Generowanie anonsów rozszerzonych za pomocą usługi Azure Cosmos DB dla rdzeni wirtualnych bazy danych MongoDB
W tym przewodniku pokazano, jak utworzyć dynamiczną zawartość reklamową, która rezonuje z odbiorcami przy użyciu naszego spersonalizowanego asystenta sztucznej inteligencji, Heelie. Korzystając z rdzeni wirtualnych usługi Azure Cosmos DB dla bazy danych MongoDB, wykorzystujemy funkcje wyszukiwania podobieństwa wektorów, aby semantycznie analizować i dopasowywać opisy spisu do tematów anonsów. Proces jest możliwy przez generowanie wektorów dla opisów spisu przy użyciu osadzania OpenAI, co znacznie zwiększa ich głębię semantyczną. Te wektory są następnie przechowywane i indeksowane w ramach zasobu usługi Cosmos DB dla rdzenia wirtualnego bazy danych MongoDB. Podczas generowania zawartości dla anonsów możemy wektoryzować temat anonsu w celu znalezienia najlepiej pasujących elementów spisu. Następnie następuje proces pobierania rozszerzonej generacji (RAG), w którym najlepsze dopasowania są wysyłane do openAI w celu utworzenia atrakcyjnej reklamy. Cała baza kodu dla aplikacji jest dostępna w repozytorium GitHub na potrzeby dokumentacji.
Funkcje
- Wyszukiwanie podobieństwa wektorów: używa usługi Azure Cosmos DB dla zaawansowanego wyszukiwania wektorów wirtualnych bazy danych MongoDB w celu zwiększenia możliwości wyszukiwania semantycznego, co ułatwia znajdowanie odpowiednich elementów spisu na podstawie zawartości anonsów.
- Osadzanie openAI: wykorzystuje najnowocześniejsze osadzanie z interfejsu OpenAI do generowania wektorów opisów spisu. Takie podejście umożliwia bardziej zniuansowane i semantycznie bogate dopasowania między spisem a zawartością anonsu.
- Generowanie zawartości: wykorzystuje zaawansowane modele językowe openAI do generowania atrakcyjnych, skoncentrowanych na trendach reklam. Ta metoda zapewnia, że zawartość jest nie tylko odpowiednia, ale także urzekająca odbiorców docelowych.
Wymagania wstępne
- Azure OpenAI: skonfigurujmy zasób Azure OpenAI. Dostęp do tej usługi jest obecnie dostępny tylko przez aplikację. Możesz ubiegać się o dostęp do usługi Azure OpenAI, wypełniając formularz pod adresem https://aka.ms/oai/access. Po uzyskaniu dostępu wykonaj następujące kroki:
- Utwórz zasób usługi Azure OpenAI, wykonując czynności opisane w tym przewodniku Szybki start.
completionsWdrażanie modelu iembeddings.- Zanotuj punkty końcowe, klucz i nazwy wdrożenia.
- Zasób rdzeni wirtualnych usługi Cosmos DB dla bazy danych MongoDB: zacznijmy od utworzenia zasobu rdzenia wirtualnego usługi Azure Cosmos DB dla bazy danych MongoDB, korzystając bezpłatnie z tego przewodnika Szybki start .
- Zanotuj szczegóły połączenia.
- Środowisko języka Python (>= 3.9) z pakietami, takimi jak
numpy, ,pymongoazure-corepython-dotenvazure-cosmosopenai,tenacity, i .gradio - Pobierz plik danych i zapisz go w wyznaczonym folderze danych.
Uruchamianie skryptu
Zanim przejdziemy do ekscytującej części generowania reklam rozszerzonych przez sztuczną inteligencję, musimy skonfigurować nasze środowisko. Ta konfiguracja obejmuje zainstalowanie niezbędnych pakietów w celu zapewnienia bezproblemowego działania skryptu. Oto przewodnik krok po kroku, aby przygotować wszystko.
1.1. Instalowanie niezbędnych pakietów
Najpierw musimy zainstalować kilka pakietów języka Python. Otwórz terminal i uruchom następujące polecenia:
pip install numpy
pip install openai==1.2.3
pip install pymongo
pip install python-dotenv
pip install azure-core
pip install azure-cosmos
pip install tenacity
pip install gradio
pip show openai
1.2 Konfigurowanie interfejsu OpenAI i klienta platformy Azure
Po zainstalowaniu niezbędnych pakietów następnym krokiem jest skonfigurowanie naszych klientów openAI i platformy Azure dla skryptu, co ma kluczowe znaczenie dla uwierzytelniania naszych żądań do interfejsu API OpenAI i usług platformy Azure.
import json
import time
import openai
from dotenv import dotenv_values
from openai import AzureOpenAI
# Configure the API to use Azure as the provider
openai.api_type = "azure"
openai.api_key = "<AZURE_OPENAI_API_KEY>" # Replace with your actual Azure OpenAI API key
openai.api_base = "https://<OPENAI_ACCOUNT_NAME>.openai.azure.com/" # Replace with your OpenAI account name
openai.api_version = "2023-06-01-preview"
# Initialize the AzureOpenAI client with your API key, version, and endpoint
client = AzureOpenAI(
api_key=openai.api_key,
api_version=openai.api_version,
azure_endpoint=openai.api_base
)
Architektura rozwiązania
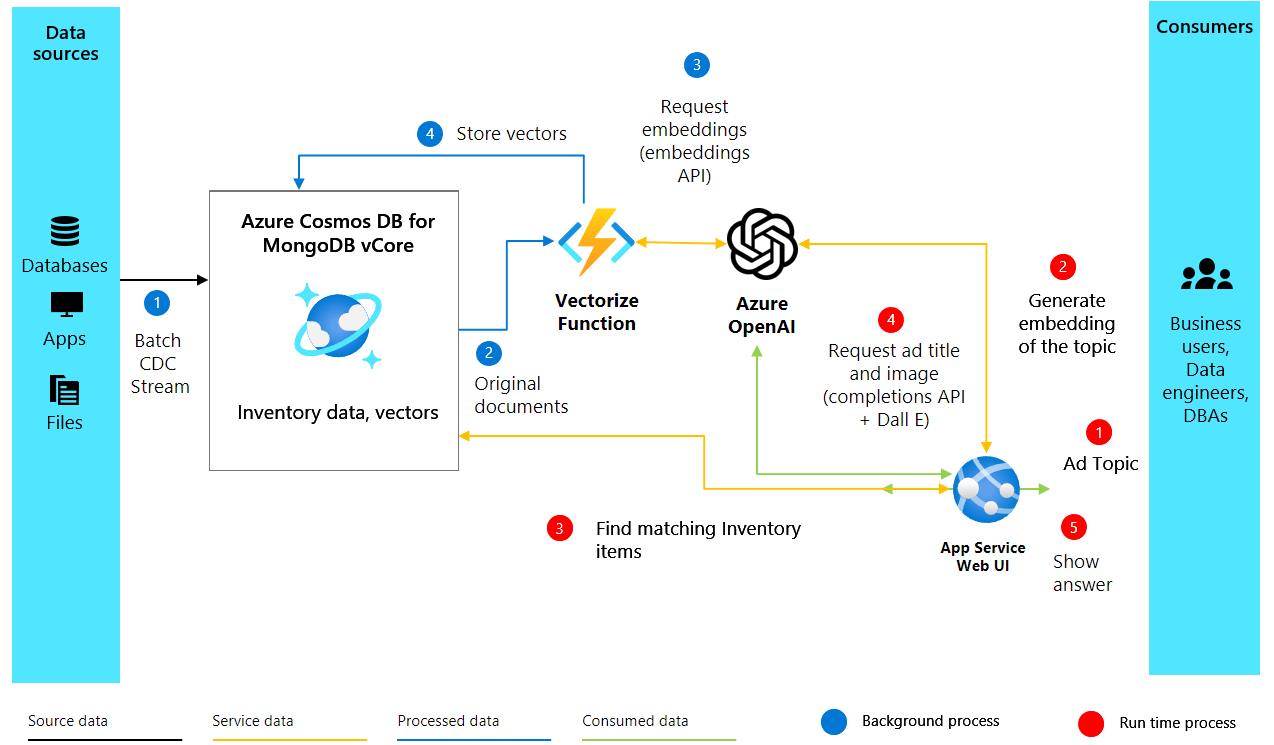
2. Tworzenie osadzania i konfigurowanie usługi Cosmos DB
Po skonfigurowaniu naszego środowiska i klienta OpenAI przechodzimy do podstawowej części naszego projektu generowania anonsów z rozszerzoną sztuczną inteligencją. Poniższy kod tworzy wektorowe osadzania z opisów tekstu produktów i konfiguruje bazę danych w usłudze Azure Cosmos DB dla mongoDB w celu przechowywania i wyszukiwania tych osadzonych.
2.1. Tworzenie osadzania
Aby wygenerować atrakcyjne reklamy, najpierw musimy zrozumieć elementy w naszym spisie. Robimy to, tworząc wektorowe osadzania z opisów naszych elementów, co pozwala nam przechwytywać ich semantyczne znaczenie w postaci, którą maszyny mogą zrozumieć i przetworzyć. Oto jak utworzyć wektorowe osadzanie dla opisu elementu przy użyciu usługi Azure OpenAI:
import openai
def generate_embeddings(text):
try:
response = client.embeddings.create(
input=text, model="text-embedding-ada-002")
embeddings = response.data[0].embedding
return embeddings
except Exception as e:
print(f"An error occurred: {e}")
return None
embeddings = generate_embeddings("Shoes for San Francisco summer")
if embeddings is not None:
print(embeddings)
Funkcja przyjmuje tekst wejściowy — taki jak opis produktu — i używa client.embeddings.create metody z interfejsu API OpenAI do wygenerowania wektorowego osadzania dla tego tekstu. Używamy text-embedding-ada-002 tutaj modelu, ale możesz wybrać inne modele na podstawie Twoich wymagań. Jeśli proces zakończy się pomyślnie, drukuje wygenerowane osadzanie; w przeciwnym razie obsługuje wyjątki, drukując komunikat o błędzie.
3. Łączenie i konfigurowanie usługi Cosmos DB dla rdzeni wirtualnych bazy danych MongoDB
Po zakończeniu osadzania następnym krokiem jest przechowywanie i indeksowanie ich w bazie danych obsługującej wyszukiwanie podobieństwa wektorów. Rdzeń wirtualny usługi Azure Cosmos DB dla bazy danych MongoDB jest idealnym rozwiązaniem dla tego zadania, ponieważ jest przeznaczony do przechowywania danych transakcyjnych i wykonywania wyszukiwania wektorów w jednym miejscu.
3.1 Konfigurowanie połączenia
Aby nawiązać połączenie z usługą Cosmos DB, użyjemy biblioteki pymongo, która umożliwia łatwą interakcję z bazą danych MongoDB. Poniższy fragment kodu ustanawia połączenie z naszym wystąpieniem rdzeni wirtualnych usługi Cosmos DB dla bazy danych MongoDB:
import pymongo
# Replace <USERNAME>, <PASSWORD>, and <VCORE_CLUSTER_NAME> with your actual credentials and cluster name
mongo_conn = "mongodb+srv://<USERNAME>:<PASSWORD>@<VCORE_CLUSTER_NAME>.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000"
mongo_client = pymongo.MongoClient(mongo_conn)
Zastąp <USERNAME>wartości , <PASSWORD>i <VCORE_CLUSTER_NAME> rzeczywistą nazwą użytkownika, hasła i klastra rdzeni wirtualnych mongoDB.
4. Konfigurowanie indeksu bazy danych i wektora w usłudze Cosmos DB
Po nawiązaniu połączenia z usługą Azure Cosmos DB następne kroki obejmują skonfigurowanie bazy danych i kolekcji, a następnie utworzenie indeksu wektorowego w celu umożliwienia wydajnego wyszukiwania podobieństwa wektorów. Przeanalizujmy te kroki.
4.1 Konfigurowanie bazy danych i kolekcji
Najpierw utworzymy bazę danych i kolekcję w ramach naszego wystąpienia usługi Cosmos DB. Oto, jak to zrobić:
DATABASE_NAME = "AdgenDatabase"
COLLECTION_NAME = "AdgenCollection"
mongo_client.drop_database(DATABASE_NAME)
db = mongo_client[DATABASE_NAME]
collection = db[COLLECTION_NAME]
if COLLECTION_NAME not in db.list_collection_names():
# Creates a unsharded collection that uses the DBs shared throughput
db.create_collection(COLLECTION_NAME)
print("Created collection '{}'.\n".format(COLLECTION_NAME))
else:
print("Using collection: '{}'.\n".format(COLLECTION_NAME))
4.2. Tworzenie indeksu wektora
Aby przeprowadzić wydajne wyszukiwania wektorów w kolekcji, musimy utworzyć indeks wektorowy. Usługa Cosmos DB obsługuje różne typy indeksów wektorów, a w tym miejscu omawiamy dwa: IVF i HNSW.
IVF
IVF to domyślny algorytm indeksowania wektorów, który działa we wszystkich warstwach klastra. Jest to przybliżone podejście najbliższych sąsiadów (ANN), które używa klastrowania do przyspieszenia wyszukiwania podobnych wektorów w zestawie danych. Aby utworzyć indeks IVF, użyj następującego polecenia:
db.command({
'createIndexes': COLLECTION_NAME,
'indexes': [
{
'name': 'vectorSearchIndex',
'key': {
"contentVector": "cosmosSearch"
},
'cosmosSearchOptions': {
'kind': 'vector-ivf',
'numLists': 1,
'similarity': 'COS',
'dimensions': 1536
}
}
]
});
Ważne
Można utworzyć tylko jeden indeks na właściwość wektora. Oznacza to, że nie można utworzyć więcej niż jednego indeksu wskazującego tę samą właściwość wektora. Jeśli chcesz zmienić typ indeksu (np. z IVF na HNSW), musisz najpierw usunąć indeks przed utworzeniem nowego indeksu.
HNSW
HNSW to hierarchiczna struktura danych oparta na grafach, która dzieli wektory na klastry i podklasy. Dzięki usłudze HNSW można szybko przeprowadzać szybkie wyszukiwanie najbliższych sąsiadów z większą szybkością z większą dokładnością. HNSW to przybliżona metoda (ANN). Oto jak go skonfigurować:
db.command(
{
"createIndexes": "ExampleCollection",
"indexes": [
{
"name": "VectorSearchIndex",
"key": {
"contentVector": "cosmosSearch"
},
"cosmosSearchOptions": {
"kind": "vector-hnsw",
"m": 16, # default value
"efConstruction": 64, # default value
"similarity": "COS",
"dimensions": 1536
}
}
]
}
)
Uwaga
Indeksowanie HNSW jest dostępne tylko w warstwach klastra M40 i nowszych.
5. Wstawianie danych do kolekcji
Teraz wstaw dane spisu, które zawierają opisy i odpowiadające im osadzanie wektorów, do nowo utworzonej kolekcji. Aby wstawić dane do kolekcji, użyjemy insert_many() metody udostępnionej przez bibliotekę pymongo . Metoda umożliwia wstawianie wielu dokumentów do kolekcji jednocześnie. Nasze dane są przechowywane w pliku JSON, który zostanie załadowany, a następnie wstawiony do bazy danych.
Pobierz plik shoes_with_vectors.json z repozytorium GitHub i zapisz go w katalogu w data folderze projektu.
data_file = open(file="./data/shoes_with_vectors.json", mode="r")
data = json.load(data_file)
data_file.close()
result = collection.insert_many(data)
print(f"Number of data points added: {len(result.inserted_ids)}")
6. Wyszukiwanie wektorowe w usłudze Cosmos DB dla rdzeni wirtualnych bazy danych MongoDB
Po pomyślnym przekazaniu danych możemy teraz zastosować możliwości wyszukiwania wektorowego, aby znaleźć najbardziej odpowiednie elementy na podstawie zapytania. Utworzony wcześniej indeks wektorowy umożliwia nam wykonywanie semantycznych wyszukiwań w naszym zestawie danych.
6.1 Przeprowadzanie wyszukiwania wektorowego
Aby przeprowadzić wyszukiwanie wektorowe, definiujemy funkcję vector_search , która przyjmuje zapytanie i liczbę wyników do zwrócenia. Funkcja generuje wektor zapytania przy użyciu zdefiniowanej generate_embeddings wcześniej funkcji, a następnie używa funkcji usługi Cosmos DB $search do znalezienia najbliższych pasujących elementów na podstawie ich osadzonych wektorów.
# Function to assist with vector search
def vector_search(query, num_results=3):
query_vector = generate_embeddings(query)
embeddings_list = []
pipeline = [
{
'$search': {
"cosmosSearch": {
"vector": query_vector,
"numLists": 1,
"path": "contentVector",
"k": num_results
},
"returnStoredSource": True }},
{'$project': { 'similarityScore': { '$meta': 'searchScore' }, 'document' : '$$ROOT' } }
]
results = collection.aggregate(pipeline)
return results
6.2 Wykonywanie zapytania wyszukiwania wektorów
Na koniec wykonamy naszą funkcję wyszukiwania wektorowego z określonym zapytaniem i przetworzymy wyniki, aby je wyświetlić:
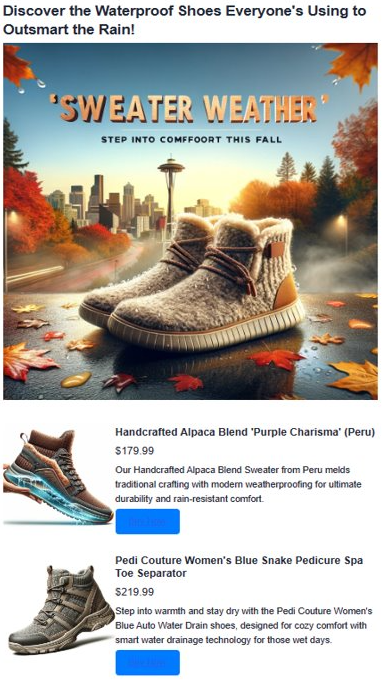
query = "Shoes for Seattle sweater weather"
results = vector_search(query, 3)
print("\nResults:\n")
for result in results:
print(f"Similarity Score: {result['similarityScore']}")
print(f"Title: {result['document']['name']}")
print(f"Price: {result['document']['price']}")
print(f"Material: {result['document']['material']}")
print(f"Image: {result['document']['img_url']}")
print(f"Purchase: {result['document']['purchase_url']}\n")
7. Generowanie zawartości reklamy przy użyciu bibliotekI GPT-4 i JĘZYKA DALL. E
Łączymy wszystkie opracowane składniki, aby tworzyć atrakcyjne reklamy, wykorzystując bibliotekę GPT-4 openAI do tekstu i języka DALL· E 3 dla obrazów. Wraz z wynikami wyszukiwania wektorowego tworzą one pełną reklamę. Wprowadzamy również Heelie, naszego inteligentnego asystenta, który miał na celu tworzenie atrakcyjnych tagów reklam. W nadchodzącym kodzie zobaczysz akcję Heelie, zwiększając nasz proces tworzenia reklam.
from openai import OpenAI
def generate_ad_title(ad_topic):
system_prompt = '''
You are Heelie, an intelligent assistant for generating witty and cativating tagline for online advertisement.
- The ad campaign taglines that you generate are short and typically under 100 characters.
'''
user_prompt = f'''Generate a catchy, witty, and short sentence (less than 100 characters)
for an advertisement for selling shoes for {ad_topic}'''
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
response = client.chat.completions.create(
model="gpt-4",
messages=messages
)
return response.choices[0].message.content
def generate_ad_image(ad_topic):
daliClient = OpenAI(
api_key="<DALI_API_KEY>"
)
image_prompt = f'''
Generate a photorealistic image of an ad campaign for selling {ad_topic}.
The image should be clean, with the item being sold in the foreground with an easily identifiable landmark of the city in the background.
The image should also try to depict the weather of the location for the time of the year mentioned.
The image should not have any generated text overlay.
'''
response = daliClient.images.generate(
model="dall-e-3",
prompt= image_prompt,
size="1024x1024",
quality="standard",
n=1,
)
return response.data[0].url
def render_html_page(ad_topic):
# Find the matching shoes from the inventory
results = vector_search(ad_topic, 4)
ad_header = generate_ad_title(ad_topic)
ad_image_url = generate_ad_image(ad_topic)
with open('./data/ad-start.html', 'r', encoding='utf-8') as html_file:
html_content = html_file.read()
html_content += f'''<header>
<h1>{ad_header}</h1>
</header>'''
html_content += f'''
<section class="ad">
<img src="{ad_image_url}" alt="Base Ad Image" class="ad-image">
</section>'''
for result in results:
html_content += f'''
<section class="product">
<img src="{result['document']['img_url']}" alt="{result['document']['name']}" class="product-image">
<div class="product-details">
<h3 class="product-title" color="gray">{result['document']['name']}</h2>
<p class="product-price">{"$"+str(result['document']['price'])}</p>
<p class="product-description">{result['document']['description']}</p>
<a href="{result['document']['purchase_url']}" class="buy-now-button">Buy Now</a>
</div>
</section>
'''
html_content += '''</article>
</body>
</html>'''
return html_content
8. Zebranie wszystkiego razem
Aby umożliwić interaktywne generowanie reklam, stosujemy aplikację Gradio, bibliotekę języka Python do tworzenia prostych internetowych interfejsów użytkownika. Definiujemy interfejs użytkownika, który umożliwia użytkownikom wprowadzanie tematów reklam, a następnie dynamicznie generuje i wyświetla wynikową anons.
import gradio as gr
css = """
button { background-color: purple; color: red; }
<style>
</style>
"""
with gr.Blocks(css=css, theme=gr.themes.Default(spacing_size=gr.themes.sizes.spacing_sm, radius_size="none")) as demo:
subject = gr.Textbox(placeholder="Ad Keywords", label="Prompt for Heelie!!")
btn = gr.Button("Generate Ad")
output_html = gr.HTML(label="Generated Ad HTML")
btn.click(render_html_page, [subject], output_html)
btn = gr.Button("Copy HTML")
if __name__ == "__main__":
demo.launch()
Wyjście