Przyrostowe ładowanie danych z usługi Azure SQL Managed Instance do usługi Azure Storage przy użyciu przechwytywania zmian (CDC)
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym samouczku utworzysz fabrykę danych Platformy Azure z potokiem, który ładuje dane różnicowe na podstawie informacji przechwytywania zmian (CDC) w źródłowej bazie danych usługi Azure SQL Managed Instance do usługi Azure Blob Storage.
Ten samouczek obejmuje następujące procedury:
- Przygotowywanie magazynu danych źródłowych
- Tworzenie fabryki danych.
- Tworzenie połączonych usług.
- Tworzenie zestawu danych źródła i ujścia.
- Tworzenie, debugowanie i uruchamianie potoku w celu sprawdzenia, czy nie zmieniono danych
- Modyfikowanie danych w tabeli źródłowej
- Ukończ, uruchom i monitoruj pełny potok kopiowania przyrostowego
Omówienie
Technologia przechwytywania zmian danych obsługiwana przez magazyny danych, takie jak wystąpienia zarządzane Azure SQL (MI) i program SQL Server, mogą służyć do identyfikowania zmienionych danych. W tym samouczku opisano sposób używania usługi Azure Data Factory z technologią przechwytywania zmian danych SQL w celu przyrostowego ładowania danych różnicowych z usługi Azure SQL Managed Instance do usługi Azure Blob Storage. Aby uzyskać bardziej szczegółowe informacje na temat technologii przechwytywania zmian danych SQL, zobacz Przechwytywanie zmian danych w programie SQL Server.
Kompletny przepływ pracy
Poniżej przedstawiono typowe kompleksowe kroki przepływu pracy umożliwiające przyrostowe ładowanie danych przy użyciu technologii Change Data Capture.
Uwaga
Zarówno usługa Azure SQL MI, jak i program SQL Server obsługują technologię Change Data Capture. W tym samouczku jako źródłowy magazyn danych jest używany usługa Azure SQL Managed Instance. Możesz również użyć lokalnego serwera SQL Server.
Rozwiązanie ogólne
W tym samouczku utworzysz potok, który wykonuje następujące operacje:
- Utwórz działanie wyszukiwania, aby zliczyć liczbę zmienionych rekordów w tabeli CDC usługi SQL Database i przekazać je do działania WARUNEK IF.
- Utwórz warunek if, aby sprawdzić, czy istnieją zmienione rekordy i jeśli tak, wywołaj działanie kopiowania.
- Utwórz działanie kopiowania, aby skopiować wstawione/zaktualizowane/usunięte dane między tabelą CDC do usługi Azure Blob Storage.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
- Azure SQL Managed Instance. Baza danych jest używana jako magazyn danych źródłowych. Jeśli nie masz wystąpienia zarządzanego Usługi Azure SQL, zobacz artykuł Tworzenie wystąpienia zarządzanego usługi Azure SQL Database, aby uzyskać instrukcje tworzenia wystąpienia zarządzanego.
- Konto usługi Azure Storage. Magazyn obiektów blob jest używany jako magazyn danych źródłowych. Jeśli nie masz konta usługi Azure Storage, utwórz je, wykonując czynności przedstawione w artykule Tworzenie konta magazynu. Utwórz kontener o nazwie raw.
Tworzenie tabeli źródła danych w usłudze Azure SQL Database
Uruchom program SQL Server Management Studio i połącz się z serwerem usługi Azure SQL Managed Instances.
W Eksploratorze serwera kliknij prawym przyciskiem używaną bazę danych, a następnie wybierz pozycję Nowe zapytanie.
Uruchom następujące polecenie SQL względem bazy danych usługi Azure SQL Managed Instances, aby utworzyć tabelę o nazwie
customersjako magazyn źródeł danych.create table customers ( customer_id int, first_name varchar(50), last_name varchar(50), email varchar(100), city varchar(50), CONSTRAINT "PK_Customers" PRIMARY KEY CLUSTERED ("customer_id") );Włącz mechanizm przechwytywania zmian danych w bazie danych i tabeli źródłowej (klientów), uruchamiając następujące zapytanie SQL:
Uwaga
- Zastąp <nazwę> schematu źródłowego schematem wystąpienia zarządzanego usługi Azure SQL, który zawiera tabelę klientów.
- Przechwytywanie zmian danych nie wykonuje żadnych czynności w ramach transakcji, które zmieniają śledzone tabele. Zamiast tego operacje wstawiania, aktualizowania i usuwania są zapisywane w dzienniku transakcji. Dane, które są zdeponowane w tabelach zmian, staną się niezarządzane, jeśli dane nie będą okresowo i systematycznie czyszczone. Aby uzyskać więcej informacji, zobacz Włączanie przechwytywania zmian danych dla bazy danych
EXEC sys.sp_cdc_enable_db EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 1Wstaw dane do tabeli customers, uruchamiając następujące polecenie:
insert into customers (customer_id, first_name, last_name, email, city) values (1, 'Chevy', 'Leward', 'cleward0@mapy.cz', 'Reading'), (2, 'Sayre', 'Ateggart', 'sateggart1@nih.gov', 'Portsmouth'), (3, 'Nathalia', 'Seckom', 'nseckom2@blogger.com', 'Portsmouth');Uwaga
Żadne historyczne zmiany w tabeli nie są przechwytywane przed włączeniem przechwytywania zmian danych.
Tworzenie fabryki danych
Wykonaj kroki opisane w artykule Szybki start: tworzenie fabryki danych przy użyciu witryny Azure Portal w celu utworzenia fabryki danych, jeśli jeszcze nie masz z nim miejsca do pracy.
Tworzenie połączonych usług
Połączone usługi tworzy się w fabryce danych w celu połączenia magazynów danych i usług obliczeniowych z fabryką danych. W tej sekcji utworzysz połączone usługi z kontem usługi Azure Storage i wystąpieniem mi usługi Azure SQL.
Utwórz połączoną usługę Azure Storage.
W tym kroku opisano łączenie konta usługi Azure Storage z fabryką danych.
Kliknij kolejno pozycje Połączenia i + Nowy.
W oknie Nowa połączona usługa wybierz pozycję Azure Blob Storage, a następnie kliknij pozycję Kontynuuj.
W oknie Nowa połączona usługa wykonaj następujące czynności:
- Wprowadź wartość AzureStorageLinkedService w polu Nazwa.
- W polu Nazwa konta magazynu wybierz konto usługi Azure Storage.
- Kliknij przycisk Zapisz.
Tworzenie połączonej usługi Azure SQL MI Database.
W tym kroku połączysz bazę danych usługi Azure SQL MI Database z fabryką danych.
Uwaga
W przypadku użytkowników korzystających z wystąpienia zarządzanego SQL zobacz tutaj , aby uzyskać informacje dotyczące dostępu za pośrednictwem publicznego i prywatnego punktu końcowego. Jeśli używasz prywatnego punktu końcowego, należy uruchomić ten potok przy użyciu własnego środowiska Integration Runtime. To samo dotyczyłoby tych, którzy uruchamiają lokalnie program SQL Server na maszynie wirtualnej lub w scenariuszach sieci wirtualnej.
Kliknij kolejno pozycje Połączenia i + Nowy.
W oknie Nowa połączona usługa wybierz pozycję Wystąpienie zarządzane usługi Azure SQL Database, a następnie kliknij przycisk Kontynuuj.
W oknie Nowa połączona usługa wykonaj następujące czynności:
- Wprowadź wartość AzureSqlMI1 w polu Nazwa .
- Wybierz serwer SQL w polu Nazwa serwera.
- Wybierz bazę danych SQL dla pola Nazwa bazy danych.
- W polu Nazwa użytkownika podaj nazwę użytkownika.
- W polu Hasło podaj hasło użytkownika.
- Kliknij pozycję Testuj połączenie w celu przetestowania połączenia.
- Kliknij przycisk Zapisz, aby zapisać połączoną usługę.
Tworzenie zestawów danych
W tym kroku utworzysz zestawy danych reprezentujące źródło danych i miejsce docelowe danych.
Tworzenie zestawu danych reprezentującego źródło danych
W tym kroku utworzysz zestaw danych reprezentujący źródło danych.
W widoku drzewa kliknij kolejno pozycje + (plus) i Zestaw danych.
Wybierz pozycję Wystąpienie zarządzane usługi Azure SQL Database, a następnie kliknij przycisk Kontynuuj.
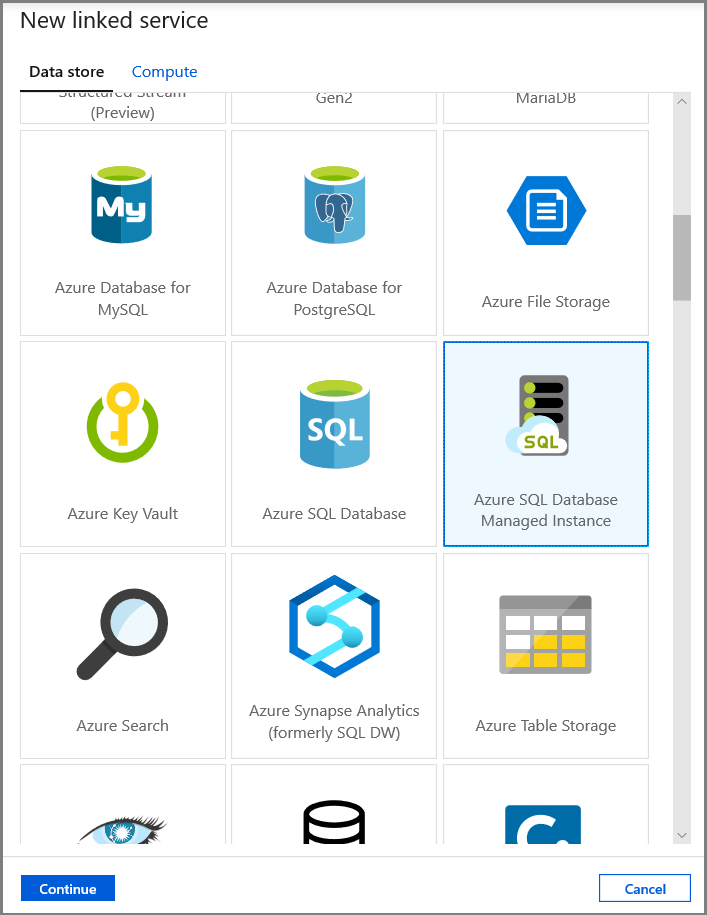
Na karcie Ustawianie właściwości ustaw nazwę zestawu danych i informacje o połączeniu:
- Wybierz pozycję AzureSqlMI1 dla pozycji Połączona usługa.
- Wybierz pozycję [dbo].[ dbo_customers_CT] w polu Nazwa tabeli. Uwaga: ta tabela została utworzona automatycznie, gdy usługa CDC została włączona w tabeli customers. Zmienione dane nigdy nie są odpytywane bezpośrednio z tej tabeli, ale zamiast tego są wyodrębniane za pośrednictwem funkcji CDC.
Utwórz zestaw danych reprezentujący dane skopiowane do magazynu danych będącego ujściem.
W tym kroku utworzysz zestaw danych reprezentujący dane skopiowane z magazynu danych źródłowych. Kontener data lake został utworzony w usłudze Azure Blob Storage w ramach wymagań wstępnych. Utwórz kontener, jeśli nie istnieje, lub zmień nazwę istniejącego kontenera. W tym samouczku nazwa pliku wyjściowego jest generowana dynamicznie przy użyciu czasu wyzwalacza, który zostanie skonfigurowany później.
W widoku drzewa kliknij kolejno pozycje + (plus) i Zestaw danych.
Wybierz pozycję Azure Blob Storage, a następnie kliknij przycisk Kontynuuj.

Wybierz pozycję RozdzielanyTekst, a następnie kliknij przycisk Kontynuuj.

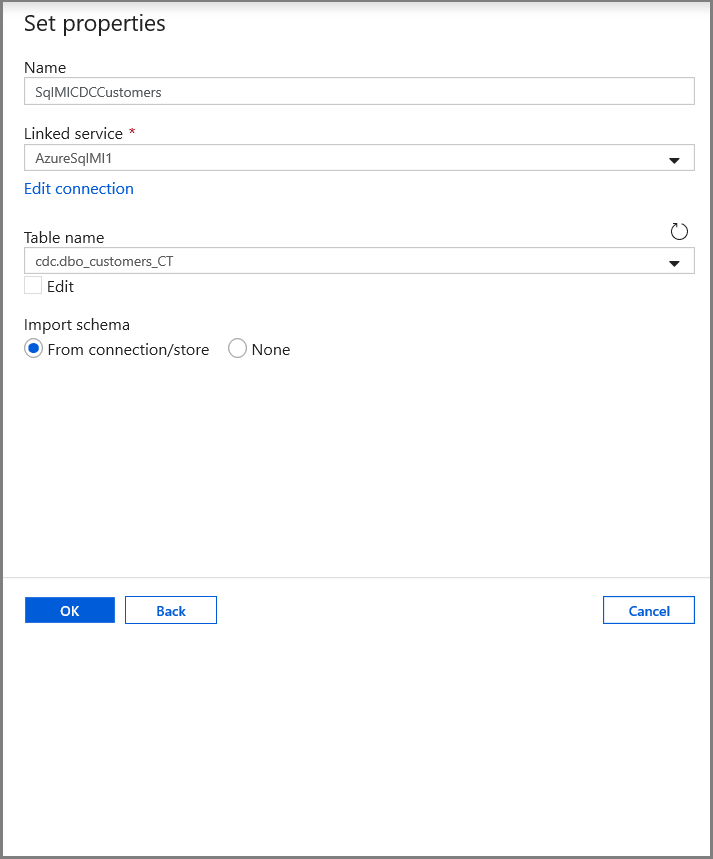
Na karcie Ustaw właściwości ustaw nazwę zestawu danych i informacje o połączeniu:
- Wybierz pozycję AzureStorageLinkedService w polu Połączona usługa.
- Wprowadź wartość raw dla części kontenera filePath.
- Włącz pierwszy wiersz jako nagłówek
- Kliknij przycisk OK.
Tworzenie potoku w celu skopiowania zmienionych danych
W tym kroku utworzysz potok, który najpierw sprawdza liczbę zmienionych rekordów znajdujących się w tabeli zmian przy użyciu działania odnośnika. Działanie warunku IF sprawdza, czy liczba zmienionych rekordów jest większa niż zero i uruchamia działanie kopiowania w celu skopiowania wstawionych/zaktualizowanych/usuniętych danych z usługi Azure SQL Database do usługi Azure Blob Storage. Na koniec skonfigurowano wyzwalacz okna wirowania, a czasy rozpoczęcia i zakończenia zostaną przekazane do działań jako parametrów okna początkowego i końcowego.
W interfejsie użytkownika usługi Data Factory przejdź do karty Edycja . Kliknij pozycję + (plus) w okienku po lewej stronie, a następnie kliknij pozycję Potok.
Zostanie wyświetlona nowa karta służąca do konfigurowania potoku. Potok powinien być też widoczny w widoku drzewa. W oknie Właściwości zmień nazwę potoku na IncrementalCopyPipeline.
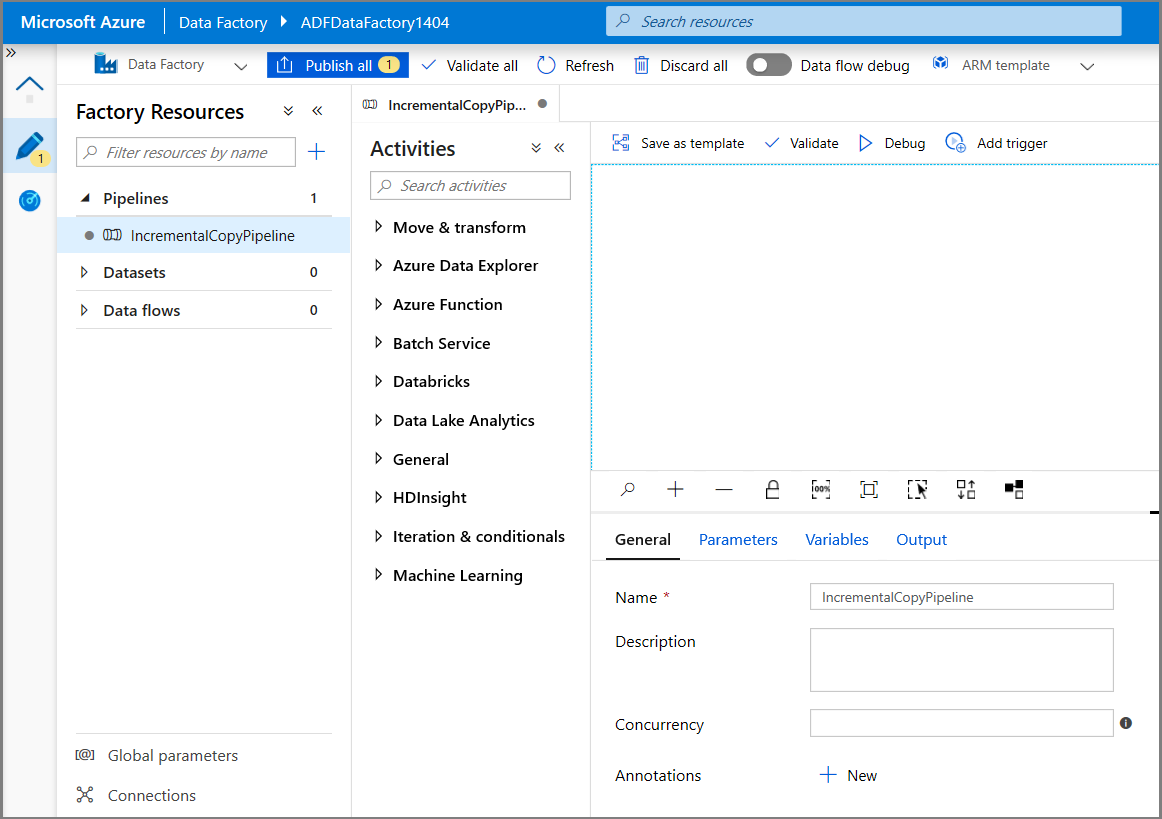
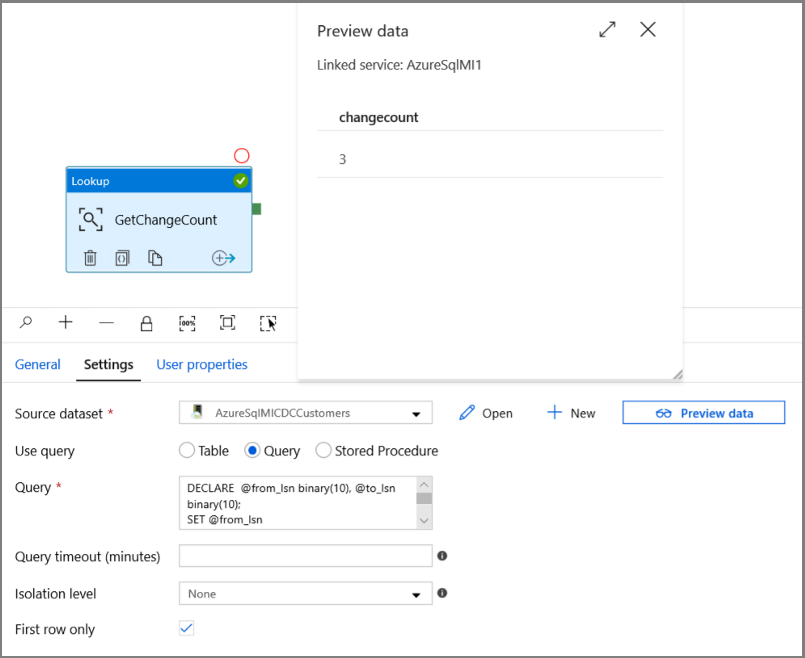
W przyborniku Działania rozwiń pozycję Ogólne, a następnie przeciągnij działanie Lookup (Wyszukiwanie) i upuść je na powierzchni projektanta potoku. Ustaw nazwę działania na GetChangeCount. To działanie pobiera liczbę rekordów w tabeli zmian dla danego przedziału czasu.
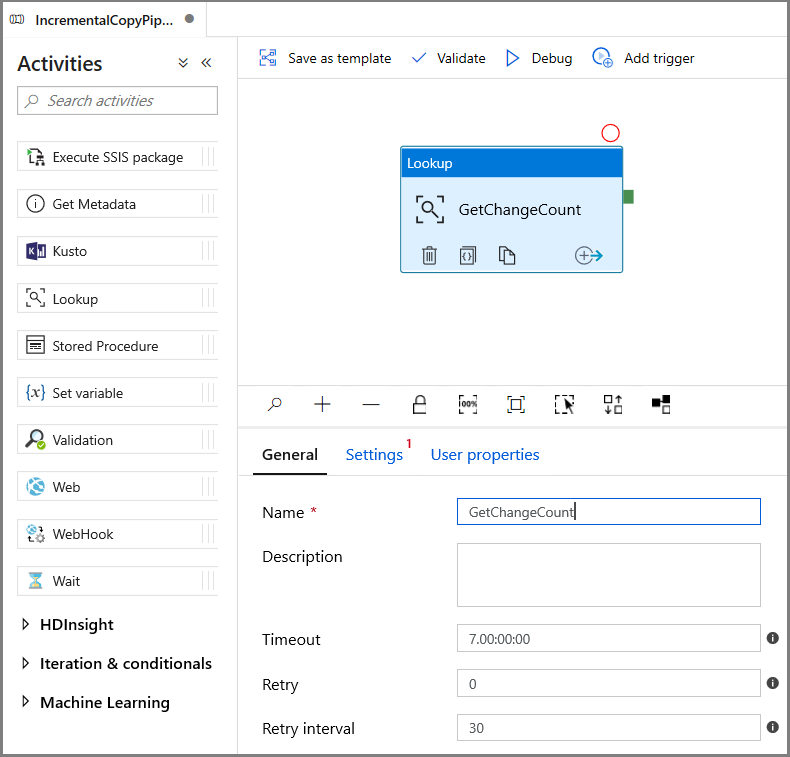
Przejdź do ustawień w oknie Właściwości :
Określ nazwę zestawu danych wystąpienia zarządzanego SQL dla pola Źródłowy zestaw danych .
Wybierz opcję Zapytanie i wprowadź następujące informacje w polu zapytania:
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')- Włącz tylko pierwszy wiersz
Kliknij przycisk Podgląd danych, aby upewnić się, że prawidłowe dane wyjściowe są uzyskiwane przez działanie wyszukiwania
Rozwiń węzeł Iteracja i warunkowe w przyborniku Działania , a następnie przeciągnij i upuść działanie Jeśli warunek na powierzchni projektanta potoku. Ustaw nazwę działania na HasChangedRows.
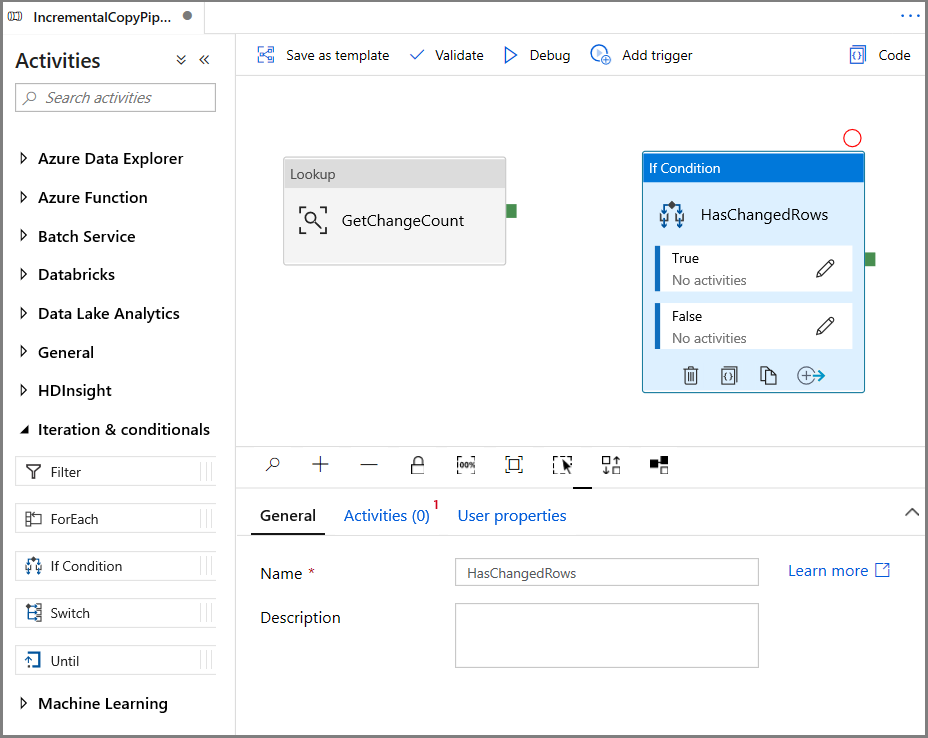
Przejdź do działań w oknie Właściwości :
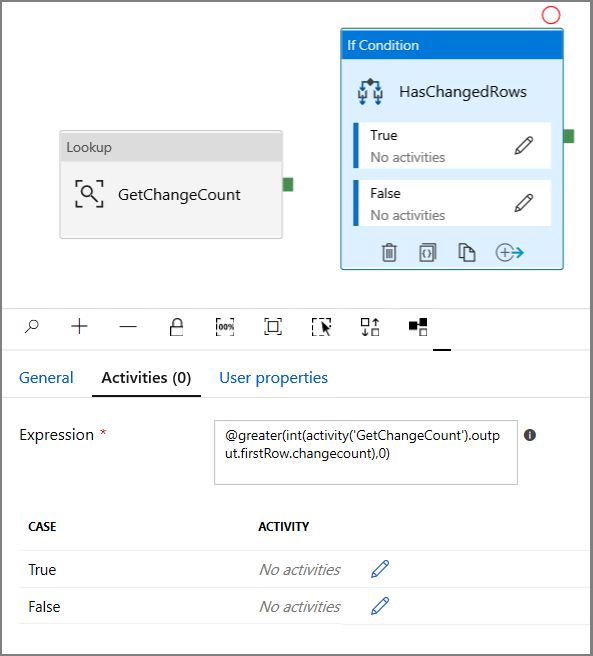
- Wprowadź następujące wyrażenie
@greater(int(activity('GetChangeCount').output.firstRow.changecount),0)- Kliknij ikonę ołówka, aby edytować warunek True.
- Rozwiń pozycję Ogólne w przyborniku Działania i przeciągnij i upuść działanie Wait na powierzchnię projektanta potoku. Jest to tymczasowe działanie w celu debugowania warunku If i zostanie zmienione w dalszej części samouczka.
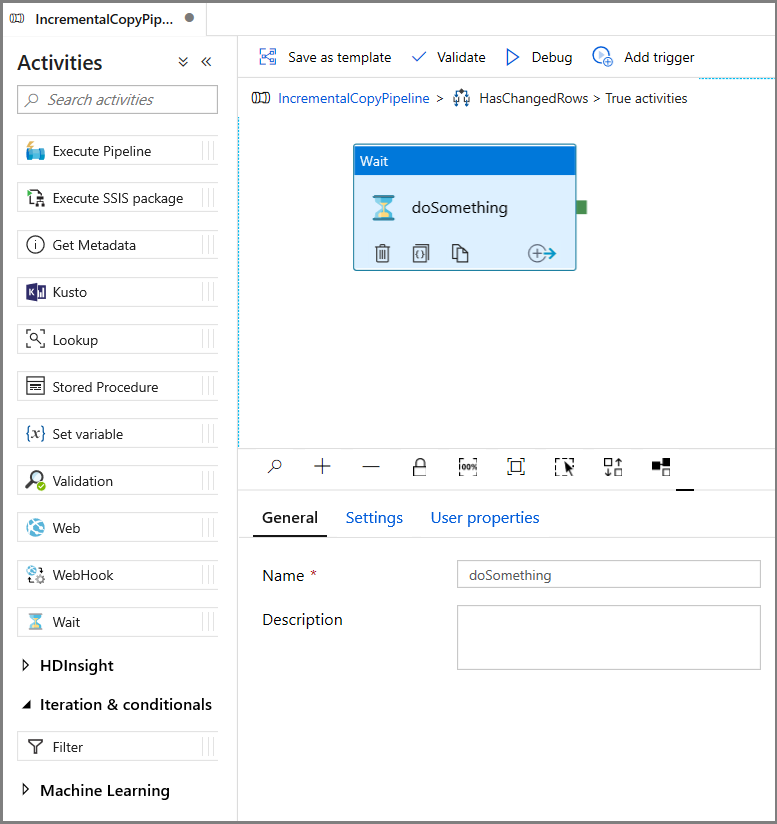
- Kliknij link Do stron nadrzędnych IncrementalCopyPipeline, aby powrócić do głównego potoku.
Uruchom potok w trybie debugowania , aby sprawdzić, czy potok zostanie wykonany pomyślnie.
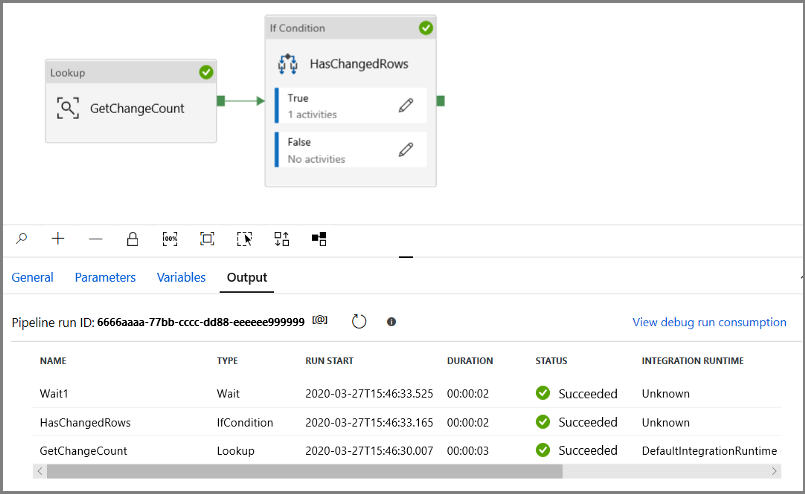
Następnie wróć do kroku True condition (Prawda) i usuń działanie Wait (Oczekiwanie). W przyborniku Działania rozwiń pozycję Przenieś i przekształć, a następnie przeciągnij i upuść działanie Kopiuj na powierzchnię projektanta potoku. Ustaw nazwę działania na IncrementalCopyActivity.
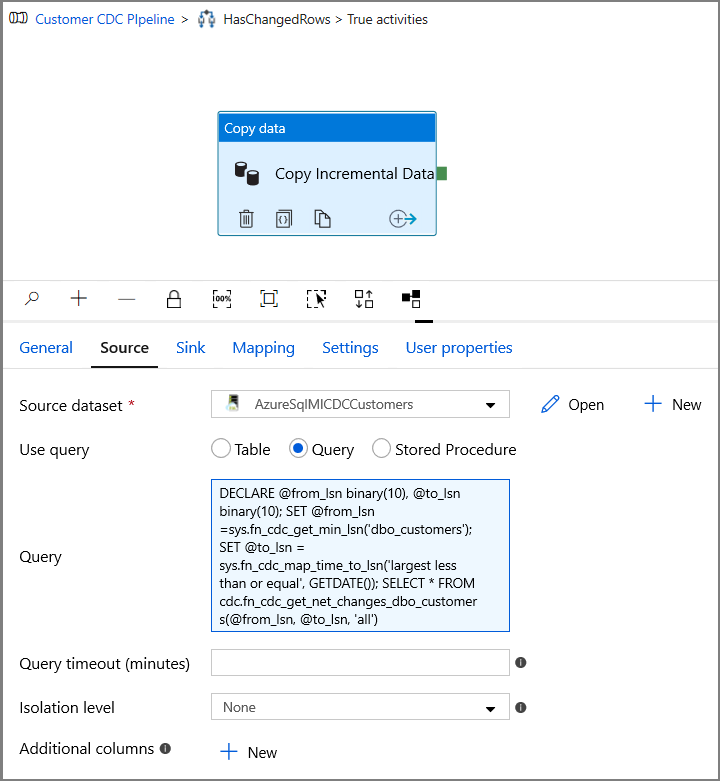
Przejdź do karty Źródło w oknie Właściwości i wykonaj następujące czynności:
Określ nazwę zestawu danych wystąpienia zarządzanego SQL dla pola Źródłowy zestaw danych .
Wybierz pozycję Zapytanie w polu Użyj zapytania.
Wprowadź następujące polecenie w polu Zapytanie.
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')
Kliknij pozycję Podgląd, aby sprawdzić, czy zapytanie zwraca poprawnie zmienione wiersze.
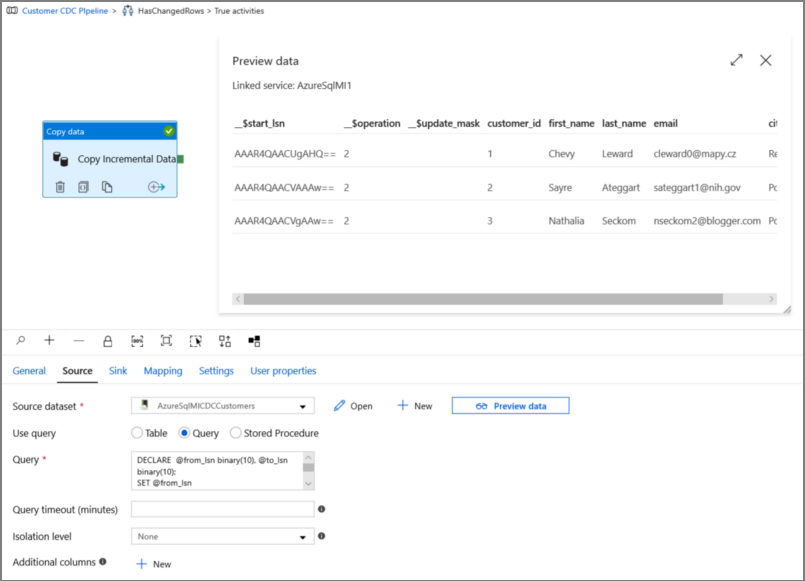
Przejdź do karty Ujście i określ zestaw danych usługi Azure Storage dla pola Zestaw danych ujścia.

Kliknij z powrotem na główną kanwę potoku i połącz działanie Lookup z działaniem If Condition jeden po drugim. Przeciągnij zielony przycisk dołączony do działania Lookup (Wyszukiwanie) do działania If Condition (Warunek if).
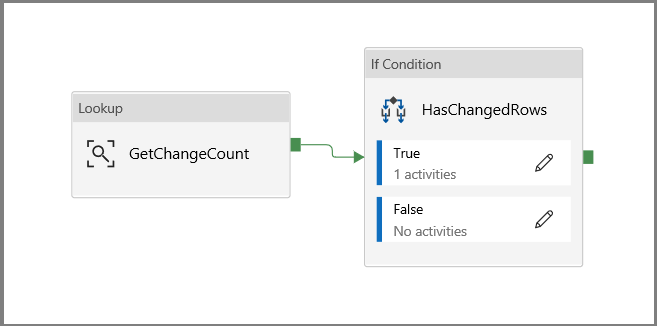
Na pasku narzędzi kliknij pozycję Weryfikuj. Potwierdź, że weryfikacja nie zwróciła błędów. Zamknij okno Raport weryfikacji potoku, klikając pozycję >>.
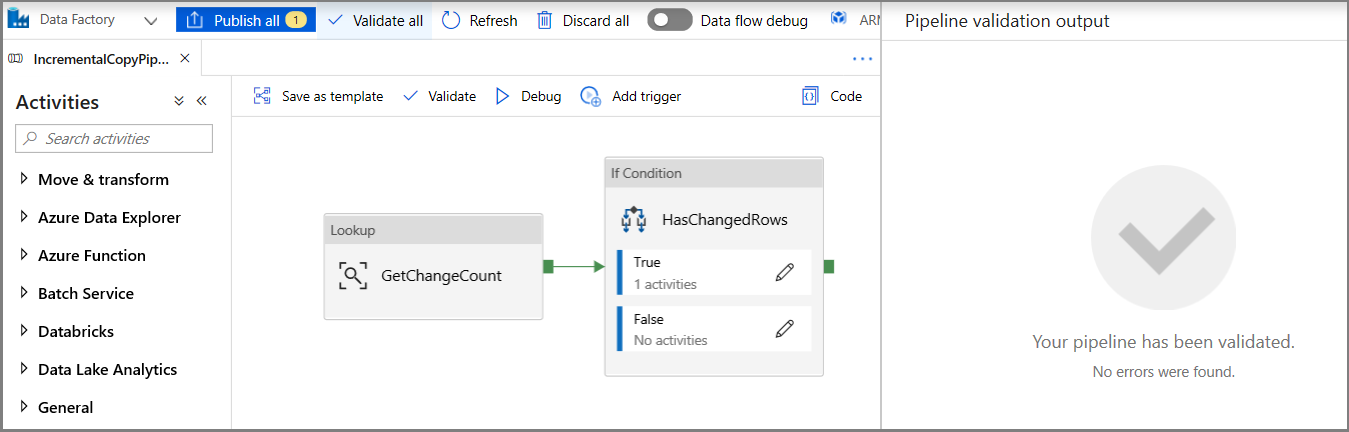
Kliknij pozycję Debuguj, aby przetestować potok i sprawdzić, czy plik jest generowany w lokalizacji magazynu.
Opublikuj jednostki (połączone usługi, zestawy danych i potoki) w usłudze Data Factory, klikając przycisk Opublikuj wszystko . Poczekaj na wyświetlenie komunikatu Publikowanie powiodło się.
Konfigurowanie wyzwalacza okna wirowania i parametrów okna CDC
W tym kroku utworzysz wyzwalacz okna wirowania, aby uruchomić zadanie zgodnie z częstym harmonogramem. Użyjesz zmiennych systemowych WindowStart i WindowEnd wyzwalacza okna wirowania i przekażesz je jako parametry do potoku do użycia w zapytaniu CDC.
Przejdź do karty Parametry potoku IncrementalCopyPipeline i użyj przycisku + Nowy dodaj dwa parametry (triggerStartTime i triggerEndTime) do potoku, co będzie reprezentować czas rozpoczęcia i zakończenia okna wirowania. Do celów debugowania dodaj wartości domyślne w formacie RRRR-MM-DD HH24:MI:SS.FFF , ale upewnij się, że wyzwalaczStartTime nie jest wcześniej włączony w tabeli, w przeciwnym razie spowoduje to błąd.
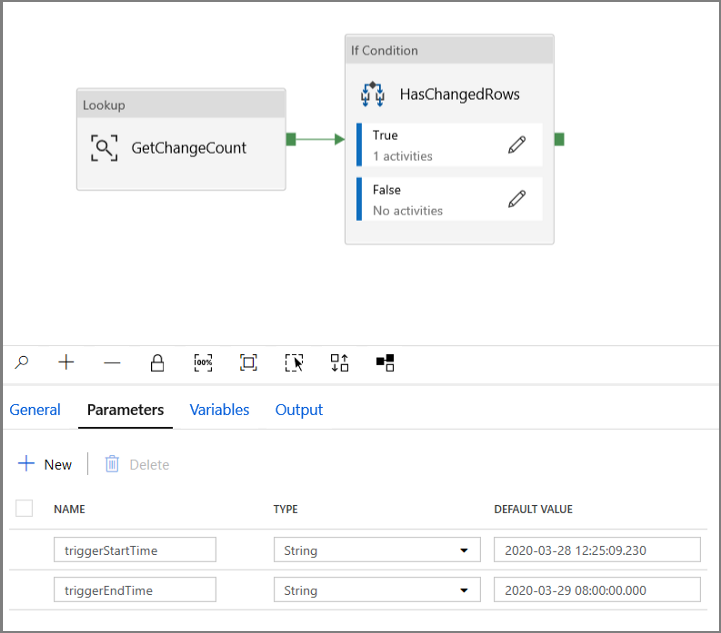
Kliknij kartę ustawień działania Lookup i skonfiguruj zapytanie tak, aby używało parametrów początkowych i końcowych. Skopiuj następujące elementy do zapytania:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Przejdź do działania Kopiuj w true przypadku działania If Condition i kliknij kartę Źródło . Skopiuj następujące elementy do kwerendy:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Kliknij kartę Ujście działania Kopiowania i kliknij przycisk Otwórz, aby edytować właściwości zestawu danych. Kliknij kartę Parametry i dodaj nowy parametr o nazwie triggerStart
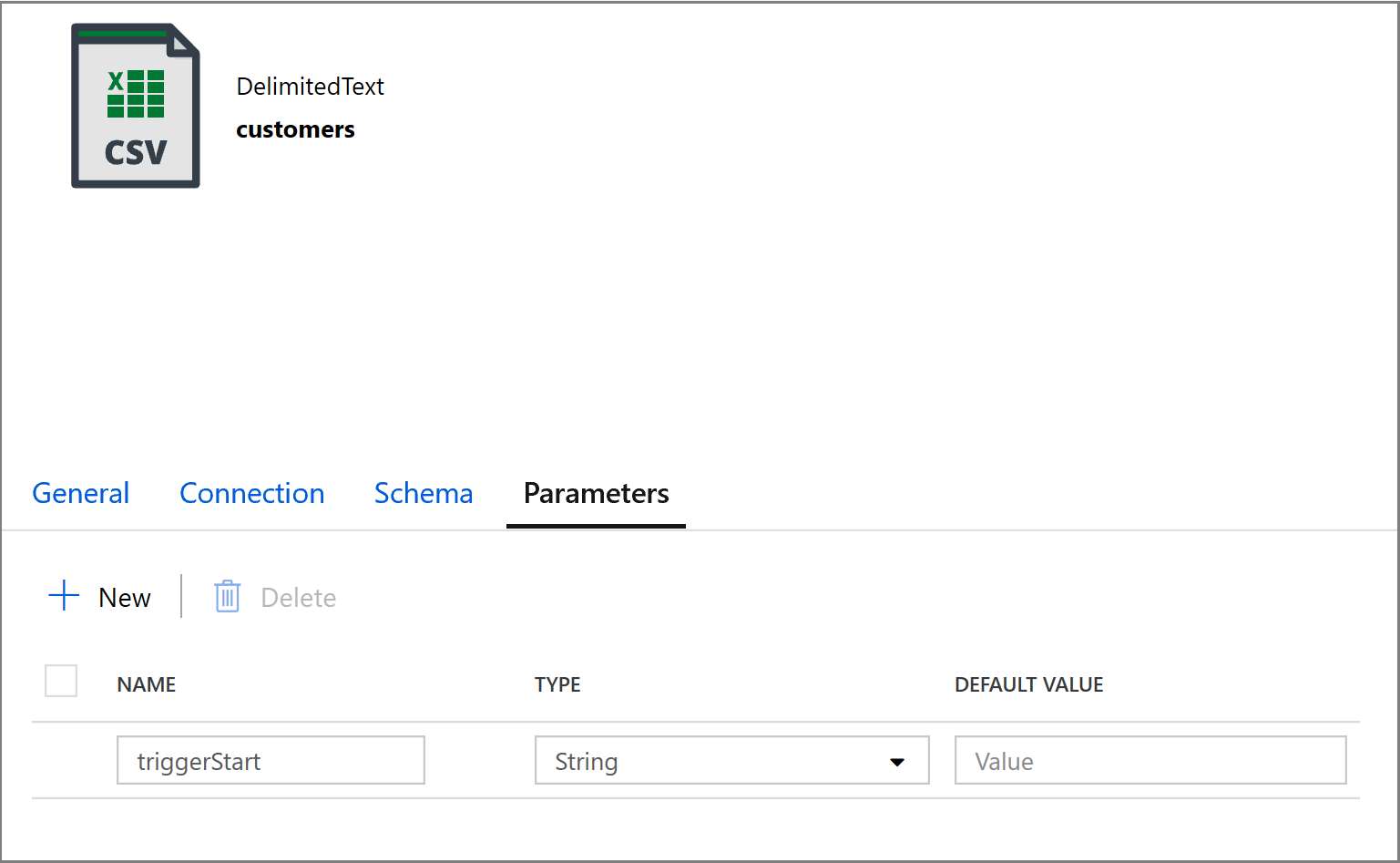
Następnie skonfiguruj właściwości zestawu danych, aby przechowywać dane w podkatalogu klientów/przyrostowych z partycjami opartymi na datach.
Kliknij kartę Połączenie właściwości zestawu danych i dodaj zawartość dynamiczną dla sekcji Katalog i Plik .
Wprowadź następujące wyrażenie w sekcji Katalog , klikając link zawartość dynamiczną w polu tekstowym:
@concat('customers/incremental/',formatDateTime(dataset().triggerStart,'yyyy/MM/dd'))Wprowadź następujące wyrażenie w sekcji Plik . Spowoduje to utworzenie nazw plików na podstawie daty i godziny rozpoczęcia wyzwalacza, z sufiksem z rozszerzeniem csv:
@concat(formatDateTime(dataset().triggerStart,'yyyyMMddHHmmssfff'),'.csv')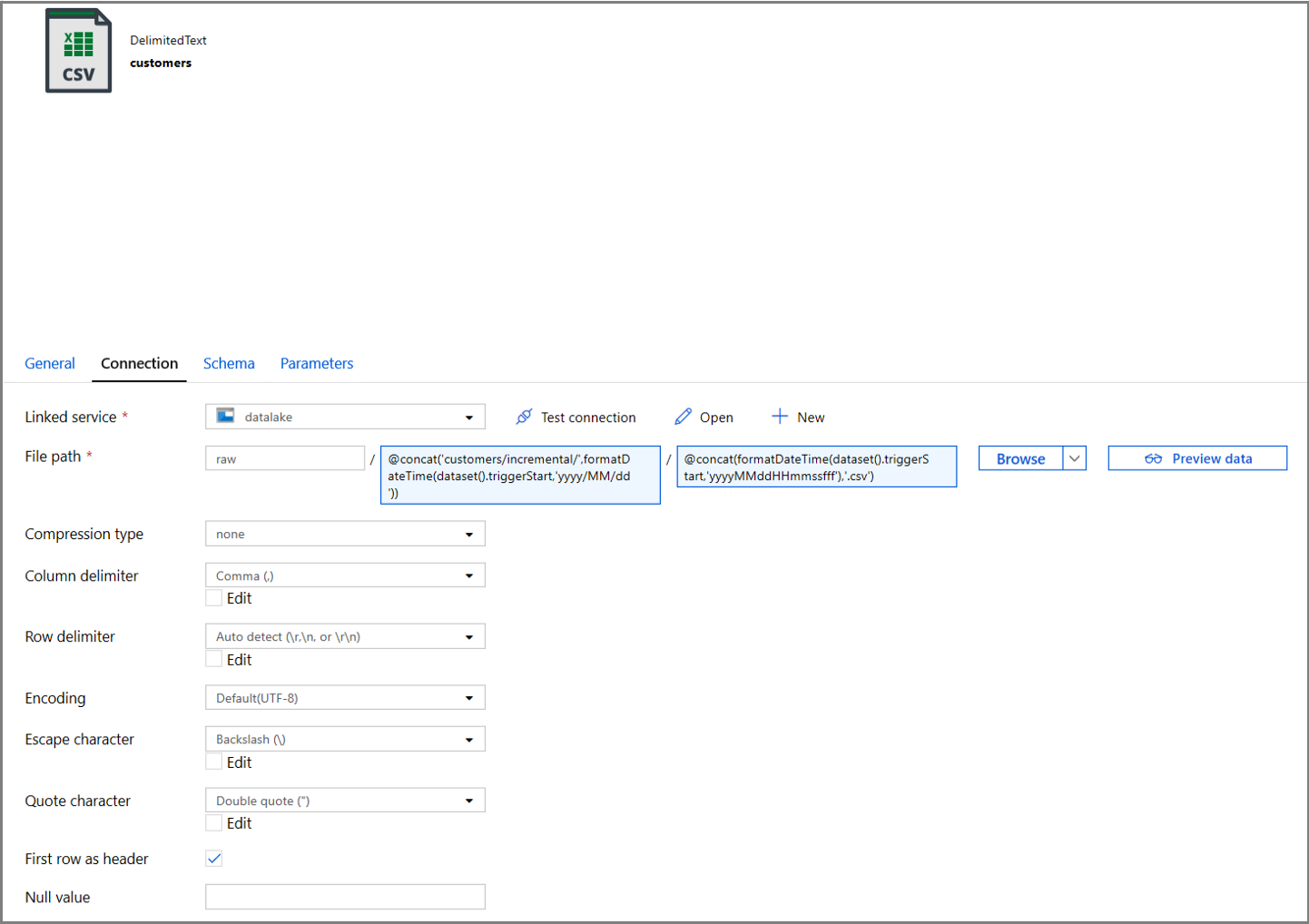
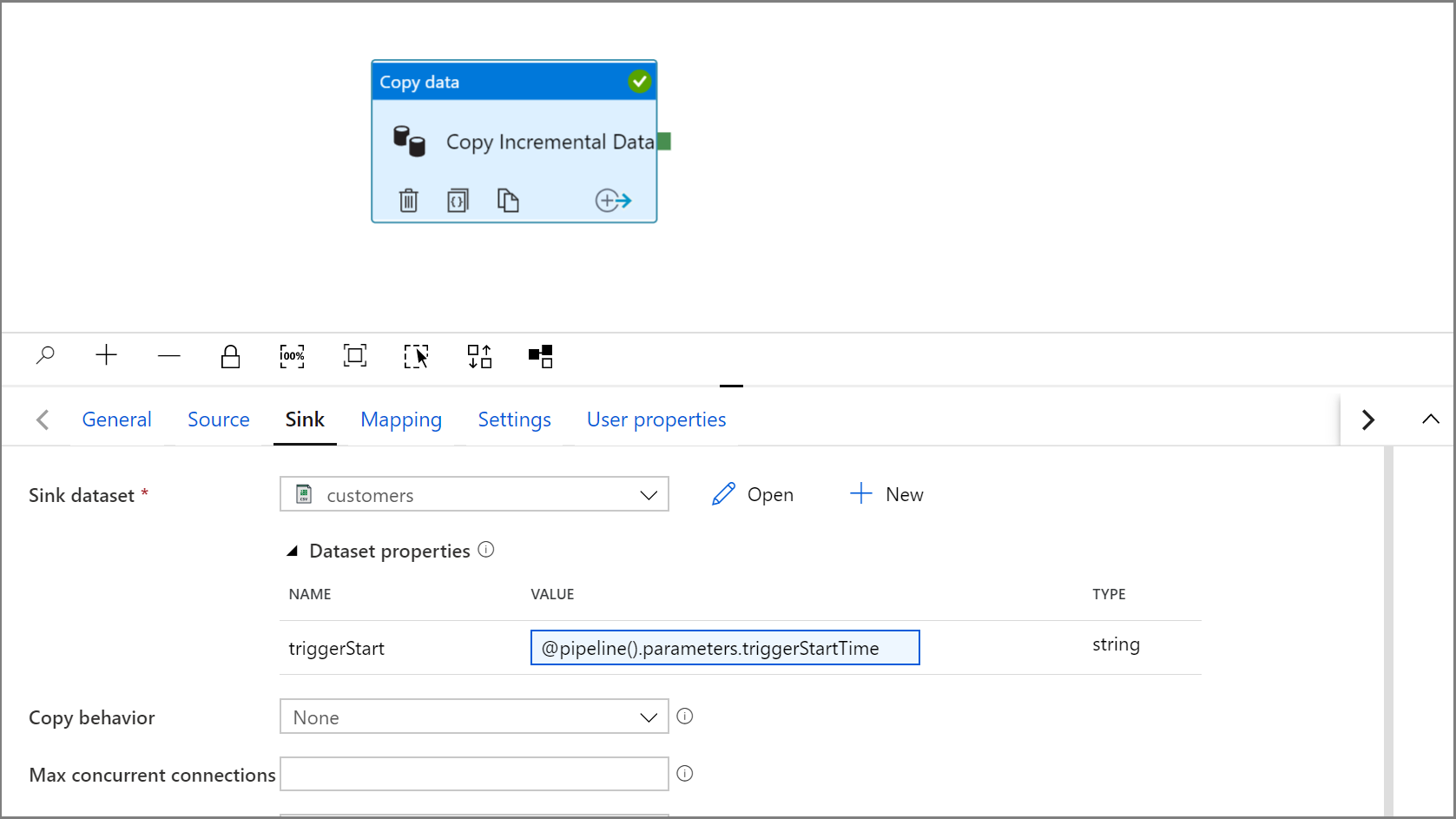
Wróć do ustawień ujścia w działaniu kopiowania, klikając kartę IncrementalCopyPipeline.
Rozwiń właściwości zestawu danych i wprowadź zawartość dynamiczną w wartości parametru triggerStart przy użyciu następującego wyrażenia:
@pipeline().parameters.triggerStartTime
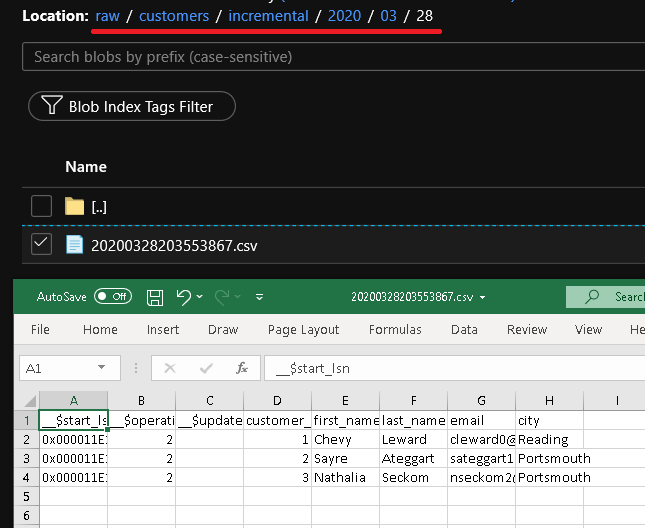
Kliknij pozycję Debuguj, aby przetestować potok i upewnić się, że struktura folderów i plik wyjściowy są generowane zgodnie z oczekiwaniami. Pobierz i otwórz plik, aby zweryfikować zawartość.
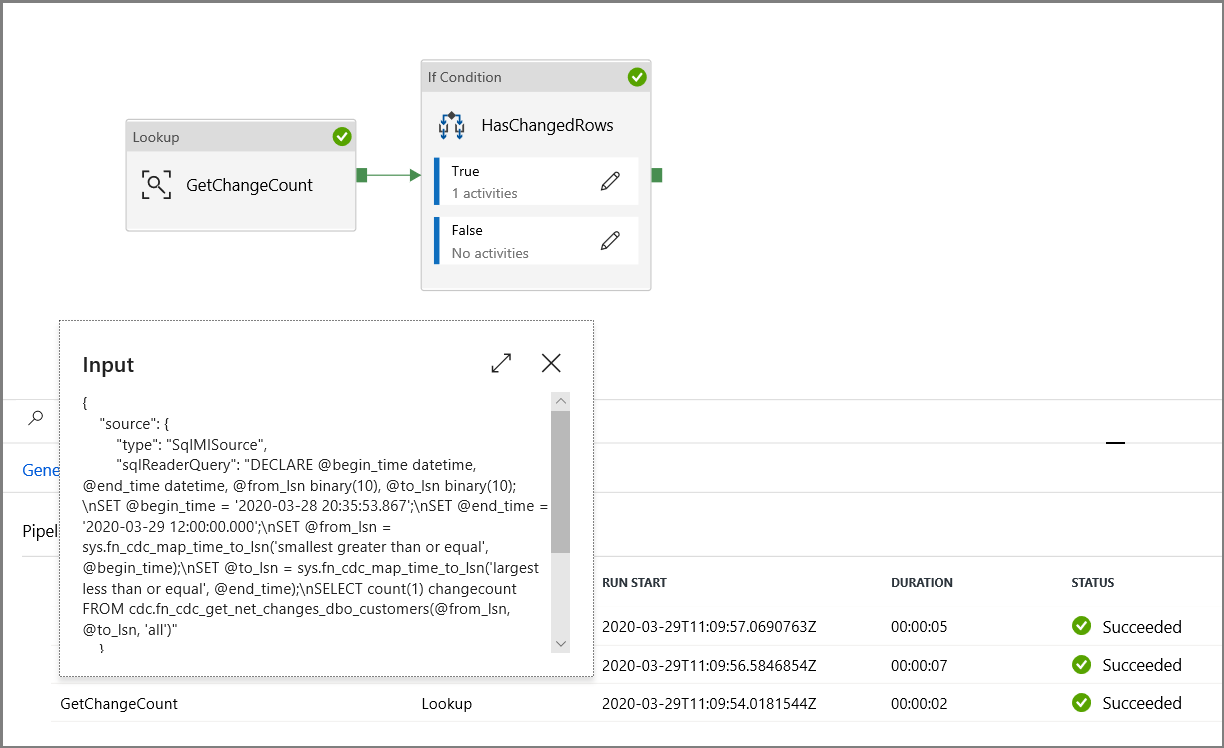
Upewnij się, że parametry są wstrzykiwane do zapytania, przeglądając parametry wejściowe przebiegu potoku.
Opublikuj jednostki (połączone usługi, zestawy danych i potoki) w usłudze Data Factory, klikając przycisk Opublikuj wszystko . Poczekaj na wyświetlenie komunikatu Publikowanie powiodło się.
Na koniec skonfiguruj wyzwalacz okna wirowania, aby uruchomić potok w regularnym interwale i ustawić parametry czasu rozpoczęcia i zakończenia.
- Kliknij przycisk Dodaj wyzwalacz, a następnie wybierz pozycję Nowy/Edytuj
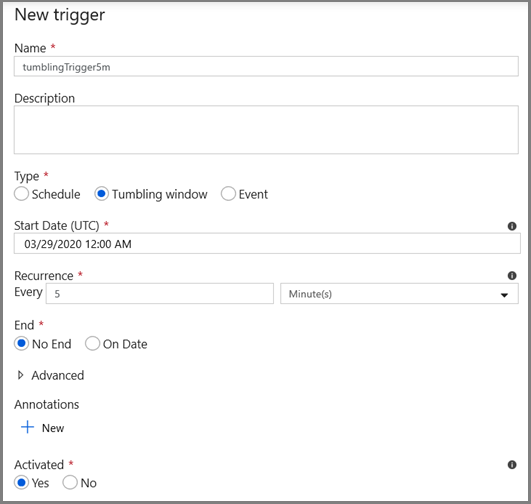
- Wprowadź nazwę wyzwalacza i określ godzinę rozpoczęcia, która jest równa godzinie zakończenia okna debugowania powyżej.
Na następnym ekranie określ następujące wartości odpowiednio dla parametrów początkowych i końcowych.
@formatDateTime(trigger().outputs.windowStartTime,'yyyy-MM-dd HH:mm:ss.fff') @formatDateTime(trigger().outputs.windowEndTime,'yyyy-MM-dd HH:mm:ss.fff')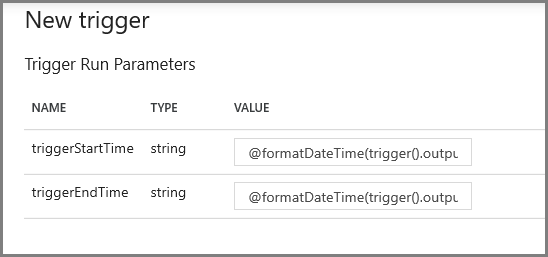
Uwaga
Wyzwalacz zostanie uruchomiony tylko po jej opublikowaniu. Ponadto oczekiwane zachowanie okna wirowania polega na uruchomieniu wszystkich historycznych interwałów od daty rozpoczęcia do tej pory. Więcej informacji na temat wyzwalaczy okien stałoczasowych można znaleźć tutaj.
Za pomocą programu SQL Server Management Studio wprowadź dodatkowe zmiany w tabeli klienta, uruchamiając następujący kod SQL:
insert into customers (customer_id, first_name, last_name, email, city) values (4, 'Farlie', 'Hadigate', 'fhadigate3@zdnet.com', 'Reading'); insert into customers (customer_id, first_name, last_name, email, city) values (5, 'Anet', 'MacColm', 'amaccolm4@yellowbook.com', 'Portsmouth'); insert into customers (customer_id, first_name, last_name, email, city) values (6, 'Elonore', 'Bearham', 'ebearham5@ebay.co.uk', 'Portsmouth'); update customers set first_name='Elon' where customer_id=6; delete from customers where customer_id=5;Kliknij przycisk Opublikuj wszystko. Poczekaj na wyświetlenie komunikatu Publikowanie powiodło się.
Po kilku minutach potok zostanie wyzwolony, a nowy plik zostanie załadowany do usługi Azure Storage
Monitorowanie potoku kopiowania przyrostowego
Kliknij kartę Monitorowanie po lewej stronie. Na liście zostanie wyświetlone uruchomienie potoku i jego stan. Aby odświeżyć listę, kliknij pozycję Odśwież. Zatrzymaj wskaźnik myszy w pobliżu nazwy potoku, aby uzyskać dostęp do akcji Uruchom ponownie i raportu Zużycie.
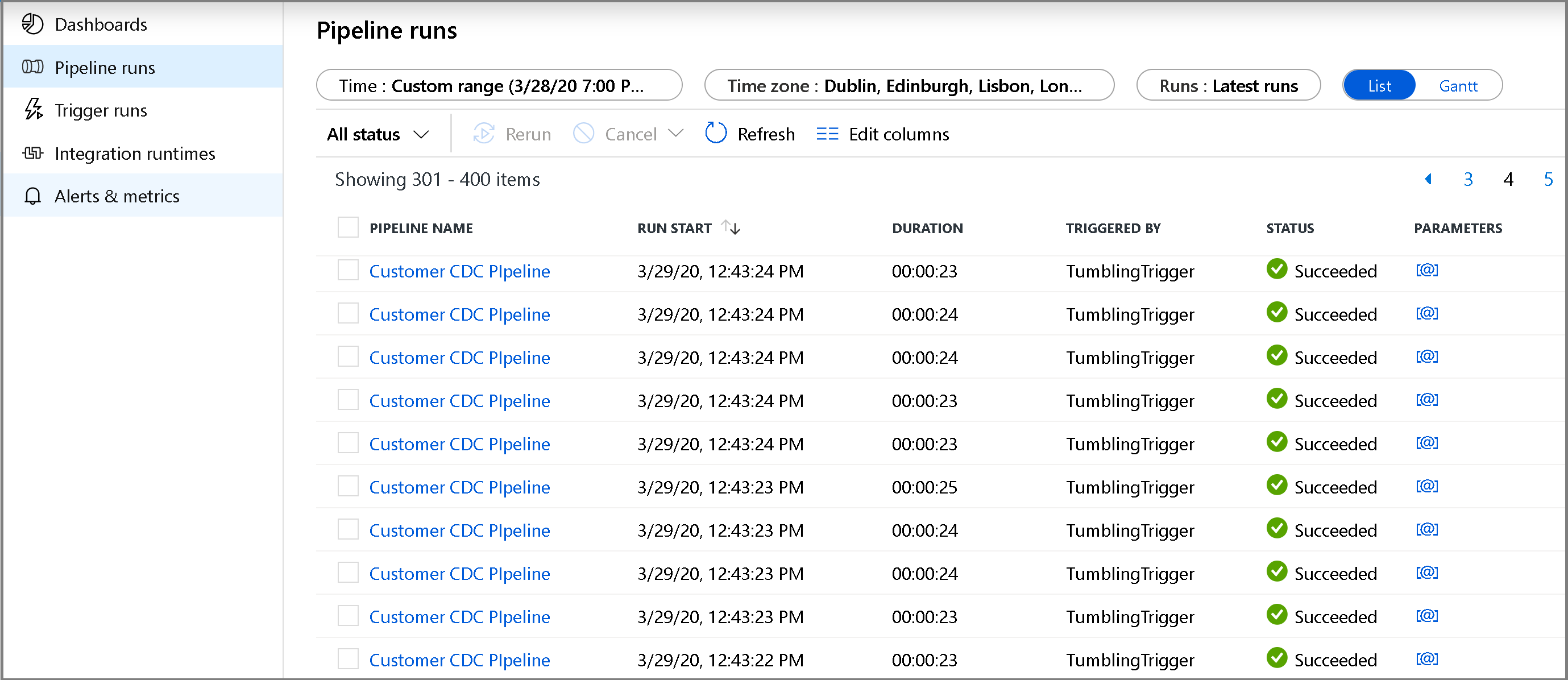
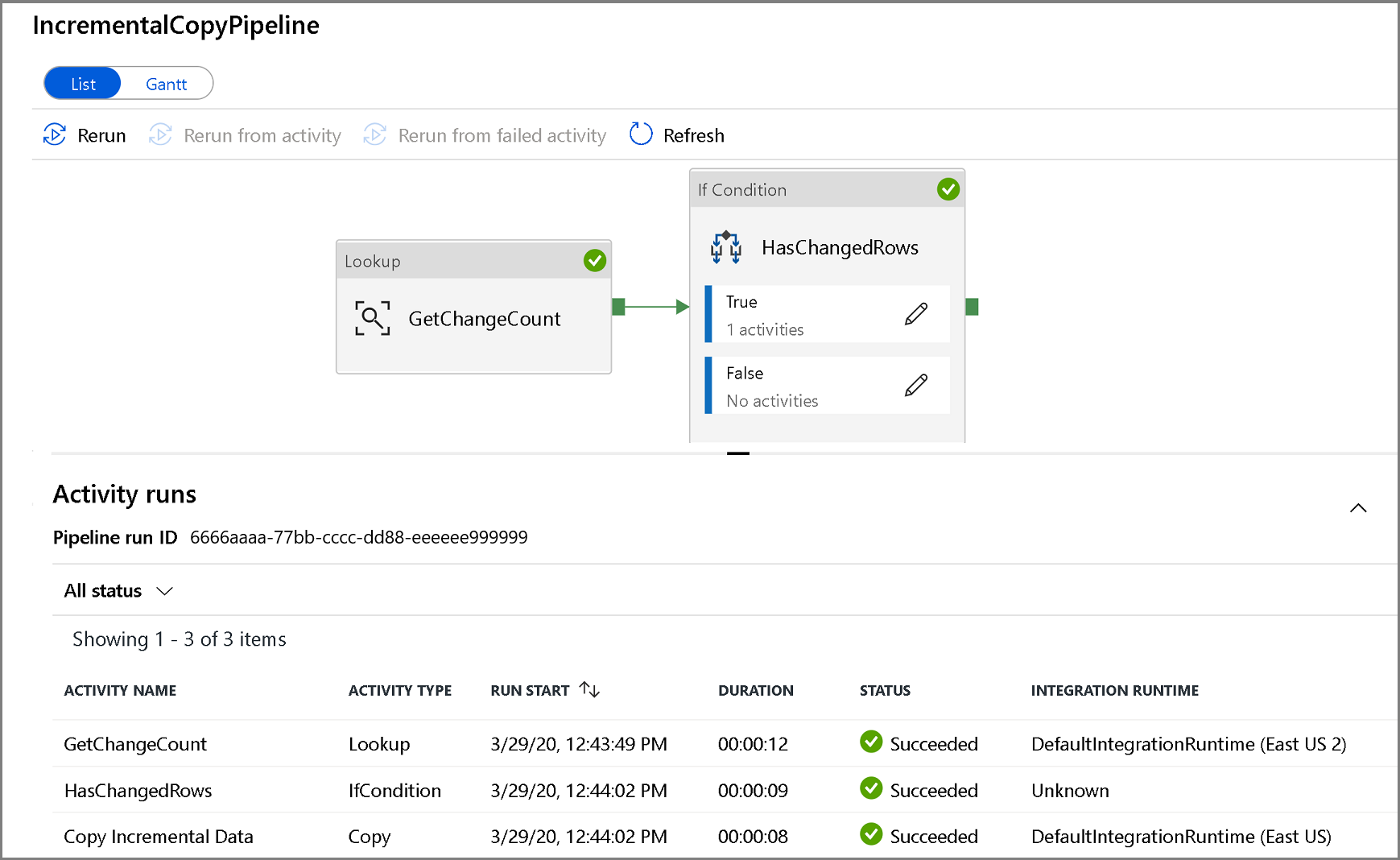
Aby wyświetlić uruchomienia działań skojarzone z uruchomieniem potoku, kliknij nazwę potoku. Jeśli wykryto zmienione dane, będą istnieć trzy działania, w tym działanie kopiowania. W przeciwnym razie na liście będą znajdować się tylko dwa wpisy. Aby wrócić do widoku przebiegów potoku, kliknij link Wszystkie potoki u góry .
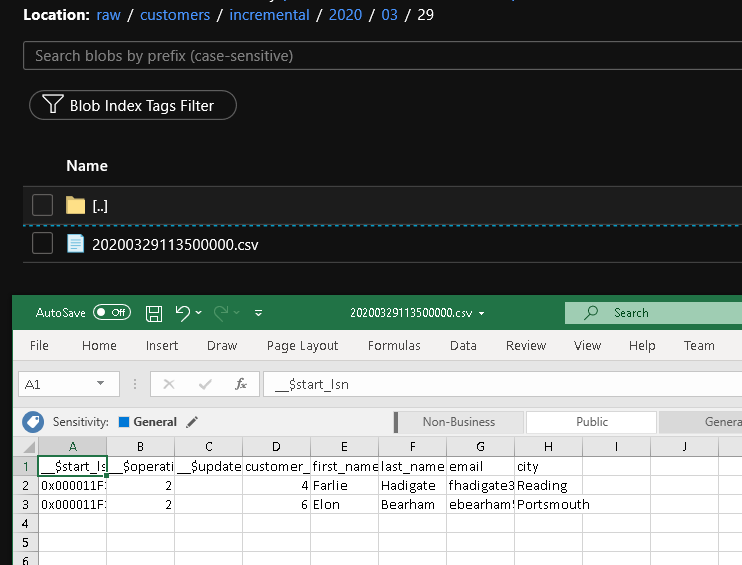
Sprawdzanie wyników
W folderze customers/incremental/YYYY/MM/DD kontenera raw widoczny będzie drugi plik.
Powiązana zawartość
Przejdź do poniższego samouczka, aby dowiedzieć się więcej o kopiowaniu nowych i zmienionych plików tylko na podstawie ich daty ostatniej modyfikacji: