Analizowanie transformacji w przepływie danych mapowania
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Przepływy danych są dostępne zarówno w usłudze Azure Data Factory, jak i w potokach usługi Azure Synapse. Ten artykuł dotyczy przepływów danych mapowania. Jeśli dopiero zaczynasz transformacje, zapoznaj się z artykułem wprowadzającym Przekształcanie danych przy użyciu przepływu danych mapowania.
Użyj przekształcenia Analizowanie, aby przeanalizować kolumny tekstowe w danych, które są ciągami w formularzu dokumentu. Bieżące obsługiwane typy dokumentów osadzonych, które mogą być analizowane, to tekst JSON, XML i rozdzielany.
Konfigurowanie
W panelu konfiguracji analizowania transformacji należy najpierw wybrać typ danych zawartych w kolumnach, które mają zostać przeanalizowane w tekście. Przekształcenie analizy zawiera również następujące ustawienia konfiguracji.

Kolumna
Podobnie jak w przypadku kolumn pochodnych i agregacji, właściwość Kolumna to miejsce, w którym można zmodyfikować istniejącą kolumnę, wybierając ją z selektora rozwijanego. Możesz też wpisać nazwę nowej kolumny tutaj. Usługa ADF przechowuje przeanalizowane dane źródłowe w tej kolumnie. W większości przypadków chcesz zdefiniować nową kolumnę, która analizuje przychodzące osadzone pole ciągu dokumentu.
Wyrażenie
Użyj konstruktora wyrażeń, aby ustawić źródło analizy. Ustawienie źródła może być tak proste, jak wybranie kolumny źródłowej z danymi samodzielnej analizy lub utworzenie złożonych wyrażeń do analizy.
Przykładowe wyrażenia
Dane ciągu źródłowego:
chrome|steel|plastic- Wyrażenie:
(desc1 as string, desc2 as string, desc3 as string)
- Wyrażenie:
Źródłowe dane JSON:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- Wyrażenie:
(level as string, registration as long)
- Wyrażenie:
Dane JSON zagnieżdżone źródła:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- Wyrażenie:
(car as (model as string, year as integer), color as string, transmission as string)
- Wyrażenie:
Źródłowe dane XML:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- Wyrażenie:
(Customers as (Customer as integer, CompanyName as string))
- Wyrażenie:
Źródłowy kod XML z danymi atrybutu:
<cars><car model="camaro"><year>1989</year></car></cars>- Wyrażenie:
(cars as (car as ({@model} as string, year as integer)))
- Wyrażenie:
Wyrażenia z zastrzeżonymi znakami:
{ "best-score": { "section 1": 1234 } }- Powyższe wyrażenie nie działa, ponieważ znak "-" w pliku
best-scorejest interpretowany jako operacja odejmowania. Użyj zmiennej z notacją nawiasu w tych przypadkach, aby poinformować aparat JSON, aby interpretować tekst dosłownie:var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- Powyższe wyrażenie nie działa, ponieważ znak "-" w pliku
Uwaga: Jeśli wystąpią błędy podczas wyodrębniania atrybutów (w szczególności z typu złożonego, obejście polega na przekonwertowaniu typu złożonego na ciąg, usunięciu symbolu @ (w szczególności @model) zastąpić(toString(your_xml_string_parsed_column_name.cars.car),'@',') ), a następnie użyć działania analizy przekształcenia JSON.
Typ kolumny wyjściowej
W tym miejscu skonfigurujesz docelowy schemat danych wyjściowych z analizy zapisywanej w jednej kolumnie. Najprostszym sposobem ustawienia schematu danych wyjściowych z analizowania jest wybranie przycisku "Wykryj typ" w prawym górnym rogu konstruktora wyrażeń. Usługa ADF próbuje automatycznie ustalić schemat z pola ciągu, które analizujesz i ustawiasz go dla Ciebie w wyrażeniu wyjściowym.
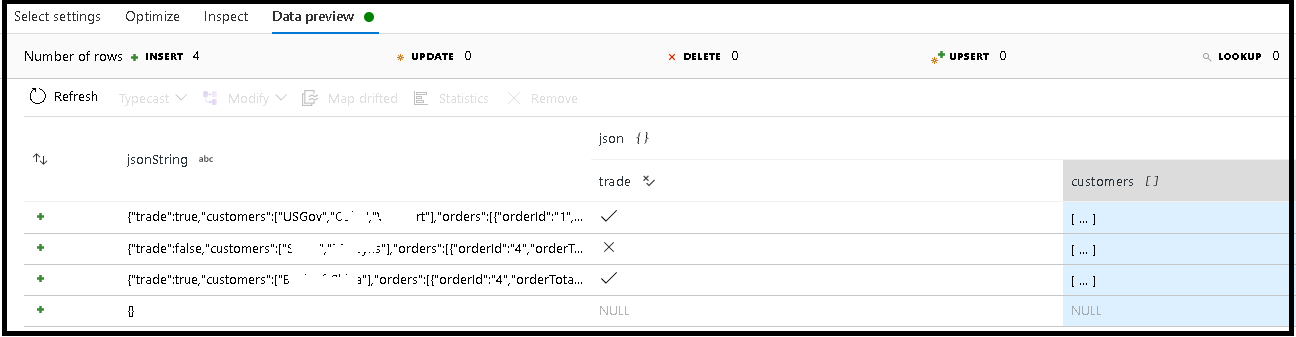
W tym przykładzie zdefiniowaliśmy analizowanie pola przychodzącego "jsonString", czyli zwykłego tekstu, ale sformatowane jako struktura JSON. Przeanalizujemy wyniki jako dane JSON w nowej kolumnie o nazwie "json" przy użyciu tego schematu:
(trade as boolean, customers as string[])
Zapoznaj się z kartą inspekcji i podglądem danych, aby sprawdzić, czy dane wyjściowe są prawidłowo mapowane.
Użyj działania Kolumna pochodna, aby wyodrębnić dane hierarchiczne (czyli your_complex_column_name.car.model w polu wyrażenia)
Przykłady
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
Skrypt przepływu danych
Składnia
Przykłady
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
Powiązana zawartość
- Użyj przekształcenia Spłaszczanego, aby przestawienia wierszy do kolumn.
- Użyj przekształcenia kolumny pochodnej, aby przekształcić wiersze.