Odzyskiwanie po awarii
Jasny wzorzec odzyskiwania po awarii ma kluczowe znaczenie dla natywnej dla chmury platformy analizy danych, takiej jak Azure Databricks. Ważne jest, aby zespoły danych mogły korzystać z platformy Azure Databricks nawet w rzadkich przypadkach awarii dostawcy usług w chmurze w całej usłudze regionalnej, niezależnie od tego, czy jest to spowodowane katastrofą regionalną, jak huragan, trzęsienie ziemi, czy inne źródło.
Usługa Azure Databricks jest często główną częścią ogólnego ekosystemu danych, który obejmuje wiele usług, w tym nadrzędne usługi pozyskiwania danych (batch/streaming), natywny magazyn w chmurze, taki jak ADLS gen2 (dla obszarów roboczych utworzonych przed 6 marca 2023 r., Azure Blob Storage), narzędzia podrzędne i usługi, takie jak aplikacje analizy biznesowej i narzędzia do orkiestracji. Niektóre przypadki użycia mogą być szczególnie wrażliwe na awarię w całej usłudze regionalnej.
W tym artykule opisano pojęcia i najlepsze rozwiązania dotyczące pomyślnego rozwiązania do odzyskiwania po awarii między regionami dla platformy Databricks.
Gwarancje wysokiej dostępności w regionie
W pozostałej części tego tematu skupiono się na implementacji odzyskiwania po awarii między regionami, ale ważne jest, aby zrozumieć gwarancje wysokiej dostępności oferowane przez usługę Azure Databricks wewnątrz jednego regionu. Gwarancje wysokiej dostępności w regionie obejmują następujące składniki:
Dostępność płaszczyzny sterowania usługi Azure Databricks
- Większość usług płaszczyzny sterowania działa w klastrach Kubernetes i automatycznie obsłuży utratę maszyn wirtualnych w określonym az.
- Dane obszaru roboczego są przechowywane w bazach danych z magazynem w warstwie Premium replikowane w całym regionie. Magazyn bazy danych (pojedynczy serwer) nie jest replikowany w różnych regionach ani w różnych regionach. Jeśli awaria strefy ma wpływ na magazyn bazy danych, baza danych zostanie odzyskana przez utworzenie nowego wystąpienia z kopii zapasowej.
- Konta magazynu używane do obsługi obrazów DBR są również nadmiarowe w regionie, a wszystkie regiony mają pomocnicze konta magazynu używane w przypadku awarii podstawowego. Zobacz Regiony usługi Azure Databricks.
- Ogólnie rzecz biorąc, funkcjonalność płaszczyzny sterowania powinna zostać przywrócona w ciągu około 15 minut po odzyskaniu strefy dostępności.
Dostępność płaszczyzny obliczeniowej
- Dostępność obszaru roboczego zależy od dostępności płaszczyzny sterowania (zgodnie z powyższym opisem).
- Nie ma to wpływu na dane w katalogu głównym systemu plików DBFS, jeśli konto magazynu dla głównego systemu plików DBFS jest skonfigurowane z magazynem ZRS lub GZRS (wartość domyślna to GRS).
- Węzły dla klastrów są pobierane z różnych stref dostępności przez żądanie węzłów od dostawcy obliczeń platformy Azure (przy założeniu wystarczającej pojemności w pozostałych strefach w celu spełnienia żądania). W przypadku utraty węzła menedżer klastra żąda węzłów zastępczych od dostawcy zasobów obliczeniowych platformy Azure, który pobiera je z dostępnych stref dostępności. Jedynym wyjątkiem jest utrata węzła sterownika. W takim przypadku zadanie lub menedżer klastra uruchamia je ponownie.
Omówienie odzyskiwania po awarii
Odzyskiwanie po awarii obejmuje zestaw zasad, narzędzi i procedur, które umożliwiają odzyskiwanie lub kontynuację istotnej infrastruktury technologicznej i systemów po klęskach żywiołowych lub wywołanych przez człowieka. Duża usługa w chmurze, podobna do platformy Azure, obsługuje wielu klientów i ma wbudowane zabezpieczenia przed pojedynczym niepowodzeniem. Na przykład region to grupa budynków połączonych z różnymi źródłami zasilania, aby zagwarantować, że jedna utrata energii nie spowoduje zamknięcia regionu. Jednak mogą wystąpić awarie regionów chmury, a stopień zakłóceń i jego wpływu na organizację może się różnić.
Przed wdrożeniem planu odzyskiwania po awarii należy zrozumieć różnicę między odzyskiwaniem po awarii (DR) i wysoką dostępnością .
Wysoka dostępność to cecha odporności systemu. Wysoka dostępność zapewnia minimalny poziom wydajności operacyjnej, który jest zwykle zdefiniowany pod względem spójnego czasu pracy lub procentu czasu pracy. Wysoka dostępność jest implementowana (w tym samym regionie co system podstawowy), projektując ją jako funkcję systemu podstawowego. Na przykład usługi w chmurze, takie jak Platforma Azure, mają usługi wysokiej dostępności, takie jak ADLS gen2 (dla obszarów roboczych utworzonych przed 6 marca 2023 r., Azure Blob Storage). Wysoka dostępność nie wymaga znaczącego jawnego przygotowania od klienta usługi Azure Databricks.
Z kolei plan odzyskiwania po awarii wymaga decyzji i rozwiązań, które działają dla określonej organizacji w celu obsługi większej awarii regionalnej w przypadku krytycznych systemów. W tym artykule omówiono typową terminologię odzyskiwania po awarii, typowe rozwiązania i niektóre najlepsze rozwiązania dotyczące planów odzyskiwania po awarii za pomocą usługi Azure Databricks.
Terminologia
Terminologia dotycząca regionów
W tym artykule użyto następujących definicji dla regionów:
Region podstawowy: region geograficzny, w którym użytkownicy uruchamiają typowe codzienne obciążenia interaktywnej i zautomatyzowanej analizy danych.
Region pomocniczy: region geograficzny, w którym zespoły IT tymczasowo przenoszą obciążenia analizy danych podczas awarii w regionie podstawowym.
Magazyn geograficznie nadmiarowy: platforma Azure ma magazyn geograficznie nadmiarowy w różnych regionach dla magazynu utrwalonego przy użyciu asynchronicznego procesu replikacji magazynu.
Ważne
W przypadku procesów odzyskiwania po awarii usługa Databricks zaleca, aby nie polegać na magazynie geograficznie nadmiarowym na potrzeby duplikowania danych między regionami, takich jak usługa ADLS Gen2 (w przypadku obszarów roboczych utworzonych przed 6 marca 2023 r. usługa Azure Blob Storage), którą usługa Azure Databricks tworzy dla każdego obszaru roboczego w ramach subskrypcji platformy Azure. Ogólnie rzecz biorąc, należy użyć głębokiego klonowania dla tabel różnicowych i przekonwertować dane na format delta, aby użyć funkcji Deep Clone, jeśli jest to możliwe w przypadku innych formatów danych.
Terminologia dotycząca stanu wdrożenia
W tym artykule użyto następujących definicji stanu wdrożenia:
Aktywne wdrażanie: użytkownicy mogą łączyć się z aktywnym wdrożeniem obszaru roboczego usługi Azure Databricks i uruchamiać obciążenia. Zadania są okresowo planowane przy użyciu harmonogramu usługi Azure Databricks lub innego mechanizmu. Strumienie danych można również wykonywać w tym wdrożeniu. Niektóre dokumenty mogą odnosić się do aktywnego wdrożenia jako gorącego wdrożenia.
Wdrożenie pasywne: procesy nie są uruchamiane we wdrożeniu pasywnym. Zespoły IT mogą skonfigurować zautomatyzowane procedury wdrażania kodu, konfiguracji i innych obiektów usługi Azure Databricks we wdrożeniu pasywnym. Wdrożenie staje się aktywne tylko wtedy, gdy bieżące aktywne wdrożenie nie działa. Niektóre dokumenty mogą odnosić się do wdrożenia pasywnego jako zimnego wdrożenia.
Ważne
Projekt może opcjonalnie obejmować wiele pasywnych wdrożeń w różnych regionach, aby zapewnić dodatkowe opcje rozwiązywania regionalnych awarii.
Ogólnie rzecz biorąc, zespół ma tylko jedno aktywne wdrożenie naraz, w co jest nazywane strategią odzyskiwania po awarii aktywne-pasywne . Istnieje mniej typowa strategia rozwiązania odzyskiwania po awarii o nazwie aktywne-aktywne, w której istnieją dwa jednoczesne aktywne wdrożenia.
Terminologia branżowa odzyskiwania po awarii
Istnieją dwa ważne terminy branżowe, które należy zrozumieć i zdefiniować dla zespołu:
Cel punktu odzyskiwania: cel punktu odzyskiwania (RPO) to maksymalny docelowy okres, w którym dane (transakcje) mogą zostać utracone z usługi IT z powodu poważnego zdarzenia. Wdrożenie usługi Azure Databricks nie przechowuje głównych danych klientów. Jest to przechowywane w oddzielnych systemach, takich jak ADLS Gen2 (dla obszarów roboczych utworzonych przed 6 marca 2023 r., Azure Blob Storage) lub innych źródeł danych pod kontrolą. Płaszczyzna sterowania usługi Azure Databricks przechowuje niektóre obiekty częściowo lub w całości, takie jak zadania i notesy. W przypadku usługi Azure Databricks cel punktu odzyskiwania jest definiowany jako maksymalny docelowy okres, w którym można utracić obiekty, takie jak zmiany zadań i notesów. Ponadto odpowiadasz za zdefiniowanie celu punktu odzyskiwania dla własnych danych klienta w usłudze ADLS Gen2 (w przypadku obszarów roboczych utworzonych przed 6 marca 2023 r. lub usługą Azure Blob Storage) lub innymi źródłami danych pod kontrolą.
Cel czasu odzyskiwania: cel czasu odzyskiwania (RTO) to docelowy czas trwania i poziom usługi, w ramach którego proces biznesowy musi zostać przywrócony po awarii.
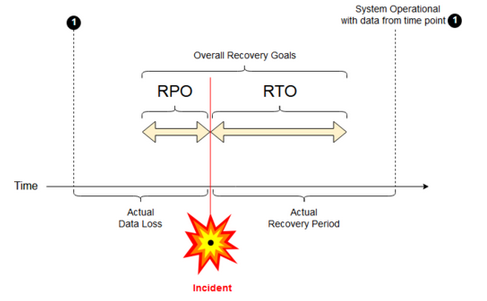
Odzyskiwanie po awarii i uszkodzenie danych
Rozwiązanie odzyskiwania po awarii nie ogranicza uszkodzenia danych. Uszkodzone dane w regionie podstawowym są replikowane z regionu podstawowego do regionu pomocniczego i są uszkodzone w obu regionach. Istnieją inne sposoby łagodzenia tego rodzaju awarii, na przykład podróży w czasie różnicy.
Typowy przepływ pracy odzyskiwania
Scenariusz odzyskiwania po awarii usługi Azure Databricks zwykle jest następujący:
Awaria występuje w usłudze krytycznej używanej w regionie podstawowym. Może to być usługa źródła danych lub sieć, która ma wpływ na wdrożenie usługi Azure Databricks.
Zbadasz sytuację u dostawcy usług w chmurze.
Jeśli stwierdzisz, że firma nie może poczekać na skorygowanie problemu w regionie podstawowym, może okazać się konieczne przejście w tryb failover do regionu pomocniczego.
Sprawdź, czy ten sam problem nie ma również wpływu na region pomocniczy.
Przechodzenie w tryb failover do regionu pomocniczego.
- Zatrzymaj wszystkie działania w obszarze roboczym. Użytkownicy zatrzymują obciążenia. Użytkownicy lub administratorzy są poinstruowani, aby w miarę możliwości utworzyć kopię zapasową ostatnich zmian. Zadania są zamykane, jeśli jeszcze nie powiodły się z powodu awarii.
- Uruchom procedurę odzyskiwania w regionie pomocniczym. Procedura odzyskiwania aktualizuje routing i zmianę nazw połączeń i ruchu sieciowego do regionu pomocniczego.
- Po przetestowaniu zadeklaruj działanie regionu pomocniczego. Obciążenia produkcyjne można teraz wznowić. Użytkownicy mogą logować się do teraz aktywnego wdrożenia. Możesz ponownie pobrać zaplanowane lub opóźnione zadania.
Aby uzyskać szczegółowe instrukcje w kontekście usługi Azure Databricks, zobacz Testowanie trybu failover.
W pewnym momencie problem w regionie podstawowym został rozwiązany i potwierdzisz ten fakt.
Przywracanie (powrót po awarii) do regionu podstawowego.
- Zatrzymaj całą pracę w regionie pomocniczym.
- Uruchom procedurę odzyskiwania w regionie podstawowym. Procedura odzyskiwania obsługuje routing i zmianę nazwy połączenia i ruchu sieciowego z powrotem do regionu podstawowego.
