Migrowanie znormalizowanego schematu bazy danych z usługi Azure SQL Database do zdenormalizowanego kontenera usługi Azure Cosmos DB
W tym przewodniku wyjaśniono, jak zastosować istniejący znormalizowany schemat bazy danych w usłudze Azure SQL Database i przekonwertować go na zdenormalizowany schemat usługi Azure Cosmos DB na potrzeby ładowania do usługi Azure Cosmos DB.
Schematy SQL są zwykle modelowane przy użyciu trzeciej formy normalnej, co powoduje znormalizowane schematy zapewniające wysoki poziom integralności danych i mniej zduplikowanych wartości danych. Zapytania mogą łączyć jednostki między tabelami w celu odczytu. Usługa Azure Cosmos DB jest zoptymalizowana pod kątem super-szybkich transakcji i wykonywania zapytań w ramach kolekcji lub kontenera za pomocą zdenormalizowanych schematów z danymi samodzielnie zawartymi w dokumencie.
Za pomocą usługi Azure Data Factory utworzymy potok, który używa pojedynczego Przepływ danych mapowania do odczytu z dwóch znormalizowanych tabel usługi Azure SQL Database zawierających klucze podstawowe i obce jako relację jednostki. Fabryka danych połączy te tabele w jednym strumieniu przy użyciu aparatu Spark przepływu danych, zbierze sprzężone wiersze w tablice i utworzy indywidualne oczyszczone dokumenty w celu wstawienia do nowego kontenera usługi Azure Cosmos DB.
Ten przewodnik tworzy nowy kontener na bieżąco o nazwie "orders", który będzie używać SalesOrderHeader tabel i SalesOrderDetail ze standardowej przykładowej bazy danych SQL Server Adventure Works. Te tabele reprezentują transakcje sprzedaży połączone przez SalesOrderID. Każdy unikatowy rekord szczegółów ma własny klucz SalesOrderDetailIDpodstawowy . Relacja między nagłówkem a szczegółem to 1:M. Dołączamy SalesOrderID do usługi ADF, a następnie umieszczamy każdy powiązany rekord szczegółów w tablicy o nazwie "detail".
Reprezentatywne zapytanie SQL dla tego przewodnika to:
SELECT
o.SalesOrderID,
o.OrderDate,
o.Status,
o.ShipDate,
o.SalesOrderNumber,
o.ShipMethod,
o.SubTotal,
(select SalesOrderDetailID, UnitPrice, OrderQty from SalesLT.SalesOrderDetail od where od.SalesOrderID = o.SalesOrderID for json auto) as OrderDetails
FROM SalesLT.SalesOrderHeader o;
Wynikowy kontener usługi Azure Cosmos DB osadza zapytanie wewnętrzne w jednym dokumencie i wygląda następująco:

Tworzenie potoku
Wybierz pozycję +Nowy potok , aby utworzyć nowy potok.
Dodawanie działania przepływu danych
W działaniu przepływu danych wybierz pozycję Nowy przepływ mapowania danych.
