opisano format projektu MLflow oraz sposób zdalnego uruchamiania projektu MLflow w klastrach usługi Azure Databricks przy użyciu interfejsu wiersza polecenia platformy MLflow, co ułatwia skalowanie w pionie kodu nauki o danych.
Format projektu MLflow
Każdy katalog lokalny lub repozytorium Git może być traktowany jako projekt MLflow. Następujące konwencje definiują projekt:
- Nazwa projektu to nazwa katalogu.
- Środowisko oprogramowania jest określone w
python_env.yaml, jeśli istnieje. Jeśli plikpython_env.yamlnie istnieje, platforma MLflow używa środowiska wirtualnego zawierającego tylko język Python (w szczególności najnowszy język Python dostępny dla środowiska virtualenv) podczas uruchamiania projektu. - Każdy plik
.pylub.shw projekcie może być punktem wejścia bez jawnie zadeklarowanych parametrów. Po uruchomieniu takiego polecenia z zestawem parametrów, MLflow przekazuje każdy parametr jako argument wiersza poleceń, używając składni--key <value>.
Możesz określić więcej opcji, dodając plik MLproject, który jest plikiem tekstowym w składni YAML. Przykładowy plik MLproject wygląda następująco:
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
W przypadku środowisk Databricks Runtime 13.0 ML i nowszych nie można skutecznie uruchomić projektów MLflow w klastrze zadaniowym Databricks. Aby przeprowadzić migrację istniejących projektów MLflow do środowiska Databricks Runtime 13.0 ML lub nowszego, zobacz format projektu MLflow Databricks Spark dla zadań .
format projektu zadania platformy Spark MLflow Databricks Spark
Projekt MLflow Databricks Spark dla zadań jest typem projektu MLflow wprowadzonego w wersji MLflow 2.14. Ten typ projektu obsługuje uruchamianie projektów MLflow z poziomu klastra zadań Platformy Spark i można go uruchamiać tylko przy użyciu zaplecza databricks.
Projekty zadań Spark na platformie Databricks muszą ustawiać databricks_spark_job.python_file lub entry_points. Nie określenie żadnego albo obu ustawień powoduje zgłoszenie wyjątku.
Poniżej przedstawiono przykład pliku MLproject, który używa ustawienia databricks_spark_job.python_file. To ustawienie obejmuje użycie zakodowanej na stałe ścieżki dla pliku uruchomieniowego języka Python i jego argumentów.
name: My Databricks Spark job project 1
databricks_spark_job:
python_file: "train.py" # the file which is the entry point file to execute
parameters: ["param1", "param2"] # a list of parameter strings
python_libraries: # dependencies required by this project
- mlflow==2.4.1 # MLflow dependency is required
- scikit-learn
Poniżej przedstawiono przykład pliku MLproject, który używa ustawienia entry_points:
name: My Databricks Spark job project 2
databricks_spark_job:
python_libraries: # dependencies to be installed as databricks cluster libraries
- mlflow==2.4.1
- scikit-learn
entry_points:
main:
parameters:
model_name: {type: string, default: model}
script_name: {type: string, default: train.py}
command: "python {script_name} {model_name}"
Ustawienie entry_points umożliwia przekazywanie parametrów używających parametrów wiersza polecenia, takich jak:
mlflow run . -b databricks --backend-config cluster-spec.json \
-P script_name=train.py -P model_name=model123 \
--experiment-id <experiment-id>
Następujące ograniczenia dotyczą projektów zadań usługi Databricks Spark:
- Ten typ projektu nie obsługuje określania następujących sekcji w pliku
MLproject:docker_env,python_envlubconda_env. - Zależności projektu muszą być określone w polu
python_librariessekcjidatabricks_spark_job. Nie można dostosować wersji języka Python przy użyciu tego typu projektu. - Środowisko uruchomieniowe musi używać głównego środowiska uruchomieniowego sterownika Spark, aby działać w klastrach zadań, które korzystają z środowiska Databricks Runtime 13.0 lub nowszego.
- Podobnie wszystkie zależności języka Python zdefiniowane zgodnie z wymaganiami projektu muszą być zainstalowane jako zależności klastra usługi Databricks. To zachowanie różni się od poprzednich zachowań uruchamiania projektu, w których biblioteki muszą być zainstalowane w osobnym środowisku.