- Replikuj dane z powrotem do regionu podstawowego zgodnie z potrzebami. Aby zmniejszyć złożoność, być może zminimalizuj ilość danych, które należy replikować. Jeśli na przykład niektóre zadania są tylko do odczytu po uruchomieniu we wdrożeniu pomocniczym, może nie być konieczne zreplikowanie tych danych z powrotem do podstawowego wdrożenia w regionie podstawowym. Może jednak istnieć jedno zadanie produkcyjne, które musi zostać uruchomione i może wymagać replikacji danych z powrotem do regionu podstawowego.
- Przetestuj wdrożenie w regionie podstawowym.
- Zadeklaruj działanie regionu podstawowego i że jest to aktywne wdrożenie. Wznawianie obciążeń produkcyjnych.
Aby uzyskać więcej informacji na temat przywracania do regionu podstawowego, zobacz Testowanie przywracania (powrót po awarii).
Ważne
W tych krokach może wystąpić utrata danych. Twoja organizacja musi zdefiniować, ile utraty danych jest akceptowalna i co można zrobić, aby ograniczyć tę utratę.
Krok 1. Zrozumienie potrzeb biznesowych
Pierwszym krokiem jest zdefiniowanie i zrozumienie potrzeb biznesowych. Zdefiniuj usługi danych o krytycznym znaczeniu i oczekiwanym celu punktu odzyskiwania i celu punktu odzyskiwania.
Zbadaj rzeczywistą tolerancję każdego systemu i pamiętaj, że przejście w tryb failover i powrót po awarii może być kosztowne i niesie ze sobą inne zagrożenia. Inne zagrożenia mogą obejmować uszkodzenie danych, zduplikowane dane, jeśli zapisujesz w niewłaściwej lokalizacji magazynu, a użytkownicy logujący się i wprowadzający zmiany w nieprawidłowych miejscach.
Mapuj wszystkie punkty integracji usługi Azure Databricks, które wpływają na Twoją firmę:
- Czy rozwiązanie odzyskiwania po awarii musi obsługiwać interaktywne procesy, zautomatyzowane procesy lub oba te procesy?
- Jakich usług danych używasz? Niektóre mogą być lokalne.
- Jak dane wejściowe są uzyskiwane do chmury?
- Kto korzysta z tych danych? Jakie procesy zużywają go podrzędnie?
- Czy istnieją integracje innych firm, które muszą mieć świadomość zmian odzyskiwania po awarii?
Określ narzędzia lub strategie komunikacji, które mogą obsługiwać plan odzyskiwania po awarii:
- Jakich narzędzi użyjesz do szybkiego modyfikowania konfiguracji sieci?
- Czy można wstępnie zdefiniować konfigurację i uczynić ją modułową, aby uwzględnić rozwiązania odzyskiwania po awarii w naturalny i konserwowalny sposób?
- Które narzędzia komunikacyjne i kanały powiadomią wewnętrzne zespoły i inne firmy (integracje, odbiorców podrzędnych) o zmianach trybu failover odzyskiwania po awarii i powrotu po awarii? A jak potwierdzisz ich potwierdzenie?
- Jakie narzędzia lub specjalne wsparcie będą potrzebne?
- Jakie usługi zostaną zamknięte do czasu zakończenia odzyskiwania?
Krok 2. Wybieranie procesu spełniającego potrzeby biznesowe
Rozwiązanie musi replikować poprawne dane zarówno na płaszczyźnie sterowania, w płaszczyźnie obliczeniowej, jak i w źródłach danych. Nadmiarowe obszary robocze na potrzeby odzyskiwania po awarii muszą być mapowanie na różne płaszczyzny sterowania w różnych regionach. Dane muszą być synchronizowane okresowo przy użyciu rozwiązania opartego na skryptach, narzędzia do synchronizacji lub przepływu pracy ciągłej integracji/ciągłego wdrażania. Nie ma potrzeby synchronizowania danych z samej sieci płaszczyzny obliczeniowej, na przykład z procesów roboczych środowiska Databricks Runtime.
Jeśli używasz funkcji iniekcji sieci wirtualnej (niedostępnej dla wszystkich subskrypcji i typów wdrożeń), możesz konsekwentnie wdrażać te sieci w obu regionach przy użyciu narzędzi opartych na szablonach, takich jak Terraform.
Ponadto należy upewnić się, że źródła danych są replikowane zgodnie z potrzebami w różnych regionach.
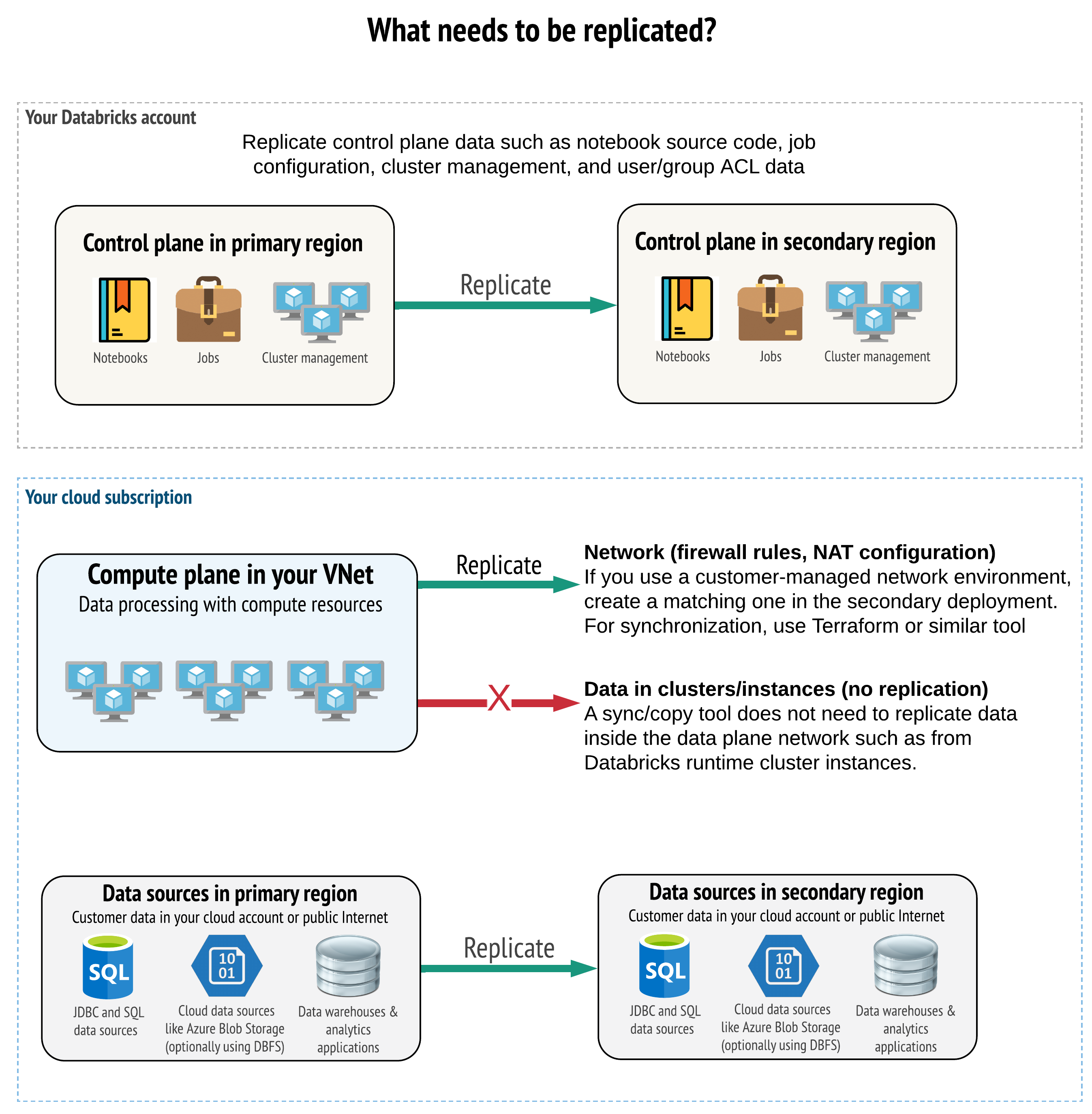
Ogólne sprawdzone metody postępowania
Ogólne najlepsze rozwiązania dotyczące pomyślnego planu odzyskiwania po awarii obejmują:
Dowiedz się, które procesy mają kluczowe znaczenie dla firmy i muszą być uruchamiane w odzyskiwaniu po awarii.
Jasno określ, które usługi są zaangażowane, które dane są przetwarzane, jaki jest przepływ danych i gdzie są przechowywane
Izoluj usługi i dane jak najwięcej. Na przykład utwórz specjalny kontener magazynu w chmurze dla danych na potrzeby odzyskiwania po awarii lub przenieś obiekty usługi Azure Databricks potrzebne podczas awarii do oddzielnego obszaru roboczego.
Twoim zadaniem jest zachowanie integralności między wdrożeniami podstawowymi i pomocniczymi dla innych obiektów, które nie są przechowywane na płaszczyźnie sterowania usługi Databricks.
Ostrzeżenie
Najlepszym rozwiązaniem jest, aby nie przechowywać danych w głównej usłudze ADLS Gen2 (w przypadku obszarów roboczych utworzonych przed 6 marca 2023 r. usługa Azure Blob Storage), która jest używana do dostępu głównego systemu plików DBFS dla obszaru roboczego. Ten magazyn główny systemu plików DBFS nie jest obsługiwany dla produkcyjnych danych klienta. Usługa Databricks zaleca również, aby nie przechowywać bibliotek, plików konfiguracji ani skryptów inicjowania w tej lokalizacji.
W przypadku źródeł danych, jeśli to możliwe, zaleca się używanie natywnych narzędzi platformy Azure do replikacji i nadmiarowości w celu replikacji danych do regionów odzyskiwania po awarii.
Wybieranie strategii rozwiązania odzyskiwania
Typowe rozwiązania odzyskiwania po awarii obejmują dwa (lub więcej) obszary robocze. Istnieje kilka strategii, które można wybrać. Rozważ potencjalną długość zakłóceń (godziny, a może nawet dzień), wysiłek, aby upewnić się, że obszar roboczy jest w pełni operacyjny, oraz nakład pracy w celu przywrócenia (powrotu po awarii) do regionu podstawowego.
Strategia rozwiązania aktywne-pasywne
Rozwiązanie aktywne-pasywne jest najczęściej spotykanym i najprostszym rozwiązaniem, a ten typ rozwiązania koncentruje się na tym artykule. Rozwiązanie aktywne-pasywne synchronizuje zmiany danych i obiektów z aktywnego wdrożenia do wdrożenia pasywnego. Jeśli wolisz, możesz mieć wiele pasywnych wdrożeń w różnych regionach, ale ten artykuł koncentruje się na podejściu do wdrażania pojedynczego pasywnego. Podczas zdarzenia odzyskiwania po awarii pasywne wdrożenie w regionie pomocniczym staje się aktywnym wdrożeniem.
Istnieją dwa główne warianty tej strategii:
- Ujednolicone (mądre dla przedsiębiorstw) rozwiązanie: dokładnie jeden zestaw aktywnych i pasywnych wdrożeń, które obsługują całą organizację.
- Rozwiązanie według działu lub projektu: każdy dział lub domena projektu obsługuje oddzielne rozwiązanie odzyskiwania po awarii. Niektóre organizacje chcą rozdzielić szczegóły odzyskiwania po awarii między działami i używać różnych regionów podstawowych i pomocniczych dla każdego zespołu na podstawie unikatowych potrzeb każdego zespołu.
Istnieją inne warianty, takie jak użycie wdrożenia pasywnego dla przypadków użycia tylko do odczytu. Jeśli masz obciążenia, które są tylko do odczytu, na przykład zapytania użytkowników, mogą być uruchamiane w rozwiązaniu pasywnym w dowolnym momencie, jeśli nie modyfikują danych lub obiektów usługi Azure Databricks, takich jak notesy lub zadania.
Strategia rozwiązania aktywne-aktywne
W rozwiązaniu aktywne-aktywne uruchamiasz wszystkie procesy danych w obu regionach przez cały czas równolegle. Zespół operacyjny musi upewnić się, że proces danych, taki jak zadanie, jest oznaczony jako ukończony tylko wtedy, gdy zakończy się pomyślnie w obu regionach. Nie można zmienić obiektów w środowisku produkcyjnym i muszą być zgodne z ścisłą promocją ciągłej integracji/ciągłego wdrażania z programowania/przemieszczania do środowiska produkcyjnego.
Rozwiązanie aktywne-aktywne jest najbardziej złożoną strategią, a ponieważ zadania są uruchamiane w obu regionach, istnieje dodatkowy koszt finansowy.
Podobnie jak w przypadku strategii aktywne-pasywne, można zaimplementować je jako ujednolicone rozwiązanie organizacji lub według działu.
W zależności od przepływu pracy może być potrzebny równoważny obszar roboczy w systemie pomocniczym dla wszystkich obszarów roboczych. Na przykład może być potrzebny zduplikowany obszar roboczy programowania lub przejściowego. W przypadku dobrze zaprojektowanego potoku programowania możesz łatwo odtworzyć te obszary robocze w razie potrzeby.
Wybieranie narzędzi
Istnieją dwa główne podejścia do przechowywania danych tak samo jak to możliwe między obszarami roboczymi w regionach podstawowych i pomocniczych:
- Klient synchronizacji, który kopiuje z podstawowej do pomocniczej: klient synchronizacji wypycha dane produkcyjne i zasoby z regionu podstawowego do regionu pomocniczego. Zazwyczaj jest to uruchamiane zgodnie z harmonogramem.
- Narzędzia ciągłej integracji/ciągłego wdrażania na potrzeby wdrażania równoległego: w przypadku kodu produkcyjnego i zasobów użyj narzędzi ciągłej integracji/ciągłego wdrażania, które wypycha zmiany do systemów produkcyjnych jednocześnie do obu regionów. Na przykład podczas wypychania kodu i zasobów z etapu przejściowego/programowania do środowiska produkcyjnego system ciągłej integracji/ciągłego wdrażania udostępnia go w obu regionach w tym samym czasie. Podstawowym pomysłem jest traktowanie wszystkich artefaktów w obszarze roboczym usługi Azure Databricks jako infrastruktury jako kodu. Większość artefaktów można wdrożyć we współdróżnych obszarach roboczych zarówno w obszarze podstawowym, jak i pomocniczym, podczas gdy niektóre artefakty mogą być wdrażane dopiero po wystąpieniu zdarzenia odzyskiwania po awarii. Aby zapoznać się z narzędziami, zobacz Automatyzacja skryptów, przykładów i prototypów.
Poniższy diagram kontrastuje z tymi dwoma metodami.
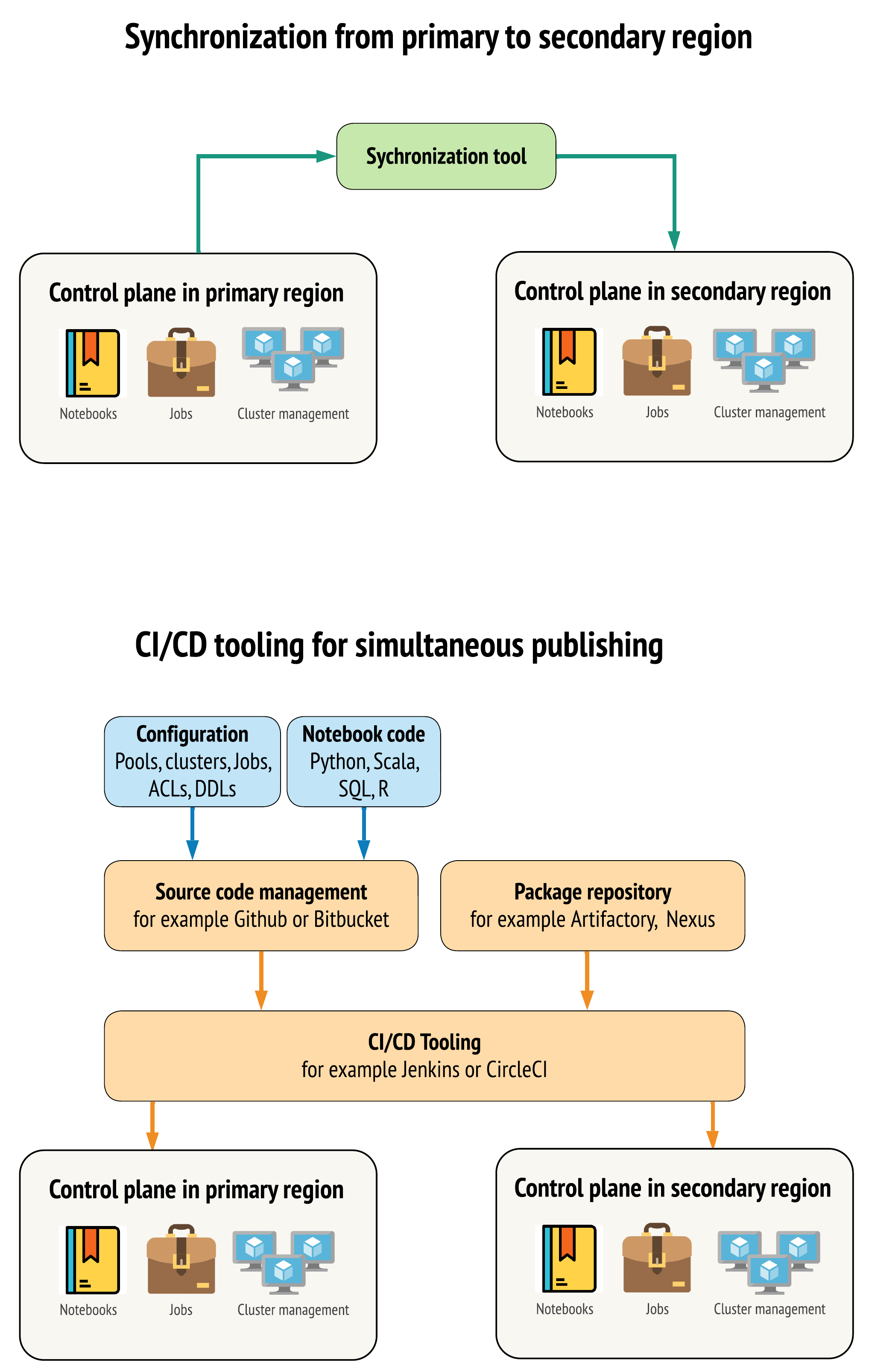
W zależności od potrzeb można połączyć podejścia. Na przykład użyj ciągłej integracji/ciągłego wdrażania dla kodu źródłowego notesu, ale użyj synchronizacji dla konfiguracji, takiej jak pule i mechanizmy kontroli dostępu.
