Przekształcanie danych przez uruchomienie definicji zadania platformy Spark usługi Synapse Spark
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Działanie definicji zadania usługi Azure Synapse Spark w potoku uruchamia definicję zadania usługi Synapse Spark w obszarze roboczym usługi Azure Synapse Analytics. Ten artykuł opiera się na artykule dotyczącym działań przekształcania danych, który zawiera ogólne omówienie transformacji danych i obsługiwanych działań przekształcania.
Ustawianie kanwy definicji zadania platformy Apache Spark
Aby użyć działania definicji zadania platformy Spark dla usługi Synapse w potoku, wykonaj następujące kroki:
Ustawienia ogólne
Wyszukaj definicję zadania platformy Spark w okienku Działania potoku i przeciągnij działanie definicji zadania platformy Spark w obszarze synapse do kanwy potoku.
Wybierz nowe działanie definicji zadania platformy Spark na kanwie, jeśli nie zostało jeszcze wybrane.
Na karcie Ogólne wprowadź przykład w polu Nazwa.
(Opcja) Możesz również wprowadzić opis.
Limit czasu: maksymalny czas uruchomienia działania. Wartość domyślna to siedem dni, czyli maksymalny dozwolony czas. Format jest w formacie D.HH:MM:SS.
Ponów próbę: maksymalna liczba ponownych prób.
Interwał ponawiania prób: liczba sekund między poszczególnymi próbami ponawiania próby.
Bezpieczne dane wyjściowe: po zaznaczeniu dane wyjściowe z działania nie będą przechwytywane podczas rejestrowania.
Bezpieczne dane wejściowe: po zaznaczeniu dane wejściowe z działania nie będą przechwytywane podczas rejestrowania.
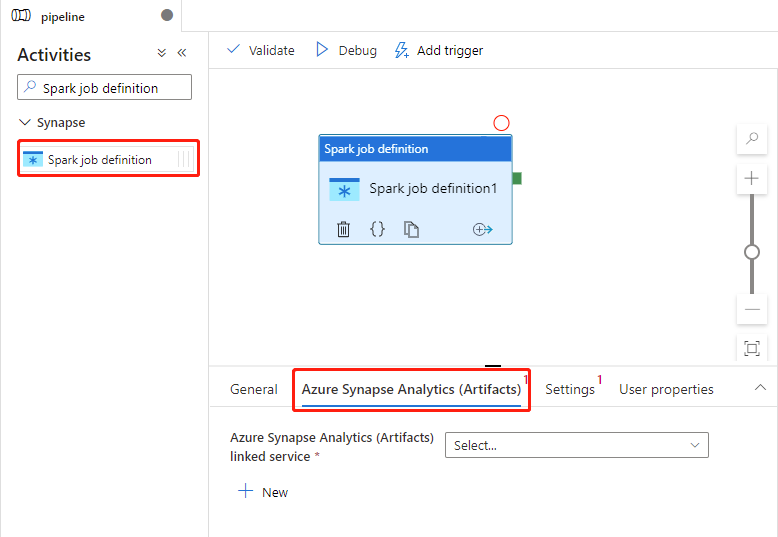
Ustawienia usługi Azure Synapse Analytics (Artefakty)
Wybierz nowe działanie definicji zadania platformy Spark na kanwie, jeśli nie zostało jeszcze wybrane.
Wybierz kartę Azure Synapse Analytics (Artifacts), aby wybrać lub utworzyć nową połączoną usługę Azure Synapse Analytics, która wykona działanie definicji zadania platformy Spark.
Karta Ustawienia
Wybierz nowe działanie definicji zadania platformy Spark na kanwie, jeśli nie zostało jeszcze wybrane.
Wybierz kartę Ustawienia.
Rozwiń listę definicji zadań platformy Spark. Możesz wybrać istniejącą definicję zadania platformy Apache Spark w połączonym obszarze roboczym usługi Azure Synapse Analytics.
(Opcjonalnie) Możesz wypełnić informacje dotyczące definicji zadania platformy Apache Spark. Jeśli następujące ustawienia są puste, do uruchomienia zostaną użyte ustawienia samej definicji zadania platformy Spark; Jeśli następujące ustawienia nie są puste, te ustawienia zastąpią ustawienia samej definicji zadania platformy Spark.
Właściwości opis Główny plik definicji Główny plik używany do zadania. Wybierz plik PY/JAR/ZIP z magazynu. Możesz wybrać pozycję Przekaż plik , aby przekazać plik na konto magazynu.
Przykład:abfss://…/path/to/wordcount.jarOdwołania z podfolderów Skanowanie podfolderów z folderu głównego głównego pliku definicji spowoduje dodanie tych plików jako plików referencyjnych. Foldery o nazwie "jars", "pyFiles", "files" lub "archives" będą skanowane, a nazwa folderów uwzględnia wielkość liter. Nazwa klasy głównej W pełni kwalifikowany identyfikator lub klasa główna, która znajduje się w głównym pliku definicji.
Przykład:WordCountArgumenty wiersza polecenia Argumenty wiersza polecenia można dodać, klikając przycisk Nowy . Należy zauważyć, że dodanie argumentów wiersza polecenia spowoduje zastąpienie argumentów wiersza polecenia zdefiniowanych przez definicję zadania platformy Spark.
Próbka:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultPula platformy Apache Spark Z listy możesz wybrać pulę platformy Apache Spark. Dokumentacja kodu w języku Python Dodatkowe pliki kodu języka Python używane do celów referencyjnych w głównym pliku definicji.
Obsługuje przekazywanie plików (.py, .py3, .zip) do właściwości "pyFiles". Spowoduje to zastąpienie właściwości "pyFiles" zdefiniowanej w definicji zadania platformy Spark.Pliki referencyjne Dodatkowe pliki używane do odwołania w głównym pliku definicji. Pula platformy Apache Spark Z listy możesz wybrać pulę platformy Apache Spark. Dynamiczne przydzielanie funkcji wykonawczych To ustawienie mapuje na właściwość alokacji dynamicznej w konfiguracji platformy Spark dla alokacji funkcji wykonawczych aplikacji platformy Spark. Minimalna liczba funkcji wykonawczych Minimalna liczba funkcji wykonawczych do przydzielenia w określonej puli Spark dla zadania. Maksymalna liczba funkcji wykonawczych Maksymalna liczba funkcji wykonawczych do przydzielenia w określonej puli Spark dla zadania. Rozmiar sterownika Liczba rdzeni i pamięci, które mają być używane dla sterownika podanego w określonej puli platformy Apache Spark dla zadania. Konfiguracja platformy Spark Określ wartości właściwości konfiguracji platformy Spark wymienione w temacie: Konfiguracja platformy Spark — właściwości aplikacji. Użytkownicy mogą używać konfiguracji domyślnej i dostosowanej konfiguracji. 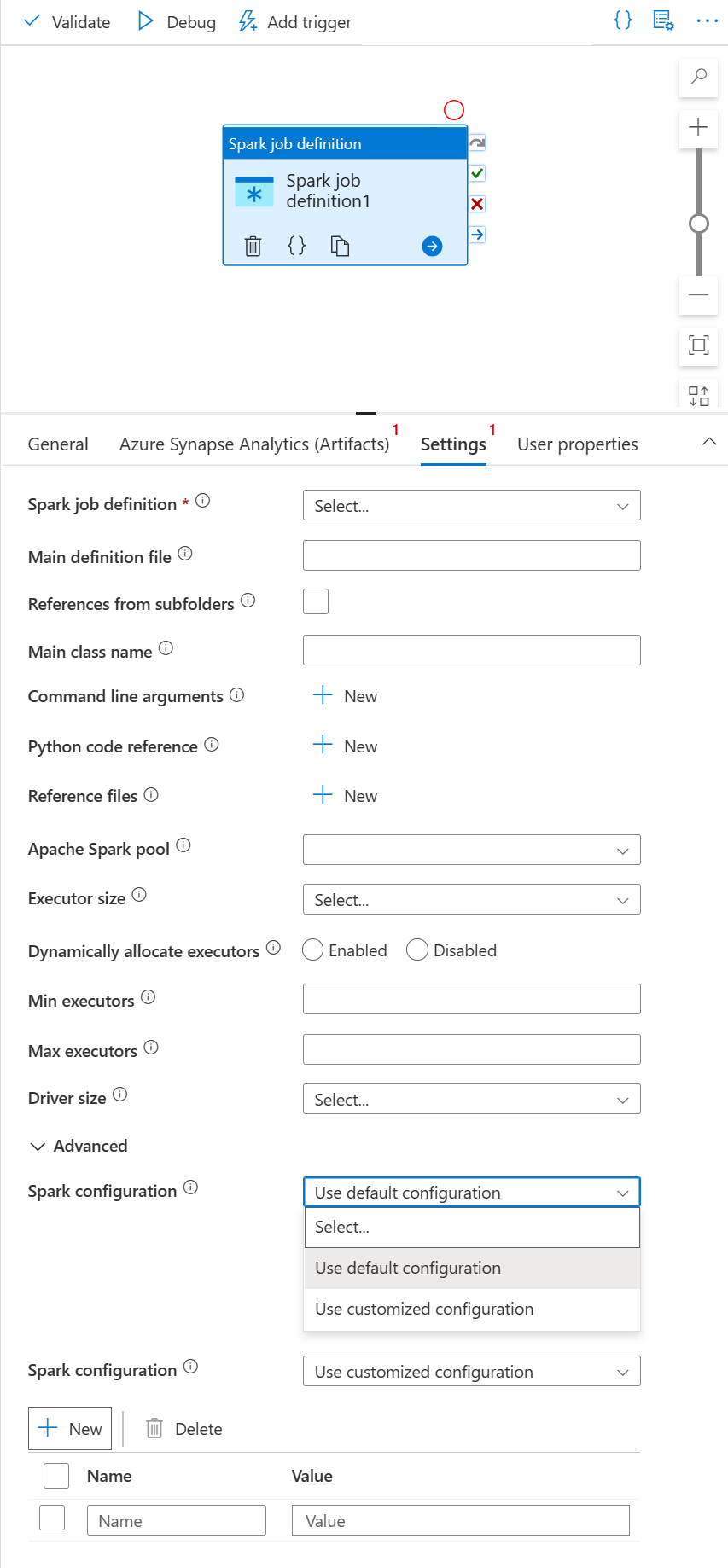
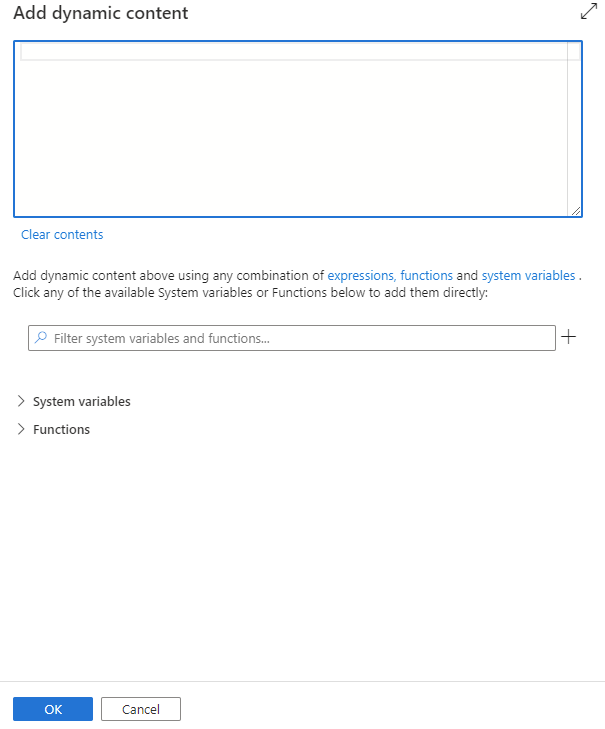
Zawartość dynamiczną można dodać, klikając przycisk Dodaj zawartość dynamiczną lub naciskając skrótu Alt+Shift+D. Na stronie Dodawanie zawartości dynamicznej można użyć dowolnej kombinacji wyrażeń, funkcji i zmiennych systemowych, aby dodać do zawartości dynamicznej.
Karta Właściwości użytkownika
W tym panelu można dodać właściwości działania definicji zadania platformy Apache Spark.
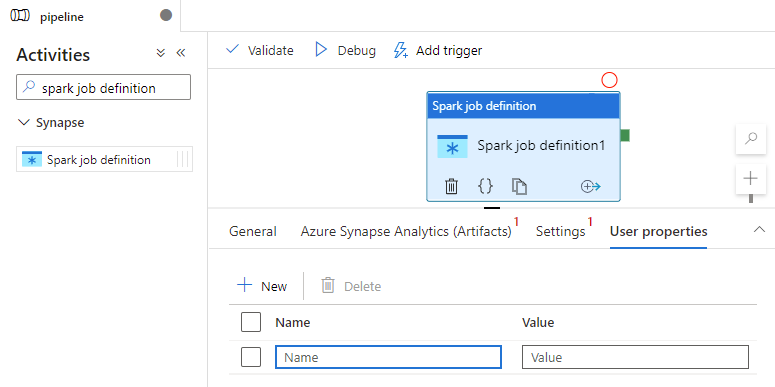
Definicja działania definicji zadania platformy Spark w usłudze Azure Synapse
Oto przykładowa definicja JSON działania notesu usługi Azure Synapse Analytics:
{
"activities": [
{
"name": "Spark job definition1",
"type": "SparkJob",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"typeProperties": {
"sparkJob": {
"referenceName": {
"value": "Spark job definition 1",
"type": "Expression"
},
"type": "SparkJobDefinitionReference"
}
},
"linkedServiceName": {
"referenceName": "AzureSynapseArtifacts1",
"type": "LinkedServiceReference"
}
}
],
}
Właściwości definicji zadania platformy Azure Synapse Spark
W poniższej tabeli opisano właściwości JSON używane w definicji JSON:
| Właściwości | Opis | Wymagania |
|---|---|---|
| name | Nazwa działania w potoku. | Tak |
| opis | Tekst opisujący działanie. | Nie. |
| type | W przypadku definicji zadania platformy Spark usługi Azure Synapse typ działania to SparkJob. | Tak |
Zobacz Historia uruchamiania definicji zadań platformy Azure Synapse Spark
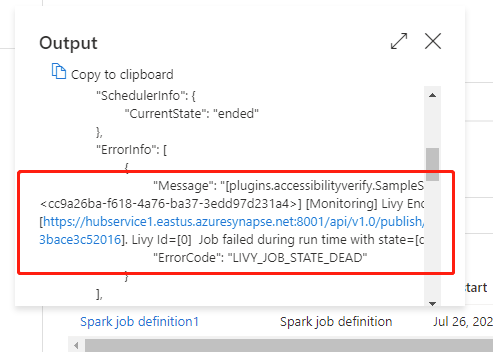
Przejdź do pozycji Uruchomienia potoku na karcie Monitor . Zobaczysz wyzwolony potok. Otwórz potok zawierający działanie definicji zadania platformy Azure Synapse Spark, aby wyświetlić historię uruchamiania.
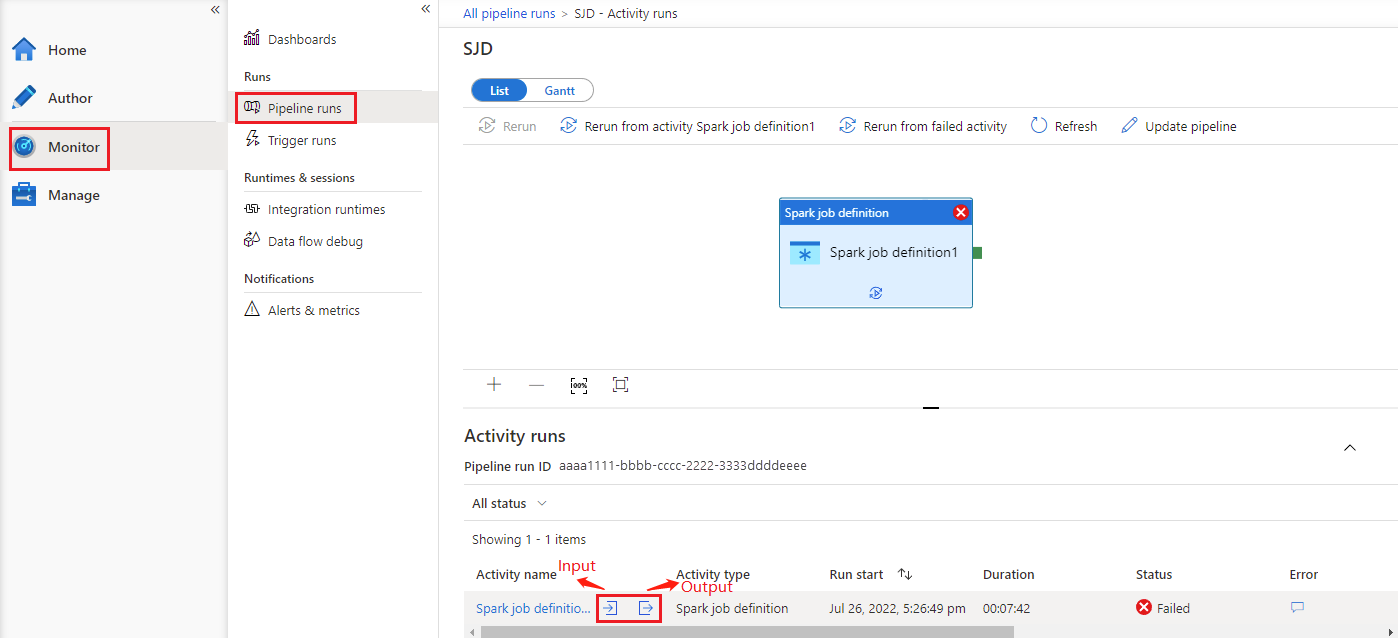
Dane wejściowe lub wyjściowe działania notesu można wyświetlić, wybierając przycisk dane wejściowe lub wyjściowe. Jeśli potok nie powiódł się z powodu błędu użytkownika, wybierz dane wyjściowe , aby sprawdzić pole wyniku , aby wyświetlić szczegółowe śledzenie błędów użytkownika.