Najlepsze rozwiązania dotyczące zapisywania plików w usłudze Data Lake za pomocą przepływów danych
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Jeśli jesteś nowym użytkownikiem usługi Azure Data Factory, zobacz Wprowadzenie do usługi Azure Data Factory.
W tym samouczku poznasz najlepsze rozwiązania, które można zastosować podczas zapisywania plików w usłudze ADLS Gen2 lub Azure Blob Storage przy użyciu przepływów danych. Będziesz potrzebować dostępu do konta usługi Azure Blob Storage lub konta usługi Azure Data Lake Store Gen2 w celu odczytania pliku parquet, a następnie zapisania wyników w folderach.
Wymagania wstępne
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto platformy Azure.
- Konto usługi Azure Storage. Magazyn usługi ADLS jest używany jako magazyn danych źródłowych i ujścia . Jeśli nie masz konta magazynu, utwórz je, wykonując czynności przedstawione w artykule Tworzenie konta magazynu platformy Azure.
W krokach opisanych w tym samouczku przyjęto założenie, że masz
Tworzenie fabryki danych
W tym kroku utworzysz fabrykę danych i otworzysz środowisko użytkownika usługi Data Factory, aby utworzyć potok w fabryce danych.
Otwórz przeglądarkę Microsoft Edge lub Google Chrome. Obecnie interfejs użytkownika usługi Data Factory jest obsługiwany tylko w przeglądarkach internetowych Przeglądarki Microsoft Edge i Google Chrome.
W menu po lewej stronie wybierz pozycję Utwórz zasób>Integration>Data Factory
Na stronie Nowa fabryka danych w obszarze Nazwa wprowadź wartość ADFTutorialDataFactory
Wybierz subskrypcję platformy Azure, w której chcesz utworzyć fabrykę danych.
W obszarze Grupa zasobów wykonaj jedną z następujących czynności:
a. Wybierz pozycję Użyj istniejącej, a następnie wybierz istniejącą grupę zasobów z listy rozwijanej.
b. Wybierz pozycję Utwórz nową i wprowadź nazwę grupy zasobów. Aby dowiedzieć się więcej o grupach zasobów, zobacz Zarządzanie zasobami platformy Azure przy użyciu grup zasobów.
W obszarze Wersja wybierz pozycję V2.
W obszarze Lokalizacja wybierz lokalizację fabryki danych. Na liście rozwijanej są wyświetlane tylko obsługiwane lokalizacje. Magazyny danych (na przykład Azure Storage i SQL Database) i obliczenia (na przykład Usługa Azure HDInsight) używane przez fabrykę danych mogą znajdować się w innych regionach.
Wybierz pozycję Utwórz.
Po zakończeniu tworzenia zostanie wyświetlone powiadomienie w Centrum powiadomień. Wybierz pozycję Przejdź do zasobu , aby przejść do strony Fabryka danych.
Wybierz pozycję Tworzenie i monitorowanie, aby uruchomić interfejs użytkownika usługi Data Factory na osobnej karcie.
Tworzenie potoku z działaniem przepływu danych
W tym kroku utworzysz potok zawierający działanie przepływu danych.
Na stronie głównej usługi Azure Data Factory wybierz pozycję Orkiestruj.
Na karcie Ogólne potoku wprowadź wartość DeltaLake w polu Nazwa potoku.
Na górnym pasku fabryki przesuń suwak debugowania Przepływ danych. Tryb debugowania umożliwia interaktywne testowanie logiki transformacji względem dynamicznego klastra Spark. Przepływ danych klastry zajmują od 5 do 7 minut, a użytkownicy powinni najpierw włączyć debugowanie, jeśli planują wykonać Przepływ danych programowania. Aby uzyskać więcej informacji, zobacz Tryb debugowania.

W okienku Działania rozwiń akordeon Przenieś i Przekształć . Przeciągnij i upuść działanie Przepływ danych z okienka do kanwy potoku.
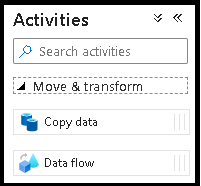
W oknie podręcznym Dodawanie Przepływ danych wybierz pozycję Utwórz nową Przepływ danych, a następnie nadaj przepływowi danych nazwę DeltaLake. Po zakończeniu kliknij przycisk Zakończ.
Tworzenie logiki przekształcania na kanwie przepływu danych
Wszystkie dane źródłowe (w tym samouczku użyjemy źródła pliku Parquet) i użyjemy przekształcenia ujścia, aby wylądować dane w formacie Parquet przy użyciu najbardziej efektywnych mechanizmów etL typu data lake.

Cele samouczka
- Wybierz dowolny źródłowy zestaw danych w nowym przepływie danych 1. Efektywne partycjonowanie zestawu danych ujścia za pomocą przepływów danych
- Lądowanie partycjonowanych danych w folderach lake usługi ADLS Gen2
Rozpoczynanie od pustej kanwy przepływu danych
Najpierw skonfigurujmy środowisko przepływu danych dla każdego z mechanizmów opisanych poniżej na potrzeby danych docelowych w usłudze ADLS Gen2
- Kliknij transformację źródłową.
- Kliknij nowy przycisk obok zestawu danych w dolnym panelu.
- Wybierz zestaw danych lub utwórz nowy. Na potrzeby tego pokazu użyjemy zestawu danych Parquet o nazwie Dane użytkownika.
- Dodaj transformację kolumny pochodnej. Użyjemy tego jako sposobu dynamicznego ustawiania żądanych nazw folderów.
- Dodaj przekształcenie ujścia.
Dane wyjściowe folderu hierarchicznego
Bardzo często używa się unikatowych wartości w danych do tworzenia hierarchii folderów w celu partycjonowania danych w usłudze Lake. Jest to bardzo optymalny sposób organizowania i przetwarzania danych w jeziorze i na platformie Spark (aparatu obliczeniowego za przepływami danych). Jednak w ten sposób będzie można zorganizować dane wyjściowe w niewielki koszt wydajności. Spodziewaj się niewielkiego spadku ogólnej wydajności potoku przy użyciu tego mechanizmu ujścia.
- Wróć do projektanta przepływu danych i edytuj utworzony powyżej przepływ danych. Kliknij przekształcenie ujścia.
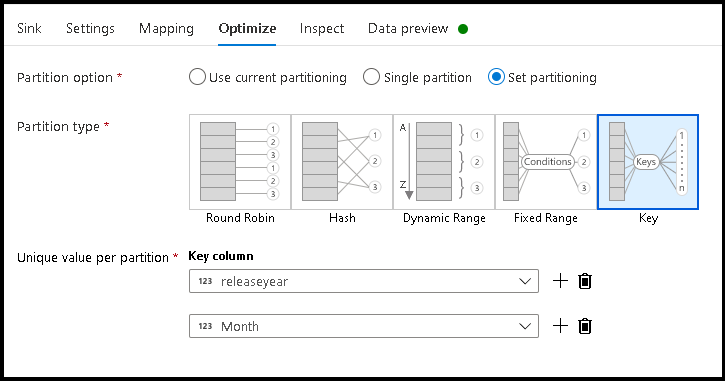
- Kliknij pozycję Optymalizuj > ustaw klucz partycjonowania >
- Wybierz kolumny, których chcesz użyć, aby ustawić hierarchiczną strukturę folderów.
- W poniższym przykładzie użyto roku i miesiąca jako kolumn nazewnictwa folderów. Wyniki będą folderami formularza
releaseyear=1990/month=8. - Podczas uzyskiwania dostępu do partycji danych w źródle przepływu danych wskażesz tylko powyższy
releaseyearfolder najwyższego poziomu i użyjesz wzorca wieloznakowego dla każdego kolejnego folderu, np.**/**/*.parquet - Aby manipulować wartościami danych, a nawet w razie potrzeby generowania syntetycznych wartości nazw folderów, użyj przekształcenia Pochodne kolumny, aby utworzyć wartości, których chcesz użyć w nazwach folderów.
Nazwij folder jako wartości danych
Nieco lepszą techniką ujścia danych typu lake przy użyciu usługi ADLS Gen2, która nie oferuje tej samej korzyści co partycjonowanie klucz/wartość, to Name folder as column data. Podczas gdy styl partycjonowania klucza struktury hierarchicznej umożliwia łatwiejsze przetwarzanie wycinków danych, ta technika jest spłaszczaną strukturą folderów, która może szybciej zapisywać dane.
- Wróć do projektanta przepływu danych i edytuj utworzony powyżej przepływ danych. Kliknij przekształcenie ujścia.
- Kliknij pozycję Optymalizacja > ustaw partycjonowanie > Użyj bieżącej partycjonowania.
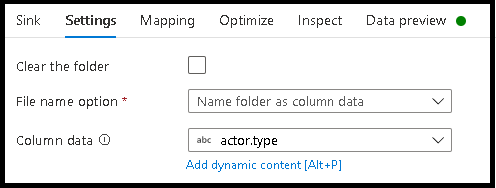
- Kliknij pozycję Ustawienia > Nazwa folderu jako dane kolumny.
- Wybierz kolumnę, której chcesz użyć do generowania nazw folderów.
- Aby manipulować wartościami danych, a nawet w razie potrzeby generowania syntetycznych wartości nazw folderów, użyj przekształcenia Pochodne kolumny, aby utworzyć wartości, których chcesz użyć w nazwach folderów.
Nazwa pliku jako wartości danych
Techniki wymienione w powyższych samouczkach są dobrymi przypadkami użycia tworzenia kategorii folderów w usłudze Data Lake. Domyślny schemat nazewnictwa plików używany przez te techniki polega na użyciu identyfikatora zadania funkcji wykonawczej platformy Spark. Czasami można ustawić nazwę pliku wyjściowego w ujściu tekstu przepływu danych. Ta technika jest sugerowana tylko do użycia z małymi plikami. Proces scalania plików partycji z jednym plikiem wyjściowym jest długotrwałym procesem.
- Wróć do projektanta przepływu danych i edytuj utworzony powyżej przepływ danych. Kliknij przekształcenie ujścia.
- Kliknij pozycję Optymalizuj > ustaw partycjonowanie pojedynczej > partycji. Jest to wymaganie dotyczące pojedynczej partycji, które tworzy wąskie gardło w procesie wykonywania podczas scalania plików. Ta opcja jest zalecana tylko w przypadku małych plików.
- Kliknij pozycję Ustawienia > Nazwa pliku jako dane kolumny.
- Wybierz kolumnę, której chcesz użyć do generowania nazw plików.
- Aby manipulować wartościami danych, a nawet w razie potrzeby generowania syntetycznych wartości dla nazw plików, użyj przekształcenia Pochodne kolumny, aby utworzyć wartości, których chcesz użyć w nazwach plików.
Powiązana zawartość
Dowiedz się więcej o ujściach przepływu danych.