W poniższej tabeli opisano sposób obsługi różnych typów danych przy użyciu każdej opcji narzędzi.
| opis | Jak obsługiwać narzędzia ciągłej integracji/ciągłego wdrażania | Jak obsługiwać narzędzie do synchronizacji |
|---|---|---|
| Kod źródłowy: eksporty źródła notesu i kod źródłowy dla spakowanych bibliotek | Współdróżne wdrożenie zarówno w wersji podstawowej, jak i pomocniczej. | Zsynchronizuj kod źródłowy z podstawowego na pomocniczy. |
| Użytkownicy i grupy | Zarządzaj metadanymi jako konfiguracją w usłudze Git. Alternatywnie użyj tego samego dostawcy tożsamości (IdP) dla obu obszarów roboczych. Wdrażanie danych użytkowników i grup we wdrożeniach podstawowych i pomocniczych. | Użyj interfejsu SCIM lub innego automatyzacji dla obu regionów. Ręczne tworzenie nie jest zalecane, ale jeśli jest używane, należy wykonać zarówno w tym samym czasie. Jeśli używasz konfiguracji ręcznej, utwórz zaplanowany proces zautomatyzowany, aby porównać listę użytkowników i grupę między dwoma wdrożeniami. |
| Konfiguracje puli | Może to być szablony w usłudze Git. Współdróżniowe wdrożenie w podstawowej i pomocniczej wersji. Jednak min_idle_instances w pomocniczej wersji musi być zero do momentu wystąpienia zdarzenia odzyskiwania po awarii. |
Pule utworzone przy użyciu dowolnej min_idle_instances synchronizacji z pomocniczym obszarem roboczym przy użyciu interfejsu API lub interfejsu wiersza polecenia. |
| Konfiguracje zadań | Może to być szablony w usłudze Git. W przypadku wdrożenia podstawowego wdróż definicję zadania w następujący sposób. W przypadku wdrożenia pomocniczego wdróż zadanie i ustaw wartość współbieżnych na zero. Spowoduje to wyłączenie zadania w tym wdrożeniu i uniemożliwia wykonywanie dodatkowych uruchomień. Zmień wartość concurrencies po wdrożeniu pomocniczym staje się aktywny. | Jeśli z jakiegoś powodu zadania są uruchamiane w istniejących <interactive> klastrach, klient synchronizacji musi mapować go na odpowiednie cluster_id w pomocniczym obszarze roboczym. |
| Listy kontroli dostępu (ACL) | Może to być szablony w usłudze Git. Wdrażanie we wdrożeniach podstawowych i pomocniczych dla notesów, folderów i klastrów. Jednak dane dla zadań będą przechowywane do momentu wystąpienia zdarzenia odzyskiwania po awarii. | Interfejs API uprawnień może ustawiać mechanizmy kontroli dostępu dla klastrów, zadań, pul, notesów i folderów. Klient synchronizacji musi mapować odpowiednie identyfikatory obiektów dla każdego obiektu w pomocniczym obszarze roboczym. Usługa Databricks zaleca utworzenie mapy identyfikatorów obiektów z podstawowego do pomocniczego obszaru roboczego podczas synchronizowania tych obiektów przed replikowaniem kontrolek dostępu. |
| Biblioteki | Uwzględnij w kodzie źródłowym i szablonach zadań/klastra. | Zsynchronizuj biblioteki niestandardowe ze scentralizowanych repozytoriów, systemu plików DBFS lub magazynu w chmurze (można je instalować). |
| Skrypty inicjowania klastra | Uwzględnij w kodzie źródłowym, jeśli wolisz. | Aby uzyskać prostszą synchronizację, przechowuj skrypty inicjowania w podstawowym obszarze roboczym we wspólnym folderze lub w małym zestawie folderów, jeśli to możliwe. |
| Punkty instalacji | Uwzględnij kod źródłowy, jeśli jest tworzony tylko za pomocą zadań opartych na notesie lub interfejsu API poleceń. | Użyj zadań, które mogą być uruchamiane jako działania usługi Azure Data Factory (ADF). Należy pamiętać, że punkty końcowe magazynu mogą ulec zmianie, biorąc pod uwagę, że obszary robocze będą znajdować się w różnych regionach. Jest to bardzo zależne od strategii odzyskiwania po awarii danych. |
| Metadane tabeli | Dołącz do kodu źródłowego, jeśli jest tworzony tylko za pomocą zadań opartych na notesie lub interfejsu API poleceń. Dotyczy to zarówno wewnętrznego magazynu metadanych usługi Azure Databricks, jak i zewnętrznego skonfigurowanego magazynu metadanych. | Porównaj definicje metadanych między magazynami metadanych przy użyciu interfejsu API wykazu platformy Spark lub Pokaż tworzenie tabeli za pomocą notesu lub skryptów. Należy pamiętać, że tabele magazynu bazowego mogą być oparte na regionie i różnią się między wystąpieniami magazynu metadanych. |
| Wpisy tajne | Uwzględnij w kodzie źródłowym, jeśli został utworzony tylko za pomocą interfejsu API poleceń. Należy pamiętać, że niektóre wpisy tajne mogą wymagać zmiany między podstawową i pomocniczą. | Wpisy tajne są tworzone w obu obszarach roboczych za pośrednictwem interfejsu API. Należy pamiętać, że niektóre wpisy tajne mogą wymagać zmiany między podstawową i pomocniczą. |
| Konfiguracje klastrów | Może to być szablony w usłudze Git. Współdróżniowe wdrożenia w wdrożeniach podstawowych i pomocniczych, chociaż te w ramach wdrożenia pomocniczego powinny zostać zakończone do momentu wystąpienia zdarzenia odzyskiwania po awarii. | Klastry są tworzone po zsynchronizowaniu z pomocniczym obszarem roboczym przy użyciu interfejsu API lub interfejsu wiersza polecenia. Można je jawnie zakończyć, jeśli chcesz, w zależności od ustawień automatycznego kończenia. |
| Uprawnienia notesu, zadania i folderu | Może to być szablony w usłudze Git. Wdrażanie we wdrożeniach podstawowych i pomocniczych. | Replikuj przy użyciu interfejsu API uprawnień. |
Wybieranie regionów i wielu pomocniczych obszarów roboczych
Potrzebujesz pełnej kontroli nad wyzwalaczem odzyskiwania po awarii. Możesz zdecydować się na wyzwolenie tego w dowolnym momencie lub z jakiegokolwiek powodu. Przed ponownym uruchomieniem trybu powrotu po awarii (normalnego środowiska produkcyjnego) musisz wziąć na siebie odpowiedzialność za stabilizację odzyskiwania po awarii. Zazwyczaj oznacza to, że musisz utworzyć wiele obszarów roboczych usługi Azure Databricks, aby obsługiwać potrzeby środowiska produkcyjnego i odzyskiwania po awarii, a następnie wybrać pomocniczy region trybu failover.
Na platformie Azure sprawdź dostępność replikacji danych, a także dostępność typów produktów i maszyn wirtualnych.
Krok 3. Przygotowywanie obszarów roboczych i wykonywanie jednorazowej kopii
Jeśli obszar roboczy jest już w środowisku produkcyjnym, zazwyczaj należy uruchomić jednorazową operację kopiowania w celu zsynchronizowania pasywnego wdrożenia z aktywnym wdrożeniem. Ta jednorazowa kopia obsługuje następujące elementy:
- Replikacja danych: replikowanie przy użyciu rozwiązania replikacji w chmurze lub operacji delta Deep Clone.
- Generowanie tokenu: użyj generowania tokenów, aby zautomatyzować replikację i przyszłe obciążenia.
- Replikacja obszaru roboczego: użyj replikacji obszaru roboczego przy użyciu metod opisanych w kroku 4: Przygotowywanie źródeł danych.
- Walidacja obszaru roboczego: — test, aby upewnić się, że obszar roboczy i proces mogą zostać wykonane pomyślnie i dostarczyć oczekiwane wyniki.
Po początkowej operacji kopiowania jednorazowego kolejne akcje kopiowania i synchronizacji są szybsze, a wszelkie rejestrowanie z narzędzi jest również dziennikiem zmian i zmian.
Krok 4. Przygotowanie źródeł danych
Usługa Azure Databricks może przetwarzać wiele różnych źródeł danych przy użyciu przetwarzania wsadowego lub strumieni danych.
Przetwarzanie wsadowe ze źródeł danych
Gdy dane są przetwarzane w partiach, zwykle znajdują się w źródle danych, które można łatwo replikować lub dostarczać do innego regionu.
Na przykład dane mogą być regularnie przekazywane do lokalizacji przechowywania w chmurze. W trybie odzyskiwania po awarii dla regionu pomocniczego należy upewnić się, że pliki zostaną przekazane do magazynu w regionie pomocniczym. Obciążenia muszą odczytywać magazyn w regionie pomocniczym i zapisywać w magazynie w regionie pomocniczym.
Strumienie danych
Przetwarzanie strumienia danych jest większym wyzwaniem. Dane przesyłane strumieniowo mogą być pozyskiwane z różnych źródeł i przetwarzane i wysyłane do rozwiązania do przesyłania strumieniowego:
- Kolejka komunikatów, taka jak Kafka
- Strumień przechwytywania zmian danych bazy danych
- Przetwarzanie ciągłe oparte na plikach
- Zaplanowane przetwarzanie oparte na plikach, nazywane również wyzwalaczem raz
We wszystkich tych przypadkach należy skonfigurować źródła danych tak, aby obsługiwały tryb odzyskiwania po awarii i korzystały z wdrożenia pomocniczego w regionie pomocniczym.
Składnik zapisywania strumienia przechowuje punkt kontrolny z informacjami o przetworzonych danych. Ten punkt kontrolny może zawierać lokalizację danych (zazwyczaj magazyn w chmurze), która musi zostać zmodyfikowana w nowej lokalizacji, aby zapewnić pomyślne ponowne uruchomienie strumienia. Na przykład source podfolder w punkcie kontrolnym może przechowywać folder w chmurze oparty na plikach.
Ten punkt kontrolny musi być replikowany w odpowiednim czasie. Rozważ synchronizację interwału punktu kontrolnego z dowolnym nowym rozwiązaniem replikacji w chmurze.
Aktualizacja punktu kontrolnego jest funkcją składnika zapisywania i dlatego ma zastosowanie do pozyskiwania lub przetwarzania strumienia danych i przechowywania ich w innym źródle przesyłania strumieniowego.
W przypadku obciążeń przesyłania strumieniowego upewnij się, że punkty kontrolne są skonfigurowane w magazynie zarządzanym przez klienta, aby można je było replikować do regionu pomocniczego w celu wznowienia obciążenia od momentu ostatniej awarii. Możesz również uruchomić pomocniczy proces przesyłania strumieniowego równolegle do procesu podstawowego.
Krok 5. Implementowanie i testowanie rozwiązania
Okresowo testuj konfigurację odzyskiwania po awarii, aby upewnić się, że działa prawidłowo. Nie ma żadnej wartości w utrzymywaniu rozwiązania odzyskiwania po awarii, jeśli nie można go używać, gdy jest potrzebny. Niektóre firmy przełączają się między regionami co kilka miesięcy. Przełączanie regionów zgodnie z regularnym harmonogramem testuje założenia i procesy oraz zapewnia, że spełniają one potrzeby odzyskiwania. Dzięki temu organizacja zapozna się również z zasadami i procedurami w nagłych wypadkach.
Ważne
Regularnie testuj rozwiązanie odzyskiwania po awarii w rzeczywistych warunkach.
Jeśli okaże się, że brakuje obiektu lub szablonu i nadal musisz polegać na informacjach przechowywanych w podstawowym obszarze roboczym, zmodyfikuj plan usunięcia tych przeszkód, zreplikuj te informacje w systemie pomocniczym lub udostępnij je w inny sposób.
Przetestuj wszelkie wymagane zmiany organizacyjne w procesach i ogólnie skonfiguruj konfigurację. Plan odzyskiwania po awarii ma wpływ na potok wdrażania i ważne jest, aby zespół wiedział, co musi być zsynchronizowane. Po skonfigurowaniu obszarów roboczych odzyskiwania po awarii należy upewnić się, że infrastruktura (ręcznie lub kod), zadania, notes, biblioteki i inne obiekty obszaru roboczego są dostępne w regionie pomocniczym.
Porozmawiaj z zespołem o sposobie rozszerzania standardowych procesów roboczych i potoków konfiguracji w celu wdrożenia zmian we wszystkich obszarach roboczych. Zarządzanie tożsamościami użytkowników we wszystkich obszarach roboczych. Pamiętaj, aby skonfigurować narzędzia, takie jak automatyzacja zadań i monitorowanie nowych obszarów roboczych.
Planowanie i testowanie zmian w narzędziach konfiguracji:
- Pozyskiwanie: dowiedz się, gdzie znajdują się źródła danych i gdzie te źródła pobierają swoje dane. Jeśli to możliwe, sparametryzuj źródło i upewnij się, że masz oddzielny szablon konfiguracji do pracy z wdrożeniami pomocniczymi i regionami pomocniczymi. Przygotuj plan przejścia w tryb failover i przetestuj wszystkie założenia.
- Zmiany wykonywania: jeśli masz harmonogram wyzwalający zadania lub inne akcje, może być konieczne skonfigurowanie oddzielnego harmonogramu, który współpracuje z wdrożeniem pomocniczym lub jego źródłami danych. Przygotuj plan przejścia w tryb failover i przetestuj wszystkie założenia.