Uruchamianie projektu MLflow
Aby uruchomić projekt MLflow w klastrze usługi Azure Databricks w domyślnym obszarze roboczym, użyj polecenia :
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
gdzie <uri> jest identyfikatorem URI repozytorium Git lub folderem, który zawiera projekt MLflow, a <json-new-cluster-spec> to dokument JSON zawierający strukturę new_cluster. Identyfikator URI usługi Git powinien mieć postać: https://github.com/<repo>#<project-folder>.
Przykładowa specyfikacja klastra to:
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
}
Jeśli musisz zainstalować biblioteki na workerze, użyj formatu "specyfikacja klastra". Należy pamiętać, że pliki wheel języka Python muszą zostać przesłane do DBFS i określone jako zależności pypi. Na przykład:
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
Ważny
- zależności
.eggi.jarnie są obsługiwane w przypadku projektów MLflow. - Wykonywanie projektów MLflow ze środowiskami platformy Docker nie jest obsługiwane.
- Podczas uruchamiania projektu MLflow w usłudze Databricks należy użyć nowej specyfikacji klastra. Uruchamianie projektów w istniejących klastrach nie jest obsługiwane.
Korzystanie z platformy SparkR
Aby użyć SparkR, uruchamiając projekt MLflow, kod projektu musi najpierw zainstalować i zaimportować SparkR w następujący sposób:
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
Projekt może następnie zainicjować sesję SparkR i używać SparkR w zwykły sposób.
sparkR.session()
...
przykład
W tym przykładzie pokazano, jak utworzyć eksperyment, uruchomić projekt samouczka MLflow w klastrze usługi Azure Databricks, wyświetlić wynik uruchomienia zadania i przejrzeć przebieg w eksperymencie.
Wymagania
- Zainstaluj MLflow przy użyciu
