Programowanie i debugowanie iteracyjne przy użyciu potoków usługi Azure Data Factory i usługi Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Usługi Azure Data Factory i Synapse Analytics obsługują iteracyjne programowanie i debugowanie potoków. Te funkcje umożliwiają przetestowanie zmian przed utworzeniem żądania ściągnięcia lub opublikowaniem ich w usłudze.
Aby zapoznać się z ośmiominutowym wprowadzeniem i pokazem tej funkcji, obejrzyj następujący film wideo:
Debugowanie potoku
Podczas tworzenia przy użyciu kanwy potoku możesz przetestować działania przy użyciu funkcji Debugowanie . Po uruchomieniu testów nie trzeba publikować zmian w usłudze przed wybraniem pozycji Debuguj. Ta funkcja jest przydatna w scenariuszach, w których chcesz upewnić się, że zmiany działają zgodnie z oczekiwaniami przed zaktualizowaniem przepływu pracy.
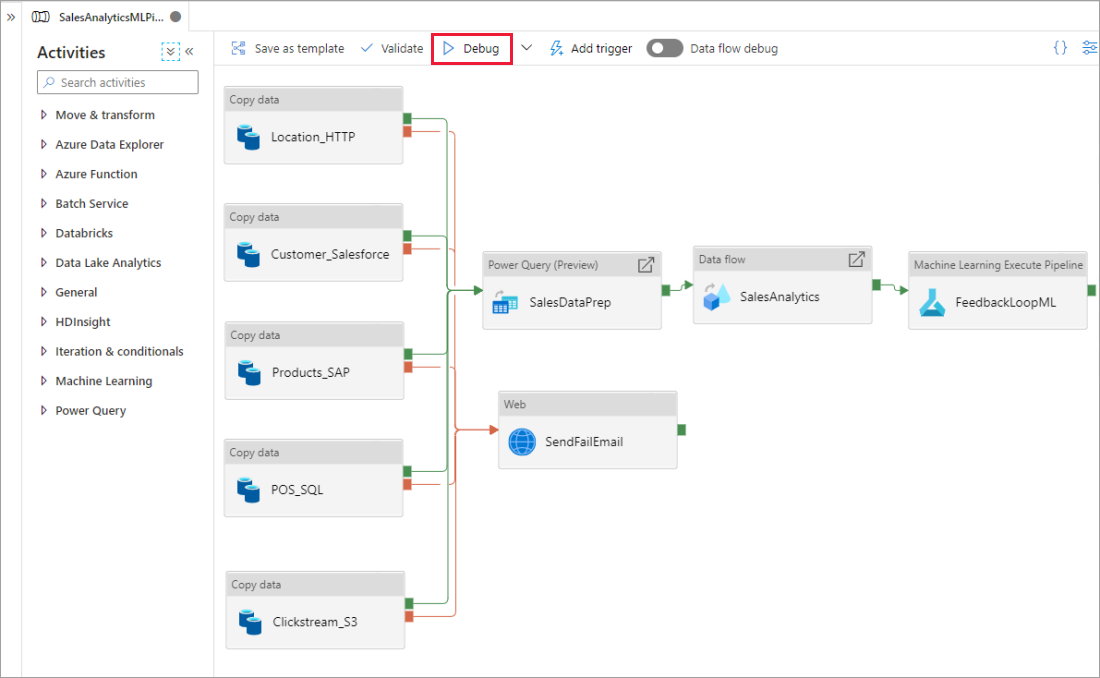
Po uruchomieniu potoku na karcie Dane wyjściowe kanwy potoku można zobaczyć wyniki każdego działania.
Wyświetl wyniki przebiegów testu w oknie Dane wyjściowe kanwy potoku.
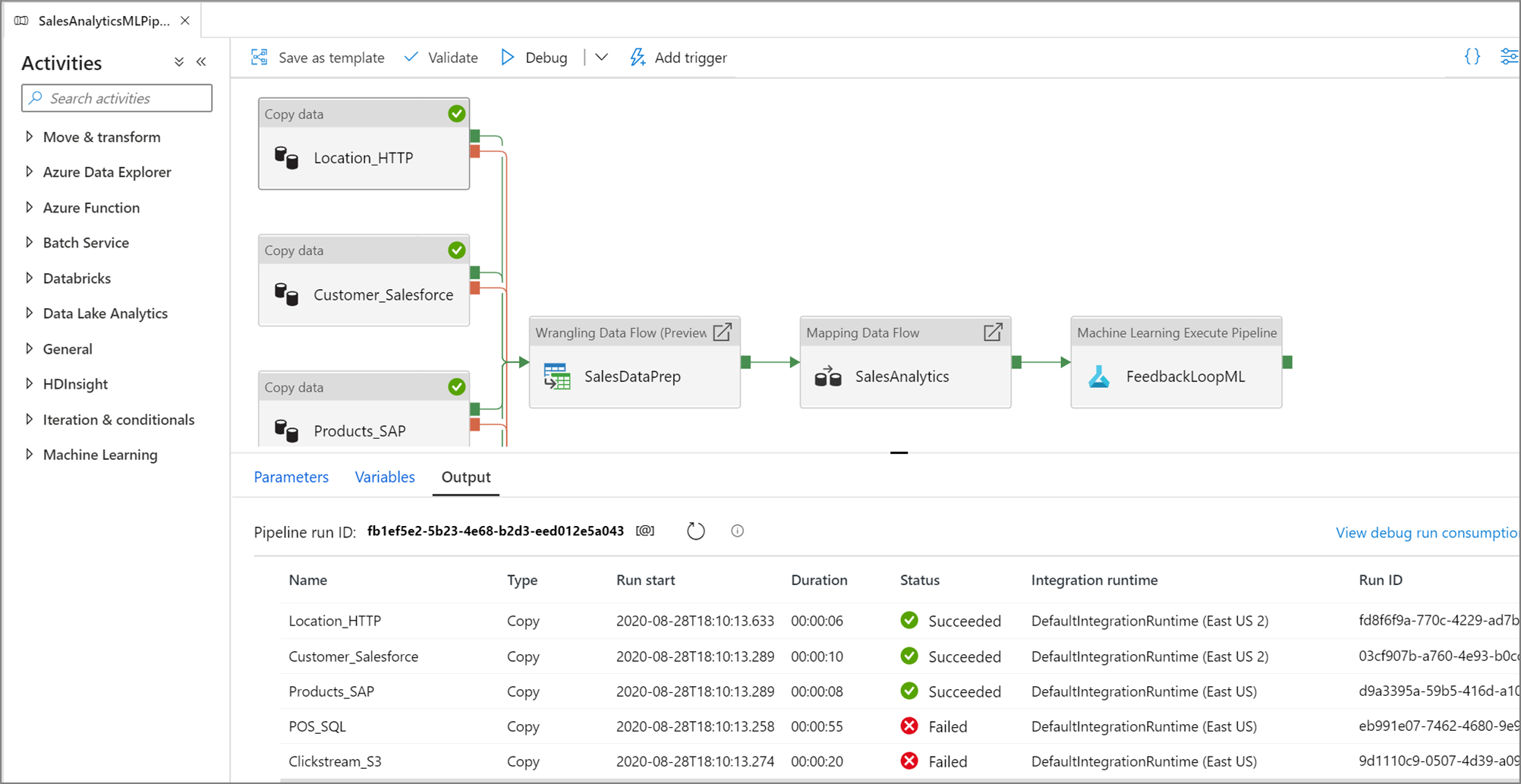
Po pomyślnym zakończeniu przebiegu testu dodaj więcej działań do potoku i kontynuuj debugowanie w sposób iteracyjny. Możesz również anulować przebieg testu, gdy jest on w toku.
Ważne
Wybranie pozycji Debugowanie powoduje uruchomienie potoku. Jeśli na przykład potok zawiera działanie kopiowania, przebieg testu kopiuje dane ze źródła do miejsca docelowego. W związku z tym zalecamy używanie folderów testowych w działaniach kopiowania i innych działaniach podczas debugowania. Po debugowania potoku przejdź do rzeczywistych folderów, które mają być używane w normalnych operacjach.
Ustawianie punktów przerwania
Usługa umożliwia debugowanie potoku do momentu osiągnięcia określonego działania na kanwie potoku. Umieść punkt przerwania w działaniu, do którego chcesz przetestować, i wybierz pozycję Debuguj. Usługa zapewnia, że test jest uruchamiany tylko do momentu działania punktu przerwania na kanwie potoku. Ta funkcja Debuguj do czasu jest przydatna, gdy nie chcesz testować całego potoku, ale tylko podzestaw działań wewnątrz potoku.
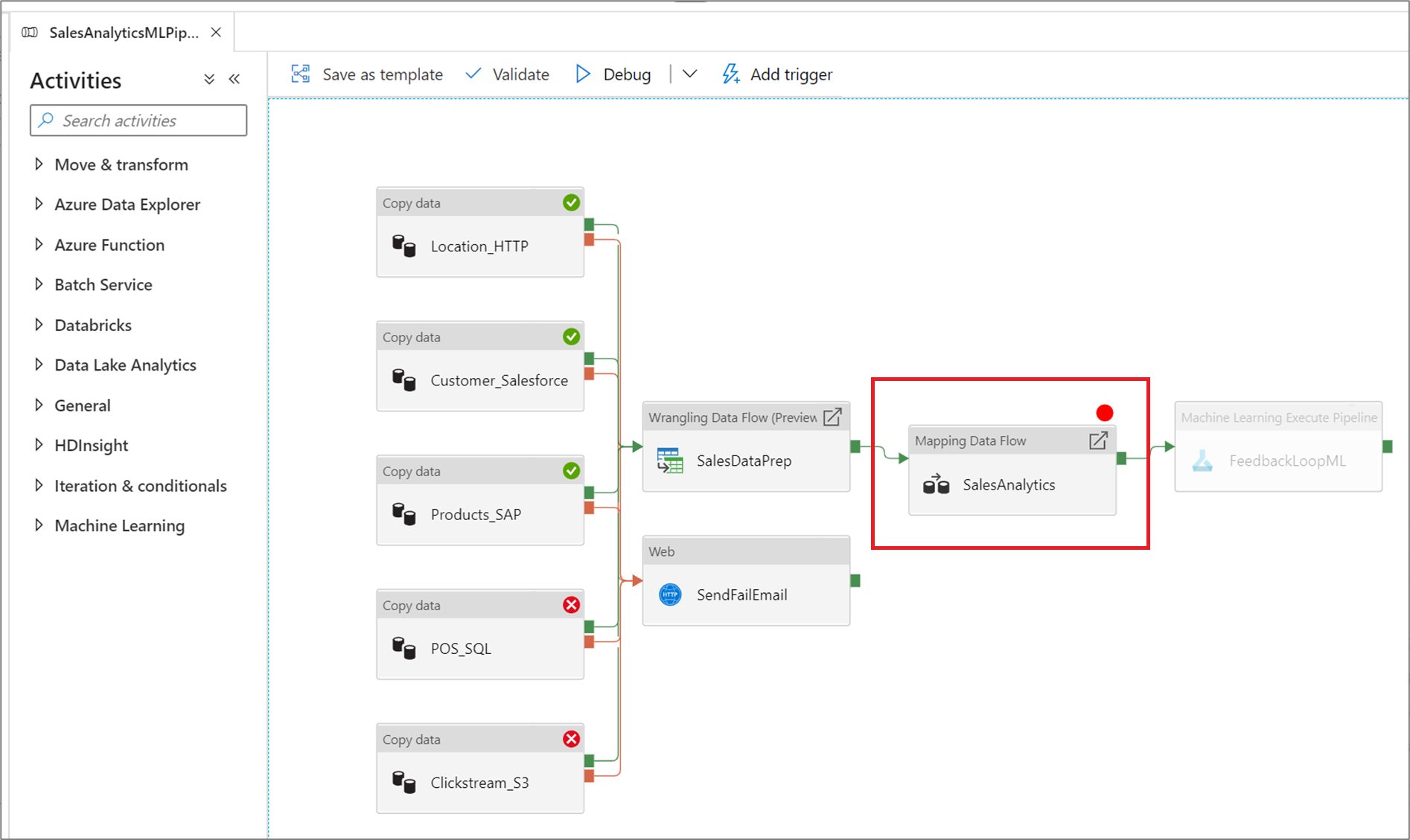
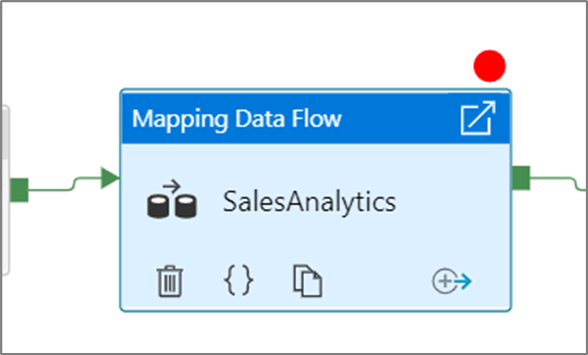
Aby ustawić punkt przerwania, wybierz element na kanwie potoku. Opcja Debuguj do jest wyświetlana jako puste czerwone kółko w prawym górnym rogu elementu.
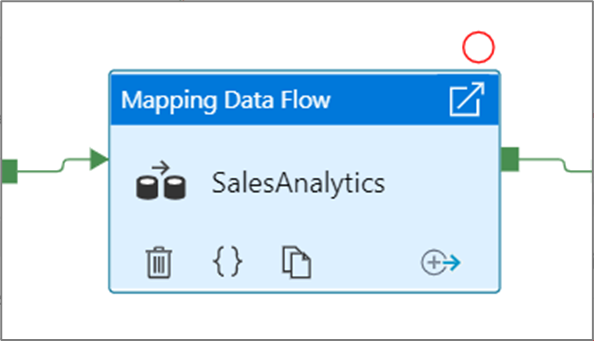
Po wybraniu opcji Debuguj do momentu zmieni się ona na wypełnione czerwone kółko, aby wskazać, że punkt przerwania jest włączony.
Monitorowanie przebiegów debugowania
Po uruchomieniu przebiegu debugowania potoku wyniki będą wyświetlane w oknie Dane wyjściowe kanwy potoku. Karta danych wyjściowych będzie zawierać tylko ostatnie uruchomienie, które wystąpiło podczas bieżącej sesji przeglądarki.
Aby wyświetlić widok historyczny przebiegów debugowania lub wyświetlić listę wszystkich aktywnych przebiegów debugowania, możesz przejść do środowiska Monitor .
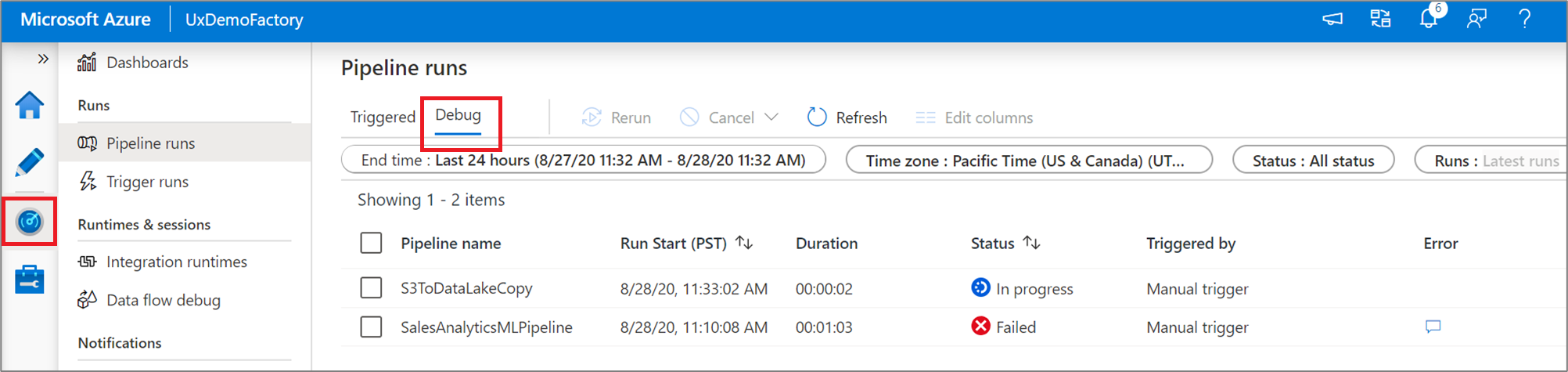
Uwaga
Usługa utrzymuje tylko historię uruchamiania debugowania przez 15 dni.
Debugowanie przepływów danych mapowania
Przepływy mapowania danych umożliwiają tworzenie logiki przekształcania danych bez użycia kodu, która działa na dużą skalę. Podczas tworzenia logiki możesz włączyć sesję debugowania, aby interaktywnie pracować z danymi przy użyciu dynamicznego klastra Spark. Aby dowiedzieć się więcej, przeczytaj o trybie debugowania przepływu mapowania danych.
Aktywne sesje debugowania przepływu danych można monitorować w środowisku monitora .
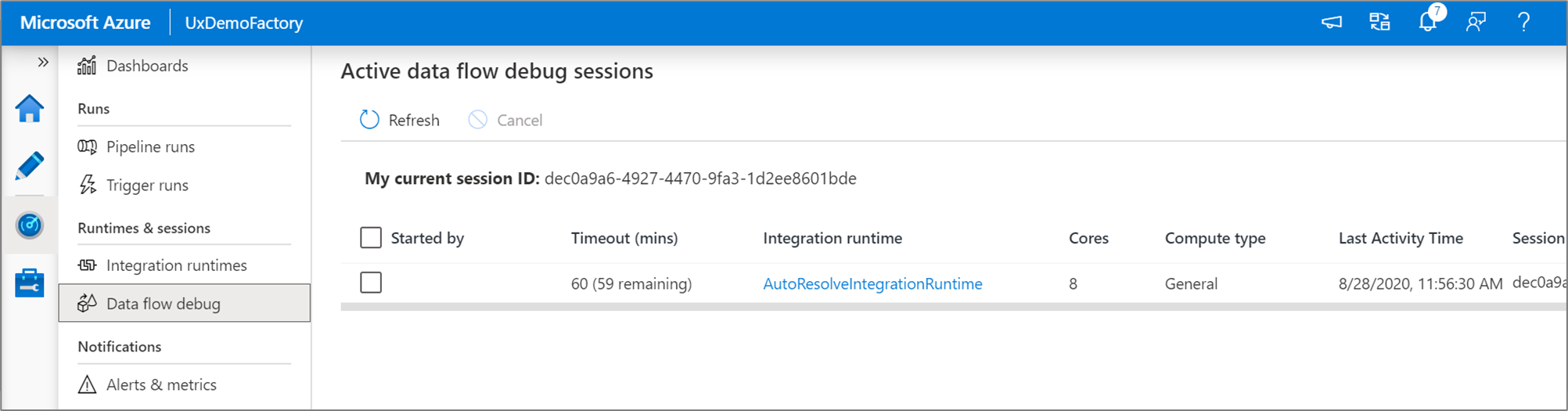
Podgląd danych w projektancie przepływu danych i debugowaniu potoków przepływów danych jest przeznaczony do pracy z małymi próbkami danych. Jeśli jednak musisz przetestować logikę w potoku lub przepływie danych pod kątem dużych ilości danych, zwiększ rozmiar środowiska Azure Integration Runtime używanego w sesji debugowania z większą liczbie rdzeni i co najmniej obliczenia ogólnego przeznaczenia.
Debugowanie potoku za pomocą działania przepływu danych
Podczas wykonywania przebiegu potoku debugowania przy użyciu przepływu danych dostępne są dwie opcje użycia obliczeń. Możesz użyć istniejącego klastra debugowania lub użyć nowego klastra just in time dla przepływów danych.
Użycie istniejącej sesji debugowania znacznie zmniejszy czas uruchamiania przepływu danych, ponieważ klaster jest już uruchomiony, ale nie jest zalecany w przypadku złożonych lub równoległych obciążeń, ponieważ może się to nie powieść, gdy wiele zadań jest uruchamianych jednocześnie.
Użycie środowiska uruchomieniowego działania spowoduje utworzenie nowego klastra przy użyciu ustawień określonych w środowisku Integration Runtime każdego przepływu danych. Umożliwia to izolowanie każdego zadania i powinno być używane na potrzeby złożonych obciążeń lub testów wydajnościowych. Możesz również kontrolować czas wygaśnięcia w środowisku Azure IR, aby zasoby klastra używane do debugowania były nadal dostępne przez ten okres w celu obsługi dodatkowych żądań zadań.
Uwaga
Jeśli masz potok z przepływami danych wykonywanymi równolegle lub przepływami danych, które muszą być przetestowane z dużymi zestawami danych, wybierz pozycję "Użyj środowiska uruchomieniowego działania", aby usługa mogła używać środowiska Integration Runtime wybranego w działaniu przepływu danych. Umożliwi to wykonywanie przepływów danych w wielu klastrach i może obsługiwać równoległe wykonywanie przepływów danych.
Powiązana zawartość
Po przetestowaniu zmian podwyższ ich poziom do wyższych środowisk przy użyciu ciągłej integracji i ciągłego wdrażania.