Przekształcanie danych w chmurze za pomocą działania platformy Spark w usłudze Azure Data Factory
DOTYCZY:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym samouczku utworzysz potok usługi Azure Data Factory za pomocą witryny Azure Portal. Ten potok przekształca dane przy użyciu działania Spark i połączonej usługi Azure HDInsight dostępnej na żądanie.
Ten samouczek obejmuje następujące procedury:
- Tworzenie fabryki danych.
- Tworzenie potoku używającego działania platformy Spark.
- Wyzwalanie uruchomienia potoku.
- Monitorowanie uruchomienia potoku.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
Uwaga
Do interakcji z platformą Azure zalecamy używanie modułu Azure Az w programie PowerShell. Zobacz Instalowanie programu Azure PowerShell, aby rozpocząć. Aby dowiedzieć się, jak przeprowadzić migrację do modułu Az PowerShell, zobacz Migracja programu Azure PowerShell z modułu AzureRM do modułu Az.
- Konto usługi Azure Storage. Utworzysz skrypt w języku Python i plik wejściowy, a następnie przekażesz je do usługi Azure Storage. Dane wyjściowe programu platformy Spark są przechowywane na tym koncie magazynu. Klaster platformy Spark na żądanie używa tego samego konta magazynu, jako swojego podstawowego magazynu.
Uwaga
Usługa HdInsight obsługuje tylko konta magazynu ogólnego przeznaczenia w warstwie Standardowa. Upewnij się, że konto nie jest kontem magazynu w warstwie Premium ani kontem magazynu obsługującym tylko obiekty blob.
- Azure PowerShell. Wykonaj instrukcje podane w temacie Instalowanie i konfigurowanie programu Azure PowerShell.
Przekazywanie skryptu w języku Python do konta usługi Blob Storage
Utwórz plik w języku Python o nazwie WordCount_Spark.py i następującej zawartości:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()Zastąp wartość <storageAccountName> nazwą swojego konta usługi Azure Storage. Następnie zapisz plik.
W usłudze Azure Blob Storage utwórz kontener o nazwie adftutorial, jeśli nie istnieje.
Utwórz folder o nazwie spark.
Utwórz podfolder o nazwie script w folderze spark.
Przekaż plik WordCount_Spark.py do podfolderu script.
Przekazywanie pliku wejściowego
- Utwórz plik o nazwie minecraftstory.txt zawierający tekst. Program platformy Spark zlicza liczbę słów w tym tekście.
- Utwórz podfolder o nazwie inputfiles w folderze spark.
- Przekaż plik minecraftstory.txt do podfolderu inputfiles.
Tworzenie fabryki danych
Wykonaj kroki opisane w artykule Szybki start: tworzenie fabryki danych przy użyciu witryny Azure Portal w celu utworzenia fabryki danych, jeśli jeszcze nie masz z nim miejsca do pracy.
Tworzenie połączonych usług
W tej sekcji zredagujesz dwie połączone usługi:
- Połączoną usługę Azure Storage, która łączy konto usługi Azure Storage z fabryką danych. Ten magazyn jest używany przez klaster usługi HDInsight na żądanie. Zawiera on także skrypt platformy Spark do uruchomienia.
- Połączoną usługę HDInsight dostępną na żądanie. Usługa Azure Data Factory automatycznie tworzy klaster usługi HDInsight i uruchamia program platformy Spark. Następnie usuwa klaster usługi HDInsight, gdy jest on bezczynny przez wstępnie skonfigurowany czas.
Tworzenie połączonej usługi Azure Storage
Na stronie głównej przejdź do karty Zarządzanie w panelu po lewej stronie.
Wybierz pozycję Połączenia w dolnej części okna, a następnie wybierz pozycję + Nowy.