pip install mlflow. - Zainstaluj i skonfiguruj Databricks CLI. Mechanizm uwierzytelniania interfejsu wiersza polecenia usługi Databricks jest wymagany do uruchamiania zadań w klastrze usługi Azure Databricks.
Krok 1. Tworzenie eksperymentu
W obszarze roboczym wybierz opcję Utwórz > Eksperyment MLflow.
W polu Nazwa wprowadź
Tutorial.Kliknij Utwórz. Zanotuj identyfikator eksperymentu. W tym przykładzie jest to
14622565.
Krok 2. Uruchamianie projektu samouczka MLflow
Następujące kroki umożliwiają skonfigurowanie MLFLOW_TRACKING_URI zmiennej środowiskowej i uruchomienie projektu, zarejestrowanie parametrów trenowania, metryk i wytrenowanego modelu do eksperymentu zanotowanego w poprzednim kroku:
Ustaw zmienną środowiskową
MLFLOW_TRACKING_URIna obszar roboczy usługi Azure Databricks.export MLFLOW_TRACKING_URI=databricksUruchom samouczek MLflow i przeprowadź trenowanie modelu wina . Zastąp
<experiment-id>identyfikatorem eksperymentu zanotowany w poprzednim kroku.mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u === === Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks === === Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... === === Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 ===Skopiuj adres URL
https://<databricks-instance>#job/<job-id>/run/1w ostatnim wierszu wyniku działania MLflow.
Krok 3. Wyświetlanie uruchomienia zadania usługi Azure Databricks
Otwórz adres URL skopiowany w poprzednim kroku w przeglądarce, aby wyświetlić dane wyjściowe uruchomienia zadania usługi Azure Databricks:
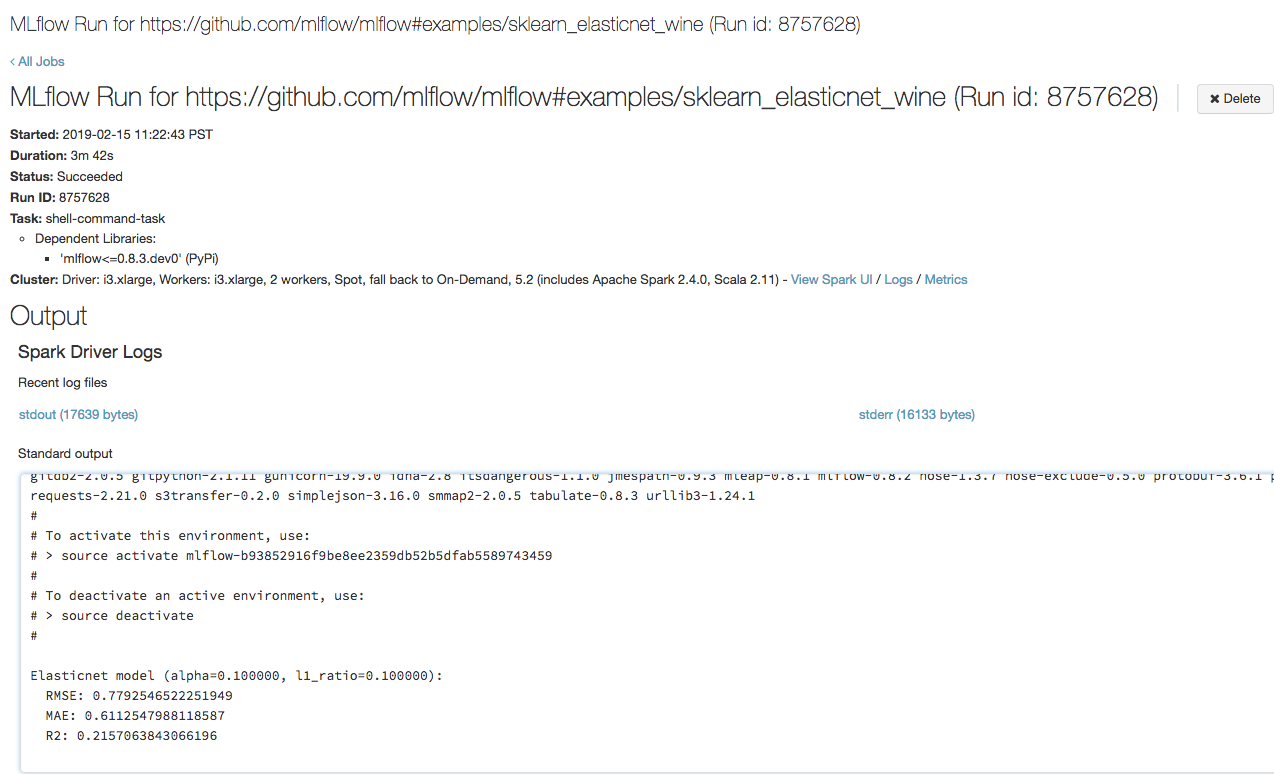
Krok 4: Wyświetlanie szczegółów eksperymentu i przebiegu eksperymentu w MLflow
Przejdź do eksperymentu w obszarze roboczym usługi Azure Databricks.
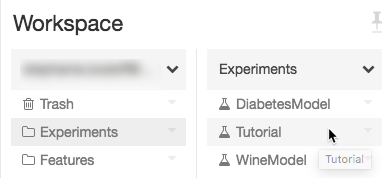 eksperymentu
eksperymentuKliknij eksperyment.
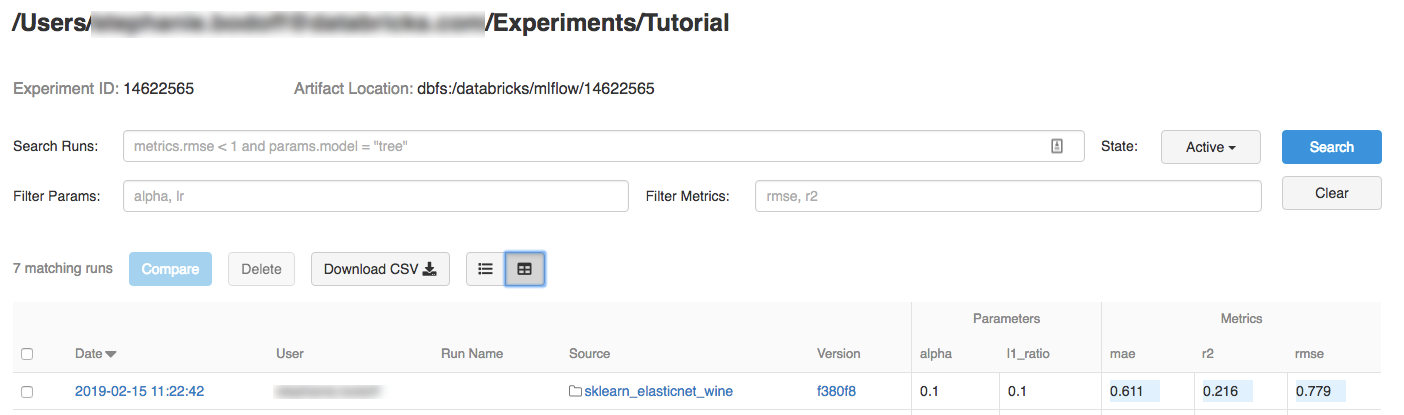
Aby wyświetlić szczegóły przebiegu, kliknij link w kolumnie Data.
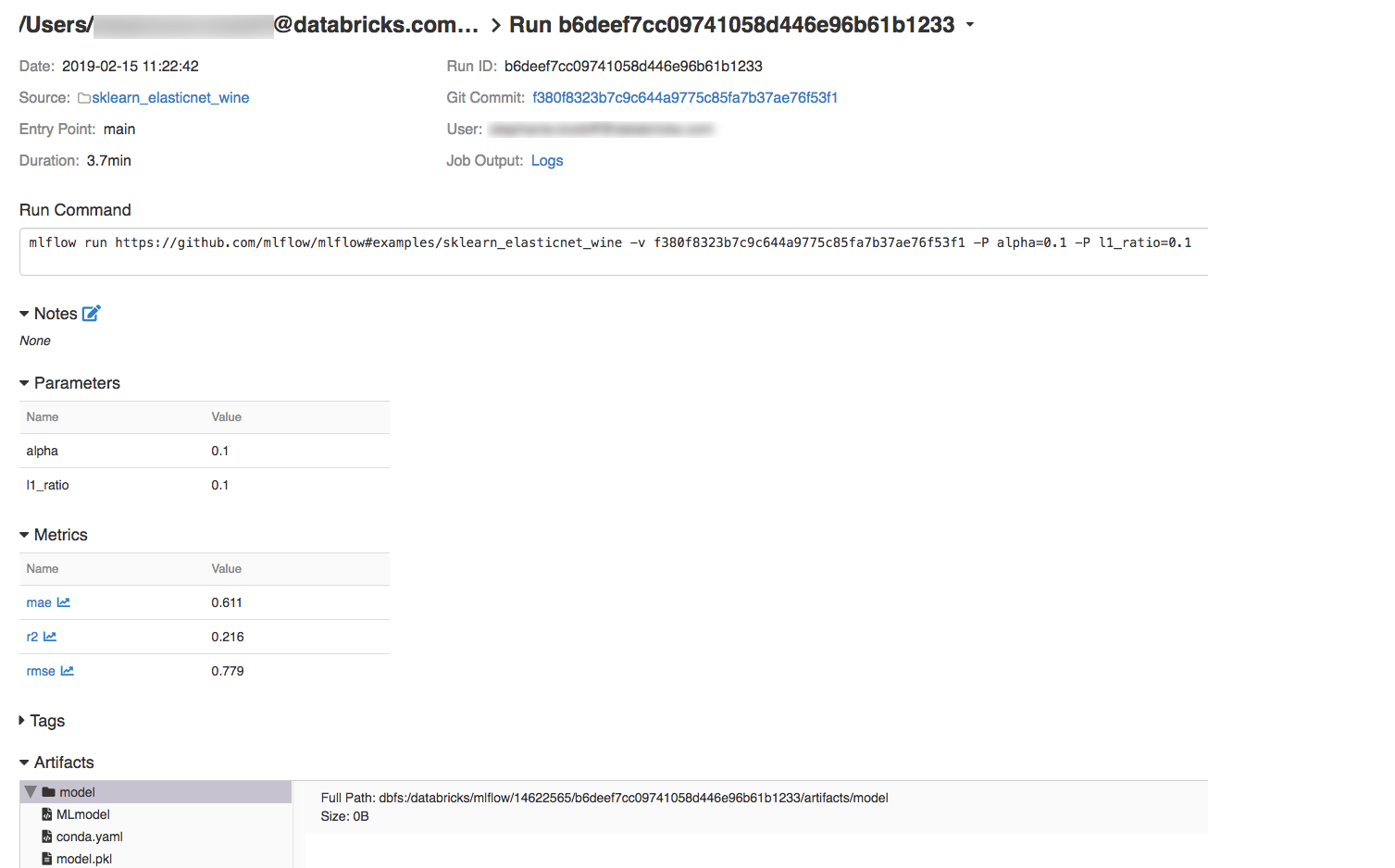
Dzienniki z przebiegu można wyświetlić, klikając link Dzienniki w polu Wynik zadania.
Zasoby
Aby zapoznać się z przykładowymi projektami MLflow, zobacz MLflow App Library, która zawiera repozytorium gotowych do uruchomienia projektów mających na celu ułatwienie uwzględnienia funkcji uczenia maszynowego w kodzie.