Zautomatyzowane publikowanie w ramach ciągłej integracji i ciągłego wdrażania (CI/CD)
DOTYCZY:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Uwaga
Usługa Synapse Analytics obsługuje również ciągłą integrację/ciągłe wdrażanie. Aby uzyskać więcej informacji, zapoznaj się z dokumentacją ciągłej integracji/ciągłego wdrażania usługi Synapse Analytics.
Omówienie
Ciągła integracja to metoda automatycznego testowania każdej zmiany wprowadzonej w bazie kodu. Jak najszybciej ciągłe dostarczanie odbywa się po testach wykonywanych podczas ciągłej integracji i wypycha zmiany do systemu przejściowego lub produkcyjnego.
W usłudze Azure Data Factory ciągła integracja/ciągłe wdrażanie oznacza przenoszenie potoków usługi Data Factory z jednego środowiska, takiego jak programowanie, testowanie i produkcja, do innego. Usługa Data Factory używa szablonów usługi Azure Resource Manager (ARM) do przechowywania konfiguracji różnych jednostek usługi Data Factory, takich jak potoki, zestawy danych i przepływy danych.
Istnieją dwie sugerowane metody podwyższania poziomu fabryki danych do innego środowiska:
- Automatyczne wdrażanie przy użyciu integracji usługi Data Factory z usługą Azure Pipelines.
- Ręczne przekazywanie szablonu usługi ARM przy użyciu integracji środowiska użytkownika usługi Data Factory z usługą Azure Resource Manager.
Aby uzyskać więcej informacji, zobacz Ciągła integracja i ciągłe dostarczanie w usłudze Azure Data Factory.
Ten artykuł koncentruje się na ulepszeniach ciągłego wdrażania i funkcji automatycznego publikowania dla ciągłej integracji/ciągłego wdrażania.
Ulepszenia ciągłego wdrażania
Funkcja automatycznego publikowania pobiera funkcje szablonu Zweryfikuj wszystkie i Eksportuj szablon usługi ARM ze środowiska użytkownika usługi Data Factory i udostępnia logikę za pośrednictwem publicznie dostępnego pakietu npm @microsoft/azure-data-factory-utilities. Z tego powodu można programowo wyzwolić te akcje zamiast przejść do interfejsu użytkownika usługi Data Factory i ręcznie wybrać przycisk. Takie podejście zwiększa ciągłość integracji w potokach ciągłej integracji / ciągłego wdrażania.
Uwaga
Pamiętaj, aby użyć węzła w wersji 18.x i jego zgodnej wersji, aby uniknąć błędów, które mogą wystąpić z powodu niezgodności pakietu ze starszymi wersjami.
Bieżący przepływ ciągłej integracji/ciągłego wdrażania
- Każdy użytkownik wprowadza zmiany w swoich gałęziach prywatnych.
- Wypychanie do wzorca nie jest dozwolone. Aby wprowadzić zmiany, użytkownicy muszą utworzyć żądanie ściągnięcia.
- Użytkownicy muszą załadować interfejs użytkownika usługi Data Factory i wybrać pozycję Publikuj , aby wdrożyć zmiany w usłudze Data Factory i wygenerować szablony usługi ARM w gałęzi publikowania.
- Potok wydania metodyki DevOps jest skonfigurowany do tworzenia nowej wersji i wdrażania szablonu usługi ARM za każdym razem, gdy nowa zmiana zostanie wypchnięta do gałęzi publikowania.
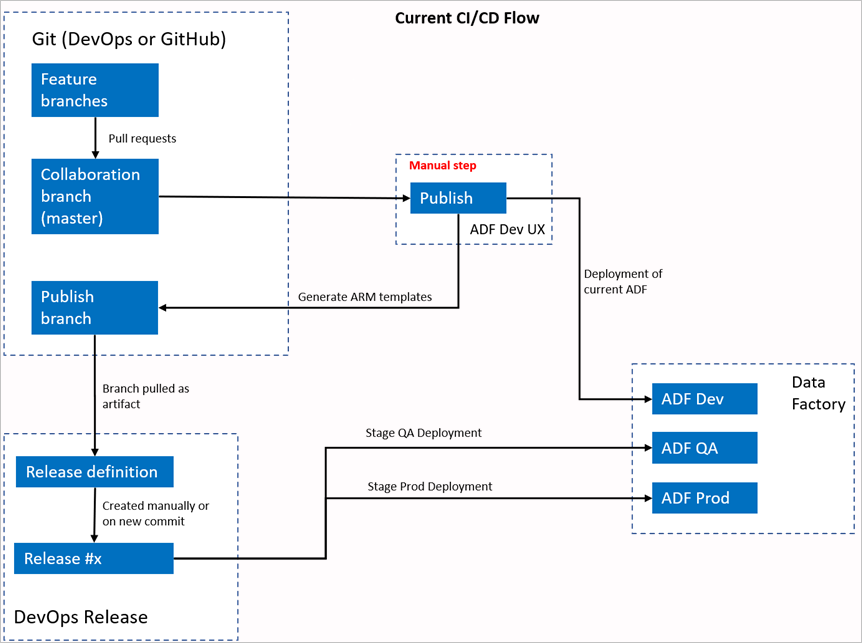
Krok ręczny
W bieżącym przepływie ciągłej integracji/ciągłego wdrażania środowisko użytkownika jest pośrednikiem w tworzeniu szablonu usługi ARM. W związku z tym użytkownik musi przejść do interfejsu użytkownika usługi Data Factory i ręcznie wybrać pozycję Publikuj , aby uruchomić generowanie szablonu usługi ARM i usunąć go w gałęzi publikowania.
Nowy przepływ ciągłej integracji/ciągłego wdrażania
- Każdy użytkownik wprowadza zmiany w swoich gałęziach prywatnych.
- Wypychanie do wzorca nie jest dozwolone. Aby wprowadzić zmiany, użytkownicy muszą utworzyć żądanie ściągnięcia.
- Kompilacja potoku usługi Azure DevOps jest wyzwalana za każdym razem, gdy nowe zatwierdzenie zostanie wykonane na serwerze głównym. Weryfikuje zasoby i generuje szablon usługi ARM jako artefakt, jeśli walidacja zakończy się pomyślnie.
- Potok wydania metodyki DevOps jest skonfigurowany do tworzenia nowej wersji i wdrażania szablonu usługi ARM za każdym razem, gdy jest dostępna nowa kompilacja.
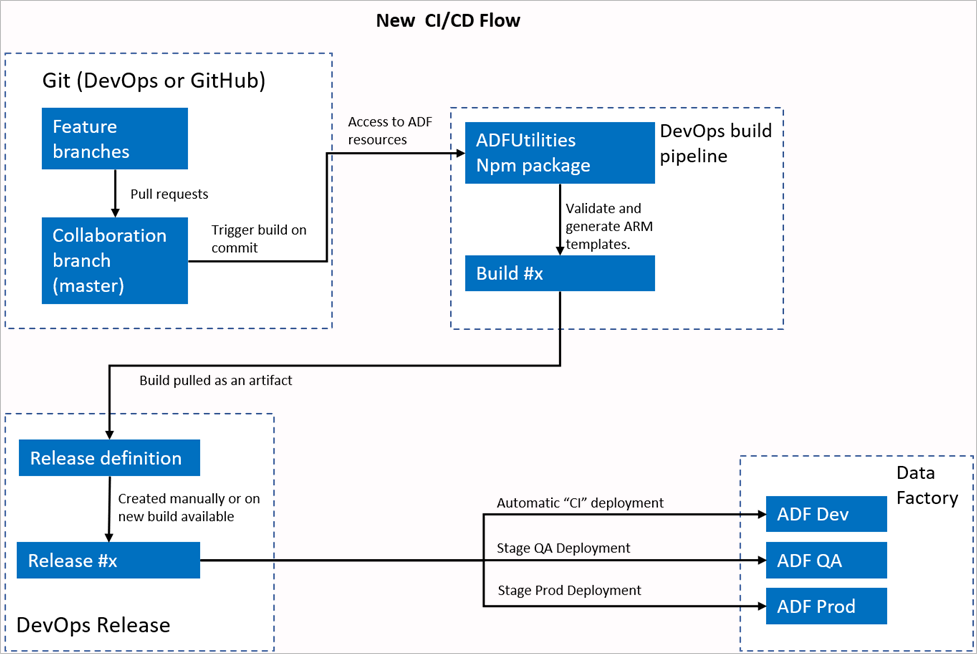
Co się zmieniło?
- Mamy teraz proces kompilacji, który używa potoku kompilacji DevOps.
- Potok kompilacji używa pakietu NPM ADFUtilities, który zweryfikuje wszystkie zasoby i wygeneruje szablony usługi ARM. Te szablony mogą być pojedyncze i połączone.
- Potok kompilacji jest odpowiedzialny za weryfikowanie zasobów usługi Data Factory i generowanie szablonu usługi ARM zamiast interfejsu użytkownika usługi Data Factory (przycisk Publikuj ).
- Definicja wydania metodyki DevOps będzie teraz używać tego nowego potoku kompilacji zamiast artefaktu Git.
Uwaga
Możesz nadal używać istniejącego mechanizmu, który jest gałęzią adf_publish , lub użyć nowego przepływu. Oba są obsługiwane.
Przegląd pakietu
W pakiecie są obecnie dostępne dwa polecenia:
- Eksportowanie szablonu usługi Resource Manager
- Sprawdź poprawność
Eksportowanie szablonu usługi Resource Manager
Uruchom polecenie npm run build export <rootFolder> <factoryId> [outputFolder] , aby wyeksportować szablon usługi ARM przy użyciu zasobów danego folderu. To polecenie uruchamia również sprawdzanie poprawności przed wygenerowaniem szablonu usługi ARM. Oto przykład użycia grupy zasobów o nazwie testResourceGroup:
npm run build export C:\DataFactories\DevDataFactory /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/testResourceGroup/providers/Microsoft.DataFactory/factories/DevDataFactory ArmTemplateOutput
RootFolderto obowiązkowe pole reprezentujące miejsce, w którym znajdują się zasoby usługi Data Factory.FactoryIdjest obowiązkowym polem reprezentującym identyfikator zasobu usługi Data Factory w formacie/subscriptions/<subId>/resourceGroups/<rgName>/providers/Microsoft.DataFactory/factories/<dfName>.OutputFolderjest opcjonalnym parametrem określającym ścieżkę względną do zapisania wygenerowanego szablonu usługi ARM.
Możliwość zatrzymywania/uruchamiania tylko zaktualizowanych wyzwalaczy jest teraz ogólnie dostępna i jest scalona z poleceniem przedstawionym powyżej.
Uwaga
Wygenerowany szablon usługi ARM nie jest publikowany w wersji na żywo fabryki. Wdrożenie powinno odbywać się przy użyciu potoku ciągłej integracji/ciągłego wdrażania.
Sprawdź poprawność
Uruchom polecenie npm run build validate <rootFolder> <factoryId> , aby zweryfikować wszystkie zasoby danego folderu. Oto przykład:
npm run build validate C:\DataFactories\DevDataFactory /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/testResourceGroup/providers/Microsoft.DataFactory/factories/DevDataFactory
RootFolderto obowiązkowe pole reprezentujące miejsce, w którym znajdują się zasoby usługi Data Factory.FactoryIdjest obowiązkowym polem reprezentującym identyfikator zasobu usługi Data Factory w formacie/subscriptions/<subId>/resourceGroups/<rgName>/providers/Microsoft.DataFactory/factories/<dfName>.
Tworzenie potoku platformy Azure
Pakiety npm mogą być używane na różne sposoby, ale jedną z podstawowych korzyści jest użycie za pośrednictwem usługi Azure Pipeline. W każdej scalaniu z gałęzią współpracy można wyzwolić potok, który najpierw weryfikuje cały kod, a następnie eksportuje szablon usługi ARM do artefaktu kompilacji, który może być używany przez potok wydania. Czym różni się od bieżącego procesu ciągłej integracji/ciągłego wdrażania jest wskazanie potoku wydania w tym artefaktzie zamiast istniejącej adf_publish gałęzi.
Wkonaj następujące kroki, aby rozpocząć:
Otwórz projekt usługi Azure DevOps i przejdź do pozycji Potoki. Wybierz pozycję Nowy potok.
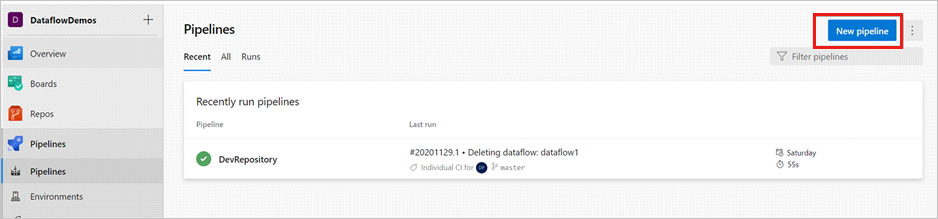
Wybierz repozytorium, w którym chcesz zapisać skrypt YAML potoku. Zalecamy zapisanie go w folderze kompilacji w tym samym repozytorium zasobów usługi Data Factory. Upewnij się, że w repozytorium znajduje się plik package.json zawierający nazwę pakietu, jak pokazano w poniższym przykładzie:
{ "scripts":{ "build":"node node_modules/@microsoft/azure-data-factory-utilities/lib/index" }, "dependencies":{ "@microsoft/azure-data-factory-utilities":"^1.0.0" } }Wybierz pozycję Potok startowy. Jeśli plik YAML został przekazany lub scalony, jak pokazano w poniższym przykładzie, możesz również wskazać go bezpośrednio i edytować.
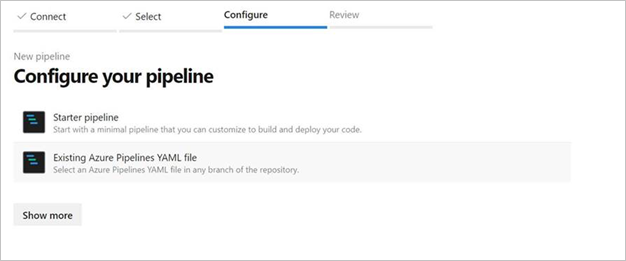
# Sample YAML file to validate and export an ARM template into a build artifact # Requires a package.json file located in the target repository trigger: - main #collaboration branch pool: vmImage: 'ubuntu-latest' steps: # Installs Node and the npm packages saved in your package.json file in the build - task: UseNode@1 inputs: version: '18.x' displayName: 'Install Node.js' - task: Npm@1 inputs: command: 'install' workingDir: '$(Build.Repository.LocalPath)/<folder-of-the-package.json-file>' #replace with the package.json folder verbose: true displayName: 'Install npm package' # Validates all of the Data Factory resources in the repository. You'll get the same validation errors as when "Validate All" is selected. # Enter the appropriate subscription and name for the source factory. Either of the "Validate" or "Validate and Generate ARM template" options are required to perform validation. Running both is unnecessary. - task: Npm@1 inputs: command: 'custom' workingDir: '$(Build.Repository.LocalPath)/<folder-of-the-package.json-file>' #replace with the package.json folder customCommand: 'run build validate $(Build.Repository.LocalPath)/<Root-folder-from-Git-configuration-settings-in-ADF> /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/<Your-ResourceGroup-Name>/providers/Microsoft.DataFactory/factories/<Your-Factory-Name>' displayName: 'Validate' # Validate and then generate the ARM template into the destination folder, which is the same as selecting "Publish" from the UX. # The ARM template generated isn't published to the live version of the factory. Deployment should be done by using a CI/CD pipeline. - task: Npm@1 inputs: command: 'custom' workingDir: '$(Build.Repository.LocalPath)/<folder-of-the-package.json-file>' #replace with the package.json folder customCommand: 'run build export $(Build.Repository.LocalPath)/<Root-folder-from-Git-configuration-settings-in-ADF> /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/<Your-ResourceGroup-Name>/providers/Microsoft.DataFactory/factories/<Your-Factory-Name> "ArmTemplate"' #For using preview that allows you to only stop/ start triggers that are modified, please comment out the above line and uncomment the below line. Make sure the package.json contains the build-preview command. #customCommand: 'run build-preview export $(Build.Repository.LocalPath) /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/GartnerMQ2021/providers/Microsoft.DataFactory/factories/Dev-GartnerMQ2021-DataFactory "ArmTemplate"' displayName: 'Validate and Generate ARM template' # Publish the artifact to be used as a source for a release pipeline. - task: PublishPipelineArtifact@1 inputs: targetPath: '$(Build.Repository.LocalPath)/<folder-of-the-package.json-file>/ArmTemplate' #replace with the package.json folder artifact: 'ArmTemplates' publishLocation: 'pipeline'Wprowadź kod YAML. Zalecamy użycie pliku YAML jako punktu wyjścia.
Zapisz i uruchom polecenie . Jeśli użyto kodu YAML, zostanie ono wyzwolone za każdym razem, gdy gałąź główna zostanie zaktualizowana.
Uwaga
Wygenerowane artefakty zawierają już skrypty przed wdrożeniem i po wdrożeniu dla wyzwalaczy, więc nie trzeba ich dodawać ręcznie. Jednak podczas wdrażania należy odwoływać się do dokumentacji dotyczącej zatrzymywania i uruchamiania wyzwalaczy w celu wykonania dostarczonego skryptu.
Powiązana zawartość
Dowiedz się więcej o ciągłej integracji i dostarczaniu w usłudze Data Factory: ciągła integracja i dostarczanie w usłudze Azure Data Factory.