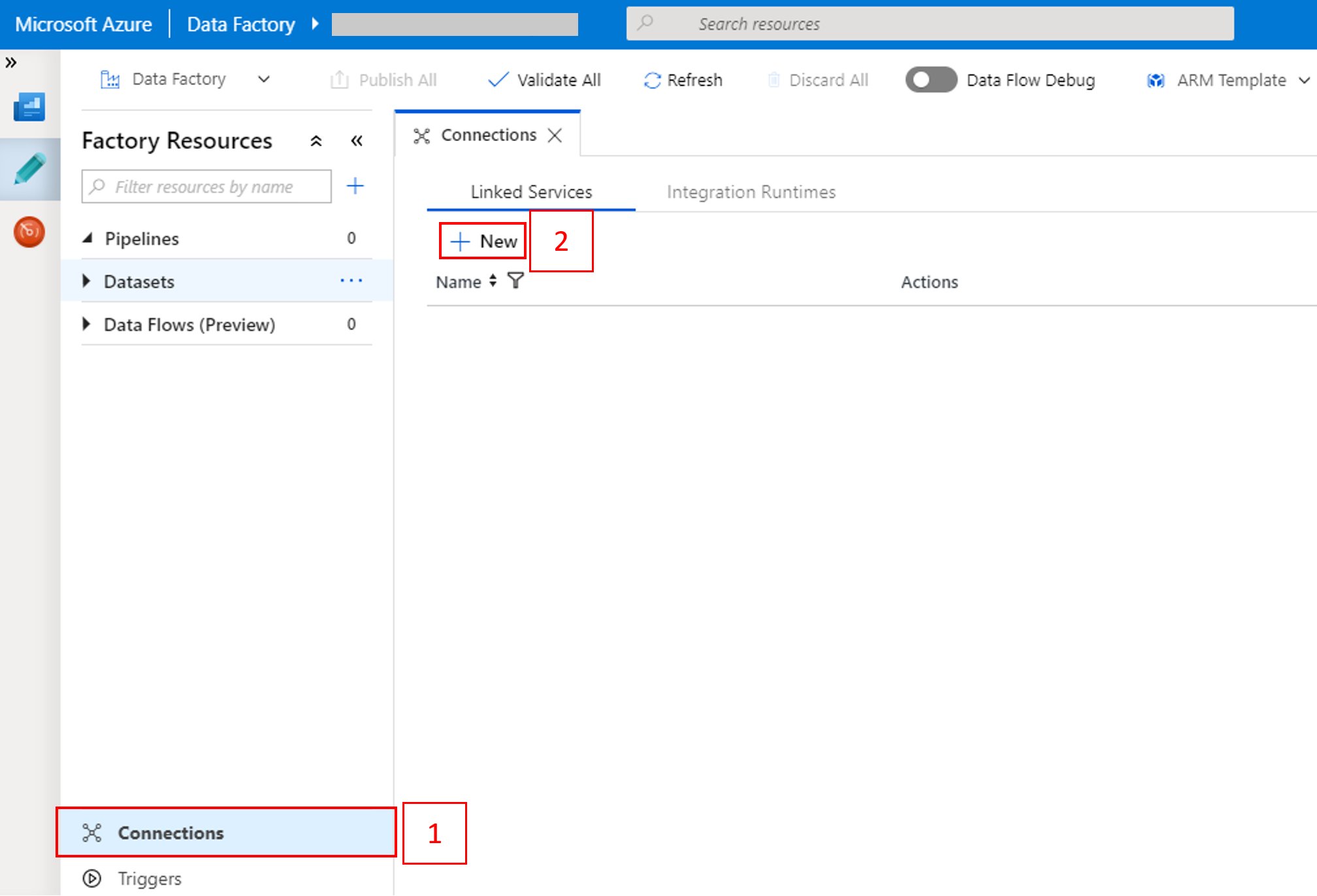
W oknie Nowa połączona usługa wybierz pozycje Magazyn danych>Azure Blob Storage, a następnie wybierz pozycję Kontynuuj.

W obszarze Nazwa konta magazynu wybierz nazwę z listy, a następnie wybierz pozycję Zapisz.
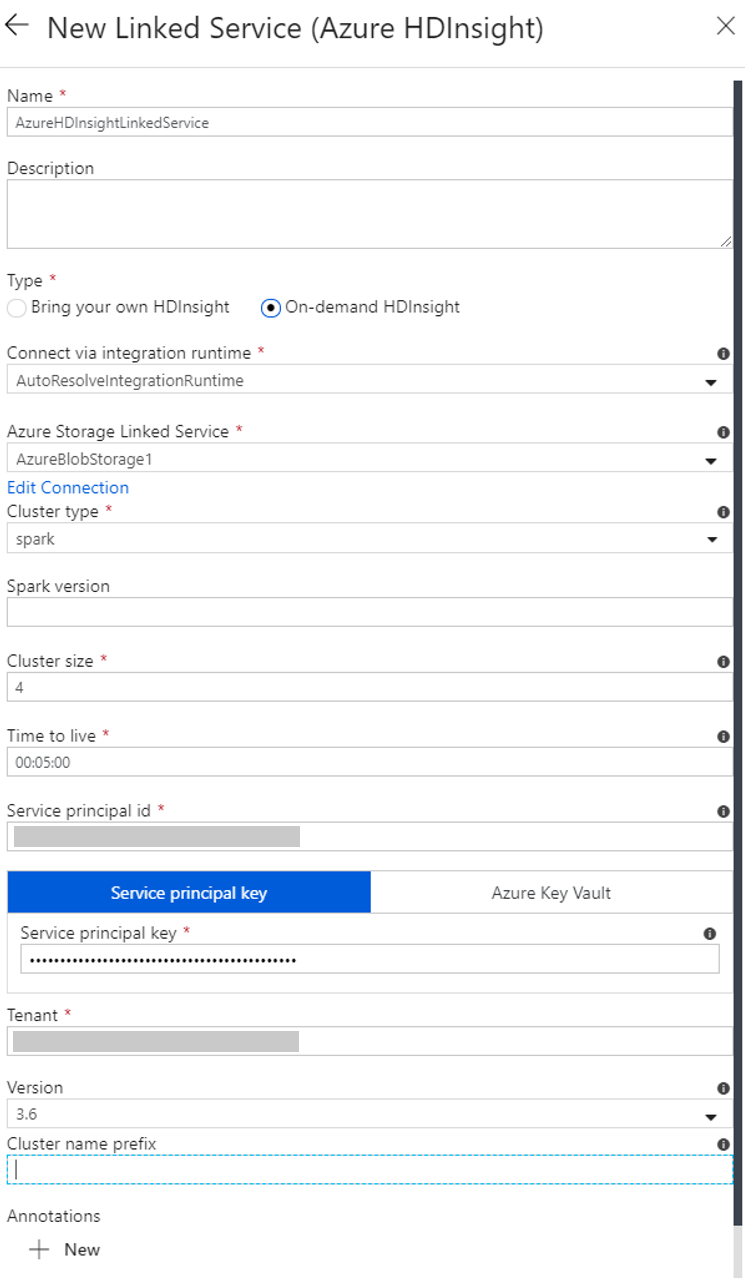
Tworzenie połączonej usługi HDInsight na żądanie
Wybierz ponownie przycisk + Nowy, aby utworzyć kolejną połączoną usługę.
