Przekształcanie danych przy użyciu działania przesyłania strumieniowego usługi Hadoop w usłudze Azure Data Factory lub Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Działanie przesyłania strumieniowego usługi HDInsight w potoku usługi Azure Data Factory lub Synapse Analytics wykonuje programy przesyłania strumieniowego hadoop we własnym klastrze usługi HDInsight lub na żądanie. Ten artykuł opiera się na artykule dotyczącym działań przekształcania danych, który zawiera ogólne omówienie transformacji danych i obsługiwanych działań przekształcania.
Aby dowiedzieć się więcej, zapoznaj się z artykułami wprowadzających do usług Azure Data Factory i Synapse Analytics , a następnie zapoznaj się z artykułem Samouczek: przekształcanie danych przed przeczytaniem tego artykułu.
Dodawanie działania przesyłania strumieniowego usługi HDInsight do potoku za pomocą interfejsu użytkownika
Aby użyć działania przesyłania strumieniowego usługi HDInsight do potoku, wykonaj następujące kroki:
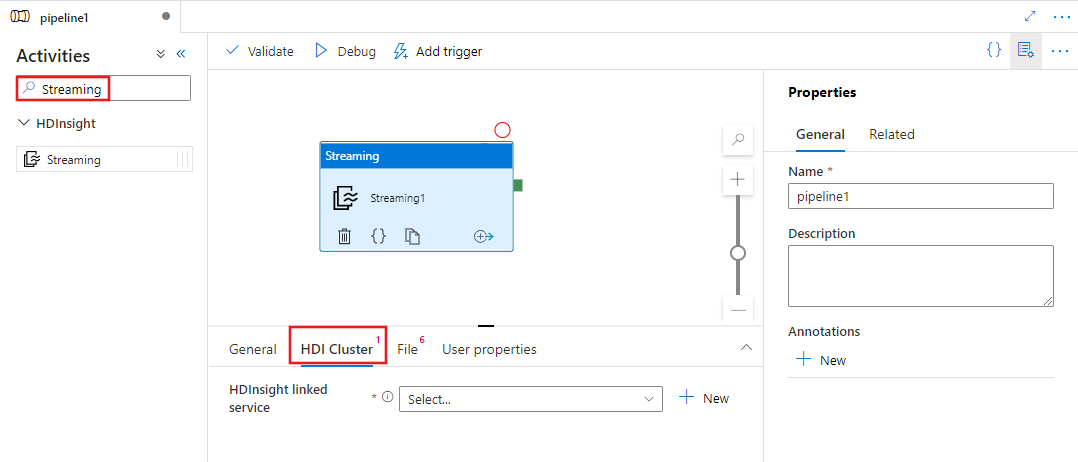
Wyszukaj pozycję Przesyłanie strumieniowe w okienku Działania potoku i przeciągnij działanie przesyłania strumieniowego na kanwę potoku.
Wybierz nowe działanie przesyłania strumieniowego na kanwie, jeśli nie zostało jeszcze wybrane.
Wybierz kartę Klaster usługi HDI, aby wybrać lub utworzyć nową połączoną usługę z klastrem usługi HDInsight, który będzie używany do wykonywania działania przesyłania strumieniowego.
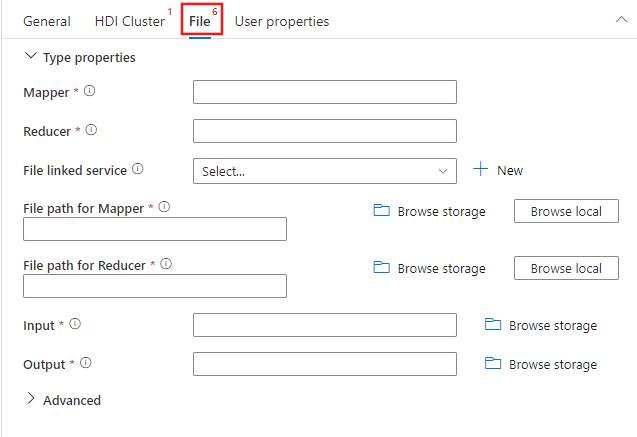
Wybierz kartę Plik , aby określić nazwy mapera i reduktora dla zadania przesyłania strumieniowego, a następnie wybierz lub utwórz nową połączoną usługę na koncie usługi Azure Storage, które będzie maperem, reduktorem, danymi wejściowymi i wyjściowymi dla zadania. Możesz również skonfigurować zaawansowane szczegóły, w tym konfigurację debugowania, argumenty i parametry, które mają zostać przekazane do zadania.
Przykład JSON
{
"name": "Streaming Activity",
"description": "Description",
"type": "HDInsightStreaming",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mapper": "MyMapper.exe",
"reducer": "MyReducer.exe",
"combiner": "MyCombiner.exe",
"fileLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"filePaths": [
"<containername>/example/apps/MyMapper.exe",
"<containername>/example/apps/MyReducer.exe",
"<containername>/example/apps/MyCombiner.exe"
],
"input": "wasb://<containername>@<accountname>.blob.core.windows.net/example/input/MapperInput.txt",
"output": "wasb://<containername>@<accountname>.blob.core.windows.net/example/output/ReducerOutput.txt",
"commandEnvironment": [
"CmdEnvVarName=CmdEnvVarValue"
],
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Szczegóły składni
| Właściwości | Opis | Wymagania |
|---|---|---|
| name | Nazwa działania | Tak |
| opis | Tekst opisujący, do czego służy działanie | Nie. |
| type | W przypadku działania przesyłania strumieniowego usługi Hadoop typ działania to HDInsightStreaming | Tak |
| linkedServiceName | Odwołanie do klastra usługi HDInsight zarejestrowanego jako połączona usługa. Aby dowiedzieć się więcej o tej połączonej usłudze, zobacz artykuł Dotyczący połączonych usług obliczeniowych. | Tak |
| Mapowania | Określa nazwę pliku wykonywalnego mapatora | Tak |
| Reduktor | Określa nazwę pliku wykonywalnego reduktora | Tak |
| łączenie | Określa nazwę pliku wykonywalnego łączenia | Nie. |
| fileLinkedService | Odwołanie do połączonej usługi Azure Storage używanej do przechowywania programów Mapper, Combiner i Reducer do wykonania. W tym miejscu obsługiwane są tylko połączone usługi Azure Blob Storage i ADLS Gen2. Jeśli nie określisz tej połączonej usługi, zostanie użyta połączona usługa Azure Storage zdefiniowana w połączonej usłudze HDInsight. | Nie. |
| filePath | Podaj tablicę ścieżek do programów Mapper, Combiner i Reducer przechowywanych w usłudze Azure Storage, o której mowa w plikuLinkedService. W ścieżce jest rozróżniana wielkość liter. | Tak |
| input | Określa ścieżkę WASB do pliku wejściowego mapatora. | Tak |
| output | Określa ścieżkę WASB do pliku wyjściowego reduktora. | Tak |
| getDebugInfo | Określa, kiedy pliki dziennika są kopiowane do usługi Azure Storage używanej przez klaster usługi HDInsight (lub) określony przez scriptLinkedService. Dozwolone wartości: Brak, Zawsze lub Niepowodzenie. Wartość domyślna: None. | Nie. |
| Argumenty | Określa tablicę argumentów dla zadania hadoop. Argumenty są przekazywane jako argumenty wiersza polecenia do każdego zadania. | Nie. |
| Definiuje | Określ parametry jako pary klucz/wartość, aby odwoływać się do skryptu Hive. | Nie. |
Powiązana zawartość
Zapoznaj się z następującymi artykułami, które wyjaśniają sposób przekształcania danych na inne sposoby: