Dokumentacja schematu konfiguracji konstruktora interfejsu API danych
Aparat konstruktora interfejsu API danych wymaga pliku konfiguracji. Plik konfiguracji narzędzia Data API Builder zapewnia ustrukturyzowane i kompleksowe podejście do konfigurowania interfejsu API, szczegółowo opisując wszystko, od zmiennych środowiskowych po konfiguracje specyficzne dla jednostki. Ten dokument w formacie JSON zaczyna się od właściwości $schema. Ta konfiguracja weryfikuje dokument.
Właściwości database-type i connection-string zapewniają bezproblemową integrację z systemami baz danych z usługi Azure SQL Database do interfejsu API NoSQL usługi Cosmos DB.
Plik konfiguracji może zawierać opcje, takie jak:
- Informacje o usłudze bazy danych i połączeniu
- Opcje konfiguracji globalnej i środowiska uruchomieniowego
- Zestaw uwidocznionych jednostek
- Metoda uwierzytelniania
- Reguły zabezpieczeń wymagane do uzyskiwania dostępu do tożsamości
- Reguły mapowania nazw między interfejsem API i bazą danych
- Relacje między jednostkami, których nie można wywnioskować
- Unikatowe funkcje dla określonych usług baz danych
Omówienie składni
Poniżej przedstawiono szybki podział podstawowych "sekcji" w pliku konfiguracji.
{
"$schema": "...",
"data-source": { ... },
"data-source-files": [ ... ],
"runtime": {
"rest": { ... },
"graphql": { .. },
"host": { ... },
"cache": { ... },
"telemetry": { ... },
"pagination": { ... }
}
"entities": [ ... ]
}
Właściwości najwyższego poziomu
Oto opis właściwości najwyższego poziomu w formacie tabeli:
| Własność | Opis |
|---|---|
| $schema | Określa schemat JSON do weryfikacji, upewniając się, że konfiguracja jest zgodna z wymaganym formatem. |
| źródła danych |
Zawiera szczegółowe informacje o typie bazy danych oraz parametry połączenia , niezbędne do nawiązania połączenia z bazą danych. |
| pliki źródła danych | Opcjonalna tablica określająca inne pliki konfiguracji, które mogą definiować inne źródła danych. |
| środowiska uruchomieniowego |
Konfiguruje zachowania i ustawienia środowiska uruchomieniowego, w tym podwłaściwości dla REST, GraphQL, hostów, pamięci podręczneji telemetrii. |
| jednostek | Definiuje zestaw jednostek (tabele bazy danych, widoki itp.), które są uwidaczniane za pośrednictwem interfejsu API, w tym ich mapowania , uprawnienia i relacje . |
Przykładowe konfiguracje
Oto przykładowy plik konfiguracji, który zawiera tylko wymagane właściwości dla pojedynczej prostej jednostki. Ten przykład ma na celu zilustrowanie minimalnego scenariusza.
{
"$schema": "https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json",
"data-source": {
"database-type": "mssql",
"connection-string": "@env('SQL_CONNECTION_STRING')"
},
"entities": {
"User": {
"source": "dbo.Users",
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
]
}
}
}
Aby zapoznać się z przykładem bardziej złożonego scenariusza, zobacz kompleksową konfigurację przykładu.
Środowiskach
Plik konfiguracji konstruktora interfejsu API danych może obsługiwać scenariusze, w których trzeba obsługiwać wiele środowisk, podobnie jak plik appSettings.json w programie ASP.NET Core. Struktura zapewnia trzy wspólnych wartości środowiska; Development, Stagingi Production; możesz jednak wybrać dowolną wybraną wartość środowiska. Środowisko używane przez konstruktora interfejsu API danych musi być skonfigurowane przy użyciu zmiennej środowiskowej DAB_ENVIRONMENT.
Rozważmy przykład, w którym chcesz uzyskać konfigurację punktu odniesienia i konfigurację specyficzną dla programowania. W tym przykładzie wymagane są dwa pliki konfiguracji:
| Środowisko | |
|---|---|
| dab-config.json | Baza |
| dab-config.Development.json | Rozwój |
Aby użyć konfiguracji specyficznej dla programowania, należy ustawić zmienną środowiskową DAB_ENVIRONMENT na Development.
Pliki konfiguracji specyficzne dla środowiska zastępują wartości właściwości w pliku konfiguracji podstawowej. W tym przykładzie, jeśli wartość connection-string jest ustawiona w obu plikach, zostanie użyta wartość z pliku *.Development.json.
Zapoznaj się z tą macierzą, aby lepiej zrozumieć, która wartość jest używana w zależności od tego, gdzie ta wartość jest określona (lub nie została określona) w danym pliku.
| określone w podstawowej konfiguracji | Nie określono w podstawowej konfiguracji | |
|---|---|---|
| określone w bieżącej konfiguracji środowiska | Bieżące środowisko | Bieżące środowisko |
| Nie określono w bieżącej konfiguracji środowiska | Baza | Żaden |
Aby zapoznać się z przykładem użycia wielu plików konfiguracji, zobacz use Data API builder with environments.
Właściwości konfiguracji
Ta sekcja zawiera wszystkie możliwe właściwości konfiguracji, które są dostępne dla pliku konfiguracji.
Schemat
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
$root |
$schema |
struna | ✔️ Tak | Żaden |
Każdy plik konfiguracji rozpoczyna się od właściwości $schema, określając schemat JSON na potrzeby walidacji.
Format
{
"$schema": <string>
}
Przykłady
Pliki schematu są dostępne dla wersji 0.3.7-alpha nowszych pod określonymi adresami URL, zapewniając użycie poprawnej wersji lub najnowszego dostępnego schematu.
https://github.com/Azure/data-api-builder/releases/download/<VERSION>-<suffix>/dab.draft.schema.json
Zastąp VERSION-suffix odpowiednią wersją.
https://github.com/Azure/data-api-builder/releases/download/v0.3.7-alpha/dab.draft.schema.json
Najnowsza wersja schematu jest zawsze dostępna w https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json.
Oto kilka przykładów prawidłowych wartości schematu.
| Wersja | URI | Opis |
|---|---|---|
| 0.3.7-alfa | https://github.com/Azure/data-api-builder/releases/download/v0.3.7-alpha/dab.draft.schema.json |
Używa schematu konfiguracji z wersji alfa narzędzia. |
| 0.10.23 | https://github.com/Azure/data-api-builder/releases/download/v0.10.23/dab.draft.schema.json |
Używa schematu konfiguracji do stabilnego wydania narzędzia. |
| Najnowszy | https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json |
Używa najnowszej wersji schematu konfiguracji. |
Nuta
Wersje konstruktora interfejsu API danych przed 0.3.7-alfa mogą mieć inny identyfikator URI schematu.
Źródło danych
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
$root |
data-source |
struna | ✔️ Tak | Żaden |
Sekcja data-source definiuje bazę danych i dostęp do bazy danych za pośrednictwem parametrów połączenia. Definiuje również opcje bazy danych. Właściwość data-source konfiguruje poświadczenia niezbędne do nawiązania połączenia z bazą danych zapasowych. W sekcji data-source opisano łączność z bazą danych zaplecza, określając zarówno database-type, jak i connection-string.
Format
{
"data-source": {
"database-type": <string>,
"connection-string": <string>,
// mssql-only
"options": {
"set-session-context": <true> (default) | <false>
},
// cosmosdb_nosql-only
"options": {
"database": <string>,
"container": <string>,
"schema": <string>
}
}
}
Właściwości
| Wymagane | Typ | |
|---|---|---|
database-type |
✔️ Tak | ciąg wyliczenia |
connection-string |
✔️ Tak | struna |
options |
❌ Nie | sprzeciwiać się |
Typ bazy danych
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
data-source |
database-type |
ciąg wyliczenia | ✔️ Tak | Żaden |
Ciąg wyliczenia służący do określania typu bazy danych do użycia jako źródła danych.
Format
{
"data-source": {
"database-type": <string>
}
}
Wartości typów
Właściwość type wskazuje rodzaj bazy danych zaplecza.
| Typ | Opis | Minimalna wersja |
|---|---|---|
mssql |
Azure SQL Database | - |
mssql |
Wystąpienie zarządzane usługi Azure SQL | - |
mssql |
SQL Server | 2016 |
sqldw |
Azure SQL Data Warehouse | - |
postgresql |
PostgreSQL | Ver. 11 |
mysql |
MySQL | Ver. 8 |
cosmosdb_nosql |
Azure Cosmos DB for NoSQL | - |
cosmosdb_postgresql |
Azure Cosmos DB for PostgreSQL | - |
Parametry połączenia
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
data-source |
connection-string |
struna | ✔️ Tak | Żaden |
Parametr wartość zawierającą prawidłowe parametry połączenia w celu nawiązania połączenia z docelową usługą bazy danych. Parametry połączenia ADO.NET do nawiązania połączenia z bazą danych zaplecza. Aby uzyskać więcej informacji, zobacz ADO.NET parametry połączenia.
Format
{
"data-source": {
"connection-string": <string>
}
}
Odporność połączenia
Konstruktor interfejsu API danych automatycznie ponawia próby żądań bazy danych po wykryciu błędów przejściowych. Logika ponawiania jest zgodna ze strategią r): $r^2$
Korzystając z tej formuły, można obliczyć czas dla każdej próby ponowienia w sekundach.
| Prób | Pierwszy | Second | Trzeci | Czwarty | Piąty |
|---|---|---|---|---|---|
| Sekund | 2s | 4s | 8s | 16s | 32s |
Usługi Azure SQL i SQL Server
Konstruktor interfejsu API danych używa biblioteki SqlClient do nawiązywania połączenia z usługą Azure SQL lub programem SQL Server przy użyciu parametrów połączenia w pliku konfiguracji. Lista wszystkich obsługiwanych opcji parametrów połączenia jest dostępna tutaj: właściwości SqlConnection.ConnectionString.
Konstruktor interfejsu API danych może również nawiązać połączenie z docelową bazą danych przy użyciu tożsamości usługi zarządzanej (MSI), gdy konstruktor interfejsu API danych jest hostowany na platformie Azure.
DefaultAzureCredential zdefiniowana w bibliotece Azure.Identity służy do nawiązywania połączenia przy użyciu znanych tożsamości, gdy nie określisz nazwy użytkownika ani hasła w parametrach połączenia. Aby uzyskać więcej informacji, zobacz przykłady DefaultAzureCredential.
tożsamości zarządzanej przypisanej przez użytkownika (UMI): dołącz uwierzytelnianiai właściwości identyfikatora użytkownika do parametrów połączenia, zastępując identyfikator klienta tożsamości zarządzanej przypisanej przez użytkownika:. tożsamość zarządzana przypisana przez system (SMI): dołącz właściwośćAuthentication i wykluczUserId oraz argumentyPassword z parametrów połączenia: . Brak UserId i password właściwości parametrów połączenia zasygnalizuje daB uwierzytelnienie przy użyciu tożsamości zarządzanej przypisanej przez system.
Aby uzyskać więcej informacji na temat konfigurowania tożsamości usługi zarządzanej przy użyciu usługi Azure SQL lub PROGRAMU SQL Server, zobacz Tożsamości zarządzane w usłudze Microsoft Entra for Azure SQL.
Przykłady
Wartość używana dla parametrów połączenia w dużej mierze zależy od usługi bazy danych używanej w danym scenariuszu. Zawsze można wybrać przechowywanie parametrów połączenia w zmiennej środowiskowej i uzyskiwanie do niej dostępu przy użyciu funkcji @env().
| Wartość | Opis | |
|---|---|---|
| użyj wartości ciągu usługi Azure SQL Database | Server=<server-address>;Database=<name-of-database>;User ID=<username>;Password=<password>; |
Parametry połączenia z kontem usługi Azure SQL Database. Aby uzyskać więcej informacji, zobacz parametry połączenia usługi Azure SQL Database. |
| użyj wartości ciągu usługi Azure Database for PostgreSQL | Server=<server-address>;Database=<name-of-database>;Port=5432;User Id=<username>;Password=<password>;Ssl Mode=Require; |
Parametry połączenia z kontem usługi Azure Database for PostgreSQL. Aby uzyskać więcej informacji, zobacz parametry połączenia usługi Azure Database for PostgreSQL. |
| użyj wartości ciągu NoSQL w usłudze Azure Cosmos DB | AccountEndpoint=<endpoint>;AccountKey=<key>; |
Parametry połączenia z kontem usługi Azure Cosmos DB for NoSQL. Aby uzyskać więcej informacji, zobacz parametry połączenia usługi Azure Cosmos DB for NoSQL. |
| użyj wartości ciągu usługi Azure Database for MySQL | Server=<server-address>;Database=<name-of-database>;User ID=<username>;Password=<password>;Sslmode=Required;SslCa=<path-to-certificate>; |
Parametry połączenia z kontem usługi Azure Database for MySQL. Aby uzyskać więcej informacji, zobacz parametry połączenia usługi Azure Database for MySQL. |
| Access zmiennej środowiskowej | @env('SQL_CONNECTION_STRING') |
Uzyskiwanie dostępu do zmiennej środowiskowej z komputera lokalnego. W tym przykładzie odwołuje się SQL_CONNECTION_STRING zmienna środowiskowa. |
Napiwek
Najlepszym rozwiązaniem jest unikanie przechowywania poufnych informacji w pliku konfiguracji. Jeśli to możliwe, użyj @env(), aby odwołać się do zmiennych środowiskowych. Aby uzyskać więcej informacji, zobacz @env() function.
Te przykłady ilustrują, jak można skonfigurować każdy typ bazy danych. Twój scenariusz może być unikatowy, ale ten przykład jest dobrym miejscem wyjścia. Zastąp symbole zastępcze, takie jak myserver, myDataBase, mylogini myPassword rzeczywistymi wartościami specyficznymi dla danego środowiska.
mssql
"data-source": {
"database-type": "mssql",
"connection-string": "$env('my-connection-string')",
"options": {
"set-session-context": true
}
}
postgresql
"data-source": {
"database-type": "postgresql",
"connection-string": "$env('my-connection-string')"
}
mysql
"data-source": {
"database-type": "mysql",
"connection-string": "$env('my-connection-string')"
}
cosmosdb_nosql
"data-source": {
"database-type": "cosmosdb_nosql",
"connection-string": "$env('my-connection-string')",
"options": {
"database": "Your_CosmosDB_Database_Name",
"container": "Your_CosmosDB_Container_Name",
"schema": "Path_to_Your_GraphQL_Schema_File"
}
}
cosmosdb_postgresql
"data-source": {
"database-type": "cosmosdb_postgresql",
"connection-string": "$env('my-connection-string')"
}
Nuta
Określone opcje, takie jak database, containeri schema, są specyficzne dla interfejsu API NoSQL usługi Azure Cosmos DB, a nie interfejsu API PostgreSQL. W przypadku usługi Azure Cosmos DB przy użyciu interfejsu API PostgreSQL "opcje" nie obejmują database, containerlub schema, jak w konfiguracji noSQL.
Opcje
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
data-source |
options |
sprzeciwiać się | ❌ Nie | Żaden |
Opcjonalna sekcja dodatkowych parametrów klucz-wartość dla określonych połączeń bazy danych.
Określa, czy sekcja options jest wymagana, czy nie jest w dużej mierze zależna od używanej usługi bazy danych.
Format
{
"data-source": {
"options": {
"<key-name>": <string>
}
}
}
opcje: { set-session-context: wartość logiczna }
W przypadku usług Azure SQL i SQL Server konstruktor interfejsu API danych może korzystać z SESSION_CONTEXT wysyłania metadanych określonych przez użytkownika do bazowej bazy danych. Takie metadane są dostępne dla konstruktora interfejsu API danych z powodu oświadczeń znajdujących się w tokenie dostępu. Dane SESSION_CONTEXT są dostępne dla bazy danych podczas połączenia z bazą danych do momentu zamknięcia tego połączenia. Aby uzyskać więcej informacji, zobacz kontekst sesji.
Przykład procedury składowanej SQL:
CREATE PROC GetUser @userId INT AS
BEGIN
-- Check if the current user has access to the requested userId
IF SESSION_CONTEXT(N'user_role') = 'admin'
OR SESSION_CONTEXT(N'user_id') = @userId
BEGIN
SELECT Id, Name, Age, IsAdmin
FROM Users
WHERE Id = @userId;
END
ELSE
BEGIN
RAISERROR('Unauthorized access', 16, 1);
END
END;
Przykład konfiguracji JSON:
{
"$schema": "https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json",
"data-source": {
"database-type": "mssql",
"connection-string": "@env('SQL_CONNECTION_STRING')",
"options": {
"set-session-context": true
}
},
"entities": {
"User": {
"source": {
"object": "dbo.GetUser",
"type": "stored-procedure",
"parameters": {
"userId": "number"
}
},
"permissions": [
{
"role": "authenticated",
"actions": ["execute"]
}
]
}
}
}
Wyjaśnienie:
procedura składowana (
GetUser):- Procedura sprawdza
SESSION_CONTEXTw celu sprawdzenia, czy obiekt wywołujący ma rolęadminlub pasuje do podanegouserId. - Nieautoryzowany dostęp powoduje wystąpienie błędu.
- Procedura sprawdza
konfiguracji JSON:
-
set-session-contextjest włączona możliwość przekazywania metadanych użytkownika z tokenu dostępu do bazy danych. - Właściwość
parametersmapuje parametruserIdwymagany przez procedurę składowaną. - Blok
permissionsgwarantuje, że tylko uwierzytelnieni użytkownicy będą mogli wykonać procedurę składowaną.
-
Pliki źródła danych
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
$root |
data-source-files |
tablica ciągów | ❌ Nie | Żaden |
Konstruktor interfejsu API danych obsługuje wiele plików konfiguracji dla różnych źródeł danych, z jednym wyznaczonym jako plik najwyższego poziomu zarządzający runtime ustawieniami. Wszystkie konfiguracje współdzielą ten sam schemat, umożliwiając runtime ustawienia w dowolnym pliku bez błędów. Konfiguracje podrzędne są scalane automatycznie, ale należy unikać odwołań cyklicznych. Jednostki można podzielić na oddzielne pliki w celu lepszego zarządzania, ale relacje między jednostkami muszą znajdować się w tym samym pliku.
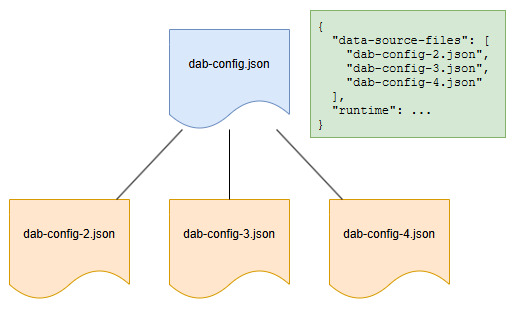
Format
{
"data-source-files": [ <string> ]
}
Zagadnienia dotyczące pliku konfiguracji
- Każdy plik konfiguracji musi zawierać właściwość
data-source. - Każdy plik konfiguracji musi zawierać właściwość
entities. - Ustawienie
runtimejest używane tylko z pliku konfiguracji najwyższego poziomu, nawet jeśli zostały uwzględnione w innych plikach. - Podrzędne pliki konfiguracji mogą również zawierać własne pliki podrzędne.
- Pliki konfiguracji można organizować w podfoldery zgodnie z potrzebami.
- Nazwy jednostek muszą być unikatowe we wszystkich plikach konfiguracji.
- Relacje między jednostkami w różnych plikach konfiguracji nie są obsługiwane.
Przykłady
{
"data-source-files": [
"dab-config-2.json"
]
}
{
"data-source-files": [
"dab-config-2.json",
"dab-config-3.json"
]
}
Składnia podfolderu jest również obsługiwana:
{
"data-source-files": [
"dab-config-2.json",
"my-folder/dab-config-3.json",
"my-folder/my-other-folder/dab-config-4.json"
]
}
Środowiska wykonawczego
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
$root |
runtime |
sprzeciwiać się | ✔️ Tak | Żaden |
W sekcji runtime opisano opcje wpływające na zachowanie środowiska uruchomieniowego i ustawienia dla wszystkich uwidocznionych jednostek.
Format
{
"runtime": {
"rest": {
"path": <string> (default: /api),
"enabled": <true> (default) | <false>,
"request-body-strict": <true> (default) | <false>
},
"graphql": {
"path": <string> (default: /graphql),
"enabled": <true> (default) | <false>,
"allow-introspection": <true> (default) | <false>
},
"host": {
"mode": "production" (default) | "development",
"cors": {
"origins": ["<array-of-strings>"],
"allow-credentials": <true> | <false> (default)
},
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<client-id>",
"issuer": "<issuer-url>"
}
}
}
},
"cache": {
"enabled": <true> | <false> (default),
"ttl-seconds": <integer; default: 5>
},
"pagination": {
"max-page-size": <integer; default: 100000>,
"default-page-size": <integer; default: 100>,
"max-response-size-mb": <integer; default: 158>
},
"telemetry": {
"application-insights": {
"connection-string": <string>,
"enabled": <true> | <false> (default)
}
}
}
Właściwości
| Wymagane | Typ | |
|---|---|---|
rest |
❌ Nie | sprzeciwiać się |
graphql |
❌ Nie | sprzeciwiać się |
host |
❌ Nie | sprzeciwiać się |
cache |
❌ Nie | sprzeciwiać się |
Przykłady
Oto przykład sekcji środowiska uruchomieniowego z wieloma typowymi parametrami domyślnymi określonymi.
{
"runtime": {
"rest": {
"enabled": true,
"path": "/api",
"request-body-strict": true
},
"graphql": {
"enabled": true,
"path": "/graphql",
"allow-introspection": true
},
"host": {
"mode": "development",
"cors": {
"allow-credentials": false,
"origins": [
"*"
]
},
"authentication": {
"provider": "StaticWebApps",
"jwt": {
"audience": "<client-id>",
"issuer": "<identity-provider-issuer-uri>"
}
}
},
"cache": {
"enabled": true,
"ttl-seconds": 5
},
"pagination": {
"max-page-size": -1 | <integer; default: 100000>,
"default-page-size": -1 | <integer; default: 100>,
"max-response-size-mb": <integer; default: 158>
},
"telemetry": {
"application-insights": {
"connection-string": "<connection-string>",
"enabled": true
}
}
}
}
GraphQL (środowisko uruchomieniowe)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime |
graphql |
sprzeciwiać się | ❌ Nie | Żaden |
Ten obiekt określa, czy język GraphQL jest włączony, a nazwa[s] używana do uwidaczniania jednostki jako typu GraphQL. Ten obiekt jest opcjonalny i używany tylko wtedy, gdy domyślna nazwa lub ustawienia nie są wystarczające. W tej sekcji opisano ustawienia globalne punktu końcowego graphQL.
Format
{
"runtime": {
"graphql": {
"path": <string> (default: /graphql),
"enabled": <true> (default) | <false>,
"depth-limit": <integer; default: none>,
"allow-introspection": <true> (default) | <false>,
"multiple-mutations": <object>
}
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
enabled |
❌ Nie | boolowski | Prawdziwy |
path |
❌ Nie | struna | /graphql (ustawienie domyślne) |
allow-introspection |
❌ Nie | boolowski | Prawdziwy |
multiple-mutations |
❌ Nie | sprzeciwiać się | { create: { enabled: false } } |
Włączone (środowisko uruchomieniowe GraphQL)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.graphql |
enabled |
boolowski | ❌ Nie | Żaden |
Określa, czy włączyć, czy wyłączyć punkty końcowe GraphQL globalnie. Jeśli globalnie nie będą dostępne żadne jednostki za pośrednictwem żądań GraphQL niezależnie od ustawień poszczególnych jednostek.
Format
{
"runtime": {
"graphql": {
"enabled": <true> (default) | <false>
}
}
}
Przykłady
W tym przykładzie punkt końcowy graphQL jest wyłączony dla wszystkich jednostek.
{
"runtime": {
"graphql": {
"enabled": false
}
}
}
Limit głębokości (środowisko uruchomieniowe GraphQL)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.graphql |
depth-limit |
liczba całkowita | ❌ Nie | Żaden |
Maksymalna dozwolona głębokość zapytania zapytania.
Możliwość obsługi zagnieżdżonych zapytań w oparciu o definicje relacji w narzędziu GraphQL jest niesamowitą funkcją umożliwiającą użytkownikom pobieranie złożonych, powiązanych danych w jednym zapytaniu. Jednak w miarę jak użytkownicy nadal dodawają zagnieżdżone zapytania, zwiększa się złożoność zapytania, co może ostatecznie naruszyć wydajność i niezawodność bazy danych i punktu końcowego interfejsu API. Aby zarządzać tą sytuacją, właściwość runtime/graphql/depth-limit ustawia maksymalną dozwoloną głębokość zapytania GraphQL (i mutację). Ta właściwość umożliwia deweloperom zachowanie równowagi, umożliwiając użytkownikom korzystanie z zalet zagnieżdżonych zapytań przy jednoczesnym umieszczeniu limitów, aby zapobiec scenariuszom, które mogłyby zagrozić wydajności i jakości systemu.
Przykłady
{
"runtime": {
"graphql": {
"depth-limit": 2
}
}
}
Ścieżka (środowisko uruchomieniowe GraphQL)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.graphql |
path |
struna | ❌ Nie | "/graphql" |
Definiuje ścieżkę adresu URL, w której jest udostępniany punkt końcowy GraphQL. Jeśli na przykład ten parametr ma ustawioną wartość /graphql, punkt końcowy graphQL jest uwidaczniony jako /graphql. Domyślnie ścieżka to /graphql.
Ważny
Ścieżki podrzędne nie są dozwolone dla tej właściwości. Niestandardowa wartość ścieżki dla punktu końcowego GraphQL nie jest obecnie dostępna.
Format
{
"runtime": {
"graphql": {
"path": <string> (default: /graphql)
}
}
}
Przykłady
W tym przykładzie główny identyfikator URI graphQL jest /query.
{
"runtime": {
"graphql": {
"path": "/query"
}
}
}
Zezwalaj na introspekcję (środowisko uruchomieniowe GraphQL)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.graphql |
allow-introspection |
boolowski | ❌ Nie | Prawdziwy |
Ta flaga logiczna steruje możliwością wykonywania zapytań introspekcji schematu w punkcie końcowym GraphQL. Włączenie introspekcji umożliwia klientom wykonywanie zapytań dotyczących schematu pod kątem dostępnych typów danych, rodzajów zapytań, które mogą wykonywać, oraz dostępnych mutacji.
Ta funkcja jest przydatna podczas opracowywania w celu zrozumienia struktury interfejsu API GraphQL i narzędzi, które automatycznie generują zapytania. Jednak w środowiskach produkcyjnych może być wyłączone, aby zaciemnić szczegóły schematu interfejsu API i zwiększyć bezpieczeństwo. Domyślnie włączono introspekcję, umożliwiając natychmiastową i kompleksową eksplorację schematu GraphQL.
Format
{
"runtime": {
"graphql": {
"allow-introspection": <true> (default) | <false>
}
}
}
Przykłady
W tym przykładzie introspekcja jest wyłączona.
{
"runtime": {
"graphql": {
"allow-introspection": false
}
}
}
Wiele mutacji (środowisko uruchomieniowe GraphQL)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.graphql |
multiple-mutations |
sprzeciwiać się | ❌ Nie | Żaden |
Konfiguruje wszystkie operacje mutacji dla środowiska uruchomieniowego GraphQL.
Nuta
Domyślnie wiele mutacji nie jest włączona i musi być jawnie skonfigurowana do włączenia.
Format
{
"runtime": {
"graphql": {
"multiple-mutations": {
"create": {
"enabled": <true> (default) | <false>
}
}
}
}
}
Właściwości
| Wymagane | Typ | |
|---|---|---|
create |
❌ Nie | sprzeciwiać się |
Wiele mutacji — tworzenie (środowisko uruchomieniowe GraphQL)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.graphql.multiple-mutations |
create |
boolowski | ❌ Nie | Fałszywy |
Konfiguruje wiele operacji tworzenia dla środowiska uruchomieniowego GraphQL.
Format
{
"runtime": {
"graphql": {
"multiple-mutations": {
"create": {
"enabled": <true> (default) | <false>
}
}
}
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
enabled |
✔️ Tak | boolowski | Prawdziwy |
Przykłady
Poniżej przedstawiono sposób włączania i używania wielu mutacji w środowisku uruchomieniowym GraphQL. W takim przypadku operacja create jest skonfigurowana tak, aby zezwalała na tworzenie wielu rekordów w jednym żądaniu przez ustawienie właściwości runtime.graphql.multiple-mutations.create.enabled na wartość true.
Przykład konfiguracji
Ta konfiguracja umożliwia wiele mutacji create:
{
"runtime": {
"graphql": {
"multiple-mutations": {
"create": {
"enabled": true
}
}
}
},
"entities": {
"User": {
"source": "dbo.Users",
"permissions": [
{
"role": "anonymous",
"actions": ["create"]
}
]
}
}
}
Przykład mutacji GraphQL
Korzystając z powyższej konfiguracji, następująca mutacja tworzy wiele rekordów User w jednej operacji:
mutation {
createUsers(input: [
{ name: "Alice", age: 30, isAdmin: true },
{ name: "Bob", age: 25, isAdmin: false },
{ name: "Charlie", age: 35, isAdmin: true }
]) {
id
name
age
isAdmin
}
}
REST (środowisko uruchomieniowe)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime |
rest |
sprzeciwiać się | ❌ Nie | Żaden |
W tej sekcji opisano ustawienia globalne punktów końcowych REST. Te ustawienia służą jako wartości domyślne dla wszystkich jednostek, ale mogą być zastępowane dla poszczególnych jednostek w odpowiednich konfiguracjach.
Format
{
"runtime": {
"rest": {
"path": <string> (default: /api),
"enabled": <true> (default) | <false>,
"request-body-strict": <true> (default) | <false>
}
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
enabled |
❌ Nie | boolowski | Prawdziwy |
path |
❌ Nie | struna | /Api |
request-body-strict |
❌ Nie | boolowski | Prawdziwy |
Włączone (środowisko uruchomieniowe REST)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.rest |
enabled |
boolowski | ❌ Nie | Żaden |
Flaga logiczna określająca globalną dostępność punktów końcowych REST. Jeśli jest wyłączona, jednostki nie mogą być dostępne za pośrednictwem interfejsu REST, niezależnie od ustawień poszczególnych jednostek.
Format
{
"runtime": {
"rest": {
"enabled": <true> (default) | <false>,
}
}
}
Przykłady
W tym przykładzie punkt końcowy interfejsu API REST jest wyłączony dla wszystkich jednostek.
{
"runtime": {
"rest": {
"enabled": false
}
}
}
Ścieżka (środowisko uruchomieniowe REST)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.rest |
path |
struna | ❌ Nie | "/api" |
Ustawia ścieżkę adresu URL na potrzeby uzyskiwania dostępu do wszystkich uwidocznionych punktów końcowych REST. Na przykład ustawienie path na wartość /api sprawia, że punkt końcowy REST jest dostępny pod adresem /api/<entity>. Ścieżki podrzędne nie są dozwolone. To pole jest opcjonalne z /api jako domyślne.
Nuta
Podczas wdrażania konstruktora interfejsu API danych przy użyciu usługi Static Web Apps (wersja zapoznawcza) usługa platformy Azure automatycznie wprowadza dodatkową ścieżkę podrzędną /data-api do adresu URL. To zachowanie zapewnia zgodność z istniejącymi funkcjami statycznej aplikacji internetowej. Wynikowy punkt końcowy będzie /data-api/api/<entity>. Dotyczy to tylko usługi Static Web Apps.
Format
{
"runtime": {
"rest": {
"path": <string> (default: /api)
}
}
}
Ważny
Dla tej właściwości nie są dozwolone ścieżki podrzędne podane przez użytkownika.
Przykłady
W tym przykładzie główny identyfikator URI interfejsu API REST to /data.
{
"runtime": {
"rest": {
"path": "/data"
}
}
}
Napiwek
Jeśli zdefiniujesz jednostkę Author, punkt końcowy tej jednostki będzie /data/Author.
Treść żądania — ścisłe (środowisko uruchomieniowe REST)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.rest |
request-body-strict |
boolowski | ❌ Nie | Prawdziwy |
To ustawienie określa, w jaki sposób jest weryfikowane ściśle ciało żądania dla operacji mutacji REST (np. POST, PUT, PATCH).
-
true(wartość domyślna): dodatkowe pola w treści żądania, które nie są mapowe na kolumny tabeli, powodują wyjątekBadRequest. -
false: Dodatkowe pola są ignorowane i przetwarzane są tylko prawidłowe kolumny.
To ustawienie nie dotyczy GET żądań, ponieważ ich treść żądania jest zawsze ignorowana.
Zachowanie przy użyciu określonych konfiguracji kolumn
- Kolumny z wartością default() są ignorowane podczas
INSERTtylko wtedy, gdy ich wartość w ładunku jestnull. Kolumny z wartością default() nie są ignorowane podczasUPDATEniezależnie od wartości ładunku. - Obliczone kolumny są zawsze ignorowane.
- Kolumny generowane automatycznie są zawsze ignorowane.
Format
{
"runtime": {
"rest": {
"request-body-strict": <true> (default) | <false>
}
}
}
Przykłady
CREATE TABLE Users (
Id INT PRIMARY KEY IDENTITY,
Name NVARCHAR(50) NOT NULL,
Age INT DEFAULT 18,
IsAdmin BIT DEFAULT 0,
IsMinor AS IIF(Age <= 18, 1, 0)
);
Przykładowa konfiguracja
{
"runtime": {
"rest": {
"request-body-strict": false
}
}
}
Zachowanie INSERT z request-body-strict: false
ładunku żądania:
{
"Id": 999,
"Name": "Alice",
"Age": null,
"IsAdmin": null,
"IsMinor": false,
"ExtraField": "ignored"
}
wynikowa instrukcja Insert:
INSERT INTO Users (Name) VALUES ('Alice');
-- Default values for Age (18) and IsAdmin (0) are applied by the database.
-- IsMinor is ignored because it’s a computed column.
-- ExtraField is ignored.
-- The database generates the Id value.
ładunku odpowiedzi:
{
"Id": 1, // Auto-generated by the database
"Name": "Alice",
"Age": 18, // Default applied
"IsAdmin": false, // Default applied
"IsMinor": true // Computed
}
Zachowanie AKTUALIZACJI za pomocą request-body-strict: false
ładunku żądania:
{
"Id": 1,
"Name": "Alice Updated",
"Age": null, // explicitely set to 'null'
"IsMinor": true, // ignored because computed
"ExtraField": "ignored"
}
wynikowej instrukcji aktualizacji:
UPDATE Users
SET Name = 'Alice Updated', Age = NULL
WHERE Id = 1;
-- IsMinor and ExtraField are ignored.
ładunku odpowiedzi:
{
"Id": 1,
"Name": "Alice Updated",
"Age": null,
"IsAdmin": false,
"IsMinor": false // Recomputed by the database (false when age is `null`)
}
Host (środowisko uruchomieniowe)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime |
host |
sprzeciwiać się | ❌ Nie | Żaden |
Sekcja host w konfiguracji środowiska uruchomieniowego zawiera ustawienia kluczowe dla środowiska operacyjnego konstruktora interfejsu API danych. Te ustawienia obejmują tryby operacyjne, konfigurację mechanizmu CORS i szczegóły uwierzytelniania.
Format
{
"runtime": {
"host": {
"mode": "production" (default) | "development",
"max-response-size-mb": <integer; default: 158>,
"cors": {
"origins": ["<array-of-strings>"],
"allow-credentials": <true> | <false> (default)
},
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<client-id>",
"issuer": "<issuer-url>"
}
}
}
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
mode |
❌ Nie | ciąg wyliczenia | produkcja |
cors |
❌ Nie | sprzeciwiać się | Żaden |
authentication |
❌ Nie | sprzeciwiać się | Żaden |
Przykłady
Oto przykład środowiska uruchomieniowego skonfigurowanego do hostowania programowania.
{
"runtime": {
"host": {
"mode": "development",
"cors": {
"allow-credentials": false,
"origins": ["*"]
},
"authentication": {
"provider": "Simulator"
}
}
}
}
Tryb (środowisko uruchomieniowe hosta)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.host |
mode |
struna | ❌ Nie | "produkcja" |
Określa, czy aparat konstruktora interfejsu API danych powinien działać w trybie development lub production. Domyślna wartość to production.
Zazwyczaj podstawowe błędy bazy danych są szczegółowo widoczne, ustawiając domyślny poziom szczegółów dzienników, aby Debug podczas uruchamiania w programowania. W środowisku produkcyjnym poziom szczegółowości dzienników jest ustawiony na Error.
Napiwek
Domyślny poziom dziennika można dodatkowo zastąpić przy użyciu dab start --LogLevel <level-of-detail>. Aby uzyskać więcej informacji, zobacz interfejs wiersza polecenia (CLI) reference.
Format
{
"runtime": {
"host": {
"mode": "production" (default) | "development"
}
}
}
Wartości
Oto lista dozwolonych wartości dla tej właściwości:
| Opis | |
|---|---|
production |
Używanie podczas hostowania w środowisku produkcyjnym na platformie Azure |
development |
Używanie w programach programistycznych na komputerze lokalnym |
Zachowania
- Tylko w trybie
developmentjest dostępna struktura Swagger. - Tylko w trybie
developmentjest dostępny Banana Cake Pop.
Maksymalny rozmiar odpowiedzi (środowisko uruchomieniowe)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.host |
max-response-size-mb |
liczba całkowita | ❌ Nie | 158 |
Ustawia maksymalny rozmiar (w megabajtach) dla dowolnego wyniku. To ustawienie umożliwia użytkownikom skonfigurowanie ilości danych, które mogą obsłużyć pamięć platformy hosta podczas przesyłania strumieniowego danych z bazowych źródeł danych.
Gdy użytkownicy żądają dużych zestawów wyników, mogą przeciążyć bazę danych i konstruktora interfejsu API danych. Aby rozwiązać ten problem, max-response-size-mb umożliwia deweloperom ograniczenie maksymalnego rozmiaru odpowiedzi mierzonego w megabajtach jako strumieni danych ze źródła danych. Ten limit jest oparty na ogólnym rozmiarze danych, a nie na liczbie wierszy. Ponieważ kolumny mogą się różnić w rozmiarze, niektóre kolumny (takie jak tekst, binarny, XML lub JSON) mogą przechowywać maksymalnie 2 GB, co powoduje, że poszczególne wiersze mogą być potencjalnie bardzo duże. To ustawienie ułatwia deweloperom ochronę punktów końcowych przez ograniczenie rozmiarów odpowiedzi i zapobieganie przeciążeniom systemu przy zachowaniu elastyczności dla różnych typów danych.
Dozwolone wartości
| Wartość | Wynik |
|---|---|
null |
Wartość domyślna to 158 megabajtów, jeśli nie ustawiono lub jawnie ustawiono wartość null. |
integer |
Obsługiwana jest dowolna dodatnia liczba całkowita 32-bitowa. |
< 0 |
Nieobsługiwane. Błędy walidacji występują, jeśli ustawiono wartość mniejszą niż 1 MB. |
Format
{
"runtime": {
"host": {
"max-response-size-mb": <integer; default: 158>
}
}
}
CORS (środowisko uruchomieniowe hosta)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.host |
cors |
sprzeciwiać się | ❌ Nie | Żaden |
Ustawienia współużytkowania zasobów między źródłami (CORS) dla hosta aparatu konstruktora interfejsu API danych.
Format
{
"runtime": {
"host": {
"cors": {
"origins": ["<array-of-strings>"],
"allow-credentials": <true> | <false> (default)
}
}
}
}
Właściwości
| Wymagane | Typ | |
|---|---|---|
allow-credentials |
❌ Nie | boolowski |
origins |
❌ Nie | tablica ciągów |
Zezwalaj na poświadczenia (środowisko uruchomieniowe hosta)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.host.cors |
allow-credentials |
boolowski | ❌ Nie | Fałszywy |
Jeśli wartość true, ustawia nagłówek Access-Control-Allow-Credentials CORS.
Nuta
Aby uzyskać więcej informacji na temat nagłówka Access-Control-Allow-Credentials CORS, zobacz dokumentacja mechanizmu CORS sieci Web usługi MDN.
Format
{
"runtime": {
"host": {
"cors": {
"allow-credentials": <true> (default) | <false>
}
}
}
}
Źródła (środowisko uruchomieniowe hosta)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.host.cors |
origins |
tablica ciągów | ❌ Nie | Żaden |
Ustawia tablicę z listą dozwolonych źródeł dla mechanizmu CORS. To ustawienie umożliwia * symbol wieloznaczny dla wszystkich źródeł.
Format
{
"runtime": {
"host": {
"cors": {
"origins": ["<array-of-strings>"]
}
}
}
}
Przykłady
Oto przykład hosta, który zezwala na mechanizm CORS bez poświadczeń ze wszystkich źródeł.
{
"runtime": {
"host": {
"cors": {
"allow-credentials": false,
"origins": ["*"]
}
}
}
}
Uwierzytelnianie (środowisko uruchomieniowe hosta)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.host |
authentication |
sprzeciwiać się | ❌ Nie | Żaden |
Konfiguruje uwierzytelnianie hosta konstruktora interfejsu API danych.
Format
{
"runtime": {
"host": {
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<string>",
"issuer": "<string>"
}
}
}
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
provider |
❌ Nie | ciąg wyliczenia | StaticWebApps |
jwt |
❌ Nie | sprzeciwiać się | Żaden |
Uwierzytelnianie i obowiązki klienta
Konstruktor interfejsu API danych jest przeznaczony do obsługi szerszego potoku zabezpieczeń i należy wykonać ważne kroki, które należy skonfigurować przed przetwarzaniem żądań. Ważne jest, aby zrozumieć, że konstruktor interfejsu API danych nie uwierzytelnia obiektu wywołującego bezpośredniego (takiego jak aplikacja internetowa), ale raczej użytkownika końcowego na podstawie prawidłowego tokenu JWT dostarczonego przez zaufanego dostawcę tożsamości (na przykład Identyfikator Entra). Gdy żądanie dociera do konstruktora interfejsu API danych, zakłada, że token JWT jest prawidłowy i sprawdza go pod kątem skonfigurowanych wymagań wstępnych, takich jak określone oświadczenia. Reguły autoryzacji są następnie stosowane w celu określenia, do czego użytkownik może uzyskać dostęp lub zmodyfikować.
Po zakończeniu autoryzacji konstruktor interfejsu API danych wykonuje żądanie przy użyciu konta określonego w parametrach połączenia. Ponieważ to konto często wymaga podwyższonych uprawnień do obsługi różnych żądań użytkowników, niezbędne jest zminimalizowanie praw dostępu w celu zmniejszenia ryzyka. Zalecamy zabezpieczenie architektury przez skonfigurowanie usługi Private Link między aplikacją internetową frontonu a punktem końcowym interfejsu API oraz przez wzmocnienie zabezpieczeń maszyny obsługującej konstruktora interfejsu API danych. Te środki pomagają zapewnić bezpieczeństwo środowiska, ochronę danych i zminimalizowanie luk w zabezpieczeniach, które mogą zostać wykorzystane do uzyskiwania dostępu, modyfikowania lub eksfiltrowania poufnych informacji.
Dostawca (środowisko uruchomieniowe hosta)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.host.authentication |
provider |
struna | ❌ Nie | "StaticWebApps" |
Ustawienie authentication.provider w ramach konfiguracji host definiuje metodę uwierzytelniania używanego przez konstruktora interfejsu API danych. Określa, w jaki sposób interfejs API weryfikuje tożsamość użytkowników lub usług próbujących uzyskać dostęp do swoich zasobów. To ustawienie umożliwia elastyczność wdrażania i integracji dzięki obsłudze różnych mechanizmów uwierzytelniania dostosowanych do różnych środowisk i wymagań dotyczących zabezpieczeń.
| Dostawca | Opis |
|---|---|
StaticWebApps |
Instruuje konstruktora interfejsu API danych, aby szukał zestawu nagłówków HTTP obecnych tylko podczas uruchamiania w środowisku usługi Static Web Apps. |
AppService |
Gdy środowisko uruchomieniowe jest hostowane w usłudze Azure AppService z włączonym i skonfigurowanym uwierzytelnianiem usługi AppService (EasyAuth). |
AzureAd |
Należy skonfigurować usługę Microsoft Entra Identity, aby mogła uwierzytelniać żądanie wysyłane do konstruktora interfejsu API danych ("Aplikacja serwera"). Aby uzyskać więcej informacji, zobacz uwierzytelniania identyfikatora entra firmy Microsoft. |
Simulator |
Konfigurowalny dostawca uwierzytelniania, który instruuje aparat konstruktora interfejsu API danych, aby traktować wszystkie żądania jako uwierzytelnione. Aby uzyskać więcej informacji, zobacz uwierzytelnianie lokalne. |
Format
{
"runtime": {
"host": {
"authentication": {
"provider": "StaticWebApps" (default) | ...
}
}
}
}
Wartości
Oto lista dozwolonych wartości dla tej właściwości:
| Opis | |
|---|---|
StaticWebApps |
Azure Static Web Apps |
AppService |
Azure App Service |
AzureAD |
Microsoft Entra ID |
Simulator |
Simulator |
Tokeny internetowe JSON (środowisko uruchomieniowe hosta)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.host.authentication |
jwt |
sprzeciwiać się | ❌ Nie | Żaden |
Jeśli dostawca uwierzytelniania ma ustawioną wartość AzureAD (Microsoft Entra ID), ta sekcja jest wymagana do określenia odbiorców i wystawców tokenów sieci Web JSOn (JWT). Te dane służą do weryfikowania tokenów względem dzierżawy firmy Microsoft Entra.
Wymagane, jeśli dostawca uwierzytelniania jest AzureAD dla identyfikatora Entra firmy Microsoft. W tej sekcji należy określić audience i issuer, aby zweryfikować odebrany token JWT względem zamierzonej dzierżawy AzureAD na potrzeby uwierzytelniania.
| Ustawienie | Opis |
|---|---|
| audiencja | Identyfikuje zamierzonego adresata tokenu; zazwyczaj identyfikator aplikacji zarejestrowany w usłudze Microsoft Entra Identity (lub dostawcy tożsamości), upewniając się, że token został rzeczywiście wystawiony dla aplikacji. |
| Emitenta | Określa adres URL urzędu wystawiającego, czyli usługę tokenu, która wystawiła JWT. Ten adres URL powinien być zgodny z adresem URL wystawcy dostawcy tożsamości, z którego uzyskano JWT, weryfikowanie źródła tokenu. |
Format
{
"runtime": {
"host": {
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<client-id>",
"issuer": "<issuer-url>"
}
}
}
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
audience |
❌ Nie | struna | Żaden |
issuer |
❌ Nie | struna | Żaden |
Przykłady
Konstruktor interfejsu API danych (DAB) oferuje elastyczną obsługę uwierzytelniania, integrując się z usługą Microsoft Entra Identity i niestandardowymi serwerami tokenu internetowego JSON (JWT). Na tej ilustracji JWT Server reprezentuje usługę uwierzytelniania, która wystawia tokeny JWT klientom po pomyślnym zalogowaniu. Następnie klient przekazuje token do języka DAB, który może przesłuchić jego oświadczenia i właściwości.
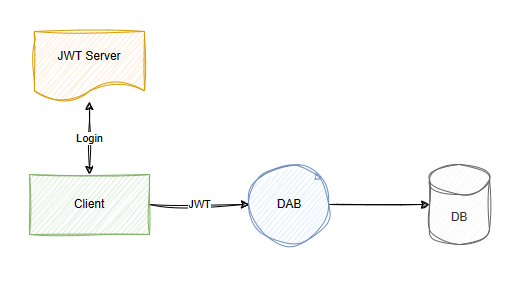
Poniżej przedstawiono przykłady właściwości host, biorąc pod uwagę różne opcje architektury, które można wprowadzić w rozwiązaniu.
Azure Static Web Apps
{
"host": {
"mode": "development",
"cors": {
"origins": ["https://dev.example.com"],
"credentials": true
},
"authentication": {
"provider": "StaticWebApps"
}
}
}
W przypadku StaticWebAppskonstruktor interfejsu API danych oczekuje, że usługa Azure Static Web Apps uwierzytelnia żądanie, a nagłówek HTTP X-MS-CLIENT-PRINCIPAL jest obecny.
Azure App Service
{
"host": {
"mode": "production",
"cors": {
"origins": [ "https://api.example.com" ],
"credentials": false
},
"authentication": {
"provider": "AppService",
"jwt": {
"audience": "9e7d452b-7e23-4300-8053-55fbf243b673",
"issuer": "https://example-appservice-auth.com"
}
}
}
}
Uwierzytelnianie jest delegowane do obsługiwanego dostawcy tożsamości, w którym można wystawiać token dostępu. Uzyskany token dostępu musi być dołączony do żądań przychodzących do konstruktora interfejsu API danych. Konstruktor interfejsu API danych weryfikuje wszystkie przedstawione tokeny dostępu, zapewniając, że konstruktor interfejsu API danych był zamierzonym odbiorcą tokenu.
Microsoft Entra ID
{
"host": {
"mode": "production",
"cors": {
"origins": [ "https://api.example.com" ],
"credentials": true
},
"authentication": {
"provider": "AzureAD",
"jwt": {
"audience": "c123d456-a789-0abc-a12b-3c4d56e78f90",
"issuer": "https://login.microsoftonline.com/98765f43-21ba-400c-a5de-1f2a3d4e5f6a/v2.0"
}
}
}
}
Symulator (tylko programowanie)
{
"host": {
"mode": "development",
"authentication": {
"provider": "Simulator"
}
}
}
Odbiorcy (środowisko uruchomieniowe hosta)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.host.authentication.jwt |
audience |
struna | ❌ Nie | Żaden |
Odbiorcy tokenu JWT.
Format
{
"runtime": {
"host": {
"authentication": {
"jwt": {
"audience": "<client-id>"
}
}
}
}
}
Wystawca (środowisko uruchomieniowe hosta)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.host.authentication.jwt |
issuer |
struna | ❌ Nie | Żaden |
Wystawca tokenu JWT.
Format
{
"runtime": {
"host": {
"authentication": {
"jwt": {
"issuer": "<issuer-url>"
}
}
}
}
}
Stronicowanie (środowisko uruchomieniowe)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime |
pagination |
sprzeciwiać się | ❌ Nie | Żaden |
Konfiguruje limity stronicowania dla punktów końcowych REST i GraphQL.
Format
{
"runtime": {
"pagination": {
"max-page-size": <integer; default: 100000>,
"default-page-size": <integer; default: 100>
}
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
max-page-size |
❌ Nie | liczba całkowita | 100,000 |
default-page-size |
❌ Nie | liczba całkowita | 100 |
Przykładowa konfiguracja
{
"runtime": {
"pagination": {
"max-page-size": 1000,
"default-page-size": 2
}
},
"entities": {
"Users": {
"source": "dbo.Users",
"permissions": [
{
"actions": ["read"],
"role": "anonymous"
}
]
}
}
}
Przykład stronicowania REST
W tym przykładzie wysłanie żądania REST GET https://localhost:5001/api/users zwróci dwa rekordy w tablicy value, ponieważ default-page-size jest ustawiona na 2. Jeśli istnieje więcej wyników, konstruktor interfejsu API danych zawiera nextLink w odpowiedzi.
nextLink zawiera parametr $after do pobierania następnej strony danych.
Prosić:
GET https://localhost:5001/api/users
Odpowiedź:
{
"value": [
{
"Id": 1,
"Name": "Alice",
"Age": 30,
"IsAdmin": true,
"IsMinor": false
},
{
"Id": 2,
"Name": "Bob",
"Age": 17,
"IsAdmin": false,
"IsMinor": true
}
],
"nextLink": "https://localhost:5001/api/users?$after=W3siRW50aXR5TmFtZSI6InVzZXJzIiwiRmllbGROYW1lI=="
}
Przy użyciu nextLinkklient może pobrać następny zestaw wyników.
Przykład stronicowania graphQL
W przypadku języka GraphQL użyj pól hasNextPage i endCursor na potrzeby stronicowania. Te pola wskazują, czy więcej wyników jest dostępnych, i podaj kursor na potrzeby pobierania następnej strony.
Zapytanie:
query {
users {
items {
Id
Name
Age
IsAdmin
IsMinor
}
hasNextPage
endCursor
}
}
Odpowiedź:
{
"data": {
"users": {
"items": [
{
"Id": 1,
"Name": "Alice",
"Age": 30,
"IsAdmin": true,
"IsMinor": false
},
{
"Id": 2,
"Name": "Bob",
"Age": 17,
"IsAdmin": false,
"IsMinor": true
}
],
"hasNextPage": true,
"endCursor": "W3siRW50aXR5TmFtZSI6InVzZXJzIiwiRmllbGROYW1lI=="
}
}
}
Aby pobrać następną stronę, dołącz wartość endCursor w następnym zapytaniu:
Zapytanie z kursorem:
query {
users(after: "W3siRW50aXR5TmFtZSI6InVzZXJzIiwiRmllbGROYW1lI==") {
items {
Id
Name
Age
IsAdmin
IsMinor
}
hasNextPage
endCursor
}
}
Dostosowywanie rozmiaru strony
Interfejsy REST i GraphQL umożliwiają dostosowanie liczby wyników na zapytanie przy użyciu $limit (REST) lub first (GraphQL).
wartość $limit/first |
Zachowanie |
|---|---|
-1 |
Wartość domyślna to max-page-size. |
< max-page-size |
Ogranicza wyniki do określonej wartości. |
0 lub < -1 |
Nieobsługiwane. |
> max-page-size |
Ograniczona do max-page-size. |
Przykładowe zapytanie REST:
GET https://localhost:5001/api/users?$limit=5
Przykładowe zapytanie GraphQL:
query {
users(first: 5) {
items {
Id
Name
Age
IsAdmin
IsMinor
}
}
}
Maksymalny rozmiar strony (środowisko uruchomieniowe stronicowania)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.pagination |
max-page-size |
Int | ❌ Nie | 100,000 |
Ustawia maksymalną liczbę rekordów najwyższego poziomu zwracanych przez interfejs REST lub GraphQL. Jeśli użytkownik żąda więcej niż max-page-size, wyniki są ograniczone do max-page-size.
Dozwolone wartości
| Wartość | Wynik |
|---|---|
-1 |
Wartość domyślna to maksymalna obsługiwana wartość. |
integer |
Obsługiwana jest dowolna dodatnia liczba całkowita 32-bitowa. |
< -1 |
Nieobsługiwane. |
0 |
Nieobsługiwane. |
Format
{
"runtime": {
"pagination": {
"max-page-size": <integer; default: 100000>
}
}
}
Domyślny rozmiar strony (środowisko uruchomieniowe stronicowania)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.pagination |
default-page-size |
Int | ❌ Nie | 100 |
Ustawia domyślną liczbę rekordów najwyższego poziomu zwracanych po włączeniu stronicowania, ale nie podano jawnego rozmiaru strony.
Dozwolone wartości
| Wartość | Wynik |
|---|---|
-1 |
Wartość domyślna bieżącego ustawienia max-page-size. |
integer |
Dowolna dodatnia liczba całkowita mniejsza niż bieżąca max-page-size. |
< -1 |
Nieobsługiwane. |
0 |
Nieobsługiwane. |
Pamięć podręczna (środowisko uruchomieniowe)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime |
cache |
sprzeciwiać się | ❌ Nie | Żaden |
Włącza i konfiguruje buforowanie dla całego środowiska uruchomieniowego.
Format
{
"runtime": {
"cache": <object>
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
enabled |
❌ Nie | boolowski | Żaden |
ttl-seconds |
❌ Nie | liczba całkowita | 5 |
Przykłady
W tym przykładzie pamięć podręczna jest włączona, a elementy wygasają po 30 sekundach.
{
"runtime": {
"cache": {
"enabled": true,
"ttl-seconds": 30
}
}
}
Włączone (środowisko uruchomieniowe pamięci podręcznej)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.cache |
enabled |
boolowski | ❌ Nie | Fałszywy |
Umożliwia buforowanie globalnie dla wszystkich jednostek. Wartość domyślna to false.
Format
{
"runtime": {
"cache": {
"enabled": <boolean>
}
}
}
Przykłady
W tym przykładzie pamięć podręczna jest wyłączona.
{
"runtime": {
"cache": {
"enabled": false
}
}
}
Czas wygaśnięcia w sekundach (środowisko uruchomieniowe pamięci podręcznej)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.cache |
ttl-seconds |
liczba całkowita | ❌ Nie | 5 |
Konfiguruje wartość czasu wygaśnięcia (TTL) w sekundach dla buforowanych elementów. Po upływie tego czasu elementy są automatycznie czyszczone z pamięci podręcznej. Wartość domyślna to 5 sekund.
Format
{
"runtime": {
"cache": {
"ttl-seconds": <integer>
}
}
}
Przykłady
W tym przykładzie pamięć podręczna jest włączona globalnie, a wszystkie elementy wygasają po 15 sekundach.
{
"runtime": {
"cache": {
"enabled": true,
"ttl-seconds": 15
}
}
}
Telemetria (środowisko uruchomieniowe)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime |
telemetry |
sprzeciwiać się | ❌ Nie | Żaden |
Ta właściwość umożliwia skonfigurowanie usługi Application Insights w celu scentralizowanego rejestrowania interfejsu API. Dowiedz się więcej.
Format
{
"runtime": {
"telemetry": {
"application-insights": {
"enabled": <true; default: true> | <false>,
"connection-string": <string>
}
}
}
}
Application Insights (środowisko uruchomieniowe telemetrii)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.telemetry |
application-insights |
sprzeciwiać się | ✔️ Tak | Żaden |
Włączone (telemetria usługi Application Insights)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.telemetry.application-insights |
enabled |
boolowski | ❌ Nie | Prawdziwy |
Parametry połączenia (telemetria usługi Application Insights)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
runtime.telemetry.application-insights |
connection-string |
struna | ✔️ Tak | Żaden |
Podmioty
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
$root |
entities |
sprzeciwiać się | ✔️ Tak | Żaden |
Sekcja entities służy jako rdzeń pliku konfiguracji, ustanawiając most między obiektami bazy danych i odpowiadającymi im punktami końcowymi interfejsu API. Ta sekcja mapuje obiekty bazy danych na uwidocznione punkty końcowe. Ta sekcja zawiera również mapowanie właściwości i definicję uprawnień. Każda uwidoczniona jednostka jest definiowana w dedykowanym obiekcie. Nazwa właściwości obiektu jest używana jako nazwa jednostki do uwidocznienia.
W tej sekcji opisano, jak każda jednostka w bazie danych jest reprezentowana w interfejsie API, w tym mapowania właściwości i uprawnienia. Każda jednostka jest hermetyzowana w ramach własnej podsekcji z nazwą jednostki działającą jako klucz do odwołania w całej konfiguracji.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"enabled": <true; default: true> | <false>,
"path": <string; default: "<entity-name>">,
"methods": <array of strings; default: ["GET", "POST"]>
},
"graphql": {
"enabled": <true; default: true> | <false>,
"type": {
"singular": <string>,
"plural": <string>
},
"operation": <"query" | "mutation"; default: "query">
},
"source": {
"object": <string>,
"type": <"view" | "stored-procedure" | "table">,
"key-fields": <array of strings>,
"parameters": {
"<parameter-name>": <string | number | boolean>
}
},
"mappings": {
"<database-field-name>": <string>
},
"relationships": {
"<relationship-name>": {
"cardinality": <"one" | "many">,
"target.entity": <string>,
"source.fields": <array of strings>,
"target.fields": <array of strings>,
"linking.object": <string>,
"linking.source.fields": <array of strings>,
"linking.target.fields": <array of strings>
}
},
"permissions": [
{
"role": <"anonymous" | "authenticated" | "custom-role-name">,
"actions": <array of strings>,
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
},
"policy": {
"database": <string>
}
}
]
}
}
}
Właściwości
| Wymagane | Typ | |
|---|---|---|
source |
✔️ Tak | sprzeciwiać się |
permissions |
✔️ Tak | tablica |
rest |
❌ Nie | sprzeciwiać się |
graphql |
❌ Nie | sprzeciwiać się |
mappings |
❌ Nie | sprzeciwiać się |
relationships |
❌ Nie | sprzeciwiać się |
cache |
❌ Nie | sprzeciwiać się |
Przykłady
Na przykład ten obiekt JSON instruuje konstruktora interfejsu API danych, aby uwidocznił jednostkę GraphQL o nazwie User i punkt końcowy REST dostępny za pośrednictwem ścieżki /User. Tabela dbo.User bazy danych tworzy kopię zapasową jednostki, a konfiguracja umożliwia każdemu anonimowy dostęp do punktu końcowego.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
},
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
]
}
}
}
W tym przykładzie zadeklarowana jest jednostka User. Ta nazwa User jest używana w dowolnym miejscu w pliku konfiguracji, w którym odwołują się jednostki. W przeciwnym razie nazwa jednostki nie jest odpowiednia dla punktów końcowych.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table",
"key-fields": ["Id"],
"parameters": {} // only when source.type = stored-procedure
},
"rest": {
"enabled": true,
"path": "/users",
"methods": [] // only when source.type = stored-procedure
},
"graphql": {
"enabled": true,
"type": {
"singular": "User",
"plural": "Users"
},
"operation": "query"
},
"mappings": {
"id": "Id",
"name": "Name",
"age": "Age",
"isAdmin": "IsAdmin"
},
"permissions": [
{
"role": "authenticated",
"actions": ["read"], // "execute" only when source.type = stored-procedure
"fields": {
"include": ["id", "name", "age", "isAdmin"],
"exclude": []
},
"policy": {
"database": "@claims.userId eq @item.id"
}
},
{
"role": "admin",
"actions": ["create", "read", "update", "delete"],
"fields": {
"include": ["*"],
"exclude": []
},
"policy": {
"database": "@claims.userRole eq 'UserAdmin'"
}
}
]
}
}
}
Źródło
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity} |
source |
sprzeciwiać się | ✔️ Tak | Żaden |
Konfiguracja {entity}.source łączy jednostkę uwidacznianą przez interfejs API i jej bazowy obiekt bazy danych. Ta właściwość określa tabelę bazy danych, widok lub procedurę składowaną reprezentowaną przez jednostkę, ustanawiając bezpośredni link do pobierania i manipulowania danymi.
W przypadku prostych scenariuszy, w których jednostka jest mapowana bezpośrednio do pojedynczej tabeli bazy danych, właściwość źródłowa wymaga tylko nazwy tego obiektu bazy danych. Ta prostota ułatwia szybką konfigurację typowych przypadków użycia: "source": "dbo.User".
Format
{
"entities": {
"<entity-name>": {
"source": {
"object": <string>,
"type": <"view" | "stored-procedure" | "table">,
"key-fields": <array of strings>,
"parameters": { // only when source.type = stored-procedure
"<name>": <string | number | boolean>
}
}
}
}
}
Właściwości
| Wymagane | Typ | |
|---|---|---|
object |
✔️ Tak | struna |
type |
✔️ Tak | ciąg wyliczenia |
parameters |
❌ Nie | sprzeciwiać się |
key-fields |
❌ Nie | tablica ciągów |
Przykłady
1. Proste mapowanie tabeli:
W tym przykładzie pokazano, jak skojarzyć jednostkę User z tabelą źródłową dbo.Users.
SQL
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
Configuration
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
}
}
}
}
2. Przykład procedury składowanej:
W tym przykładzie pokazano, jak skojarzyć jednostkę User ze źródłem proc dbo.GetUsers.
SQL
CREATE PROCEDURE GetUsers
@IsAdmin BIT
AS
SELECT Id, Name, Age, IsAdmin
FROM dbo.Users
WHERE IsAdmin = @IsAdmin;
Configuration
{
"entities": {
"User": {
"source": {
"type": "stored-procedure",
"object": "GetUsers",
"parameters": {
"IsAdmin": "boolean"
}
},
"mappings": {
"Id": "id",
"Name": "name",
"Age": "age",
"IsAdmin": "isAdmin"
}
}
}
}
Właściwość mappings jest opcjonalna dla procedur składowanych.
Sprzeciwiać się
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.source |
object |
struna | ✔️ Tak | Żaden |
Nazwa obiektu bazy danych do użycia. Jeśli obiekt należy do schematu dbo, określenie schematu jest opcjonalne. Ponadto nawiasy kwadratowe wokół nazw obiektów (np. [dbo].[Users] a dbo.Users) mogą być używane lub pomijane.
Przykłady
SQL
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
Configuration
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
}
}
}
}
notacja alternatywna bez schematu i nawiasów:
Jeśli tabela znajduje się w schemacie dbo, możesz pominąć schemat lub nawiasy:
{
"entities": {
"User": {
"source": {
"object": "Users",
"type": "table"
}
}
}
}
Typ (jednostki)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.source |
type |
struna | ✔️ Tak | Żaden |
Właściwość type identyfikuje typ obiektu bazy danych za jednostką, w tym view, tablei stored-procedure. Ta właściwość jest wymagana i nie ma wartości domyślnej.
Format
{
"entities": {
"<entity-name>": {
"type": <"view" | "stored-procedure" | "table">
}
}
}
Wartości
| Wartość | Opis |
|---|---|
table |
Reprezentuje tabelę. |
stored-procedure |
Reprezentuje procedurę składowaną. |
view |
Reprezentuje widok. |
Przykłady
1. Przykład tabeli:
SQL
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
Configuration
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
}
}
}
}
2. Przykład widoku:
SQL
CREATE VIEW dbo.AdminUsers AS
SELECT Id, Name, Age
FROM dbo.Users
WHERE IsAdmin = 1;
Configuration
{
"entities": {
"AdminUsers": {
"source": {
"object": "dbo.AdminUsers",
"type": "view",
"key-fields": ["Id"]
},
"mappings": {
"Id": "id",
"Name": "name",
"Age": "age"
}
}
}
}
Uwaga: Określanie key-fields jest ważne dla widoków, ponieważ brakuje im nieodłącznych kluczy podstawowych.
3. Przykład procedury składowanej:
SQL
CREATE PROCEDURE dbo.GetUsers (@IsAdmin BIT)
AS
SELECT Id, Name, Age, IsAdmin
FROM dbo.Users
WHERE IsAdmin = @IsAdmin;
Configuration
{
"entities": {
"User": {
"source": {
"type": "stored-procedure",
"object": "GetUsers",
"parameters": {
"IsAdmin": "boolean"
}
}
}
}
}
Pola klucza
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.source |
key-fields |
tablica ciągów | ❌ Nie | Żaden |
Właściwość {entity}.key-fields jest szczególnie niezbędna w przypadku jednostek wspieranych przez widoki, więc narzędzie Data API Builder wie, jak identyfikować i zwracać pojedynczy element. Jeśli type jest ustawiona na view bez określenia key-fields, silnik nie chce się uruchomić. Ta właściwość jest dozwolona w tabelach i procedurach składowanych, ale nie jest używana w tych przypadkach.
Ważny
Ta właściwość jest wymagana, jeśli typ obiektu jest view.
Format
{
"entities": {
"<entity-name>": {
"source": {
"type": <"view" | "stored-procedure" | "table">,
"key-fields": <array of strings>
}
}
}
}
Przykład: Wyświetlanie z polami klucza
W tym przykładzie użyto widoku dbo.AdminUsers z Id wskazywanymi jako pole klucza.
SQL
CREATE VIEW dbo.AdminUsers AS
SELECT Id, Name, Age
FROM dbo.Users
WHERE IsAdmin = 1;
Configuration
{
"entities": {
"AdminUsers": {
"source": {
"object": "dbo.AdminUsers",
"type": "view",
"key-fields": ["Id"]
}
}
}
}
Parametry
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.source |
parameters |
sprzeciwiać się | ❌ Nie | Żaden |
Właściwość parameters w entities.{entity}.source jest używana dla jednostek wspieranych przez procedury składowane. Zapewnia prawidłowe mapowanie nazw parametrów i typów danych wymaganych przez procedurę składowaną.
Ważny
Właściwość parameters jest wymagana, jeśli type obiektu jest stored-procedure, a parametr jest wymagany.
Format
{
"entities": {
"<entity-name>": {
"source": {
"type": "stored-procedure",
"parameters": {
"<parameter-name-1>": <string | number | boolean>,
"<parameter-name-2>": <string | number | boolean>
}
}
}
}
}
Przykład 1: Procedura składowana bez parametrów
SQL
CREATE PROCEDURE dbo.GetUsers AS
SELECT Id, Name, Age, IsAdmin FROM dbo.Users;
Configuration
{
"entities": {
"Users": {
"source": {
"object": "dbo.GetUsers",
"type": "stored-procedure"
}
}
}
}
Przykład 2: Procedura składowana z parametrami
SQL
CREATE PROCEDURE dbo.GetUser (@userId INT) AS
SELECT Id, Name, Age, IsAdmin FROM dbo.Users
WHERE Id = @userId;
Configuration
{
"entities": {
"User": {
"source": {
"object": "dbo.GetUser",
"type": "stored-procedure",
"parameters": {
"userId": "number"
}
}
}
}
}
Uprawnienia
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity} |
permissions |
sprzeciwiać się | ✔️ Tak | Żaden |
W tej sekcji zdefiniowano, kto może uzyskać dostęp do powiązanej jednostki i jakie akcje są dozwolone. Uprawnienia są definiowane pod względem ról i operacji CRUD: create, read, updatei delete. Sekcja permissions określa, które role mogą uzyskiwać dostęp do powiązanej jednostki i za pomocą których akcji.
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"actions": ["create", "read", "update", "delete", "execute", "*"]
}
]
}
}
}
| Akcja | Opis |
|---|---|
create |
Umożliwia utworzenie nowego rekordu w jednostce. |
read |
Umożliwia odczytywanie lub pobieranie rekordów z jednostki. |
update |
Umożliwia aktualizowanie istniejących rekordów w jednostce. |
delete |
Umożliwia usuwanie rekordów z jednostki. |
execute |
Umożliwia wykonywanie procedury składowanej lub operacji. |
* |
Przyznaje wszystkie odpowiednie operacje CRUD. |
Przykłady
przykład 1: rola anonimowa w jednostce użytkownika
W tym przykładzie rola anonymous jest definiowana z dostępem do wszystkich możliwych akcji w jednostce User.
{
"entities": {
"User": {
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
]
}
}
}
przykład 2: akcje mieszane dla roli anonimowej
W tym przykładzie pokazano, jak mieszać akcje ciągu i tablicy obiektów dla jednostki User.
{
"entities": {
"User": {
"permissions": [
{
"role": "anonymous",
"actions": [
{ "action": "read" },
"create"
]
}
]
}
}
}
rola anonimowa: umożliwia anonimowym użytkownikom odczytywanie wszystkich pól z wyjątkiem hipotetycznego pola poufnego (np. secret-field). Używanie "include": ["*"] z "exclude": ["secret-field"] ukrywa secret-field, zezwalając jednocześnie na dostęp do wszystkich innych pól.
uwierzytelnionej roli: umożliwia uwierzytelnieni użytkownikom odczytywanie i aktualizowanie określonych pól. Na przykład jawne dołączanie id, namei age, ale wykluczanie isAdmin może zademonstrować, w jaki sposób wykluczenia zastępują dołączania.
rola administratora: Administratorzy mogą wykonywać wszystkie operacje (*) we wszystkich polach bez wykluczeń. Określanie "include": ["*"] z pustą tablicą "exclude": [] przyznaje dostęp do wszystkich pól.
Ta konfiguracja:
"fields": {
"include": [],
"exclude": []
}
jest w rzeczywistości identyczny z:
"fields": {
"include": ["*"],
"exclude": []
}
Rozważ również tę konfigurację:
"fields": {
"include": [],
"exclude": ["*"]
}
Określa to, że żadne pola nie są jawnie uwzględniane, a wszystkie pola są wykluczane, co zwykle ogranicza dostęp całkowicie.
praktycznym zastosowaniem: Taka konfiguracja może wydawać się nieintuiktywna, ponieważ ogranicza dostęp do wszystkich pól. Można go jednak używać w scenariuszach, w których rola wykonuje pewne akcje (takie jak tworzenie jednostki) bez uzyskiwania dostępu do danych.
To samo zachowanie, ale z inną składnią, byłoby następujące:
"fields": {
"include": ["Id", "Name"],
"exclude": ["*"]
}
Ta konfiguracja próbuje uwzględnić tylko pola Id i Name, ale wyklucza wszystkie pola ze względu na symbol wieloznaczny w exclude.
Innym sposobem wyrażenia tej samej logiki jest:
"fields": {
"include": ["Id", "Name"],
"exclude": ["Id", "Name"]
}
Biorąc pod uwagę, że exclude ma pierwszeństwo przed include, określając exclude: ["*"] oznacza, że wszystkie pola są wykluczone, nawet te w include. W związku z tym na pierwszy rzut oka ta konfiguracja może uniemożliwić dostęp do wszystkich pól.
Odwrotna: jeśli celem jest przyznanie dostępu tylko do pól Id i Name, jest jaśniejszy i bardziej niezawodny, aby określić tylko te pola w sekcji include bez używania symbolu wieloznakowego wykluczania:
"fields": {
"include": ["Id", "Name"],
"exclude": []
}
Właściwości
| Wymagane | Typ | |
|---|---|---|
role |
✔️ Tak | struna |
| lub actions (tablica obiektów) |
✔️ Tak | tablica obiektów lub ciągów |
Rola
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.permissions |
role |
struna | ✔️ Tak | Żaden |
Ciąg zawierający nazwę roli, do której ma zastosowanie zdefiniowane uprawnienie. Role ustawiają kontekst uprawnień, w którym ma zostać wykonane żądanie. Dla każdej jednostki zdefiniowanej w konfiguracji środowiska uruchomieniowego można zdefiniować zestaw ról i skojarzonych uprawnień, które określają sposób uzyskiwania dostępu do jednostki za pośrednictwem punktów końcowych REST i GraphQL. Role nie są dodawane.
Narzędzie Data API Builder ocenia żądania w kontekście jednej roli:
| Rola | Opis |
|---|---|
anonymous |
Nie przedstawiono tokenu dostępu |
authenticated |
Zostanie wyświetlony prawidłowy token dostępu |
<custom-role> |
Zostanie wyświetlony prawidłowy token dostępu, a nagłówek HTTP X-MS-API-ROLE określa rolę obecną w tokenie |
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <"anonymous" | "authenticated" | "custom-role">,
"actions": ["create", "read", "update", "delete", "execute", "*"],
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
}
}
]
}
}
}
Przykłady
W tym przykładzie zdefiniowano rolę o nazwie reader z uprawnieniami tylko read w jednostce User.
{
"entities": {
"User": {
"permissions": [
{
"role": "reader",
"actions": ["read"]
}
]
}
}
}
Można użyć <custom-role>, gdy jest wyświetlany prawidłowy token dostępu i dołączany jest nagłówek HTTP X-MS-API-ROLE, określając rolę użytkownika, która jest również zawarta w oświadczeniach ról tokenu dostępu. Poniżej przedstawiono przykłady żądań GET do jednostki User, w tym token elementu nośnego autoryzacji i nagłówek X-MS-API-ROLE w bazie punktu końcowego REST /api w localhost przy użyciu różnych języków.
GET https://localhost:5001/api/User
Authorization: Bearer <your_access_token>
X-MS-API-ROLE: custom-role
Akcje (tablica ciągów)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.permissions |
actions |
oneOf [ciąg, tablica] | ✔️ Tak | Żaden |
Tablica wartości ciągów szczegółowo określa, jakie operacje są dozwolone dla skojarzonej roli. W przypadku obiektów bazy danych table i view role mogą używać dowolnej kombinacji akcji create, read, updatelub delete. W przypadku procedur składowanych role mogą mieć tylko akcję execute.
| Akcja | Operacja SQL |
|---|---|
* |
Symbol wieloznaczny, w tym wykonanie |
create |
Wstaw co najmniej jeden wiersz |
read |
Wybierz co najmniej jeden wiersz |
update |
Modyfikowanie co najmniej jednego wiersza |
delete |
Usuwanie co najmniej jednego wiersza |
execute |
Uruchamia procedurę składowaną |
Nuta
W przypadku procedur składowanych akcja wieloznaczny (*) rozszerza się tylko do akcji execute. W przypadku tabel i widoków rozszerza się na create, read, updatei delete.
Przykłady
W tym przykładzie przedstawiono uprawnienia create i read do roli o nazwie contributor i delete uprawnienia do roli o nazwie auditor w jednostce User.
{
"entities": {
"User": {
"permissions": [
{
"role": "auditor",
"actions": ["delete"]
},
{
"role": "contributor",
"actions": ["read", "create"]
}
]
}
}
}
Inny przykład:
{
"entities": {
"User": {
"permissions": [
{
"role": "contributor",
"actions": ["read", "create"]
}
]
}
}
}
Akcje (tablica-obiekt)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.permissions |
actions |
tablica ciągów | ✔️ Tak | Żaden |
Tablica obiektów akcji szczegółowo opisujących dozwolone operacje dla skojarzonej roli. W przypadku obiektów table i view role mogą używać dowolnej kombinacji create, read, updatelub delete. W przypadku procedur składowanych dozwolone są tylko execute.
Nuta
W przypadku procedur składowanych akcja wieloznaczny (*) rozszerza się tylko na execute. W przypadku tabel/widoków rozszerza się na create, read, updatei delete.
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <string>,
"actions": [
{
"action": <string>,
"fields": <array of strings>,
"policy": <object>
}
]
}
]
}
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
action |
✔️ Tak | struna | Żaden |
fields |
❌ Nie | tablica ciągów | Żaden |
policy |
❌ Nie | sprzeciwiać się | Żaden |
Przykład
W tym przykładzie udzielono tylko read uprawnień do roli auditor w jednostce User z ograniczeniami pól i zasad.
{
"entities": {
"User": {
"permissions": [
{
"role": "auditor",
"actions": [
{
"action": "read",
"fields": {
"include": ["*"],
"exclude": ["last_login"]
},
"policy": {
"database": "@item.IsAdmin eq false"
}
}
]
}
]
}
}
}
Akcja
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.permissions.actions[] |
action |
struna | ✔️ Tak | Żaden |
Określa określoną operację dozwoloną w obiekcie bazy danych.
Wartości
| Tabel | Widoki | Procedury składowane | Opis | |
|---|---|---|---|---|
create |
✔️ Tak | ✔️ Tak | ❌ Nie | Tworzenie nowych elementów |
read |
✔️ Tak | ✔️ Tak | ❌ Nie | Odczytywanie istniejących elementów |
update |
✔️ Tak | ✔️ Tak | ❌ Nie | Aktualizowanie lub zastępowanie elementów |
delete |
✔️ Tak | ✔️ Tak | ❌ Nie | Usuń elementy |
execute |
❌ Nie | ❌ Nie | ✔️ Tak | Wykonywanie operacji programistycznych |
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": "<role>",
"actions": [
{
"action": "<string>",
"fields": {
"include": [/* fields */],
"exclude": [/* fields */]
},
"policy": {
"database": "<predicate>"
}
}
]
}
]
}
}
}
Przykład
Oto przykład, w którym użytkownicy anonymous mogą execute procedurę składowaną i read z tabeli User.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
},
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read"
}
]
}
]
},
"GetUser": {
"source": {
"object": "dbo.GetUser",
"type": "stored-procedure",
"parameters": {
"userId": "number"
}
},
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "execute"
}
]
}
]
}
}
}
Pola
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.permissions.actions[] |
fields |
sprzeciwiać się | ❌ Nie | Żaden |
Szczegółowe specyfikacje, dla których określone pola mają dozwolony dostęp do obiektu bazy danych. Obiekt fields zawiera dwie właściwości, include i exclude, aby zdefiniować, które kolumny bazy danych są dozwolone lub ograniczone dla danej akcji.
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": "<role>",
"actions": [
{
"action": "<string>",
"fields": {
"include": [/* array of strings */],
"exclude": [/* array of strings */]
},
"policy": { /* object */ }
}
]
}
]
}
}
}
Przykłady
SQL
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
Configuration
Ta konfiguracja umożliwia roli anonymous odczytywanie wszystkich pól z jednostki User z wyjątkiem IsAdmin, przy jednoczesnym umożliwieniu tworzenia nowych rekordów User.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
},
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read",
"fields": {
"include": ["*"],
"exclude": ["IsAdmin"]
}
},
{
"action": "create"
}
]
}
]
}
}
}
Polityka
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.permissions.actions[] |
policy |
sprzeciwiać się | ❌ Nie | Żaden |
Sekcja policy zdefiniowana dla akcji ustawia reguły zabezpieczeń na poziomie elementu, które ograniczają wyniki zwracane z żądania. Podsekcja database określa wyrażenie podobne do danych OData oceniane podczas wykonywania zapytania, które konstruktor interfejsu API danych tłumaczy na predykat zapytania.
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": "<role>",
"actions": [
{
"action": "<string>",
"policy": {
"database": "<predicate>"
}
}
]
}
]
}
}
}
Przykład podstawowy
Ten przykład ogranicza akcję read dla roli adultReader, tak aby zwracano tylko użytkowników starszych niż 18:
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
},
"permissions": [
{
"role": "adultReader",
"actions": [
{
"action": "read",
"policy": {
"database": "@item.Age gt 18"
}
}
]
}
]
}
}
}
Baza danych
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.permissions[].actions[].policy |
database |
struna | ✔️ Tak | Żaden |
Opis
Właściwość database w ramach zasad definiuje wyrażenie podobne do danych OData, które konstruktor interfejsu API danych tłumaczy na predykat SQL w celu filtrowania wyników podczas wykonywania zapytania. To wyrażenie musi mieć wartość true, aby zwracać wiersze. Na przykład:
-
@item.Age gt 18może przełożyć się naWHERE Users.Age > 18. -
@claims.userId eq @item.Idogranicza wyniki do wierszy, w których identyfikator użytkownika z oświadczeń jest zgodny z polemId.
Dyrektyw
-
@claims: uzyskaj dostęp do oświadczenia ze zweryfikowanego tokenu dostępu. -
@item: reprezentuje pole jednostki, dla której zdefiniowano zasady.
Nuta
W przypadku korzystania z uwierzytelniania usługi Azure Static Web Apps (EasyAuth) dostępne są tylko niektóre typy oświadczeń (identityProvider, userId, userDetails, userRoles).
Obsługiwane operatory podobne do OData
Wyrażenie obsługuje operatory, takie jak:
-
logiczne:
and,or,not -
porównanie:
eq,gt,lt -
jednoargumentową negację liczbową:
-
Na przykład "@item.Age gt 18 and @item.Age lt 65" ogranicza wyniki użytkownikom w wieku od 19 do 64 lat.
Ograniczenia nazwy pola jednostki
Pola muszą zaczynać się od litery lub podkreślenia (_), a następnie maksymalnie 127 liter, podkreśleń lub cyfr. Pola, które nie są przestrzegane tych reguł, nie mogą być używane bezpośrednio w zasadach. Użyj sekcji mappings, aby aliasować nazwy pól niezgodnych z odwołaniami do zasad.
Wykorzystanie mappings dla pól niekonformujących
Jeśli nazwy pól jednostki nie spełniają konwencji nazewnictwa OData, zdefiniuj aliasy w sekcji mappings:
{
"entities": {
"<entity-name>": {
"mappings": {
"<original-field-name>": "<alias>",
"...": "..."
}
}
}
}
Spowoduje to utworzenie zgodnych aliasów do użycia w zasadach i zwiększenie przejrzystości w punktach końcowych.
Ograniczenia
- Zasady dotyczą tylko tabel i widoków; procedury składowane nie mogą ich używać.
- Zasady filtrują wyniki, ale nie uniemożliwiają wykonywania zapytań w bazie danych.
- Obsługiwane tylko w przypadku akcji:
create,read,updateidelete. - Nazwy pól muszą być zgodne z konwencjami nazewnictwa OData. W razie potrzeby użyj mapowań do pól aliasu.
Przykłady
Rozważ jednostkę o nazwie User w ramach konfiguracji interfejsu API danych, która używa zasad w celu ograniczenia dostępu na podstawie wieku i tożsamości użytkownika.
SQL
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
Przykład 1: Age-Based Access
Ta konfiguracja ogranicza rolę adultReader, tak aby akcja read zwracała tylko użytkowników, którzy Age > 18.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
},
"permissions": [
{
"role": "adultReader",
"actions": [
{
"action": "read",
"policy": {
"database": "@item.Age gt 18"
}
}
]
}
]
}
}
}
przykład 2: dostępu opartego na oświadczeniach
Ta konfiguracja używa oświadczenia, aby ograniczyć rolę selfReader, aby użytkownicy mogli odczytywać własne rekordy tylko wtedy, gdy oświadczenia userId są zgodne z polem Id.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
},
"permissions": [
{
"role": "selfReader",
"actions": [
{
"action": "read",
"policy": {
"database": "@claims.userId eq @item.Id"
}
}
]
}
]
}
}
}
GraphQL (jednostki)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity} |
graphql |
sprzeciwiać się | ❌ Nie | Żaden |
Ten obiekt definiuje zachowanie graphQL jednostki.
Format
{
"entities": {
"<entity-name>": {
"graphql": {
"enabled": <true> (default) | <false>,
"type": {
"singular": <string>,
"plural": <string>
},
"operation": "query" (default) | "mutation"
}
}
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
enabled |
❌ Nie | boolowski | Żaden |
type |
❌ Nie | ciąg lub obiekt | Żaden |
operation |
❌ Nie | ciąg wyliczenia | Żaden |
Przykłady
Te dwa przykłady są funkcjonalnie równoważne, włączając język GraphQL dla jednostki User z ustawieniami domyślnymi:
{
"entities": {
"User": {
"graphql": {
"enabled": true
}
}
}
}
W tym przykładzie zdefiniowana jednostka jest User, co wskazuje, że mamy do czynienia z danymi użytkownika. Konfiguracja jednostki User w segmencie GraphQL określa sposób jej reprezentowania i interakcji ze schematem GraphQL.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
},
"graphql": {
"enabled": true,
"type": {
"singular": "User",
"plural": "Users"
},
"operation": "query"
}
}
}
}
Typ (jednostka GraphQL)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.graphql |
type |
sprzeciwiać się | ❌ Nie | {nazwa jednostki} |
Ta właściwość określa konwencję nazewnictwa jednostki w schemacie GraphQL. Określa liczbę pojedynczą i mnogą, zapewniając szczegółową kontrolę nad czytelnością schematu i środowiskiem użytkownika.
Format
{
"entities": {
"<entity-name>": {
"graphql": {
"type": {
"singular": "<string>",
"plural": "<string>"
}
}
}
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
singular |
❌ Nie | struna | Żaden |
plural |
❌ Nie | struna | N/A (domyślnie wartość pojedyncza) |
Przykłady
Jeśli brakuje plural lub pominięto (na przykład wartości skalarnej), narzędzie Data API Builder podejmie próbę liczenia nazwy automatycznie przy użyciu angielskich reguł dla liczby mnogiej.
jawne nazwy pojedyncze i mnogie:
{
"entities": {
"User": {
"graphql": {
"type": {
"singular": "User",
"plural": "Users"
}
}
}
}
}
przykład zapytania GraphQL:
{
Users {
items {
id
name
age
isAdmin
}
}
}
przykładowa odpowiedź JSON:
{
"data": {
"Users": {
"items": [
{
"id": 1,
"name": "Alice",
"age": 30,
"isAdmin": true
},
{
"id": 2,
"name": "Bob",
"age": 25,
"isAdmin": false
}
// ...
]
}
}
}
Operacja (jednostka GraphQL)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.graphql |
operation |
ciąg wyliczenia | ❌ Nie | mutacja |
W przypadku jednostek zamapowanych na procedury składowane właściwość operation określa, czy operacja GraphQL jest wyświetlana w Query lub Mutation typie. To ustawienie organizuje schemat logicznie bez wpływu na funkcjonalność.
Nuta
Po ustawieniu {entity}.type na stored-procedurezostanie automatycznie utworzony nowy typ graphQL executeXXX. Właściwość operation określa, czy ten typ jest umieszczany w Query, czy Mutation. Nie ma wpływu funkcjonalnego na podstawie wybranej wartości.
Format
{
"entities": {
"<entity-name>": {
"graphql": {
"operation": "query" | "mutation"
}
}
}
}
Wartości
| Wartość | Opis |
|---|---|
query |
Procedura składowana jest uwidoczniona jako zapytanie |
mutation |
Procedura składowana jest uwidoczniona jako mutacja |
Przykłady
Configuration
{
"entities": {
"UserProcedure": {
"graphql": {
"operation": "query" // schema location
},
"source": {
"object": "dbo.GetUser",
"type": "stored-procedure",
"parameters": {
"userId": "number"
}
}
}
}
}
wynik schematu GraphQL
Jeśli operation jest ustawiona na query, schemat GraphQL umieszcza procedurę w Query typ:
type Query {
executeGetUserDetails(userId: Int!): GetUserDetailsResponse
}
Jeśli ustawiono wartość mutation, zostanie wyświetlona w obszarze typu Mutation:
type Mutation {
executeGetUserDetails(userId: Int!): GetUserDetailsResponse
}
Nuta
Właściwość operation ma wpływ tylko na umieszczenie operacji GraphQL w schemacie; nie zmienia zachowania operacji.
Włączone (jednostka GraphQL)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.graphql |
enabled |
boolowski | ❌ Nie | Prawdziwy |
Włącza lub wyłącza punkt końcowy GraphQL. Określa, czy jednostka jest dostępna za pośrednictwem punktów końcowych GraphQL. Przełączanie właściwości enabled umożliwia deweloperom selektywne uwidacznianie jednostek ze schematu GraphQL.
Format
{
"entities": {
"<entity-name>": {
"graphql": {
"enabled": <true> (default) | <false>
}
}
}
}
REST (jednostki)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity} |
rest |
sprzeciwiać się | ❌ Nie | Żaden |
Sekcja rest pliku konfiguracji jest przeznaczona do dostrajania punktów końcowych RESTful dla każdej jednostki bazy danych. Ta możliwość dostosowywania zapewnia, że uwidoczniony interfejs API REST spełnia określone wymagania, poprawiając możliwości zarówno narzędzia, jak i integracji. Rozwiązuje ona potencjalne niezgodności między domyślnymi ustawieniami wywnioskowanym i żądanymi zachowaniami punktu końcowego.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"enabled": <true> (default) | <false>,
"path": <string; default: "<entity-name>">,
"methods": <array of strings; default: ["GET", "POST"]>
}
}
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
enabled |
✔️ Tak | boolowski | Prawdziwy |
path |
❌ Nie | struna | /<entity-name> |
methods |
❌ Nie | tablica ciągów | POBIERZ |
Przykłady
Te dwa przykłady są funkcjonalnie równoważne.
{
"entities": {
"Author": {
"source": {
"object": "dbo.authors",
"type": "table"
},
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
],
"rest": true
}
}
}
{
"entities": {
"Author": {
...
"rest": {
"enabled": true
}
}
}
}
Oto kolejny przykład konfiguracji REST dla jednostki.
{
"entities" {
"User": {
"rest": {
"enabled": true,
"path": "/User"
},
...
}
}
}
Włączone (jednostka REST)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.rest |
enabled |
boolowski | ❌ Nie | Prawdziwy |
Ta właściwość działa jako przełącznik widoczności jednostek w interfejsie API REST. Ustawiając właściwość enabled na true lub false, deweloperzy mogą kontrolować dostęp do określonych jednostek, włączając dostosowany powierzchnię interfejsu API zgodną z wymaganiami dotyczącymi zabezpieczeń i funkcjonalności aplikacji.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"enabled": <true> (default) | <false>
}
}
}
}
Ścieżka (jednostka REST)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.rest |
path |
struna | ❌ Nie | Żaden |
Właściwość path określa segment identyfikatora URI używany do uzyskiwania dostępu do jednostki za pośrednictwem interfejsu API REST. To dostosowanie umożliwia bardziej opisowe lub uproszczone ścieżki punktów końcowych poza domyślną nazwą jednostki, zwiększenie możliwości nawigacji interfejsu API i integracji po stronie klienta. Domyślnie ścieżka to /<entity-name>.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"path": <string; default: "<entity-name>">
}
}
}
}
Przykłady
Ten przykład uwidacznia jednostkę Author przy użyciu punktu końcowego /auth.
{
"entities": {
"Author": {
"rest": {
"path": "/auth"
}
}
}
}
Metody (jednostka REST)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.rest |
methods |
tablica ciągów | ❌ Nie | Żaden |
Dotyczy to zwłaszcza procedur składowanych, właściwość methods określa czasowniki HTTP (na przykład GET, POST), na które procedura może odpowiedzieć. Metody umożliwiają precyzyjną kontrolę nad sposobem uwidaczniania procedur składowanych za pośrednictwem interfejsu API REST, zapewniając zgodność ze standardami RESTful i oczekiwaniami klientów. Ta sekcja podkreśla zaangażowanie platformy w elastyczność i kontrolę deweloperów, umożliwiając precyzyjne i intuicyjne projektowanie interfejsu API dostosowane do konkretnych potrzeb każdej aplikacji.
W przypadku pominięcia lub braku wartości domyślnej methods jest POST.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"methods": ["GET" (default), "POST"]
}
}
}
}
Wartości
Oto lista dozwolonych wartości dla tej właściwości:
| Opis | |
|---|---|
get |
Uwidacznia żądania HTTP GET |
post |
Uwidacznia żądania HTTP POST |
Przykłady
W tym przykładzie aparat instruuje, że stp_get_bestselling_authors procedura składowana obsługuje tylko akcje HTTP GET.
{
"entities": {
"BestSellingAuthor": {
"source": {
"object": "dbo.stp_get_bestselling_authors",
"type": "stored-procedure",
"parameters": {
"depth": "number"
}
},
"rest": {
"path": "/best-selling-authors",
"methods": [ "get" ]
}
}
}
}
Mapowania (jednostki)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity} |
mappings |
sprzeciwiać się | ❌ Nie | Żaden |
sekcja mappings umożliwia konfigurowanie aliasów lub uwidocznionych nazw dla pól obiektów bazy danych. Skonfigurowane uwidocznione nazwy mają zastosowanie zarówno do punktów końcowych GraphQL, jak i REST.
Ważny
W przypadku jednostek z włączonym językiem GraphQL skonfigurowana nazwa uwidoczniona musi spełniać wymagania dotyczące nazewnictwa graphQL. Aby uzyskać więcej informacji, zobacz Specyfikacja nazw GraphQL.
Format
{
"entities": {
"<entity-name>": {
"mappings": {
"<field-1-name>": "<field-1-alias>",
"<field-2-name>": "<field-2-alias>",
"<field-3-name>": "<field-3-alias>"
}
}
}
}
Przykłady
W tym przykładzie pole sku_title z obiektu bazy danych dbo.magazines jest uwidocznione przy użyciu nazwy title. Podobnie pole sku_status jest widoczne jako status w punktach końcowych REST i GraphQL.
{
"entities": {
"Magazine": {
...
"mappings": {
"sku_title": "title",
"sku_status": "status"
}
}
}
}
Oto kolejny przykład mapowań.
{
"entities": {
"Book": {
...
"mappings": {
"id": "BookID",
"title": "BookTitle",
"author": "AuthorName"
}
}
}
}
Mapowania: obiekt mappings łączy pola bazy danych (BookID, BookTitle, AuthorName) z bardziej intuicyjnymi lub ustandaryzowanymi nazwami (id, title, author) używanymi zewnętrznie. Ten alias służy do kilku celów:
Clarity and Consistency: umożliwia korzystanie z jasnego i spójnego nazewnictwa w interfejsie API, niezależnie od bazowego schematu bazy danych. Na przykład
BookIDw bazie danych jest reprezentowana jakoidw interfejsie API, dzięki czemu jest bardziej intuicyjna dla deweloperów korzystających z punktu końcowego.graphQL Compliance: Udostępniając mechanizm nazw pól aliasów, zapewnia, że nazwy uwidocznione za pośrednictwem interfejsu GraphQL są zgodne z wymaganiami dotyczącymi nazewnictwa GraphQL. Zwracanie uwagi na nazwy jest ważne, ponieważ język GraphQL ma ścisłe reguły dotyczące nazw (na przykład brak spacji, musi zaczynać się od litery lub podkreślenia itp.). Jeśli na przykład nazwa pola bazy danych nie spełnia tych kryteriów, może być aliasem dla zgodnej nazwy za pomocą mapowań.
elastyczność: ten alias dodaje warstwę abstrakcji między schematem bazy danych a interfejsem API, umożliwiając wprowadzanie zmian w jednym bez konieczności wprowadzania zmian w drugim. Na przykład zmiana nazwy pola w bazie danych nie wymaga aktualizacji dokumentacji interfejsu API ani kodu po stronie klienta, jeśli mapowanie pozostaje spójne.
zaciemnianie nazwy pola: mapowanie umożliwia zaciemnianie nazw pól, co może pomóc uniemożliwić nieautoryzowanym użytkownikom wnioskowanie poufnych informacji o schemacie bazy danych lub charakter przechowywanych danych.
Ochrona zastrzeżonych informacji: zmieniając nazwy pól, można również chronić zastrzeżone nazwy lub logikę biznesową, które mogą być sugerowane za pomocą oryginalnych nazw pól bazy danych.
Relacje (jednostki)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity} |
relationships |
sprzeciwiać się | ❌ Nie | Żaden |
Ta sekcja zawiera zestaw definicji relacji, które mapują sposób, w jaki jednostki są powiązane z innymi uwidocznionych jednostkami. Te definicje relacji mogą również opcjonalnie zawierać szczegóły dotyczące bazowych obiektów bazy danych używanych do obsługi i wymuszania relacji. Obiekty zdefiniowane w tej sekcji są widoczne jako pola GraphQL w powiązanej jednostce. Aby uzyskać więcej informacji, zobacz Podział relacji konstruktora interfejsu API danych.
Nuta
Relacje są istotne tylko dla zapytań GraphQL. Punkty końcowe REST uzyskują dostęp tylko do jednej jednostki jednocześnie i nie mogą zwracać typów zagnieżdżonych.
W sekcji relationships opisano, w jaki sposób jednostki wchodzą w interakcje w konstruktorze interfejsu API danych, szczegółowo opisując skojarzenia i potencjalną obsługę baz danych dla tych relacji. Właściwość relationship-name dla każdej relacji jest wymagana i musi być unikatowa we wszystkich relacjach dla danej jednostki. Nazwy niestandardowe zapewniają jasne, możliwe do zidentyfikowania połączenia i zachowają integralność schematu GraphQL wygenerowanego na podstawie tych konfiguracji.
| Związek | Moc | Przykład |
|---|---|---|
| jeden do wielu | many |
Jedna jednostka kategorii może odnosić się do wielu jednostek zadań do wykonania |
| wiele do jednego | one |
Wiele jednostek zadań do wykonania może odnosić się do jednej jednostki kategorii |
| wiele do wielu | many |
Jedna jednostka zadań do wykonania może odnosić się do wielu jednostek użytkowników, a jedna jednostka użytkownika może odnosić się do wielu jednostek zadań do wykonania |
Format
{
"entities": {
"<entity-name>": {
"relationships": {
"<relationship-name>": {
"cardinality": "one" | "many",
"target.entity": "<string>",
"source.fields": ["<string>"],
"target.fields": ["<string>"],
"linking.object": "<string>",
"linking.source.fields": ["<string>"],
"linking.target.fields": ["<string>"]
}
}
}
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
cardinality |
✔️ Tak | ciąg wyliczenia | Żaden |
target.entity |
✔️ Tak | struna | Żaden |
source.fields |
❌ Nie | tablica ciągów | Żaden |
target.fields |
❌ Nie | tablica ciągów | Żaden |
linking.<object-or-entity> |
❌ Nie | struna | Żaden |
linking.source.fields |
❌ Nie | tablica ciągów | Żaden |
linking.target.fields |
❌ Nie | tablica ciągów | Żaden |
Przykłady
Biorąc pod uwagę relacje, najlepiej porównać różnice między jeden do wielu, wiele do jednegoi relacje wiele do wielu.
Jeden do wielu
Najpierw rozważmy przykład relacji z jednostką uwidocznionego Category, która ma relację jeden do wielu z jednostką Book. W tym miejscu kardynalność jest ustawiona na wartość many. Każda Category może mieć wiele powiązanych jednostek Book, podczas gdy każda jednostka Book jest skojarzona tylko z jedną jednostką Category.
{
"entities": {
"Book": {
...
},
"Category": {
"relationships": {
"category_books": {
"cardinality": "many",
"target.entity": "Book",
"source.fields": [ "id" ],
"target.fields": [ "category_id" ]
}
}
}
}
}
W tym przykładzie lista source.fields określa pole id jednostki źródłowej (Category). To pole służy do nawiązywania połączenia z powiązanym elementem w jednostce target. Z drugiej strony lista target.fields określa pole category_id jednostki docelowej (Book). To pole służy do nawiązywania połączenia z powiązanym elementem w jednostce source.
Po zdefiniowaniu tej relacji wynikowy uwidoczniony schemat GraphQL powinien przypominać ten przykład.
type Category
{
id: Int!
...
books: [BookConnection]!
}
Wiele do jednego
Następnie rozważ wiele do jednego, która ustawia kardynalność na one. Uwidoczniona jednostka Book może mieć pojedynczą powiązaną jednostkę Category. Jednostka Category może mieć wiele powiązanych jednostek Book.
{
"entities": {
"Book": {
"relationships": {
"books_category": {
"cardinality": "one",
"target.entity": "Category",
"source.fields": [ "category_id" ],
"target.fields": [ "id" ]
}
},
"Category": {
...
}
}
}
}
W tym miejscu lista source.fields określa, że pole category_id jednostki źródłowej (Book) odwołuje się do pola id powiązanej jednostki docelowej (Category). Odwrotnie lista target.fields określa odwrotną relację. W przypadku tej relacji wynikowy schemat GraphQL zawiera teraz mapowanie z powrotem z książek do kategorii.
type Book
{
id: Int!
...
category: Category
}
Wiele do wielu
Na koniec zdefiniowano relację wiele-do-wielu z kardynalnością many i większą liczbą metadanych w celu zdefiniowania obiektów bazy danych używanych do tworzenia relacji w bazie danych zaplecza. W tym miejscu jednostka Book może mieć wiele jednostek Author i z drugiej strony jednostka Author może mieć wiele jednostek Book.
{
"entities": {
"Book": {
"relationships": {
...,
"books_authors": {
"cardinality": "many",
"target.entity": "Author",
"source.fields": [ "id" ],
"target.fields": [ "id" ],
"linking.object": "dbo.books_authors",
"linking.source.fields": [ "book_id" ],
"linking.target.fields": [ "author_id" ]
}
},
"Category": {
...
},
"Author": {
...
}
}
}
}
W tym przykładzie source.fields i target.fields wskazują, że tabela relacji używa identyfikatora podstawowego (id) zarówno źródłowego (Book) jak i docelowego (Author). Pole linking.object określa, że relacja jest zdefiniowana w obiekcie bazy danych dbo.books_authors. Ponadto linking.source.fields określa, że pole book_id obiektu łączącego odwołuje się do pola id jednostki Book i linking.target.fields określa, że pole author_id obiektu łączącego odwołuje się do pola id jednostki Author.
Ten przykład można opisać przy użyciu schematu GraphQL podobnego do tego przykładu.
type Book
{
id: Int!
...
authors: [AuthorConnection]!
}
type Author
{
id: Int!
...
books: [BookConnection]!
}
Moc
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.relationships |
cardinality |
struna | ✔️ Tak | Żaden |
Określa, czy bieżąca jednostka źródłowa jest powiązana tylko z pojedynczym wystąpieniem jednostki docelowej lub wieloma.
Wartości
Oto lista dozwolonych wartości dla tej właściwości:
| Opis | |
|---|---|
one |
Źródło odnosi się tylko do jednego rekordu z obiektu docelowego |
many |
Źródło może odnosić się do rekordów zero-do-wielu z obiektu docelowego |
Jednostka docelowa
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.relationships |
target.entity |
struna | ✔️ Tak | Żaden |
Nazwa jednostki zdefiniowanej gdzie indziej w konfiguracji, która jest celem relacji.
Pola źródłowe
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.relationships |
source.fields |
tablica | ❌ Nie | Żaden |
Opcjonalny parametr służący do definiowania pola używanego do mapowania w jednostce źródłowej
Napiwek
To pole nie jest wymagane, jeśli istnieje klucza obcego powściągliwości w bazie danych między dwoma obiektami bazy danych, których można użyć do automatycznego wnioskowania relacji.
Pola docelowe
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.relationships |
target.fields |
tablica | ❌ Nie | Żaden |
Opcjonalny parametr służący do definiowania pola używanego do mapowania w jednostce docelowej
Napiwek
To pole nie jest wymagane, jeśli istnieje klucza obcego powściągliwości w bazie danych między dwoma obiektami bazy danych, których można użyć do automatycznego wnioskowania relacji.
Łączenie obiektu lub jednostki
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.relationships |
linking.object |
struna | ❌ Nie | Żaden |
W przypadku relacji wiele-do-wielu nazwa obiektu bazy danych lub jednostki zawierającej dane niezbędne do zdefiniowania relacji między dwiema innymi jednostkami.
Łączenie pól źródłowych
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.relationships |
linking.source.fields |
tablica | ❌ Nie | Żaden |
Nazwa obiektu bazy danych lub pola jednostki powiązanego z jednostką źródłową.
Łączenie pól docelowych
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.relationships |
linking.target.fields |
tablica | ❌ Nie | Żaden |
Nazwa obiektu bazy danych lub pola jednostki powiązanego z jednostką docelową.
Pamięć podręczna (jednostki)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.cache |
enabled |
boolowski | ❌ Nie | Fałszywy |
Włącza i konfiguruje buforowanie dla jednostki.
Format
{
"entities": {
"<entity-name>": {
"cache": {
"enabled": <true> (default) | <false>,
"ttl-seconds": <integer; default: 5>
}
}
}
}
Właściwości
| Własność | Wymagane | Typ | Domyślny |
|---|---|---|---|
enabled |
❌ Nie | boolowski | Fałszywy |
ttl-seconds |
❌ Nie | liczba całkowita | 5 |
Przykłady
W tym przykładzie pamięć podręczna jest włączona, a elementy wygasają po 30 sekundach.
{
"entities": {
"Author": {
"cache": {
"enabled": true,
"ttl-seconds": 30
}
}
}
}
Włączone (jednostka pamięci podręcznej)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.{entity}.cache |
enabled |
boolowski | ❌ Nie | Fałszywy |
Włącza buforowanie dla jednostki.
Obsługa obiektów bazy danych
| Typ obiektu | Obsługa pamięci podręcznej |
|---|---|
| Stół | ✅ Tak |
| Widok | ✅ Tak |
| Procedura składowana | ✖️ Nie |
| Kontener | ✖️ Nie |
Obsługa nagłówka HTTP
| Nagłówek żądania | Obsługa pamięci podręcznej |
|---|---|
no-cache |
✖️ Nie |
no-store |
✖️ Nie |
max-age |
✖️ Nie |
public |
✖️ Nie |
private |
✖️ Nie |
etag |
✖️ Nie |
Format
{
"entities": {
"<entity-name>": {
"cache": {
"enabled": <boolean> (default: false)
}
}
}
}
Przykłady
W tym przykładzie pamięć podręczna jest wyłączona.
{
"entities": {
"Author": {
"cache": {
"enabled": false
}
}
}
}
Czas wygaśnięcia w sekundach (jednostka pamięci podręcznej)
| Rodzic | Własność | Typ | Wymagane | Domyślny |
|---|---|---|---|---|
entities.cache |
ttl-seconds |
liczba całkowita | ❌ Nie | 5 |
Konfiguruje wartość czasu wygaśnięcia (TTL) w sekundach dla buforowanych elementów. Po upływie tego czasu elementy są automatycznie czyszczone z pamięci podręcznej. Wartość domyślna to 5 sekund.
Format
{
"entities": {
"<entity-name>": {
"cache": {
"ttl-seconds": <integer; inherited>
}
}
}
}
Przykłady
W tym przykładzie pamięć podręczna jest włączona, a elementy wygasają po 15 sekundach. Po pominięciu to ustawienie dziedziczy ustawienie globalne lub domyślne.
{
"entities": {
"Author": {
"cache": {
"enabled": true,
"ttl-seconds": 15
}
}
}
}
Powiązana zawartość
- dokumentacja usługi Functions
- dokumentacja interfejsu wiersza polecenia (CLI)