W oknie Nowa połączona usługa wybierz kolejno pozycje Compute>Azure HDInsight, a następnie kliknij pozycję Kontynuuj.

W oknie Nowa połączona usługa wykonaj następujące czynności:
a. W polu Nazwa wprowadź ciąg AzureHDInsightLinkedService.
b. Upewnij się, że w polu Typ wybrano wartość HDInsight na żądanie.
c. W polu Połączona usługa Azure Storage wybierz pozycję AzureBlobStorage1. Ta połączona usługa została utworzona wcześniej. Jeśli użyto innej nazwy, podaj w tym miejscu prawidłową nazwę.
d. W polu Typ klastra wybierz wartość spark.
e. W polu Identyfikator jednostki usługi wprowadź identyfikator, który ma uprawnienia do tworzenia klastra usługi HDInsight.
Jednostka usługi musi być członkiem roli współautora subskrypcji lub grupy zasobów, gdzie został utworzony klaster. Aby uzyskać więcej informacji, zobacz Tworzenie aplikacji Microsoft Entra i jednostki usługi. Identyfikator jednostki usługi jest odpowiednikiem identyfikatora aplikacji, a klucz jednostki usługi jest odpowiednikiem wartości klucza tajnego klienta.
f. W polu Klucz jednostki usługi wprowadź klucz.
g. W polu Grupa zasobów wybierz tę samą grupę zasobów, która została użyta podczas tworzenia fabryki danych. W tej grupie zasobów jest tworzony klaster Spark.
h. Rozwiń węzeł Typ systemu operacyjnego.
i. Podaj nazwę w polu Nazwa użytkownika klastra.
j. Określ wartość pola Hasło klastra dla użytkownika.
k. Wybierz Zakończ.
Uwaga
Usługa Azure HDInsight ogranicza całkowitą liczbę rdzeni, których możesz użyć w każdym obsługiwanym przez nią regionie platformy Azure. Dla połączonej usługi HDInsight dostępnej na żądanie zostanie utworzony klaster usługi HDInsight w tej samej lokalizacji usługi Azure Storage użytej jako jej podstawowy magazyn. Upewnij się, że masz wystarczająco duże limity przydziału dla klastra, aby można go było pomyślnie utworzyć. Aby uzyskać więcej informacji, zobacz Set up clusters in HDInsight with Hadoop, Spark, Kafka and more (Konfigurowanie klastrów w usłudze HDInsight za pomocą platform Hadoop, Spark, Kafka i innych).
Tworzenie potoku
Wybierz przycisk + (znak plus), a następnie wybierz pozycję Potok w menu.