- Łączność interaktywna: rozważ, jak konfiguracja, uwierzytelnianie i połączenia sieciowe mogą mieć wpływ na regionalne zakłócenia w przypadku dowolnego użycia interfejsów API REST, narzędzi interfejsu wiersza polecenia lub innych usług, takich jak JDBC/ODBC. Przygotuj plan przejścia w tryb failover i przetestuj wszystkie założenia.
- Zmiany automatyzacji: dla wszystkich narzędzi automatyzacji przygotuj plan przejścia w tryb failover i przetestuj wszystkie założenia.
- Dane wyjściowe: w przypadku wszystkich narzędzi, które generują dane wyjściowe lub dzienniki, przygotuj plan przejścia w tryb failover i przetestuj wszystkie założenia.
Testowanie pracy w trybie failover
Odzyskiwanie po awarii może być wyzwalane przez wiele różnych scenariuszy. Może zostać wyzwolony przez nieoczekiwaną przerwę. Niektóre podstawowe funkcje mogą nie działać, w tym sieć w chmurze, magazyn w chmurze lub inna podstawowa usługa. Nie masz dostępu do bezpiecznego zamykania systemu i musisz spróbować odzyskać. Jednak proces może zostać wyzwolony przez zamknięcie lub planowaną awarię, a nawet przez okresowe przełączanie aktywnych wdrożeń między dwoma regionami.
Podczas testowania trybu failover połącz się z systemem i uruchom proces zamykania. Upewnij się, że wszystkie zadania zostały ukończone, a klastry zostaną zakończone.
Klient synchronizacji (lub narzędzia ciągłej integracji/ciągłego wdrażania) może replikować odpowiednie obiekty i zasoby usługi Azure Databricks do pomocniczego obszaru roboczego. Aby aktywować pomocniczy obszar roboczy, proces może obejmować niektóre lub wszystkie następujące elementy:
- Uruchom testy, aby potwierdzić, że platforma jest aktualna.
- Wyłącz pule i klastry w regionie podstawowym, aby w przypadku powrotu usługi, która zakończyła się niepowodzeniem, region podstawowy nie rozpoczyna przetwarzania nowych danych.
- Proces odzyskiwania:
- Sprawdź datę najnowszych zsynchronizowanych danych. Zobacz Terminologia branżowa odzyskiwania po awarii. Szczegóły tego kroku różnią się w zależności od sposobu synchronizowania danych i unikatowych potrzeb biznesowych.
- Stabilizuj źródła danych i upewnij się, że są one dostępne. Uwzględnij wszystkie zewnętrzne źródła danych, takie jak Azure Cloud SQL, a także usługi Delta Lake, Parquet lub inne pliki.
- Znajdź punkt odzyskiwania przesyłania strumieniowego. Skonfiguruj proces ponownego uruchomienia z tego miejsca i przygotuj proces do identyfikowania i eliminowania potencjalnych duplikatów (usługa Delta Lake Lake ułatwia to).
- Ukończ proces przepływu danych i poinformuj użytkowników.
- Uruchom odpowiednie pule (lub zwiększ
min_idle_instanceswartość do odpowiedniej liczby). - Uruchom odpowiednie klastry (jeśli nie zostanie zakończone).
- Zmień współbieżne uruchamianie dla zadań i uruchom odpowiednie zadania. Mogą to być jednorazowe uruchomienia lub okresowe uruchomienia.
- W przypadku dowolnego zewnętrznego narzędzia korzystającego z adresu URL lub nazwy domeny dla obszaru roboczego usługi Azure Databricks zaktualizuj konfiguracje, aby uwzględnić nową płaszczyznę sterowania. Na przykład zaktualizuj adresy URL dla interfejsów API REST i połączeń JDBC/ODBC. Adres URL aplikacji internetowej usługi Azure Databricks zmienia się po zmianie płaszczyzny sterowania, dlatego powiadamiaj użytkowników organizacji o nowym adresie URL.
Testowanie przywracania (powrót po awarii)
Powrót po awarii jest łatwiejszy do kontrolowania i można go wykonać w oknie obsługi. Ten plan może obejmować niektóre lub wszystkie następujące elementy:
- Uzyskaj potwierdzenie przywrócenia regionu podstawowego.
- Wyłącz pule i klastry w regionie pomocniczym, aby nie rozpocząć przetwarzania nowych danych.
- Zsynchronizuj wszystkie nowe lub zmodyfikowane zasoby w pomocniczym obszarze roboczym z powrotem do wdrożenia podstawowego. W zależności od projektu skryptów trybu failover może być możliwe uruchomienie tych samych skryptów w celu zsynchronizowania obiektów z regionu pomocniczego (odzyskiwania po awarii) do regionu podstawowego (produkcyjnego).
- Zsynchronizuj wszystkie nowe aktualizacje danych z powrotem do wdrożenia podstawowego. Możesz użyć dzienników inspekcji i tabel delty, aby zagwarantować brak utraty danych.
- Zamknij wszystkie obciążenia w regionie odzyskiwania po awarii.
- Zmień adres URL zadań i użytkowników na region podstawowy.
- Uruchom testy, aby potwierdzić, że platforma jest aktualna.
- Uruchom odpowiednie pule (lub zwiększ wartość
min_idle_instancesdo odpowiedniej liczby). - Uruchom odpowiednie klastry (jeśli nie zostanie zakończone).
- Zmień współbieżne uruchamianie dla zadań i uruchom odpowiednie zadania. Mogą to być jednorazowe uruchomienia lub okresowe uruchomienia.
- W razie potrzeby skonfiguruj ponownie region pomocniczy na potrzeby przyszłego odzyskiwania po awarii.
Skrypty automatyzacji, przykłady i prototypy
Skrypty automatyzacji do rozważenia dla projektów odzyskiwania po awarii:
- Usługa Databricks zaleca użycie dostawcy narzędzia Terraform usługi Databricks w celu ułatwienia tworzenia własnego procesu synchronizacji.
- Zobacz również Narzędzia migracji obszaru roboczego usługi Databricks, aby zapoznać się z przykładowymi i prototypowymi skryptami. Oprócz obiektów usługi Azure Databricks zreplikuj wszystkie odpowiednie potoki usługi Azure Data Factory, aby odwoływały się do połączonej usługi mapowanej na pomocniczy obszar roboczy.
- Projekt synchronizacji usługi Databricks (DBSync) to narzędzie do synchronizacji obiektów, które tworzy kopię zapasową, przywraca i synchronizuje obszary robocze usługi Databricks.