Modelowanie aplikacji analitycznych w czasie rzeczywistym w usłudze Azure Cosmos DB for PostgreSQL
DOTYCZY: ![]() Usługa Azure Cosmos DB for PostgreSQL (obsługiwana przez rozszerzenie bazy danych Citus do bazy danych PostgreSQL)
Usługa Azure Cosmos DB for PostgreSQL (obsługiwana przez rozszerzenie bazy danych Citus do bazy danych PostgreSQL)
Kolokuj duże tabele z kluczem fragmentu
Aby wybrać klucz fragmentu dla aplikacji analizy operacyjnej w czasie rzeczywistym, postępuj zgodnie z następującymi wytycznymi:
- Wybierz kolumnę wspólną dla dużych tabel
- Wybierz kolumnę, która jest naturalnym wymiarem danych lub centralnym elementem aplikacji. Kilka przykładów:
- W świecie finansowym aplikacja, która analizuje trendy zabezpieczeń, prawdopodobnie będzie używać .
security_id - W obciążeniu analizy użytkowników, w którym chcesz analizować metryki użycia witryny internetowej,
user_idbyłaby to dobra kolumna dystrybucji
- W świecie finansowym aplikacja, która analizuje trendy zabezpieczeń, prawdopodobnie będzie używać .
Kolokując duże tabele, można równolegle wypychać zapytania SQL do węzłów roboczych. Wypychanie zapytań pozwala uniknąć mieszania danych między węzłami za pośrednictwem sieci. Operacje, takie jak JOIN, agregacje, zestawienia, filtry, LIMITs można efektywnie wykonywać.
Aby wizualizować równoległe zapytania rozproszone w tabelach kolokowanych, rozważmy następujący diagram:
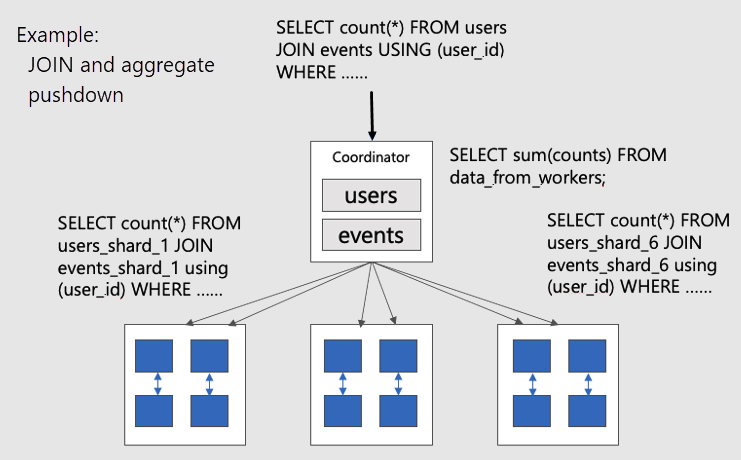
Tabele users i events są podzielone na fragmenty według user_idelementu , więc powiązane wiersze dla tego samego identyfikatora użytkownika są umieszczane razem w tym samym węźle roboczym. Sieci JOIN SQL mogą wystąpić bez ściągania informacji między procesami roboczymi.
Optymalny model danych dla aplikacji w czasie rzeczywistym
Kontynuujmy pracę z przykładem aplikacji, która analizuje wizyty i metryki witryny internetowej użytkownika. Istnieją dwie tabele "faktów" — użytkownicy i zdarzenia — i inne mniejsze tabele "wymiarów".
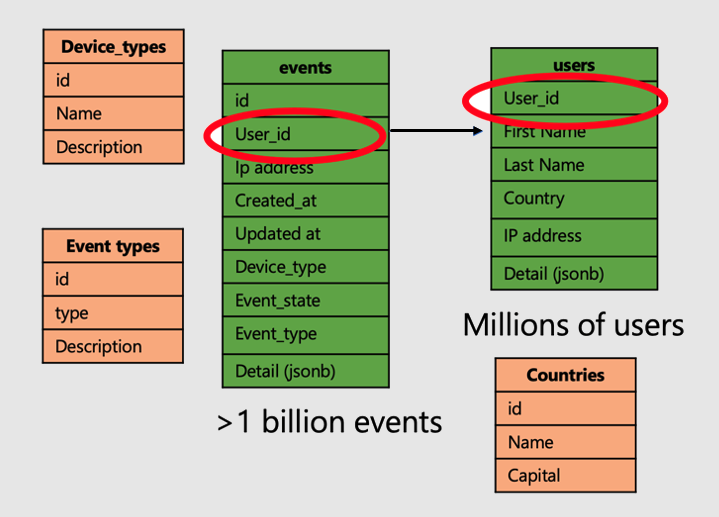
Aby zastosować super moc tabel rozproszonych w usłudze Azure Cosmos DB for PostgreSQL, wykonaj następujące kroki:
- Dystrybuuj duże tabele faktów w wspólnej kolumnie. W naszym przypadku użytkownicy i zdarzenia są dystrybuowane w systemie
user_id. - Oznacz tabele małych/wymiarów (
device_types,countriesi "event_types) jako tabele referencyjne. - Pamiętaj, aby uwzględnić kolumnę dystrybucji w podstawowych, unikatowych i obcych ograniczeniach dotyczących tabel rozproszonych. Dołączenie kolumny może wymagać wprowadzania kluczy złożonych. Należy zaktualizować klucze dla tabel referencyjnych.
- Podczas dołączania dużych tabel rozproszonych pamiętaj o połączeniu przy użyciu klucza fragmentu.
-- Distribute the fact tables
SELECT create_distributed_table('users', 'user_id');
SELECT create_distributed_table('products', 'user_id', colocate_with => 'users');
-- Turn dimension tables into reference tables, with synchronized copies
-- maintained on every worker node
SELECT create_reference_table('countries');
-- similarly for device_types and event_types...
Następne kroki
Teraz zakończyliśmy eksplorowanie modelowania danych dla skalowalnych aplikacji. Następnym krokiem jest nawiązanie połączenia z bazą danych i wykonywanie zapytań względem bazy danych przy użyciu wybranego języka programowania.