Wykonywanie działania potoku w usługach Azure Data Factory i Synapse Analytics
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Działanie Execute Pipeline (Wykonywanie potoku) umożliwia potokowi usługi Data Factory lub Synapse wywoływanie innego potoku.
Tworzenie działania Execute Pipeline za pomocą interfejsu użytkownika
Aby użyć działania Execute Pipeline w potoku, wykonaj następujące kroki:
Wyszukaj potok w okienku Działania potoku i przeciągnij działanie Execute Pipeline do kanwy potoku.
Wybierz nowe działanie Execute Pipeline (Wykonywanie potoku) na kanwie, jeśli nie zostało jeszcze wybrane, a jego karta Ustawienia , aby edytować jego szczegóły.
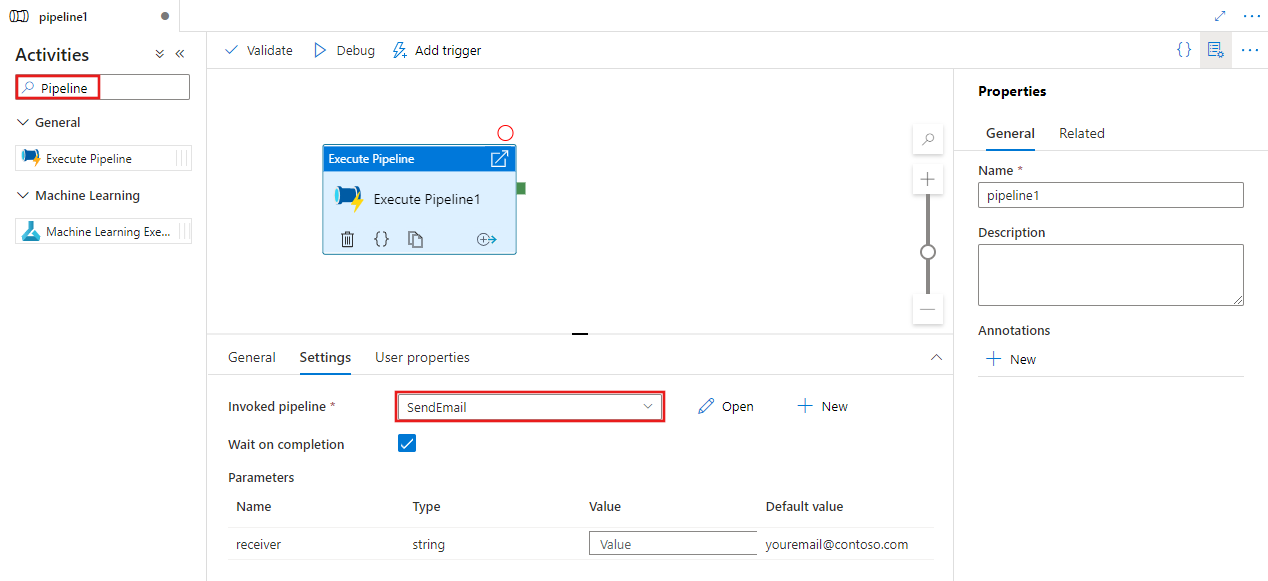
Wybierz istniejący potok lub utwórz nowy przy użyciu przycisku Nowy. Wybierz inne opcje i skonfiguruj wszystkie parametry potoku zgodnie z wymaganiami, aby ukończyć konfigurację.
Składnia
{
"name": "MyPipeline",
"properties": {
"activities": [
{
"name": "ExecutePipelineActivity",
"type": "ExecutePipeline",
"typeProperties": {
"parameters": {
"mySourceDatasetFolderPath": {
"value": "@pipeline().parameters.mySourceDatasetFolderPath",
"type": "Expression"
}
},
"pipeline": {
"referenceName": "<InvokedPipelineName>",
"type": "PipelineReference"
},
"waitOnCompletion": true
}
}
],
"parameters": [
{
"mySourceDatasetFolderPath": {
"type": "String"
}
}
]
}
}
Właściwości typu
| Właściwości | opis | Dozwolone wartości | Wymagania |
|---|---|---|---|
| name | Nazwa działania wykonywania potoku. | String | Tak |
| type | Musi być ustawiona na: ExecutePipeline. | String | Tak |
| rurociąg | Odwołanie do potoku zależnego wywoływanego przez ten potok. Obiekt referencyjny potoku ma dwie właściwości: referenceName i type. Właściwość referenceName określa nazwę potoku odwołania. Właściwość type musi być ustawiona na PipelineReference. | PipelineReference | Tak |
| parameters | Parametry do przekazania do wywoływanego potoku | Obiekt JSON mapujący nazwy parametrów na wartości argumentów | Nie. |
| waitOnCompletion | Określa, czy wykonywanie działania oczekuje na zakończenie wykonywania potoku zależnego. Ustawieniem domyślnym jest true. | Wartość logiczna | Nie. |
Przykład
Ten scenariusz ma dwa potoki:
-
Potok główny — ten potok ma jedno działanie Execute Pipeline, które wywołuje wywoływany potok. Potok główny przyjmuje dwa parametry:
masterSourceBlobContainer,masterSinkBlobContainer. -
Wywoływany potok — ten potok ma jedną działanie Kopiuj, która kopiuje dane ze źródła obiektu blob platformy Azure do ujścia obiektu blob platformy Azure. Wywoływany potok przyjmuje dwa parametry:
sourceBlobContainer,sinkBlobContainer.
Definicja potoku głównego
{
"name": "masterPipeline",
"properties": {
"activities": [
{
"type": "ExecutePipeline",
"typeProperties": {
"pipeline": {
"referenceName": "invokedPipeline",
"type": "PipelineReference"
},
"parameters": {
"sourceBlobContainer": {
"value": "@pipeline().parameters.masterSourceBlobContainer",
"type": "Expression"
},
"sinkBlobContainer": {
"value": "@pipeline().parameters.masterSinkBlobContainer",
"type": "Expression"
}
},
"waitOnCompletion": true
},
"name": "MyExecutePipelineActivity"
}
],
"parameters": {
"masterSourceBlobContainer": {
"type": "String"
},
"masterSinkBlobContainer": {
"type": "String"
}
}
}
}
Definicja wywoływanego potoku
{
"name": "invokedPipeline",
"properties": {
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink"
}
},
"name": "CopyBlobtoBlob",
"inputs": [
{
"referenceName": "SourceBlobDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "sinkBlobDataset",
"type": "DatasetReference"
}
]
}
],
"parameters": {
"sourceBlobContainer": {
"type": "String"
},
"sinkBlobContainer": {
"type": "String"
}
}
}
}
Połączona usługa
{
"name": "BlobStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=*****;AccountKey=*****"
}
}
}
Źródłowy zestaw danych
{
"name": "SourceBlobDataset",
"properties": {
"type": "AzureBlob",
"typeProperties": {
"folderPath": {
"value": "@pipeline().parameters.sourceBlobContainer",
"type": "Expression"
},
"fileName": "salesforce.txt"
},
"linkedServiceName": {
"referenceName": "BlobStorageLinkedService",
"type": "LinkedServiceReference"
}
}
}
Zestaw danych ujścia
{
"name": "sinkBlobDataset",
"properties": {
"type": "AzureBlob",
"typeProperties": {
"folderPath": {
"value": "@pipeline().parameters.sinkBlobContainer",
"type": "Expression"
}
},
"linkedServiceName": {
"referenceName": "BlobStorageLinkedService",
"type": "LinkedServiceReference"
}
}
}
Uruchamianie potoku
Aby uruchomić potok główny w tym przykładzie, następujące wartości są przekazywane dla parametrów masterSourceBlobContainer i masterSinkBlobContainer:
{
"masterSourceBlobContainer": "executetest",
"masterSinkBlobContainer": "executesink"
}
Potok główny przekazuje te wartości do wywoływanego potoku, jak pokazano w poniższym przykładzie:
{
"type": "ExecutePipeline",
"typeProperties": {
"pipeline": {
"referenceName": "invokedPipeline",
"type": "PipelineReference"
},
"parameters": {
"sourceBlobContainer": {
"value": "@pipeline().parameters.masterSourceBlobContainer",
"type": "Expression"
},
"sinkBlobContainer": {
"value": "@pipeline().parameters.masterSinkBlobContainer",
"type": "Expression"
}
},
....
}
Ostrzeżenie
Działanie Execute Pipeline przekazuje parametr tablicy jako ciąg do potoku podrzędnego. Wynika to z faktu, że ładunek jest przekazywany z potoku nadrzędnego do elementu podrzędnego >jako ciąg. Widzimy to po sprawdzeniu danych wejściowych przekazanych do potoku podrzędnego. Aby uzyskać więcej informacji, zapoznaj się z tą sekcją .
Powiązana zawartość
Zobacz inne obsługiwane działania przepływu sterowania: