Przekształcanie danych w usłudze Delta Lake przy użyciu przepływów danych mapowania
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Jeśli jesteś nowym użytkownikiem usługi Azure Data Factory, zobacz Wprowadzenie do usługi Azure Data Factory.
W tym samouczku użyjesz kanwy przepływu danych, aby utworzyć przepływy danych, które umożliwiają analizowanie i przekształcanie danych w usłudze Azure Data Lake Storage (ADLS) Gen2 i przechowywanie ich w usłudze Delta Lake.
Wymagania wstępne
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto platformy Azure.
- Konto usługi Azure Storage. Magazyn usługi ADLS jest używany jako magazyn danych źródłowych i ujścia . Jeśli nie masz konta magazynu, utwórz je, wykonując czynności przedstawione w artykule Tworzenie konta magazynu platformy Azure.
Plik, który przekształcamy w tym samouczku, jest MoviesDB.csv, który można znaleźć tutaj. Aby pobrać plik z usługi GitHub, skopiuj zawartość do wybranego edytora tekstów, aby zapisać lokalnie jako plik .csv. Aby przekazać plik na konto magazynu, zobacz Przekazywanie obiektów blob za pomocą witryny Azure Portal. Przykłady odwołują się do kontenera o nazwie "sample-data".
Tworzenie fabryki danych
W tym kroku utworzysz fabrykę danych i otworzysz środowisko użytkownika usługi Data Factory, aby utworzyć potok w fabryce danych.
Otwórz przeglądarkę Microsoft Edge lub Google Chrome. Obecnie interfejs użytkownika usługi Data Factory jest obsługiwany tylko w przeglądarkach internetowych Przeglądarki Microsoft Edge i Google Chrome.
W menu po lewej stronie wybierz pozycję Utwórz zasób>Integration>Data Factory
Na stronie Nowa fabryka danych w obszarze Nazwa wprowadź wartość ADFTutorialDataFactory
Wybierz subskrypcję platformy Azure, w której chcesz utworzyć fabrykę danych.
W obszarze Grupa zasobów wykonaj jedną z następujących czynności:
a. Wybierz pozycję Użyj istniejącej, a następnie wybierz istniejącą grupę zasobów z listy rozwijanej.
b. Wybierz pozycję Utwórz nową, a następnie wprowadź nazwę grupy zasobów.
Informacje na temat grup zasobów znajdują się w artykule Using resource groups to manage your Azure resources (Używanie grup zasobów do zarządzania zasobami platformy Azure).
W obszarze Wersja wybierz pozycję V2.
W obszarze Lokalizacja wybierz lokalizację fabryki danych. Na liście rozwijanej są wyświetlane tylko obsługiwane lokalizacje. Magazyny danych (na przykład Azure Storage i SQL Database) i obliczenia (na przykład Usługa Azure HDInsight) używane przez fabrykę danych mogą znajdować się w innych regionach.
Wybierz pozycję Utwórz.
Po zakończeniu tworzenia zostanie wyświetlone powiadomienie w Centrum powiadomień. Wybierz pozycję Przejdź do zasobu , aby przejść do strony Fabryka danych.
Wybierz pozycję Tworzenie i monitorowanie, aby uruchomić interfejs użytkownika usługi Data Factory na osobnej karcie.
Tworzenie potoku z działaniem przepływu danych
W tym kroku utworzysz potok zawierający działanie przepływu danych.
Na stronie głównej wybierz pozycję Orkiestruj.
Na karcie Ogólne potoku wprowadź wartość DeltaLake w polu Nazwa potoku.
W okienku Działania rozwiń akordeon Przenieś i Przekształć . Przeciągnij i upuść działanie Przepływ danych z okienka do kanwy potoku.
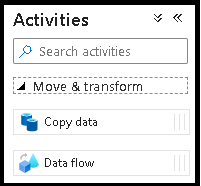
W oknie podręcznym Dodawanie Przepływ danych wybierz pozycję Utwórz nową Przepływ danych, a następnie nadaj przepływowi danych nazwę DeltaLake. Po zakończeniu wybierz pozycję Zakończ.
Na górnym pasku kanwy potoku przesuń suwak debugowania Przepływ danych. Tryb debugowania umożliwia interaktywne testowanie logiki transformacji względem dynamicznego klastra Spark. Przepływ danych klastry zajmują od 5 do 7 minut, a użytkownicy powinni najpierw włączyć debugowanie, jeśli planują wykonać Przepływ danych programowania. Aby uzyskać więcej informacji, zobacz Tryb debugowania.

Tworzenie logiki przekształcania na kanwie przepływu danych
W tym samouczku wygenerujesz dwa przepływy danych. Pierwszy przepływ danych to proste źródło do ujścia w celu wygenerowania nowego usługi Delta Lake z pliku CSV filmów. Na koniec utworzysz projekt przepływu, który jest zgodny z instrukcjami w celu zaktualizowania danych w usłudze Delta Lake.

Cele samouczka
- Użyj źródła zestawu danych MoviesCSV z wymagań wstępnych i utwórz z niego nową usługę Delta Lake.
- Skompiluj logikę, aby zaktualizować oceny dla filmów z 1988 roku na "1".
- Usuń wszystkie filmy z 1950 roku.
- Wstaw nowe filmy na rok 2021, duplikując filmy z 1960 roku.
Rozpoczynanie od pustej kanwy przepływu danych
Wybierz przekształcenie źródła w górnej części okna edytora przepływu danych, a następnie wybierz pozycję + Nowy obok właściwości Zestaw danych w oknie Ustawienia źródła:

Wybierz pozycję Azure Data Lake Storage Gen2 w wyświetlonym oknie Nowy zestaw danych , a następnie wybierz pozycję Kontynuuj.

Wybierz pozycję RozdzielanyTekst dla typu zestawu danych, a następnie ponownie wybierz pozycję Kontynuuj .

Nadaj zestawowi danych nazwę "MoviesCSV" i wybierz pozycję + Nowy w obszarze Połączona usługa , aby utworzyć nową połączoną usługę z plikiem.
Podaj szczegóły konta magazynu utworzonego wcześniej w sekcji Wymagania wstępne, a następnie przeglądaj i wybierz przekazany tam plik MoviesCSV.
Po dodaniu połączonej usługi zaznacz pole wyboru Pierwszy wiersz jako nagłówek , a następnie wybierz przycisk OK , aby dodać źródło.
Przejdź do karty Projekcja okna ustawień przepływu danych, a następnie wybierz pozycję Wykryj typy danych.
Teraz wybierz pozycję po źródle + w oknie edytora przepływu danych i przewiń w dół, aby wybrać pozycję Ujście w sekcji Miejsce docelowe , dodając nowy ujście do przepływu danych.

Na karcie Ujście ustawień ujścia wyświetlanych po dodaniu ujścia wybierz pozycję Wbudowane dla typu ujścia, a następnie pozycję Delta dla typu zestawu danych wbudowanego. Następnie wybierz usługę Azure Data Lake Storage Gen2 dla połączonej usługi.

Wybierz nazwę folderu w kontenerze magazynu, w którym chcesz, aby usługa utworzyła usługę Delta Lake.
Na koniec przejdź z powrotem do projektanta potoku i wybierz pozycję Debuguj , aby wykonać potok w trybie debugowania przy użyciu tylko tego działania przepływu danych na kanwie. Spowoduje to wygenerowanie nowego usługi Delta Lake w usłudze Azure Data Lake Storage Gen2.
Teraz z menu Zasoby fabryki po lewej stronie ekranu wybierz, + aby dodać nowy zasób, a następnie wybierz pozycję Przepływ danych.
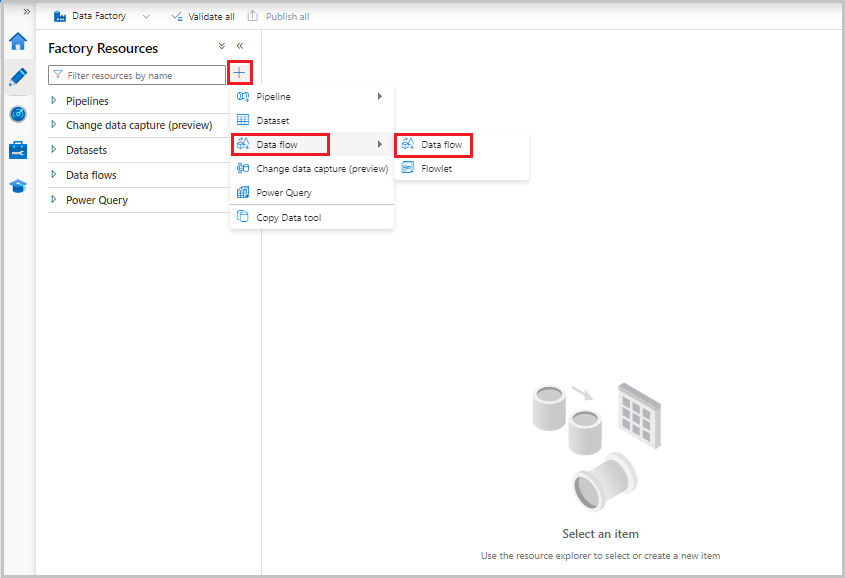
Jak poprzednio, ponownie wybierz plik MoviesCSV jako źródło, a następnie ponownie wybierz pozycję Wykryj typy danych na karcie Projekcja .
Tym razem po utworzeniu źródła wybierz + w oknie edytora przepływu danych i dodaj przekształcenie Filtr do źródła.

Dodaj warunek Filtruj w oknie Ustawienia filtru, które zezwala tylko na wiersze filmów zgodne z 1950, 1960 i 1988.

Teraz dodaj transformację kolumny pochodnej, aby zaktualizować klasyfikacje dla każdego filmu z 1988 roku do "1".

Update, insert, delete, and upsertzasady są tworzone w przekształceniu alter Row. Dodaj przekształcenie alter row po kolumnie pochodnej.Zasady zmiany wierszy powinny wyglądać następująco.

Teraz, po ustawieniu odpowiednich zasad dla każdego typu alter wiersza, sprawdź, czy odpowiednie reguły aktualizacji zostały ustawione na transformacji ujścia

W tym miejscu używamy ujścia usługi Delta Lake do usługi Azure Data Lake Storage Gen2 i zezwalamy na wstawianie, aktualizacje, usuwanie.
Należy pamiętać, że kolumny kluczy są kluczem złożonym składającym się z kolumny klucz podstawowy Movie i kolumny roku. Jest to spowodowane tym, że stworzyliśmy fałszywe filmy z 2021 roku, duplikując 1960 wierszy. Pozwala to uniknąć kolizji podczas wyszukiwania istniejących wierszy, zapewniając unikatowość.
Ukończono pobieranie przykładu
Oto przykładowe rozwiązanie dla potoku delty z przepływem danych dla wierszy aktualizacji/usuwania w jeziorze.
Powiązana zawartość
Dowiedz się więcej o języku wyrażeń przepływu danych.