Przekształcanie za pomocą usługi Azure Databricks
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
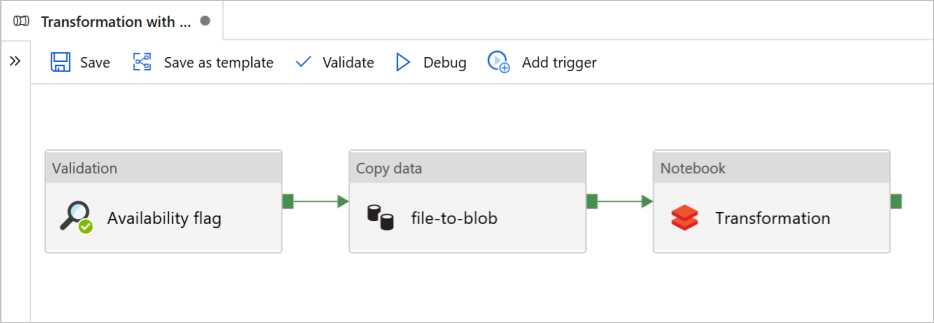
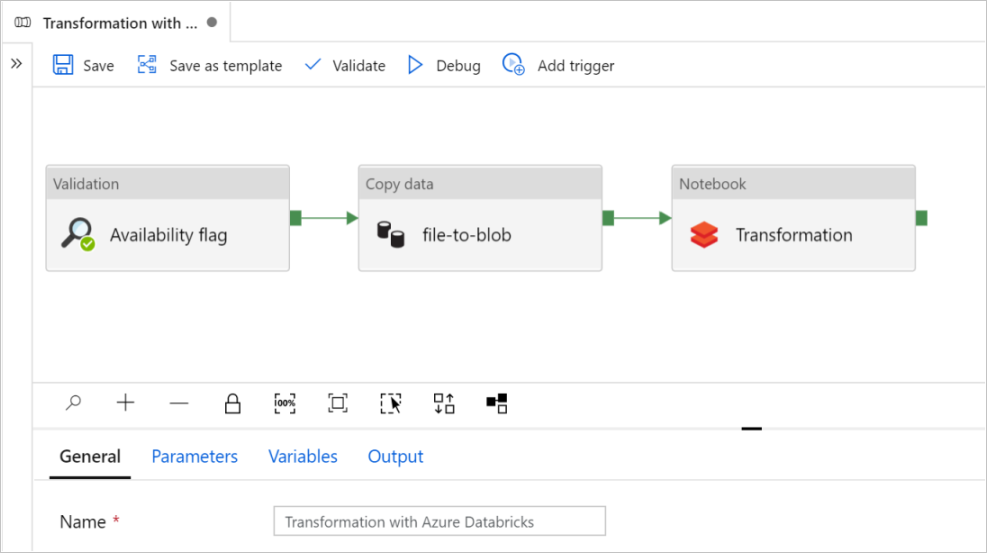
W tym samouczku utworzysz pełny potok zawierający działania walidacji, kopiowania danych i notesu w usłudze Azure Data Factory.
Weryfikacja gwarantuje, że źródłowy zestaw danych jest gotowy do użycia podrzędnego przed wyzwoleniem zadania kopiowania i analizy.
Kopiowanie danych duplikuje źródłowy zestaw danych do magazynu ujścia, który jest instalowany jako system plików DBFS w notesie usługi Azure Databricks. W ten sposób zestaw danych może być używany bezpośrednio przez platformę Spark.
Notes wyzwala notes usługi Databricks, który przekształca zestaw danych. Dodaje również zestaw danych do przetworzonego folderu lub usługi Azure Synapse Analytics.
Dla uproszczenia szablon w tym samouczku nie tworzy zaplanowanego wyzwalacza. W razie potrzeby możesz go dodać.
Wymagania wstępne
Konto usługi Azure Blob Storage z kontenerem wywoływanym
sinkdatado użycia jako ujście.Zanotuj nazwę konta magazynu, nazwę kontenera i klucz dostępu. Te wartości będą potrzebne w dalszej części szablonu.
Obszar roboczy usługi Azure Databricks.
Importowanie notesu na potrzeby transformacji
Aby zaimportować notes przekształcenia do obszaru roboczego usługi Databricks:
Zaloguj się do obszaru roboczego usługi Azure Databricks.
Kliknij prawym przyciskiem myszy folder w obszarze roboczym i wybierz polecenie Importuj.
Wybierz pozycję Importuj z: adres URL. W polu tekstowym wprowadź .
https://adflabstaging1.blob.core.windows.net/share/Transformations.html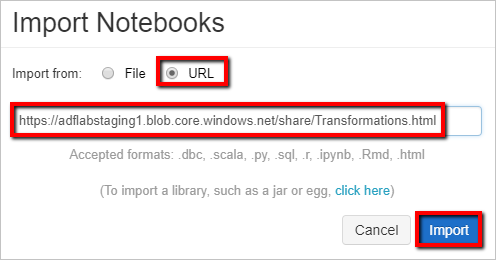
Teraz zaktualizujmy notes przekształcenia przy użyciu informacji o połączeniu magazynu.
W zaimportowanych notesach przejdź do polecenia 5 , jak pokazano w poniższym fragmencie kodu.
- Zastąp
<storage name>wartości i<access key>własnymi informacjami o połączeniu magazynu. - Użyj konta magazynu z kontenerem
sinkdata.
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.- Zastąp
Wygeneruj token dostępu usługi Databricks dla usługi Data Factory, aby uzyskać dostęp do usługi Databricks.
- W obszarze roboczym usługi Azure Databricks wybierz nazwę użytkownika usługi Azure Databricks na górnym pasku, a następnie wybierz pozycję Ustawienia z listy rozwijanej.
- Wybierz pozycję Deweloper.
- Obok pozycji Tokeny dostępu wybierz pozycję Zarządzaj.
- Wybierz pozycję Generuj nowy token.
- (Opcjonalnie) Wprowadź komentarz, który pomaga zidentyfikować ten token w przyszłości i zmienić domyślny okres istnienia tokenu na 90 dni. Aby utworzyć token bez okresu istnienia (niezalecane), pozostaw puste pole Okres istnienia (dni) (puste).
- Wybierz Generuj.
- Skopiuj wyświetlony token do bezpiecznej lokalizacji, a następnie wybierz pozycję Gotowe.
Zapisz token dostępu do późniejszego użycia podczas tworzenia połączonej usługi Databricks. Token dostępu wygląda mniej więcej tak: dapi32db32cbb4w6eee18b7d87e45exxxxxx.
Jak używać tego szablonu
Przejdź do szablonu Przekształcanie za pomocą usługi Azure Databricks i utwórz nowe połączone usługi dla następujących połączeń.
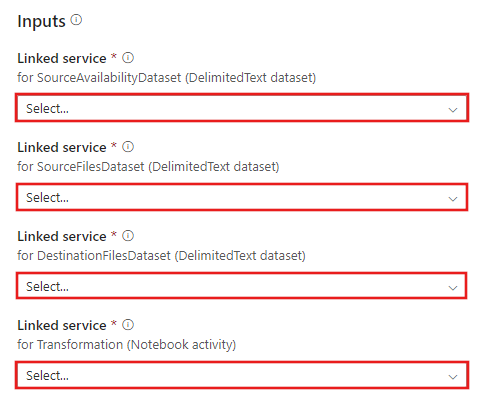
Połączenie źródłowego obiektu blob — aby uzyskać dostęp do danych źródłowych.
W tym ćwiczeniu można użyć publicznego magazynu obiektów blob, który zawiera pliki źródłowe. Aby uzyskać informacje o konfiguracji, zobacz poniższy zrzut ekranu. Użyj następującego adresu URL sygnatury dostępu współdzielonego, aby nawiązać połączenie z magazynem źródłowym (dostęp tylko do odczytu):
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D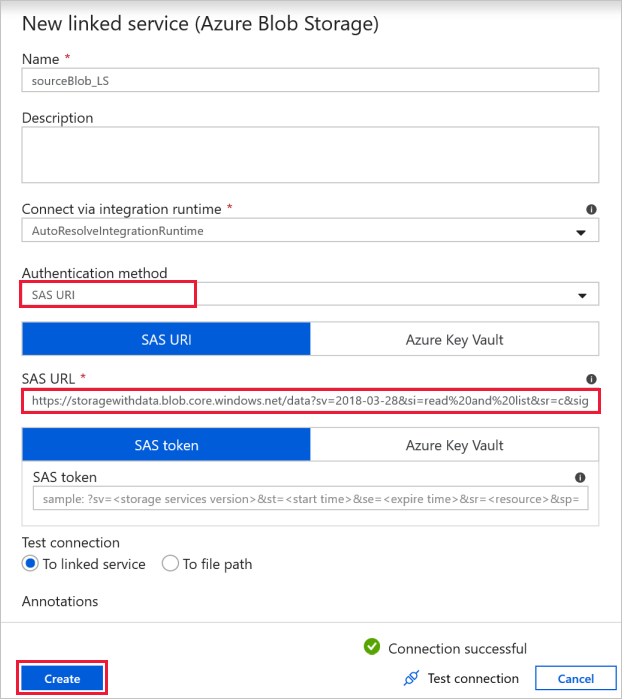
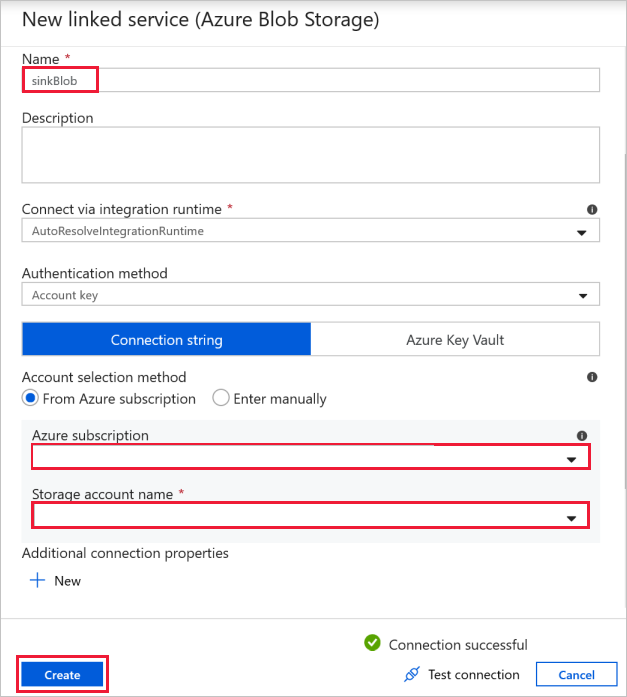
Docelowe połączenie obiektu blob — do przechowywania skopiowanych danych.
W oknie Nowa połączona usługa wybierz obiekt blob magazynu ujścia.
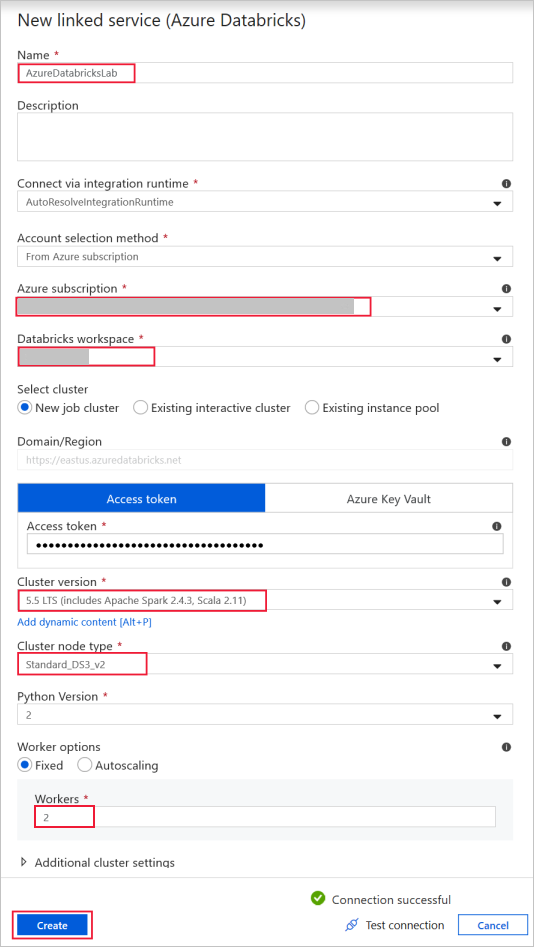
Azure Databricks — aby nawiązać połączenie z klastrem usługi Databricks.
Utwórz połączoną usługę Databricks przy użyciu wygenerowanego wcześniej klucza dostępu. Jeśli go masz, możesz wybrać klaster interaktywny. W tym przykładzie użyto opcji Nowy klaster zadań.
Wybierz Użyj tego szablonu. Zobaczysz utworzony potok.
Wprowadzenie i konfiguracja potoku
W nowym potoku większość ustawień jest konfigurowana automatycznie z wartościami domyślnymi. Przejrzyj konfiguracje potoku i wprowadź niezbędne zmiany.
W flagi Dostępność działania walidacji sprawdź, czy wartość źródłowego zestawu danych jest ustawiona na
SourceAvailabilityDatasetutworzoną wcześniej.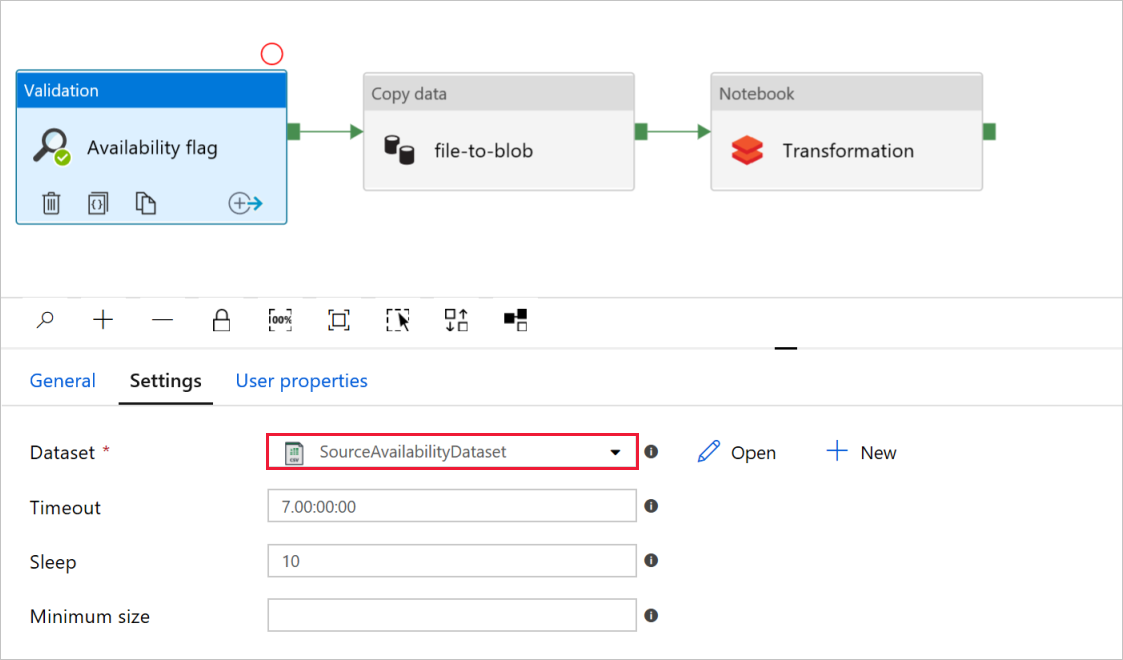
Na karcie Copy data activity file-to-blob (Kopiowanie pliku do obiektu blob) sprawdź karty Źródło i Ujście . W razie potrzeby zmień ustawienia.
Karta Źródło
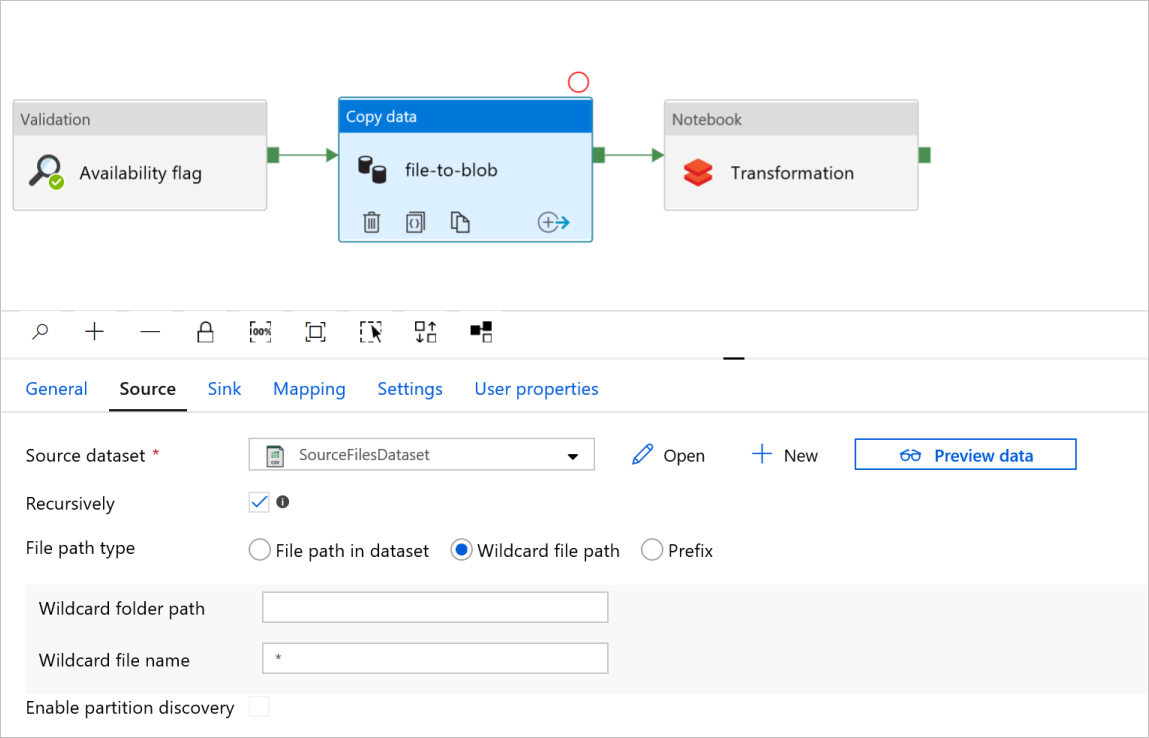
Karta Ujście
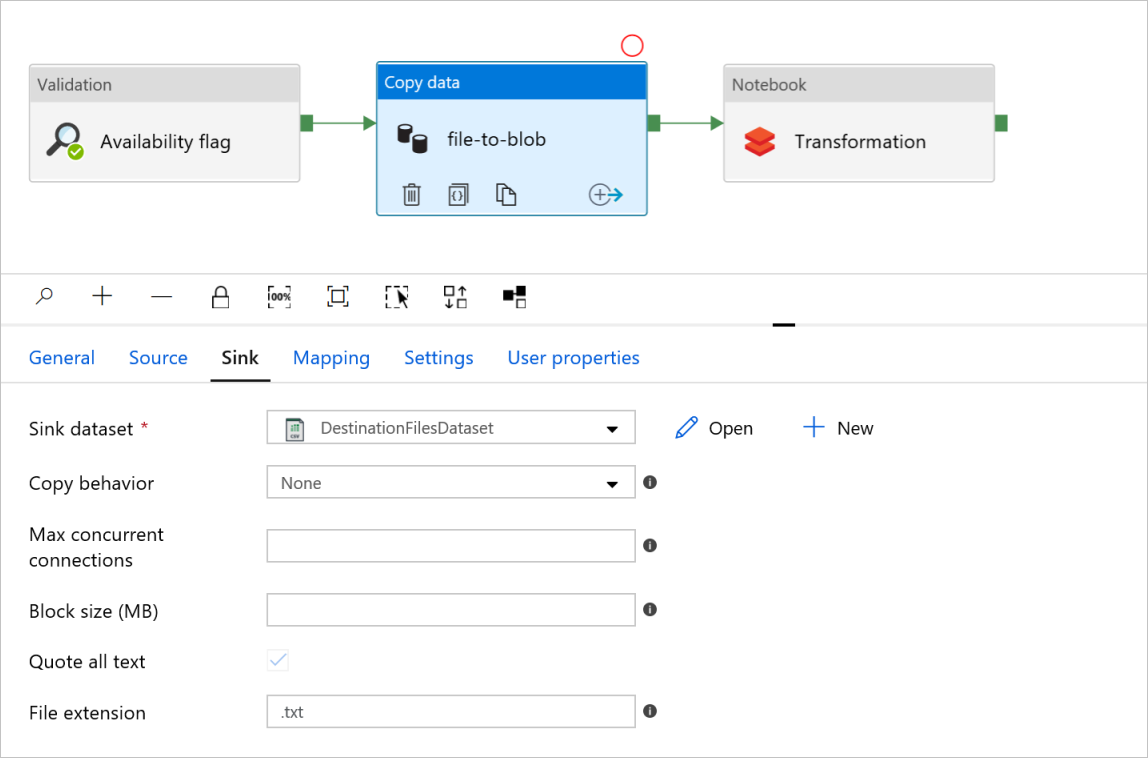
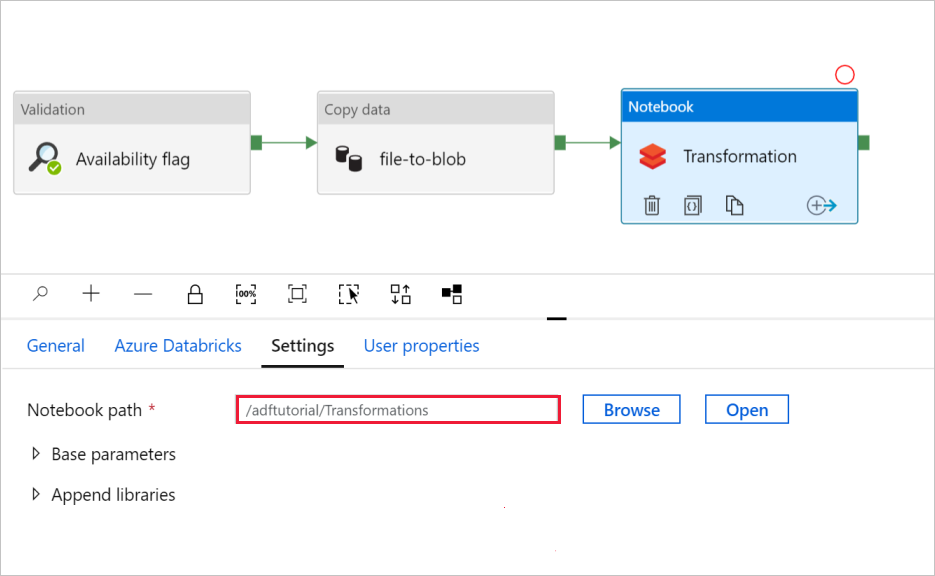
W obszarze Przekształcanie działania Notes przejrzyj i zaktualizuj ścieżki i ustawienia zgodnie z potrzebami.
Połączona usługa Databricks powinna zostać wstępnie wypełniona wartością z poprzedniego kroku, jak pokazano poniżej:
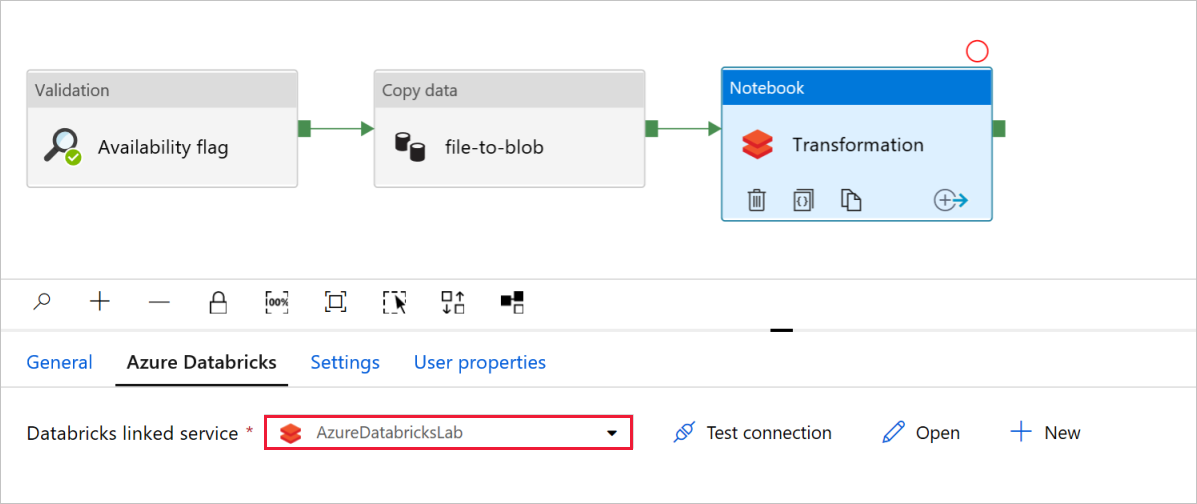
Aby sprawdzić ustawienia notesu:
Wybierz kartę Ustawienia . W polu Ścieżka notesu sprawdź, czy ścieżka domyślna jest poprawna. Może być konieczne przeglądanie i wybieranie właściwej ścieżki notesu.
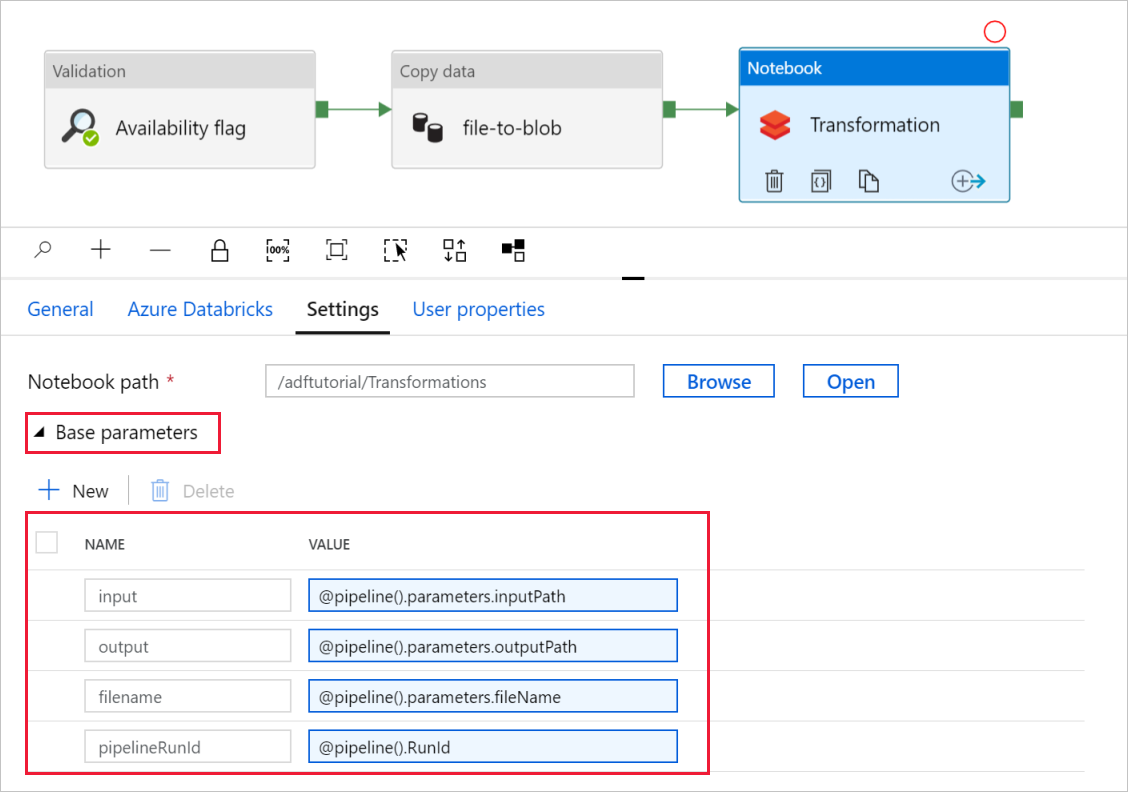
Rozwiń selektor Podstawowe parametry i sprawdź, czy parametry są zgodne z tym, co pokazano na poniższym zrzucie ekranu. Te parametry są przekazywane do notesu usługi Databricks z usługi Data Factory.
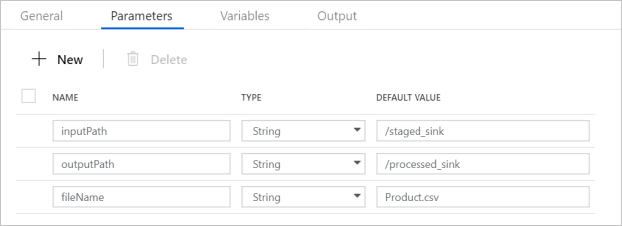
Sprawdź, czy parametry potoku są zgodne z tym, co pokazano na poniższym zrzucie ekranu:
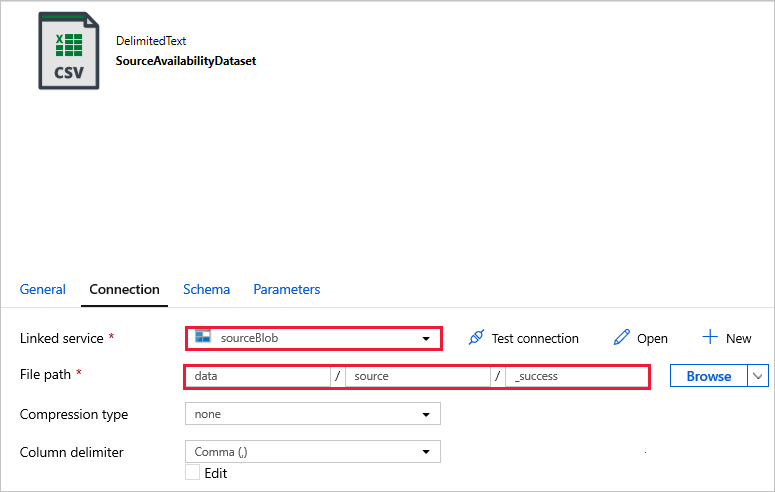
Połącz się z zestawami danych.
Uwaga
W poniższych zestawach danych ścieżka pliku została automatycznie określona w szablonie. Jeśli są wymagane jakiekolwiek zmiany, upewnij się, że określono ścieżkę zarówno dla kontenera , jak i katalogu w przypadku wystąpienia błędu połączenia.
SourceAvailabilityDataset — aby sprawdzić, czy dane źródłowe są dostępne.
SourceFilesDataset — aby uzyskać dostęp do danych źródłowych.
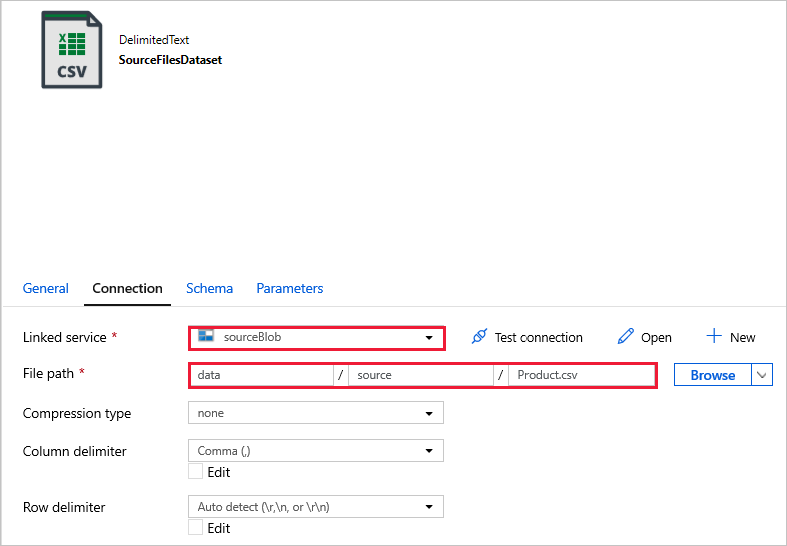
DestinationFilesDataset — aby skopiować dane do lokalizacji docelowej ujścia. Użyj następujących wartości:
Połączona usługa -
sinkBlob_LSutworzona w poprzednim kroku.Ścieżka -
sinkdata/staged_sinkpliku.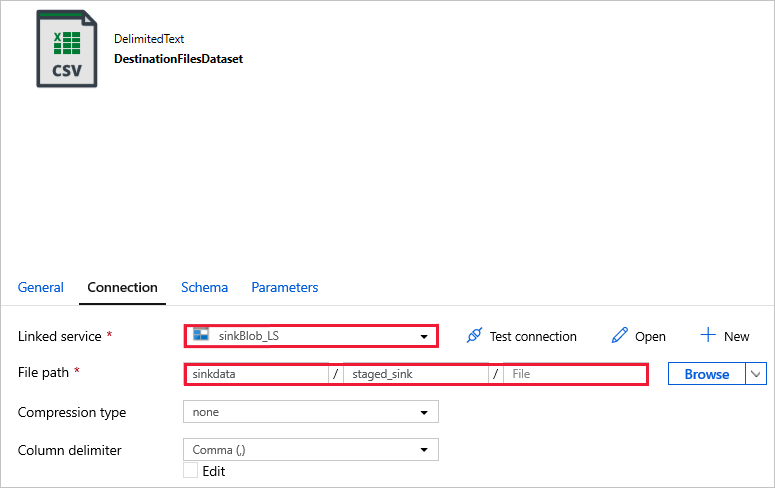
Wybierz pozycję Debuguj , aby uruchomić potok. Link do dzienników usługi Databricks można znaleźć, aby uzyskać bardziej szczegółowe dzienniki platformy Spark.
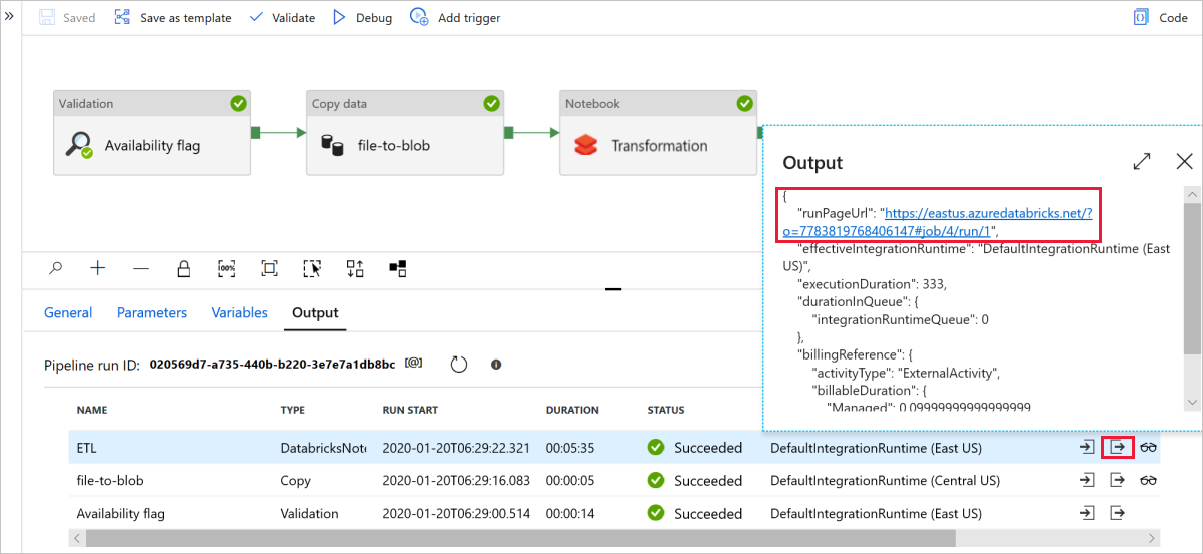
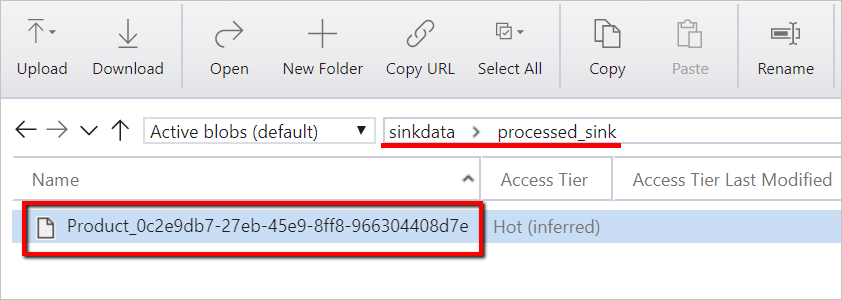
Plik danych można również zweryfikować przy użyciu Eksplorator usługi Azure Storage.
Uwaga
W przypadku korelacji z przebiegami potoku usługi Data Factory ten przykład dołącza identyfikator uruchomienia potoku z fabryki danych do folderu wyjściowego. Pomaga to śledzić pliki generowane przez każdy przebieg.