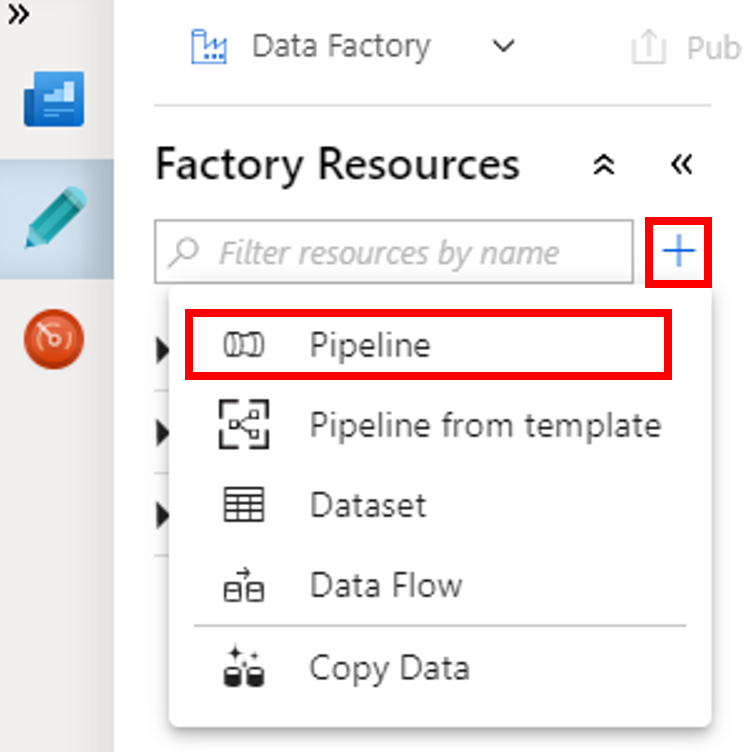
W przyborniku Działania rozwiń pozycję HDInsight. Przeciągnij działanie Spark z przybornika Działania na powierzchnię projektanta potoku.
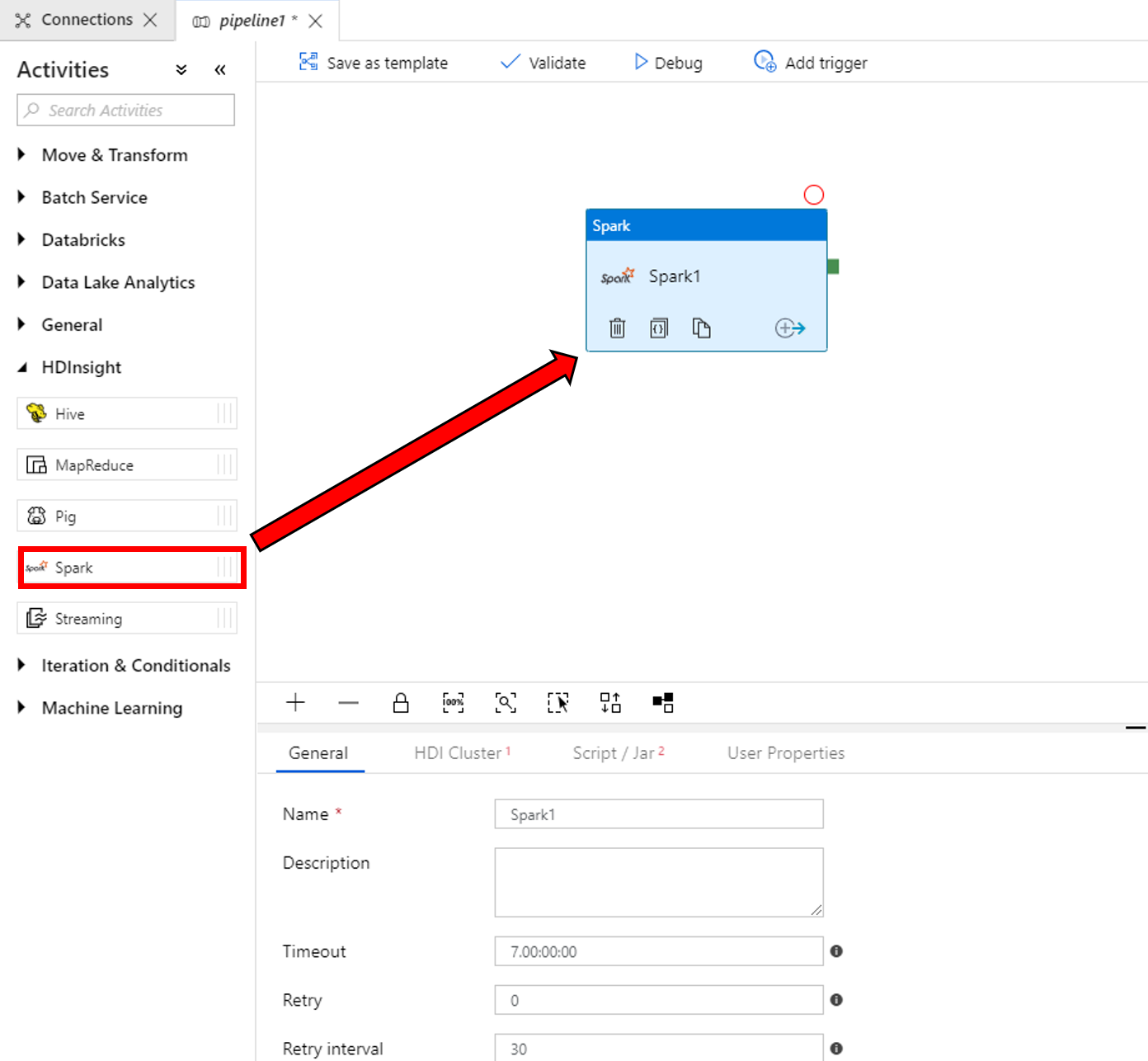
We właściwościach okna działania Spark u dołu wykonaj następujące czynności:
a. Przejdź do karty Klaster usługi HDI.
b. Wybierz usługę AzureHDInsightLinkedService (utworzoną w ramach poprzedniej procedury).
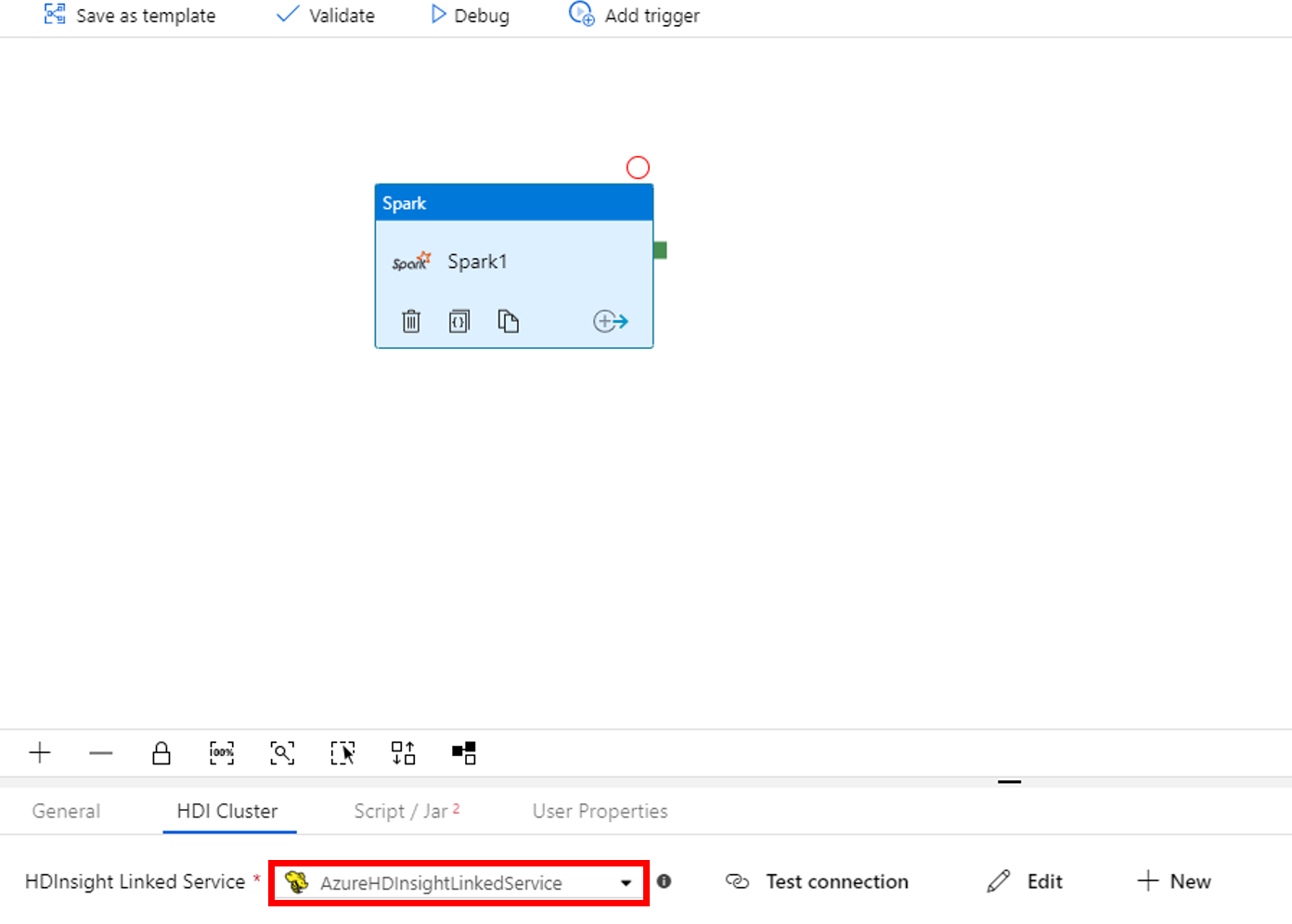
Przejdź do karty Skrypt/Jar i wykonaj następujące czynności:
a. W obszarze Połączona usługa zadań wybierz pozycję AzureBlobStorage1.
b. Wybierz pozycję Przeglądaj magazyn.

c. Przejdź do folderu adftutorial/spark/script, wybierz plik WordCount_Spark.py i wybierz pozycję Zakończ.
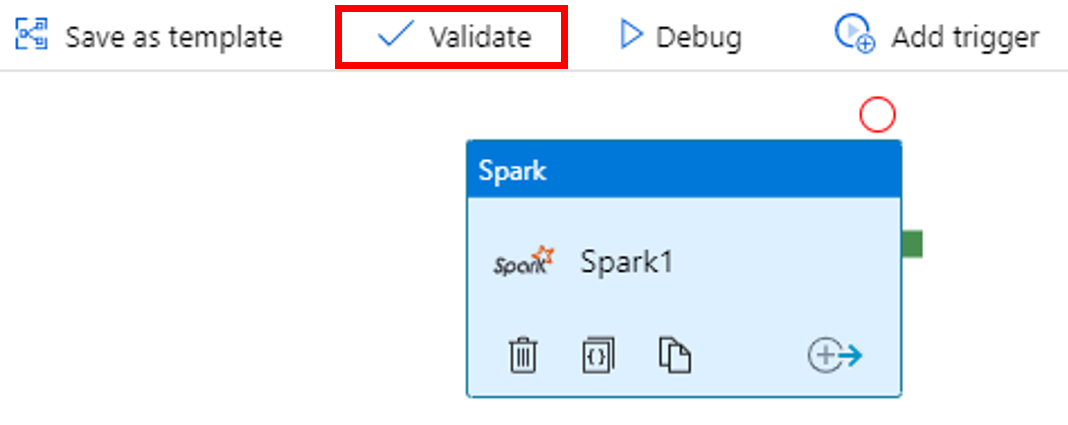
Aby zweryfikować potok, wybierz przycisk Weryfikuj na pasku narzędzi. Wybierz przycisk >> (strzałka w prawo), aby zamknąć okno weryfikacji.
Wybierz pozycję Opublikuj wszystkie. Interfejs użytkownika usługi Data Factory publikuje jednostki (połączone usług i potok) do usługi Azure Data Factory.
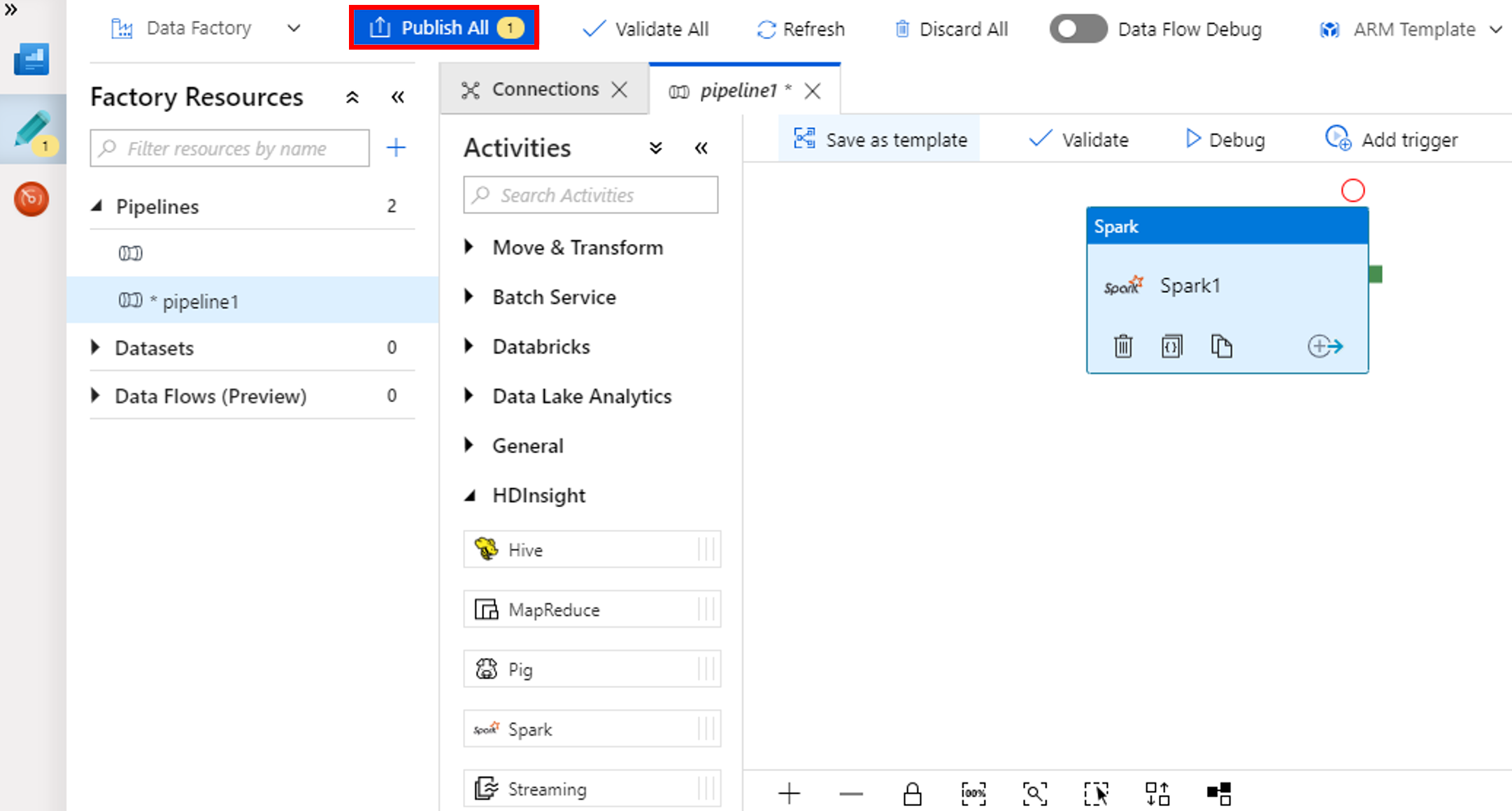
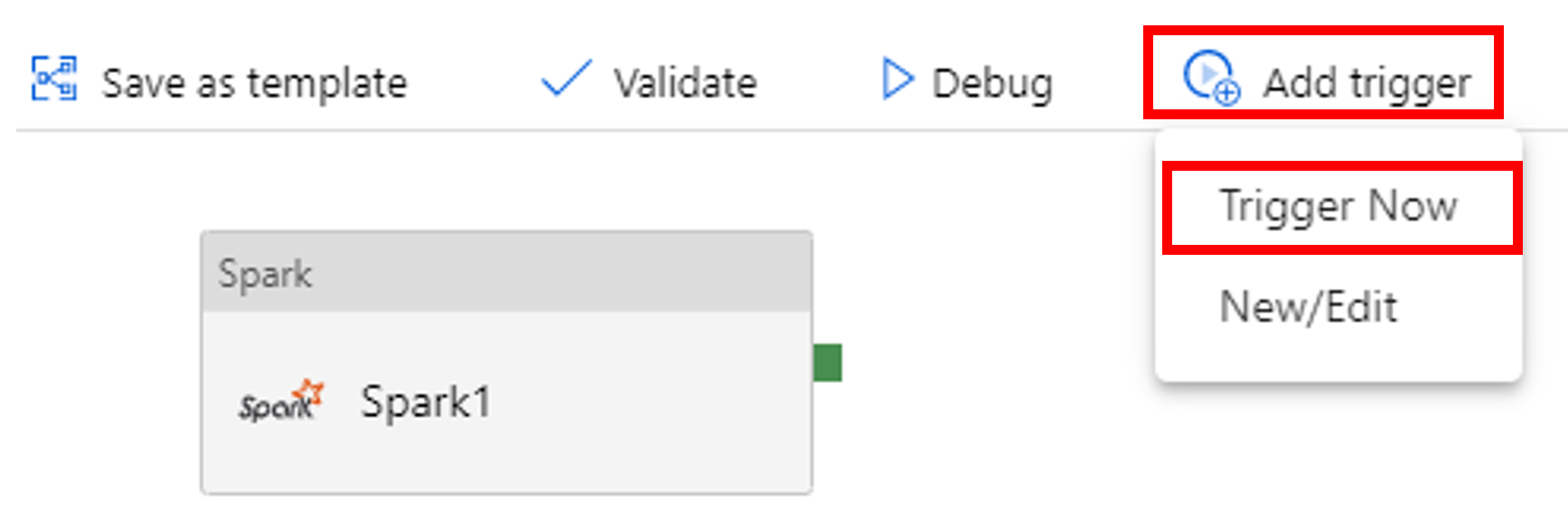
Wyzwalanie uruchomienia potoku
Wybierz pozycję Dodaj wyzwalacz na pasku narzędzi, a następnie wybierz pozycję Wyzwól teraz.
Monitorowanie działania potoku
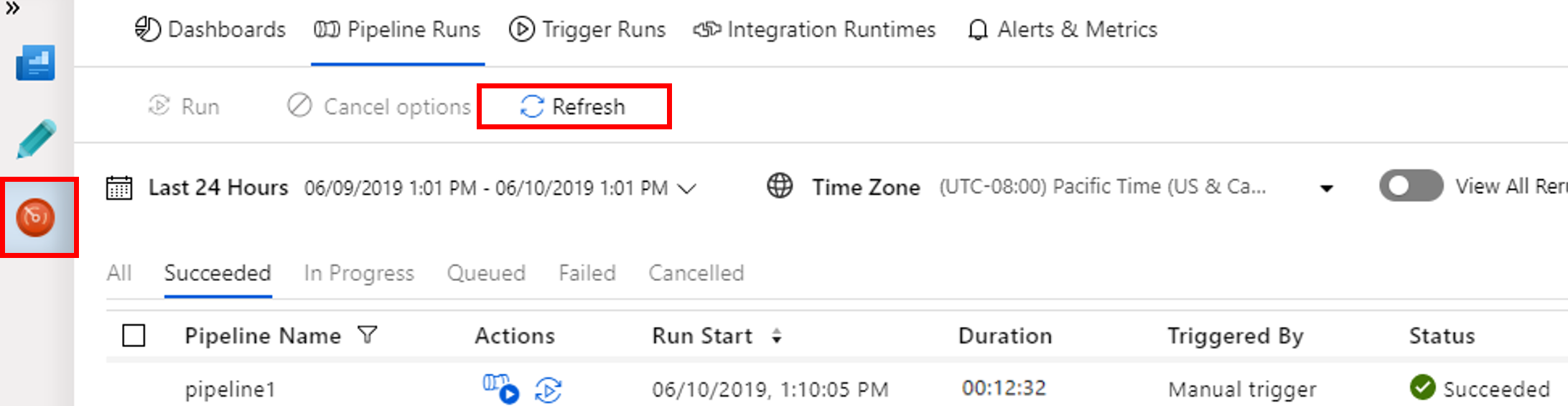
Przejdź do karty Monitorowanie . Upewnij się, że zostanie wyświetlony przebieg potoku. Utworzenie klastra Spark trwa około 20 minut.
Okresowo wybieraj pozycję Odśwież, aby sprawdzić stan uruchomienia potoku.
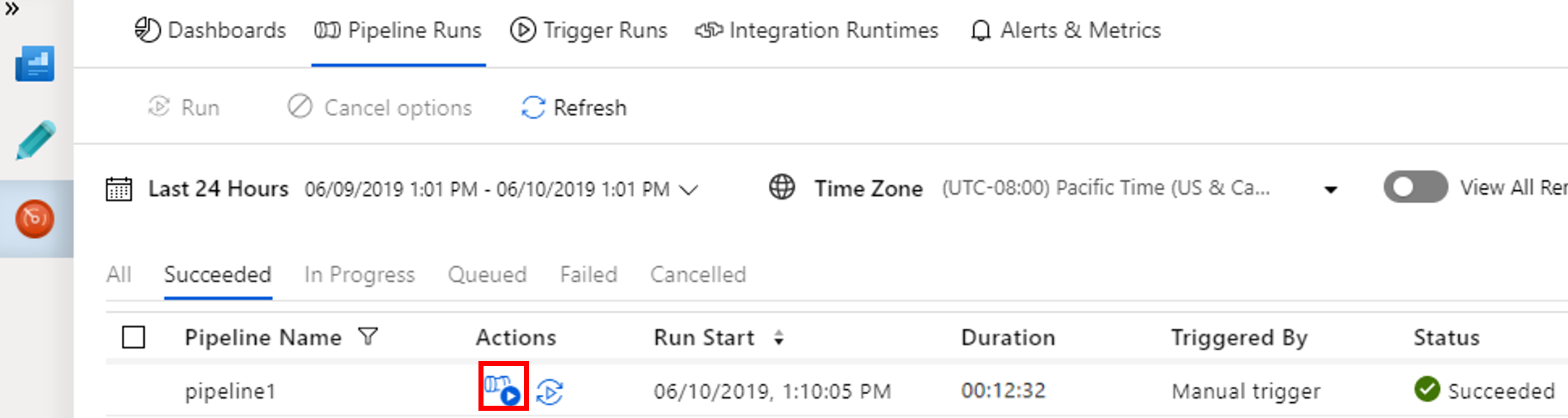
Aby wyświetlić uruchomienia działań skojarzone z uruchomieniem potoku, wybierz pozycję Wyświetl uruchomienia działań w kolumnie Akcje.
Możesz wrócić do widoku przebiegów potoku, wybierając link Wszystkie uruchomienia potoku u góry.
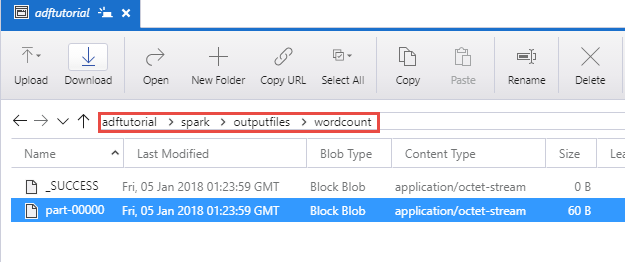
Sprawdzanie danych wyjściowych
Sprawdź, czy plik wyjściowy został utworzony w folderze spark/otuputfiles/wordcount kontenera adftutorial.
Ten plik powinien zawierać każdy wyraz z wejściowego pliku tekstowego oraz liczbę powtórzeń wyrazu w pliku. Na przykład:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
Powiązana zawartość
Potok w tym przykładzie przekształca dane przy użyciu działania Spark i połączonej usługi HDInsight dostępnej na żądanie. W tym samouczku omówiono:
- Tworzenie fabryki danych.
- Tworzenie potoku używającego działania platformy Spark.
- Wyzwalanie uruchomienia potoku.
- Monitorowanie uruchomienia potoku.
Aby dowiedzieć się, jak przekształcać dane, uruchamiając skrypt programu Hive w klastrze usługi Azure HDInsight, który znajduje się w sieci wirtualnej, przejdź do następnego samouczka: