Ponowne pobieranie rozszerzonej generacji (RAG) z opartą na rdzeniach wirtualnych usługą Azure Cosmos DB dla bazy danych MongoDB
W szybko zmieniającym się obszarze generowania sztucznej inteligencji duże modele językowe (LLM), takie jak GPT-3.5, przekształciły przetwarzanie języka naturalnego. Jednak pojawiający się trend w sztucznej inteligencji to użycie magazynów wektorowych, które odgrywają kluczową rolę w ulepszaniu aplikacji sztucznej inteligencji.
W tym samouczku opisano, jak używać usługi Azure Cosmos DB dla bazy danych MongoDB (rdzeni wirtualnych), biblioteki LangChain i interfejsu OpenAI w celu zaimplementowania generacji rozszerzonej (RAG) pobierania w celu uzyskania najwyższej wydajności sztucznej inteligencji wraz z omówieniem funkcji LLM i ich ograniczeń. Zapoznamy się z szybko przyjętym paradygmatem "generowania rozszerzonego pobierania" (RAG) i krótko omawiamy platformę LangChain, modele Azure OpenAI. Na koniec integrujemy te pojęcia z rzeczywistą aplikacją. Na koniec czytelnicy będą mieli solidne zrozumienie tych pojęć.
Omówienie dużych modeli językowych (LLM) i ich ograniczeń
Duże modele językowe (LLM) to zaawansowane głębokie modele sieci neuronowych przeszkolone na obszernych zestawach danych tekstowych, co umożliwia im zrozumienie i generowanie tekstu przypominającego człowieka. Chociaż rewolucyjne w przetwarzaniu języka naturalnego, LLMs mają nieodłączne ograniczenia:
- Halucynacje: LLMs czasami generują faktycznie nieprawidłowe lub nieziemne informacje, znane jako "halucynacje".
- Nieaktualne dane: moduły LLM są trenowane na statycznych zestawach danych, które mogą nie zawierać najnowszych informacji, ograniczając ich bieżące znaczenie.
- Brak dostępu do danych lokalnych użytkownika: LLMs nie mają bezpośredniego dostępu do danych osobistych lub zlokalizowanych, ograniczając możliwość udostępniania spersonalizowanych odpowiedzi.
- Limity tokenów: maszyny LLM mają maksymalny limit tokenu na interakcję, ograniczając ilość tekstu, którą mogą przetwarzać jednocześnie. Na przykład gpt-3.5-turbo openAI ma limit tokenu 4096.
Wykorzystanie rozszerzonej generacji pobierania (RAG)
Generowanie rozszerzonej generacji (RAG) jest architekturą zaprojektowaną w celu przezwyciężenia ograniczeń usługi LLM. Funkcja RAG używa wyszukiwania wektorowego do pobierania odpowiednich dokumentów na podstawie zapytania wejściowego, podając te dokumenty jako kontekst do modułu LLM w celu wygenerowania bardziej dokładnych odpowiedzi. Zamiast polegać wyłącznie na wstępnie wytrenowanych wzorcach, rag rozszerza odpowiedzi poprzez uwzględnienie aktualnych, istotnych informacji. Takie podejście pomaga:
- Minimalizuj halucynacje: uziemienia odpowiedzi w informacjach rzeczowych.
- Upewnij się, że bieżące informacje: pobieranie najnowszych danych w celu zapewnienia aktualnych odpowiedzi.
- Korzystanie z zewnętrznych baz danych: chociaż nie udziela bezpośredniego dostępu do danych osobowych, program RAG umożliwia integrację z zewnętrznymi, specyficznymi dla użytkownika baza wiedzy.
- Optymalizowanie użycia tokenu: koncentrując się na najbardziej odpowiednich dokumentach, funkcja RAG sprawia, że użycie tokenu jest bardziej wydajne.
W tym samouczku pokazano, jak program RAG można zaimplementować przy użyciu usługi Azure Cosmos DB dla bazy danych MongoDB (rdzeń wirtualny) w celu utworzenia aplikacji do odpowiadania na pytania dostosowanej do Twoich danych.
Omówienie architektury aplikacji
Na poniższym diagramie architektury przedstawiono kluczowe składniki naszej implementacji RAG:
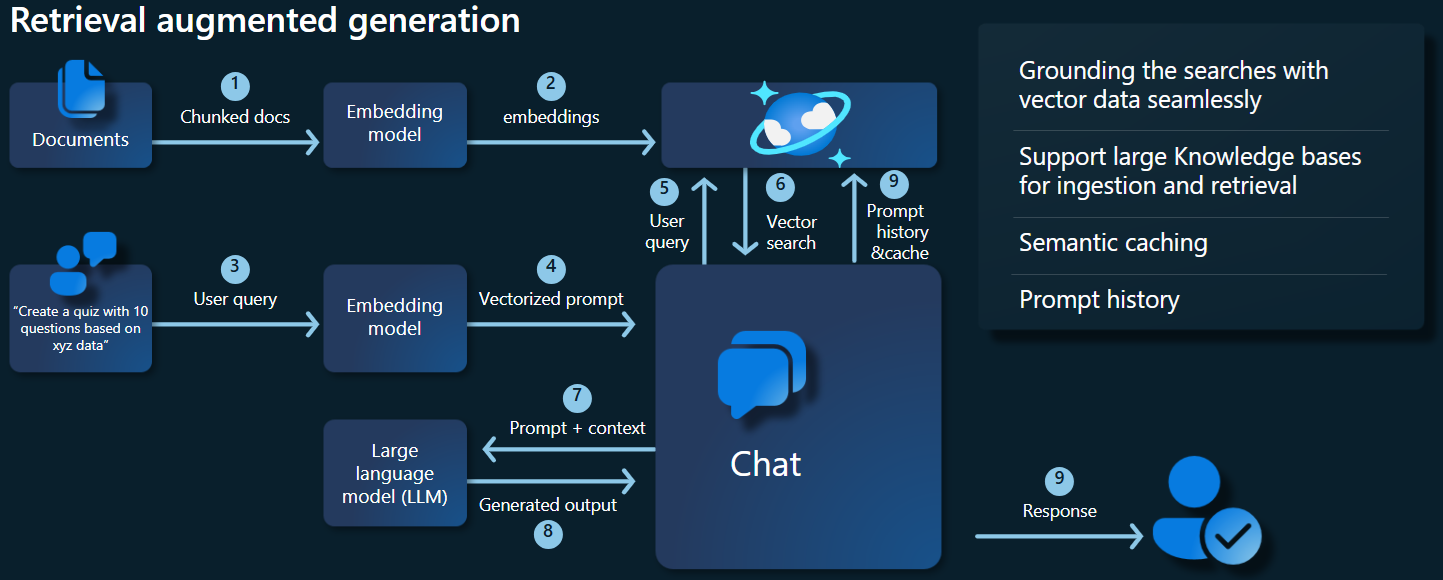
Kluczowe składniki i struktury
Omówimy teraz różne struktury, modele i składniki używane w tym samouczku, podkreślając ich role i niuanse.
Usługa Azure Cosmos DB dla bazy danych MongoDB (rdzeń wirtualny)
Usługa Azure Cosmos DB dla bazy danych MongoDB (rdzeń wirtualny) obsługuje wyszukiwania semantyczne podobieństwa, niezbędne dla aplikacji opartych na sztucznej inteligencji. Umożliwia ona reprezentację danych w różnych formatach jako osadzanie wektorów, które mogą być przechowywane wraz z danymi źródłowymi i metadanymi. Korzystając z przybliżonego algorytmu najbliższych sąsiadów, takiego jak Hierarchiczny świat nawigowalny mały świat (HNSW), te osadzanie można badać pod kątem szybkiego wyszukiwania semantycznego podobieństwa.
Struktura LangChain
LangChain upraszcza tworzenie aplikacji LLM, zapewniając standardowy interfejs łańcuchów, wiele integracji narzędzi i kompleksowe łańcuchy dla typowych zadań. Umożliwia ona deweloperom sztucznej inteligencji tworzenie aplikacji LLM korzystających z zewnętrznych źródeł danych.
Kluczowe aspekty langchaina:
- Łańcuchy: sekwencje składników rozwiązujące określone zadania.
- Składniki: moduły, takie jak otoki LLM, otoki magazynów wektorów, szablony monitów, moduły ładujące dane, rozdzielacze tekstu i pobieranie.
- Modułowość: upraszcza programowanie, debugowanie i konserwację.
- Popularność: Projekt open source szybko zyskuje na wdrożeniu i ewoluuje zgodnie z potrzebami użytkowników.
interfejs usług aplikacja systemu Azure
Usługi App Services zapewniają niezawodną platformę do tworzenia przyjaznych dla użytkownika interfejsów internetowych dla aplikacji Gen-AI. W tym samouczku użyto usług aplikacja systemu Azure do utworzenia interaktywnego interfejsu internetowego dla aplikacji.
Modele OpenAI
OpenAI jest liderem w badaniach nad sztuczną inteligencją, zapewniając różne modele generowania języka, wektoryzacji tekstu, tworzenia obrazów i konwersji audio na tekst. Na potrzeby tego samouczka użyjemy osadzania i modeli językowych openAI, które mają kluczowe znaczenie dla zrozumienia i generowania aplikacji opartych na języku.
Osadzanie modeli a modele generowania języka
| Kategoria | Model osadzania tekstu | Model językowy |
|---|---|---|
| Przeznaczenie | Konwertowanie tekstu na wektorowe osadzanie. | Zrozumienie i generowanie języka naturalnego. |
| Funkcja | Przekształca dane tekstowe w wielowymiarowe tablice liczb, przechwytując semantyczne znaczenie tekstu. | Rozumie i tworzy tekst podobny do człowieka na podstawie danych wejściowych. |
| Wyjście | Tablica liczb (osadzanie wektorów). | Tekst, odpowiedzi, tłumaczenia, kod itp. |
| Przykładowe dane wyjściowe | Każde osadzanie reprezentuje semantyczne znaczenie tekstu w postaci liczbowej z wymiarowością określoną przez model. Na przykład text-embedding-ada-002 generuje wektory o wymiarach 1536. |
Kontekstowo odpowiedni i spójny tekst wygenerowany na podstawie podanych danych wejściowych. Na przykład gpt-3.5-turbo może generować odpowiedzi na pytania, tłumaczyć tekst, pisać kod i nie tylko. |
| Typowe przypadki użycia | - Wyszukiwanie semantyczne | - Chatboty |
| - Systemy rekomendacji | - Automatyczne tworzenie zawartości | |
| - Klastrowanie i klasyfikacja danych tekstowych | - Tłumaczenie języka | |
| - Pobieranie informacji | -Podsumowania | |
| Reprezentacja danych | Reprezentacja liczbowa (osadzanie) | Tekst w języku naturalnym |
| Wymiarze | Długość tablicy odpowiada liczbie wymiarów w miejscu osadzania, na przykład 1536 wymiarów. | Zazwyczaj reprezentowana jako sekwencja tokenów z kontekstem określającym długość. |
Główne składniki aplikacji
- Rdzenie wirtualne usługi Azure Cosmos DB dla bazy danych MongoDB: przechowywanie i odpytywanie wektorów osadzania.
- LangChain: konstruowanie przepływu pracy LLM aplikacji. Wykorzystuje narzędzia, takie jak:
- Moduł ładujący dokumentów: do ładowania i przetwarzania dokumentów z katalogu.
- Integracja magazynu wektorów: do przechowywania i wykonywania zapytań dotyczących osadzania wektorów w usłudze Azure Cosmos DB.
- AzureCosmosDBVectorSearch: Otoka wokół wyszukiwania wektorów usługi Cosmos DB
- aplikacja systemu Azure Services: Tworzenie interfejsu użytkownika dla aplikacji Kosmiczna żywność.
- Azure OpenAI: w celu udostępniania modeli LLM i osadzania, w tym:
- text-embedding-ada-002: model osadzania tekstu, który konwertuje tekst na wektorowe osadzanie z wymiarami 1536.
- gpt-3.5-turbo: model językowy do zrozumienia i generowania języka naturalnego.
Konfigurowanie środowiska
Aby rozpocząć optymalizowanie generowania rozszerzonego pobierania (RAG) przy użyciu usługi Azure Cosmos DB dla bazy danych MongoDB (rdzeń wirtualny), wykonaj następujące kroki:
- Utwórz następujące zasoby na platformie Microsoft Azure:
- Klaster rdzeni wirtualnych usługi Azure Cosmos DB dla bazy danych MongoDB: zobacz przewodnik Szybki start tutaj.
- Zasób usługi Azure OpenAI z:
- Osadzanie wdrożenia modelu (na przykład
text-embedding-ada-002). - Wdrażanie modelu czatu (na przykład
gpt-35-turbo).
- Osadzanie wdrożenia modelu (na przykład
Przykładowe dokumenty
W tym samouczku załadujemy pojedynczy plik tekstowy przy użyciu usługi Document. Te pliki powinny być zapisywane w katalogu o nazwie data w folderze src . Zawartość elementu jest następująca:
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
Ładowanie dokumentów
Ustaw usługę Cosmos DB dla bazy danych MongoDB (rdzeń wirtualny) parametry połączenia, nazwę bazy danych, nazwę kolekcji i indeks:
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]Zainicjuj klienta osadzania.
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )Utwórz osadzanie z danych, zapisz w bazie danych i zwróć połączenie z magazynem wektorów Cosmos DB dla bazy danych MongoDB (rdzeń wirtualny).
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )Utwórz następujący indeks wektora HNSW w kolekcji (zwróć uwagę, że nazwa indeksu jest taka sama jak powyżej).
num_lists = 100 dimensions = 1536 similarity_algorithm = CosmosDBSimilarityType.COS kind = CosmosDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
Wyszukiwanie wektorów przy użyciu usługi Cosmos DB dla bazy danych MongoDB (rdzenie wirtualne)
Połącz się z magazynem wektorów.
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )Zdefiniuj funkcję wykonującą wyszukiwanie semantyczne podobieństwa przy użyciu wyszukiwania wektorowego usługi Cosmos DB w zapytaniu (zwróć uwagę, że ten fragment kodu jest tylko funkcją testową).
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)Zainicjuj klienta czatu w celu zaimplementowania funkcji RAG.
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )Utwórz funkcję RAG.
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )Konwertuje magazyn wektorów na program retriever, który może wyszukiwać odpowiednie dokumenty na podstawie określonych parametrów.
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )Utwórz łańcuch pobierania, który jest świadomy historii konwersacji, zapewniając kontekstowe pobieranie dokumentów przy użyciu modelu azure_openai_chat i vector_store_retriever.
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)Utwórz łańcuch, który łączy pobrane dokumenty w spójną odpowiedź przy użyciu modelu językowego (azure_openai_chat) i określonego monitu (context_prompt).
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)Utwórz łańcuch, który obsługuje cały proces pobierania, integrując łańcuch pobierania obsługujący historię i łańcuch kombinacji dokumentów. Ten łańcuch RAG można wykonać, aby pobrać i wygenerować kontekstowo dokładne odpowiedzi.
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
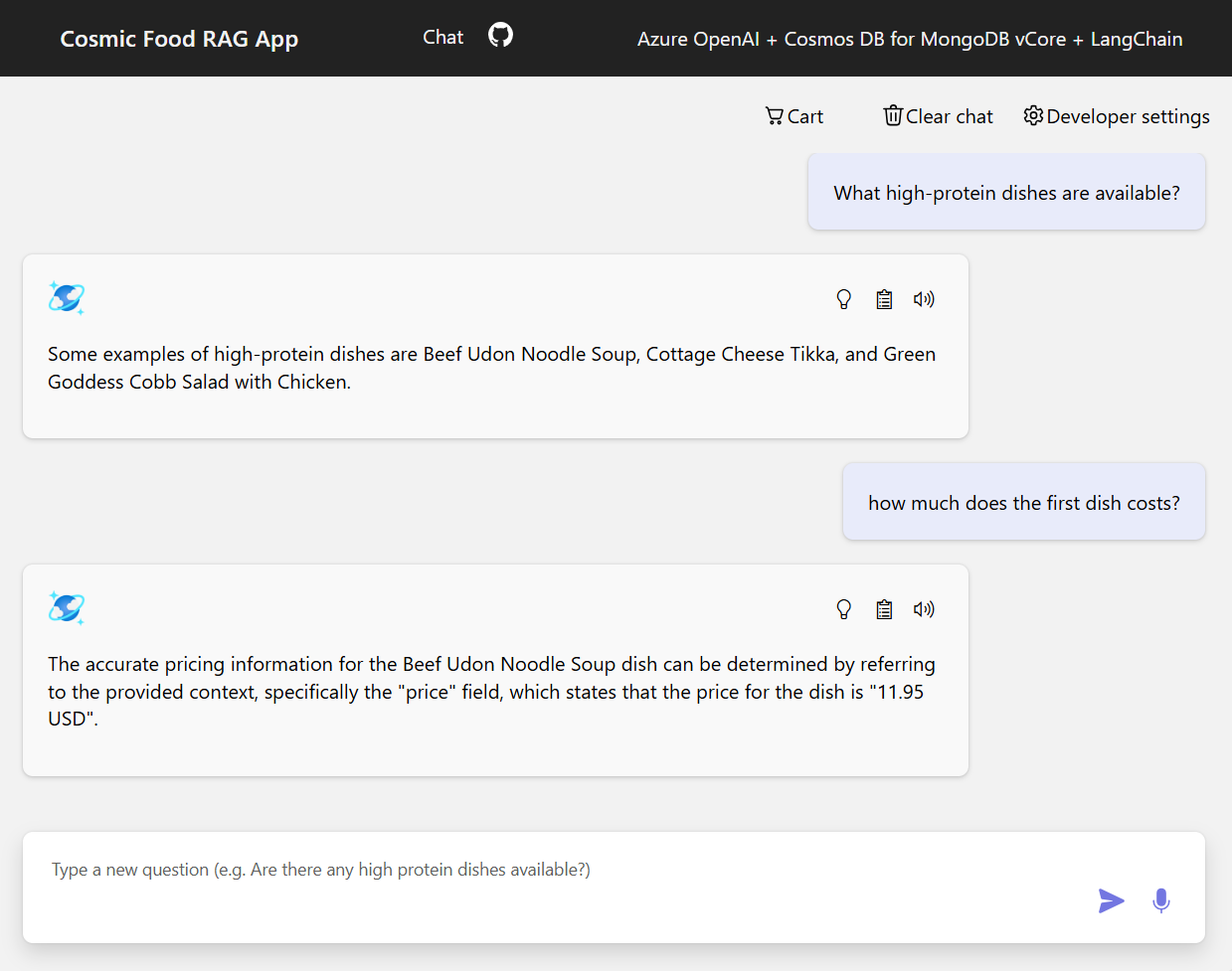
Przykładowe dane wyjściowe
Poniższy zrzut ekranu przedstawia dane wyjściowe dotyczące różnych pytań. Wyszukiwanie czysto semantyczne podobieństwa zwraca nieprzetworzonego tekstu z dokumentów źródłowych, podczas gdy aplikacja do odpowiadania na pytania przy użyciu architektury RAG generuje dokładne i spersonalizowane odpowiedzi, łącząc pobraną zawartość dokumentu z modelem językowym.
Podsumowanie
W tym samouczku przedstawiono sposób tworzenia aplikacji do odpowiadania na pytania, która współdziała z danymi prywatnymi przy użyciu usługi Cosmos DB jako magazynu wektorów. Korzystając z architektury generowania rozszerzonego pobierania (RAG) za pomocą bibliotek LangChain i Azure OpenAI, pokazaliśmy, jak magazyny wektorów są niezbędne dla aplikacji LLM.
RAG to znaczący postęp w zakresie sztucznej inteligencji, szczególnie w przetwarzaniu języka naturalnego, a połączenie tych technologii umożliwia tworzenie zaawansowanych aplikacji opartych na sztucznej inteligencji w różnych przypadkach użycia.