Tworzymy ten wykres przepływu danych:
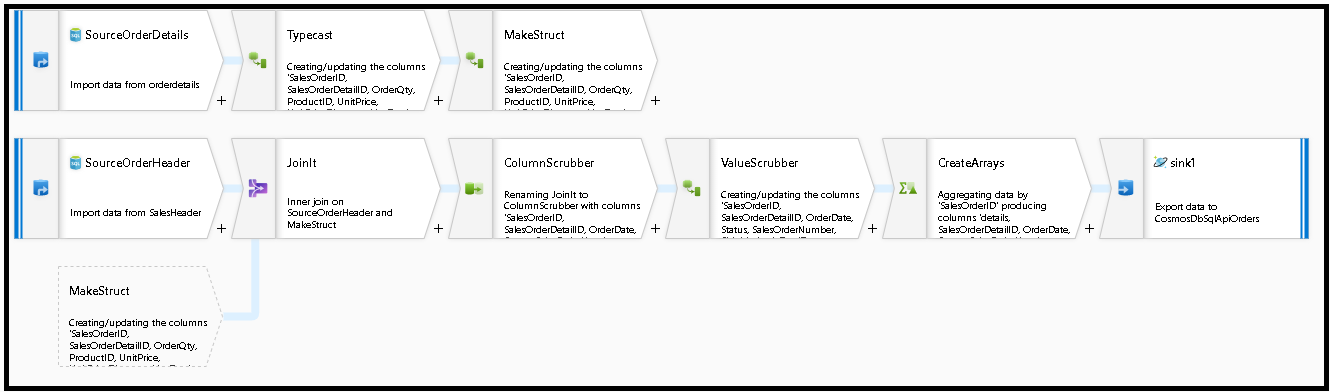
Zdefiniuj źródło dla elementu "SourceOrderDetails". W przypadku zestawu danych utwórz nowy zestaw danych usługi Azure SQL Database, który wskazuje tabelę
SalesOrderDetail.Zdefiniuj źródło "SourceOrderHeader". W przypadku zestawu danych utwórz nowy zestaw danych usługi Azure SQL Database, który wskazuje tabelę
SalesOrderHeader.W górnym źródle dodaj przekształcenie kolumny pochodnej po "SourceOrderDetails". Wywołaj nową transformację "TypeCast". Musimy zaokrąglić kolumnę
UnitPricei rzutować ją na podwójny typ danych dla usługi Azure Cosmos DB. Ustaw formułę na:toDouble(round(UnitPrice,2)).Dodaj kolejną kolumnę pochodną i wywołaj ją "MakeStruct". W tym miejscu tworzymy strukturę hierarchiczną do przechowywania wartości z tabeli szczegółów. Pamiętaj, że szczegóły są relacją z nagłówkiem
M:1. Nadaj nowej strukturzeorderdetailsstructnazwę i utwórz hierarchię w ten sposób, ustawiając każdy podkolumn na nazwę przychodzącej kolumny: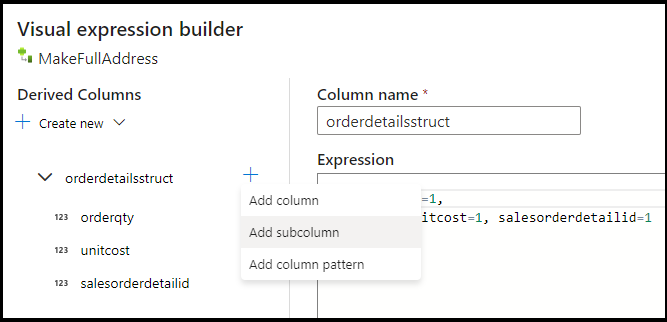
Teraz przejdźmy do źródła nagłówka sprzedaży. Dodaj przekształcenie sprzężenia. Po prawej stronie wybierz pozycję "MakeStruct". Pozostaw wartość sprzężenia wewnętrznego i wybierz
SalesOrderIDdla obu stron warunku sprzężenia.Wybierz kartę Podgląd danych w dodanym nowym sprzężeniu, aby zobaczyć wyniki do tego momentu. Powinny zostać wyświetlone wszystkie wiersze nagłówka połączone ze szczegółowymi wierszami. Jest to wynik sprzężenia tworzonego z obiektu
SalesOrderID. Następnie połączymy szczegóły z typowych wierszy w strukturę szczegółów i zagregujemy typowe wiersze.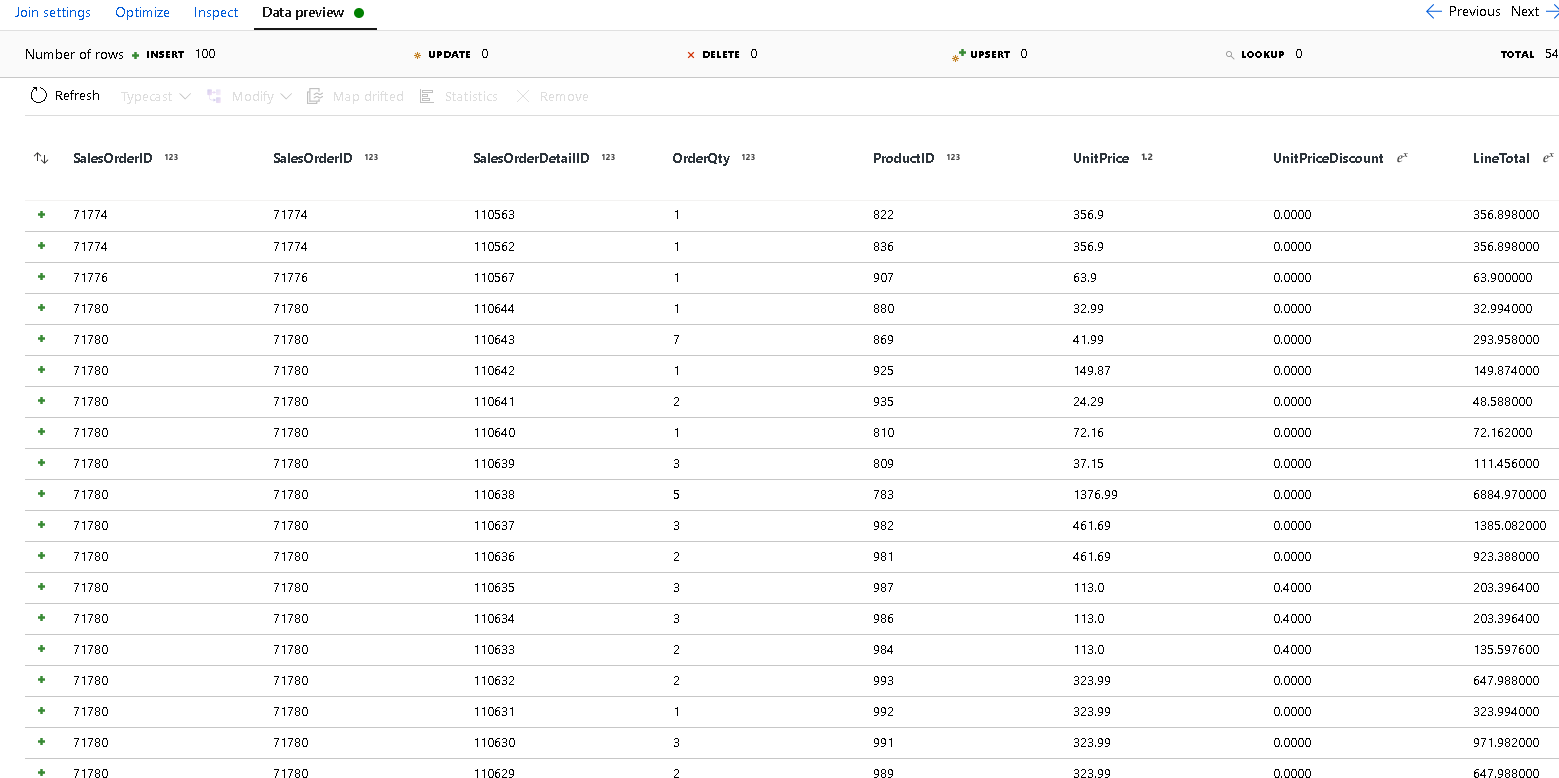
Zanim będziemy mogli utworzyć tablice, aby zdenormalizować te wiersze, najpierw musimy usunąć niechciane kolumny i upewnić się, że wartości danych są zgodne z typami danych usługi Azure Cosmos DB.
Dodaj przekształcenie Select (Wybierz przekształcenie) i ustaw mapowanie pól tak, aby wyglądało następująco:
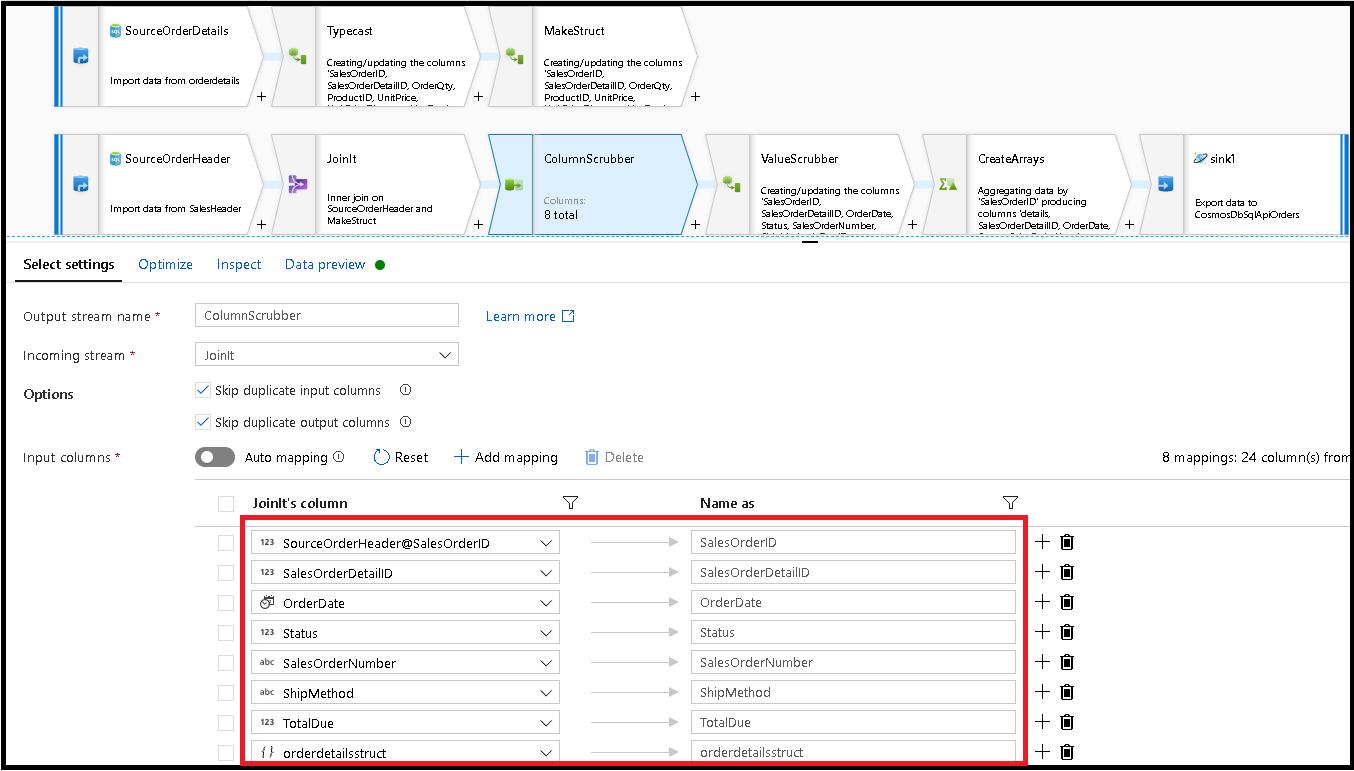
Teraz ponownie rzutujmy kolumnę waluty, tym razem
TotalDue. Podobnie jak w powyższym kroku 7 ustaw formułę na :toDouble(round(TotalDue,2)).Tutaj denormalizujemy wiersze, grupując według klucza
SalesOrderIDwspólnego . Dodaj przekształcenie agregacji i ustaw grupę według na .SalesOrderIDW formule agregującej dodaj nową kolumnę o nazwie "details" i użyj tej formuły, aby zebrać wartości w strukturze utworzonej wcześniej o nazwie
orderdetailsstruct:collect(orderdetailsstruct).Przekształcenie agregujące będzie zawierać tylko kolumny, które są częścią agregacji lub grupowania według formuł. Dlatego musimy również uwzględnić kolumny z nagłówka sprzedaży. W tym celu dodaj wzorzec kolumny w tej samej transformacji agregującej. Ten wzorzec zawiera wszystkie inne kolumny w danych wyjściowych, z wyłączeniem kolumn wymienionych poniżej (OrderQty, UnitPrice, SalesOrderID):
instr(name,'OrderQty')==0&&instr(name,'UnitPrice')==0&&instr(name,'SalesOrderID')==0
Użyj składni "this" ($$) w innych właściwościach, aby zachować te same nazwy kolumn i użyć
first()funkcji jako agregacji. Spowoduje to, że usługa ADF zachowa pierwszą zgodną wartość: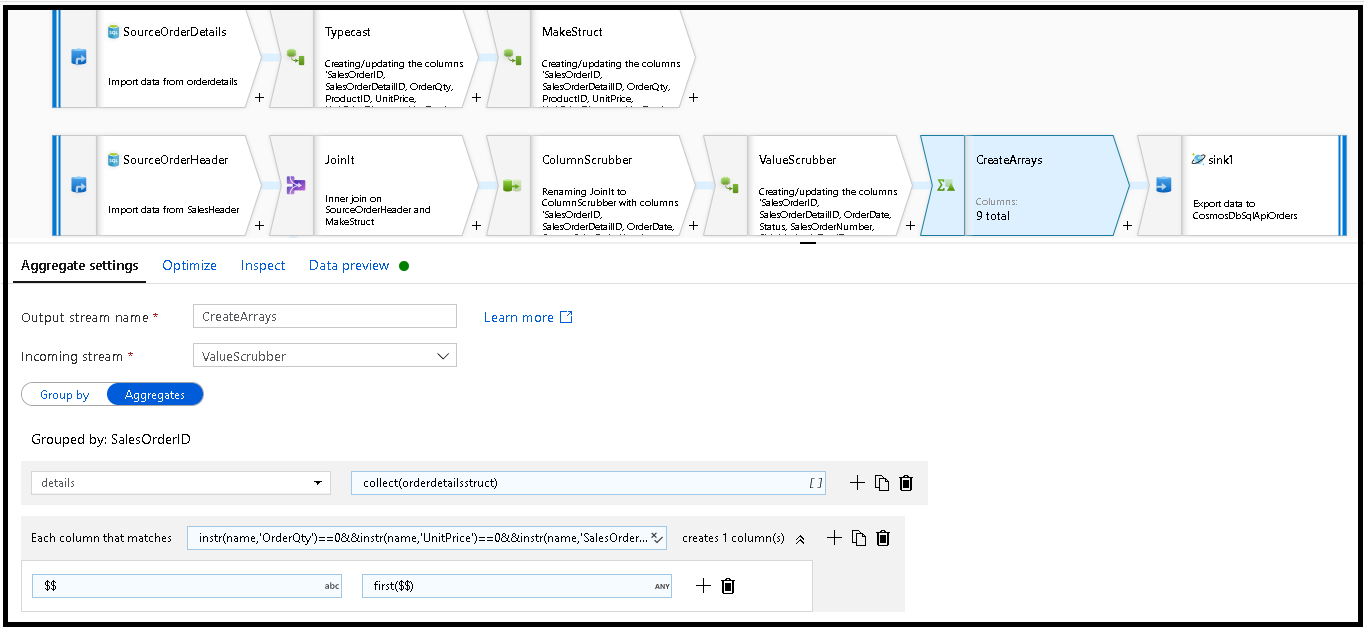
Jesteśmy gotowi do zakończenia przepływu migracji przez dodanie przekształcenia ujścia. Wybierz pozycję "new" obok zestawu danych i dodaj zestaw danych usługi Azure Cosmos DB, który wskazuje bazę danych usługi Azure Cosmos DB. W przypadku kolekcji nazywamy ją "zamówieniami" i nie ma schematu i żadnych dokumentów, ponieważ zostanie ona utworzona na bieżąco.
W obszarze Ustawienia ujścia klucz partycji do
/SalesOrderIDi akcja kolekcji w celu "odtworzenia". Upewnij się, że karta mapowania wygląda następująco: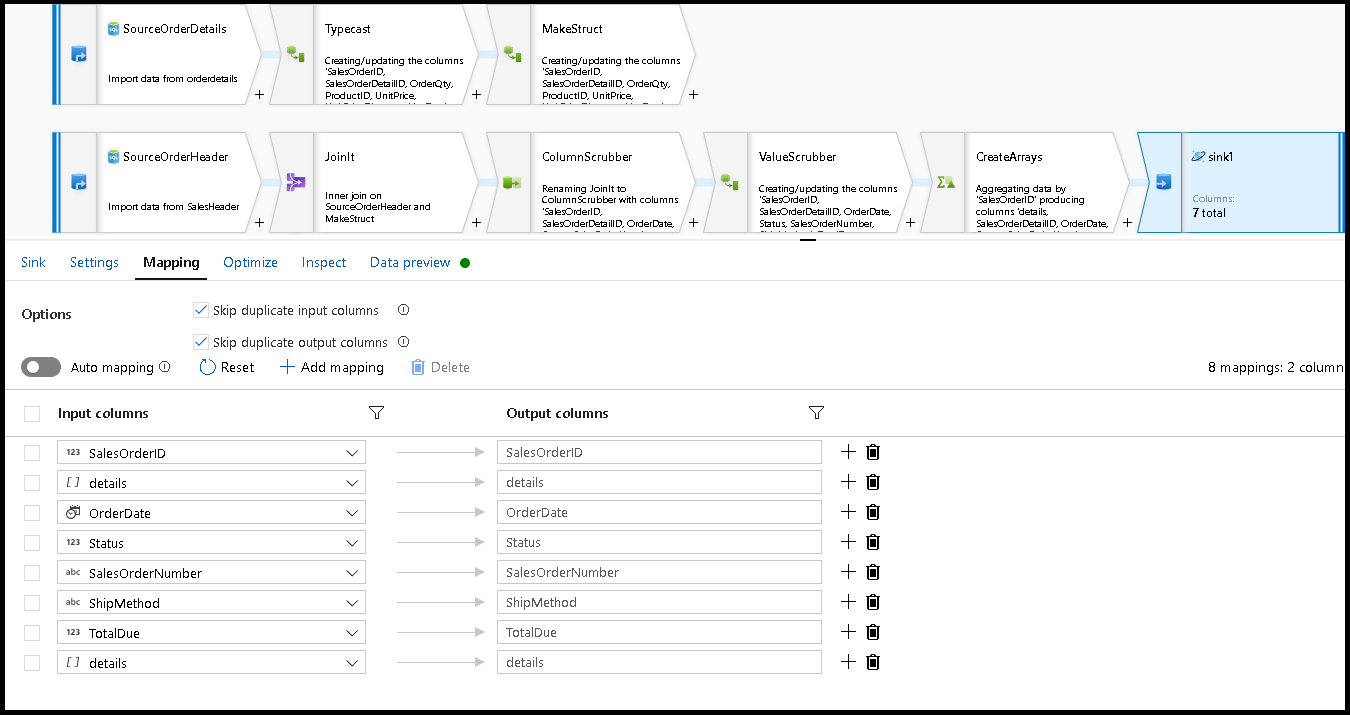
Wybierz podgląd danych, aby upewnić się, że te 32 wiersze mają być wstawione jako nowe dokumenty do nowego kontenera:
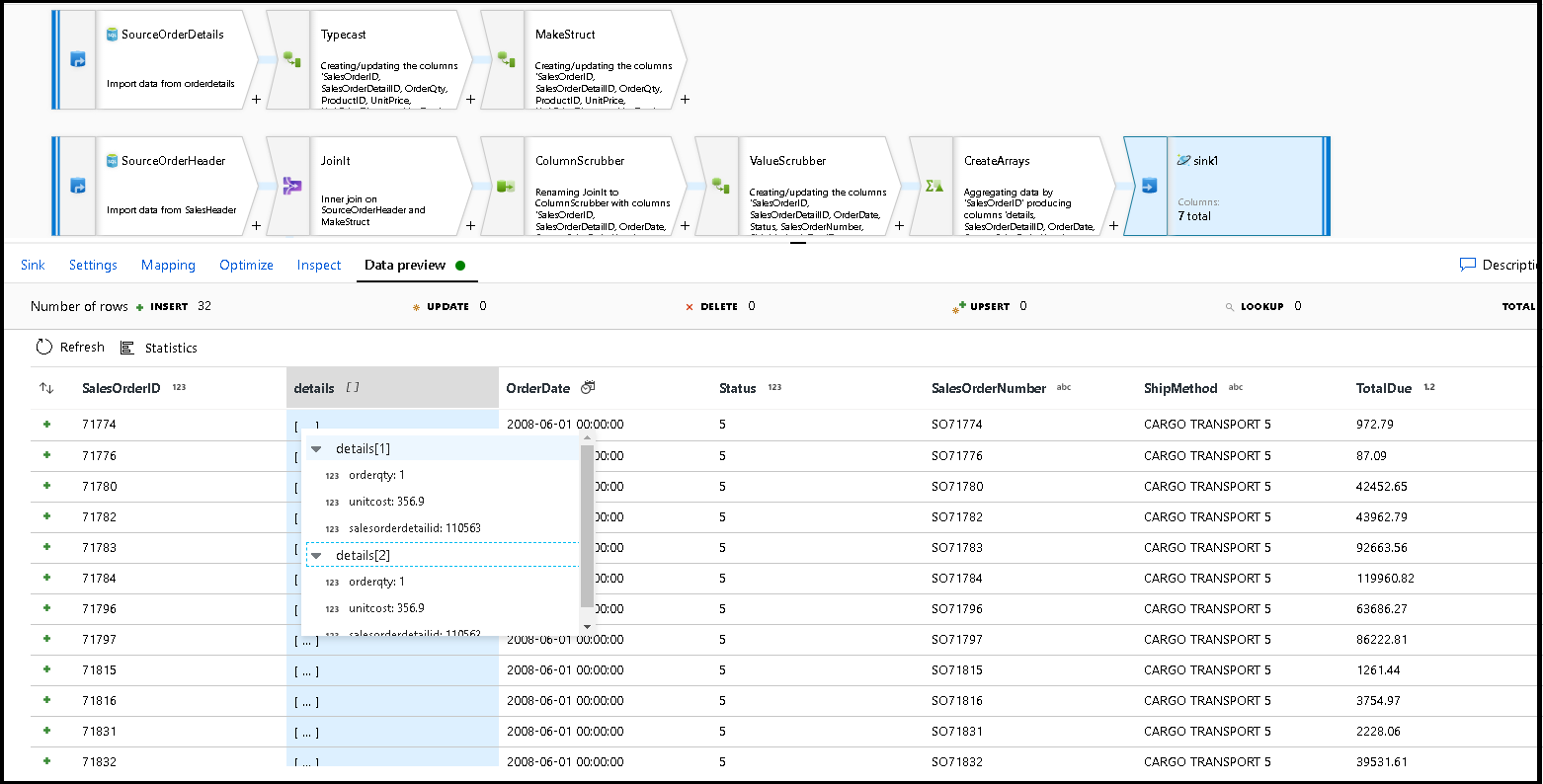
Jeśli wszystko wygląda dobrze, możesz teraz utworzyć nowy potok, dodać to działanie przepływu danych do tego potoku i wykonać go. Można wykonać z poziomu debugowania lub wyzwolonego przebiegu. Po kilku minutach w bazie danych usługi Azure Cosmos DB powinien istnieć nowy zdenormalizowany kontener zamówień o nazwie "orders".
Powiązana zawartość
- Utwórz pozostałą część logiki przepływu danych przy użyciu przekształceń przepływów danych mapowania.
- Pobierz ukończony szablon potoku dla tego samouczka i zaimportuj szablon do fabryki.