Pozyskiwanie danych z platformy Apache Kafka do usługi Azure Data Explorer
Apache Kafka to rozproszona platforma przesyłania strumieniowego do tworzenia potoków danych przesyłanych strumieniowo w czasie rzeczywistym, które niezawodnie przenoszą dane między systemami lub aplikacjami. Kafka Connect to narzędzie do skalowalnego i niezawodnego przesyłania strumieniowego danych między platformą Apache Kafka i innymi systemami danych. Ujście platformy Kafka kusto służy jako łącznik z platformy Kafka i nie wymaga użycia kodu. Pobierz plik jar łącznika ujścia z repozytorium Git lub centrum łącznika Confluent.
W tym artykule pokazano, jak pozyskiwać dane za pomocą platformy Kafka, korzystając z samodzielnej konfiguracji platformy Docker w celu uproszczenia konfiguracji klastra platformy Kafka i klastra łącznika platformy Kafka.
Aby uzyskać więcej informacji, zobacz repozytorium Git łącznika i specyfikę wersji.
Wymagania wstępne
- Subskrypcja platformy Azure. Utwórz bezpłatne konto platformy Azure.
- Klaster i baza danych usługi Azure Data Explorer z domyślną pamięcią podręczną i zasadami przechowywania.
- Interfejs wiersza polecenia platformy Azure.
- Docker i Docker Compose.
Tworzenie jednostki usługi Entra firmy Microsoft
Jednostkę usługi Microsoft Entra można utworzyć za pomocą witryny Azure Portal lub programowo, jak w poniższym przykładzie.
Ta jednostka usługi jest tożsamością używaną przez łącznik do zapisywania danych w tabeli w usłudze Kusto. Przyznasz uprawnienia dla tej jednostki usługi w celu uzyskania dostępu do zasobów usługi Kusto.
Zaloguj się do subskrypcji platformy Azure za pomocą interfejsu wiersza polecenia platformy Azure. Następnie uwierzytelnij się w przeglądarce.
az loginWybierz subskrypcję do hostowania podmiotu zabezpieczeń. Ten krok jest wymagany, gdy masz wiele subskrypcji.
az account set --subscription YOUR_SUBSCRIPTION_GUIDUtwórz jednostkę usługi. W tym przykładzie jednostka usługi nosi nazwę
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Z zwróconych danych JSON skopiuj wartości
appId,passworditenantdo użycia w przyszłości.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Utworzono aplikację Microsoft Entra i jednostkę usługi.
Tworzenie tabeli docelowej
W środowisku zapytań utwórz tabelę o nazwie
Stormsprzy użyciu następującego polecenia:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)Utwórz odpowiednie mapowanie
Storms_CSV_Mappingtabeli dla pozyskanych danych przy użyciu następującego polecenia:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'Utwórz zasady dzielenia na partie pozyskiwania danych w tabeli w celu skonfigurowania opóźnienia pozyskiwania w kolejce.
Napiwek
Zasady dzielenia na partie pozyskiwania są optymalizatorem wydajności i zawierają trzy parametry. Pierwszy warunek spełnia warunek wyzwala pozyskiwanie do tabeli.
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'Użyj jednostki usługi w sekcji Tworzenie jednostki usługi Entra firmy Microsoft, aby udzielić uprawnień do pracy z bazą danych.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
Uruchamianie laboratorium
Poniższe laboratorium ma na celu zapewnienie doświadczenia w tworzeniu danych, konfigurowaniu łącznika platformy Kafka i przesyłaniu strumieniowego tych danych. Następnie możesz przyjrzeć się pozyskanym danym.
Klonowanie repozytorium git
Sklonuj repozytorium git laboratorium.
Utwórz katalog lokalny na maszynie.
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holSklonuj repozytorium.
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
Zawartość sklonowanego repozytorium
Uruchom następujące polecenie, aby wyświetlić listę zawartości sklonowanego repozytorium:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
Ten wynik tego wyszukiwania to:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
Przejrzyj pliki w sklonowanym repozytorium
W poniższych sekcjach opisano ważne części plików w drzewie plików.
adx-sink-config.json
Ten plik zawiera plik właściwości ujścia kusto, w którym są aktualizowane szczegółowe informacje o konfiguracji:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
Zastąp wartości następujących atrybutów zgodnie z konfiguracją: aad.auth.authority, aad.auth.appid, , aad.auth.appkey( kusto.tables.topics.mapping nazwa bazy danych), i .kusto.query.urlkusto.ingestion.url
Łącznik — Dockerfile
Ten plik zawiera polecenia służące do generowania obrazu platformy Docker dla wystąpienia łącznika. Obejmuje on pobieranie łącznika z katalogu wersji repozytorium Git.
Katalog storm-events-producer
Ten katalog zawiera program języka Go, który odczytuje lokalny plik "StormEvents.csv" i publikuje dane w temacie platformy Kafka.
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
Uruchamianie kontenerów
W terminalu uruchom kontenery:
docker-compose upAplikacja producenta rozpoczyna wysyłanie zdarzeń do tematu
storm-events. Powinny zostać wyświetlone dzienniki podobne do następujących dzienników:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....Aby sprawdzić dzienniki, uruchom następujące polecenie w osobnym terminalu:
docker-compose logs -f | grep kusto-connect
Uruchamianie łącznika
Użyj wywołania REST platformy Kafka Connect, aby uruchomić łącznik.
W osobnym terminalu uruchom zadanie ujścia za pomocą następującego polecenia:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectorsAby sprawdzić stan, uruchom następujące polecenie w osobnym terminalu:
curl http://localhost:8083/connectors/storm/status
Łącznik rozpoczyna kolejkowanie procesów pozyskiwania.
Uwaga
Jeśli masz problemy z łącznikiem dzienników, utwórz problem.
Tożsamość zarządzana
Domyślnie łącznik platformy Kafka używa metody aplikacji do uwierzytelniania podczas pozyskiwania. Aby uwierzytelnić się przy użyciu tożsamości zarządzanej:
Przypisz klastrowi tożsamość zarządzaną i przyznaj swojemu kontu magazynu uprawnienia do odczytu. Aby uzyskać więcej informacji, zobacz Pozyskiwanie danych przy użyciu uwierzytelniania tożsamości zarządzanej.
W pliku adx-sink-config.json ustaw
aad.auth.strategymanaged_identitywartość i upewnij się, żeaad.auth.appidustawiono identyfikator klienta tożsamości zarządzanej (aplikacji).Użyj tokenu usługi metadanych wystąpienia prywatnego zamiast jednostki usługi Microsoft Entra.
Uwaga
W przypadku korzystania z tożsamości appId zarządzanej i tenant są one wywoływane z kontekstu lokacji wywołań i password nie są potrzebne.
Wykonywanie zapytań i przeglądanie danych
Potwierdzanie pozyskiwania danych
Po dodaniu danych do
Stormstabeli potwierdź transfer danych, sprawdzając liczbę wierszy:Storms | countUpewnij się, że w procesie pozyskiwania nie występują żadne błędy:
.show ingestion failuresGdy zobaczysz dane, wypróbuj kilka zapytań.
Wykonywanie zapytań na danych
Aby wyświetlić wszystkie rekordy, uruchom następujące zapytanie:
Storms | take 10Użyj funkcji
whereiproject, aby filtrować określone dane:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdUżyj operatora
summarize:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart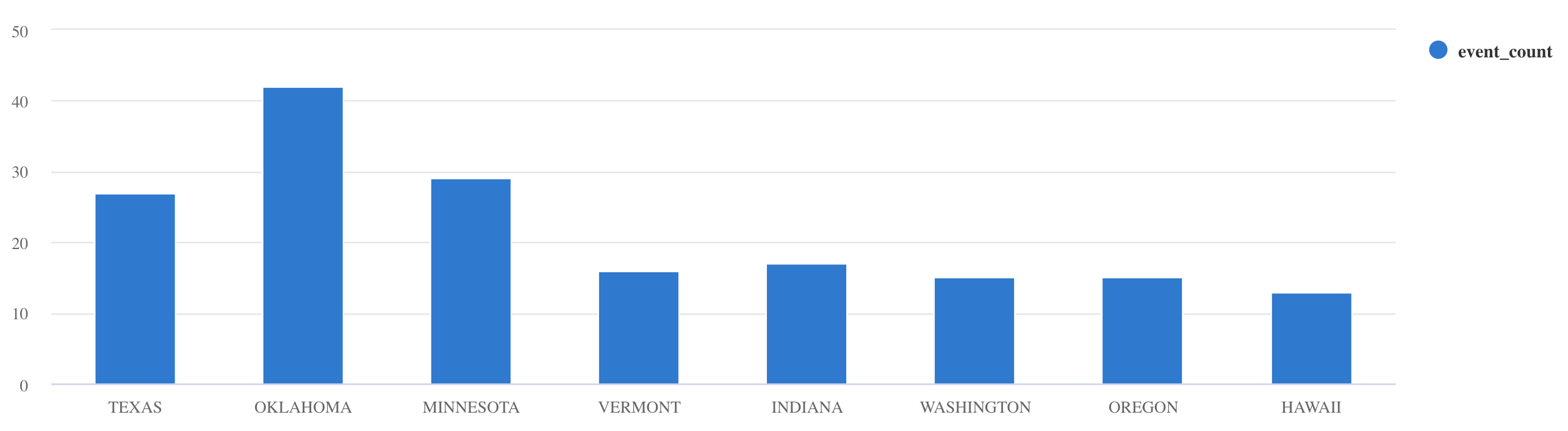
Aby uzyskać więcej przykładów zapytań i wskazówek, zobacz Pisanie zapytań w języku KQL i język zapytań Kusto dokumentacji.
Reset
Aby zresetować, wykonaj następujące czynności:
- Zatrzymywanie kontenerów (
docker-compose down -v) - Usuń (
drop table Storms) - Utwórz ponownie tabelę
Storms - Ponowne tworzenie mapowania tabeli
- Ponowne uruchamianie kontenerów (
docker-compose up)
Czyszczenie zasobów
Aby usunąć zasoby usługi Azure Data Explorer, użyj polecenia az kusto cluster delete (rozszerzenie kusto) lub az kusto database delete (rozszerzenie kusto)::
az kusto cluster delete --name "<cluster name>" --resource-group "<resource group name>"
az kusto database delete --cluster-name "<cluster name>" --database-name "<database name>" --resource-group "<resource group name>"
Klaster i baza danych można również usunąć za pośrednictwem witryny Azure Portal. Aby uzyskać więcej informacji, zobacz Usuwanie klastra usługi Azure Data Explorer i Usuwanie bazy danych w usłudze Azure Data Explorer.
Dostrajanie łącznika ujścia platformy Kafka
Dostosuj łącznik ujścia platformy Kafka, aby pracować z zasadami dzielenia na partie pozyskiwania:
- Dostosuj limit rozmiaru ujścia
flush.size.bytesplatformy Kafka, począwszy od 1 MB, zwiększając się o zwiększenie o 10 MB lub 100 MB. - W przypadku korzystania z ujścia platformy Kafka dane są agregowane dwa razy. Dane po stronie łącznika są agregowane zgodnie z ustawieniami opróżniania, a po stronie usługi zgodnie z zasadami dzielenia na partie. Jeśli czas dzielenia na partie jest zbyt krótki, więc nie można pozyskiwać danych zarówno przez łącznik, jak i usługę, należy zwiększyć czas dzielenia na partie. Ustaw rozmiar partii na 1 GB i zwiększ lub zmniejsz o 100 MB przyrostów zgodnie z potrzebami. Jeśli na przykład rozmiar opróżniania wynosi 1 MB, a rozmiar zasad dzielenia na partie wynosi 100 MB, łącznik ujścia platformy Kafka agreguje dane do partii 100 MB. Ta partia jest następnie pozyskiwana przez usługę. Jeśli czas zasad przetwarzania wsadowego wynosi 20 sekund, a łącznik ujścia platformy Kafka opróżnia 50 MB w ciągu 20 sekund, usługa pozyskuje partię 50 MB.
- Skalowanie można przeprowadzić, dodając wystąpienia i partycje platformy Kafka. Zwiększ
tasks.maxliczbę partycji. Utwórz partycję, jeśli masz wystarczającą ilość danych, aby utworzyć obiekt blob o rozmiarzeflush.size.bytesustawienia. Jeśli obiekt blob jest mniejszy, partia jest przetwarzana po osiągnięciu limitu czasu, więc partycja nie otrzymuje wystarczającej przepływności. Duża liczba partycji oznacza większe obciążenie związane z przetwarzaniem.
Powiązana zawartość
- Dowiedz się więcej o architekturze danych big data.
- Dowiedz się , jak pozyskiwać przykładowe dane w formacie JSON do usługi Azure Data Explorer.
- Dowiedz się więcej za pomocą laboratoriów platformy Kafka:
- Praktyczne laboratorium na potrzeby pozyskiwania z platformy Confluent Cloud Kafka w trybie rozproszonym
- Praktyczne laboratorium na potrzeby pozyskiwania z usługi HDInsight Kafka w trybie rozproszonym
- Praktyczne laboratorium na potrzeby pozyskiwania z platformy Confluent IaaS Kafka w usłudze AKS w trybie rozproszonym