Omówienie indeksowania w usłudze Azure Cosmos DB
DOTYCZY: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Kasandra
Kasandra ![]() Gremlin
Gremlin ![]() Stół
Stół
Azure Cosmos DB to niezależna od schematu baza danych, która umożliwia iterowanie aplikacji bez konieczności zarządzania schematami lub indeksami. Domyślnie usługa Azure Cosmos DB automatycznie indeksuje każdą właściwość dla wszystkich elementów w kontenerze bez konieczności definiowania schematu ani konfigurowania indeksów pomocniczych.
Celem tego artykułu jest wyjaśnienie sposobu indeksowania danych przez usługę Azure Cosmos DB i wykorzystania tych indeksów do podwyższenia wydajności zapytań. Zaleca się przejrzenie tej sekcji przed zbadaniem sposobu dostosowywania zasad indeksowania.
Od elementów do drzew
Za każdym razem, gdy element jest przechowywany w kontenerze, jego zawartość jest projektowana jako dokument JSON, a następnie konwertowana na reprezentację drzewa. Ta konwersja oznacza, że każda właściwość tego elementu jest reprezentowana jako węzeł w drzewie. Pseudowęźle główny jest tworzony jako element nadrzędny dla wszystkich właściwości pierwszego poziomu elementu. Węzły liścia zawierają rzeczywiste wartości skalarne przenoszone przez element.
Rozważmy na przykład ten element:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
To drzewo reprezentuje przykładowy element JSON:
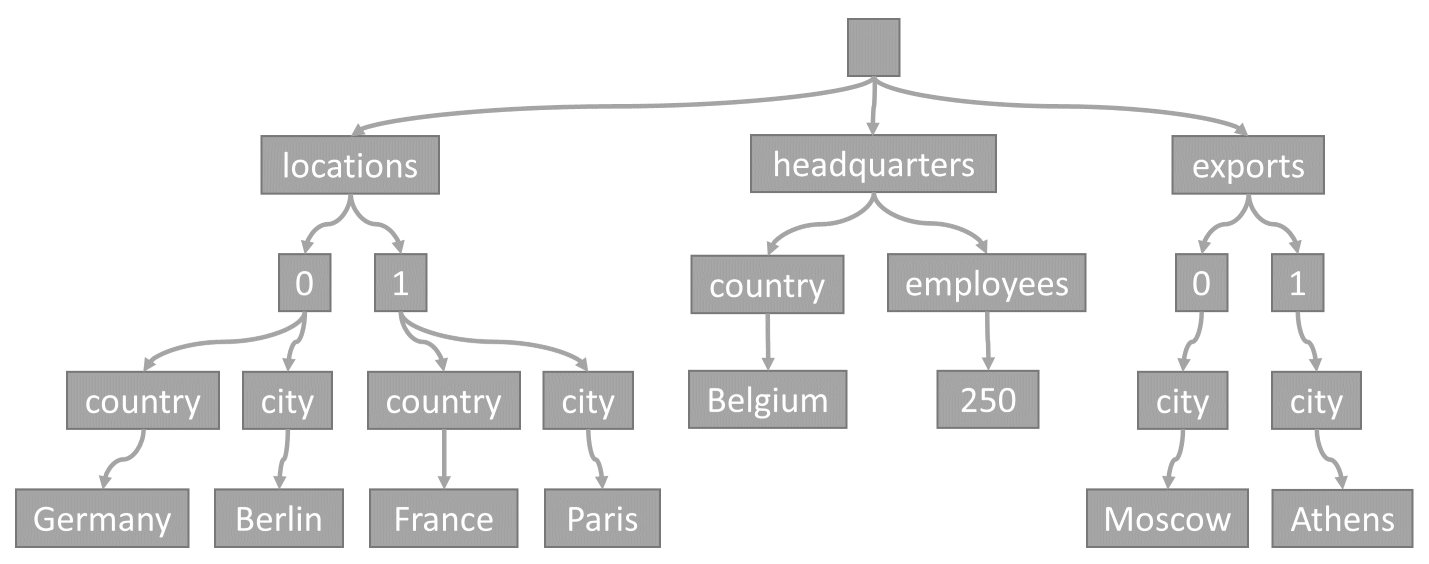
Zwróć uwagę, jak tablice są kodowane w drzewie: każdy wpis w tablicy otrzymuje węzeł pośredni oznaczony indeksem tego wpisu w tablicy (0, 1 itp.).
Od drzew do ścieżek właściwości
Powodem, dla którego usługa Azure Cosmos DB przekształca elementy w drzewa, jest to, że umożliwia systemowi odwołanie się do właściwości przy użyciu ich ścieżek w tych drzewach. Aby uzyskać ścieżkę dla właściwości, możemy przejść przez drzewo z węzła głównego do tej właściwości i połączyć etykiety każdego węzła przechodzącego.
Poniżej przedstawiono ścieżki dla każdej właściwości z przykładowego elementu opisanego wcześniej:
/locations/0/country: "Niemcy"/locations/0/city: "Berlin"/locations/1/country: "Francja"/locations/1/city: "Paryż"/headquarters/country: "Belgia"/headquarters/employees: 250/exports/0/city: "Moskwa"/exports/1/city: "Ateny"
Usługa Azure Cosmos DB skutecznie indeksuje ścieżkę każdej właściwości i odpowiadającą jej wartość podczas zapisywania elementu.
Typy indeksów
Usługa Azure Cosmos DB obecnie obsługuje trzy typy indeksów. Te typy indeksów można skonfigurować podczas definiowania zasad indeksowania.
Indeks zakresu
Indeksy zakresu są oparte na uporządkowanej strukturze podobnej do drzewa. Typ indeksu zakresu jest używany dla:
Zapytania dotyczące równości:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")Dopasowanie równości w elemecie tablicy
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")Zapytania zakresu:
SELECT * FROM container c WHERE c.property > 'value'Uwaga
(działa dla
>, ,>=<, ,<=)!=Sprawdzanie obecności właściwości:
SELECT * FROM c WHERE IS_DEFINED(c.property)Funkcje systemowe ciągów:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")ORDER BYKwerendy:SELECT * FROM container c ORDER BY c.propertyJOINKwerendy:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
Indeksy zakresu mogą być używane w wartościach skalarnych (ciąg lub liczba). Domyślne zasady indeksowania dla nowo utworzonych kontenerów wymuszają indeksy zakresu dla wszelkich ciągów i liczb. Aby dowiedzieć się, jak skonfigurować indeksy zakresu, zobacz Przykłady zasad indeksowania zakresu
Uwaga
Klauzula ORDER BY , która porządkuje według pojedynczej właściwości , zawsze potrzebuje indeksu zakresu i zakończy się niepowodzeniem, jeśli ścieżka, do której się odwołuje, nie ma tego indeksu. Podobnie zapytanie, ORDER BY które porządkuje według wielu właściwości , zawsze wymaga indeksu złożonego.
Indeks przestrzenny
Indeksy przestrzenne umożliwiają wydajne zapytania dotyczące obiektów geoprzestrzennych, takich jak — punkty, linie, wielokąty i wielobiegun. Te zapytania używają słów kluczowych ST_DISTANCE, ST_WITHIN ST_INTERSECTS. Poniżej przedstawiono kilka przykładów, które używają typu indeksu przestrzennego:
Zapytania dotyczące odległości geoprzestrzennych:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Geoprzestrzenne w zapytaniach:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })Zapytania interprzestrzenne geoprzestrzenne:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
Indeksy przestrzenne mogą być używane w poprawnie sformatowanych obiektach GeoJSON . Punkty, Ciągi liniowe, Wielokąty i MultiPolygony są obecnie obsługiwane. Aby dowiedzieć się, jak skonfigurować indeksy przestrzenne, zobacz Przykłady zasad indeksowania przestrzennego
Indeksy złożone
Indeksy złożone zwiększają wydajność podczas wykonywania operacji na wielu polach. Typ indeksu złożonego jest używany dla:
ORDER BYzapytania dotyczące wielu właściwości:SELECT * FROM container c ORDER BY c.property1, c.property2Zapytania z filtrem i
ORDER BY. Te zapytania mogą korzystać z indeksu złożonego, jeśli właściwość filter jest dodawana do klauzuliORDER BY.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2Kwerendy z filtrem w co najmniej dwóch właściwościach, w których co najmniej jedna właściwość jest filtrem równości
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
O ile jeden predykat filtru używa jednego z typów indeksów, aparat zapytań ocenia to najpierw przed skanowaniem reszty. Jeśli na przykład masz zapytanie SQL, takie jak SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
Powyższe zapytanie najpierw filtruje wpisy, w których firstName = "Andrew" przy użyciu indeksu. Następnie przekazuje wszystkie wpisy firstName = "Andrew" za pośrednictwem kolejnego potoku, aby ocenić predykat filtru CONTAINS.
Możesz przyspieszyć wykonywanie zapytań i unikać pełnego skanowania kontenerów podczas korzystania z funkcji, które wykonują pełne skanowanie, takie jak CONTAINS. Możesz dodać więcej predykatów filtrów, które używają indeksu do przyspieszenia tych zapytań. Kolejność klauzul filtru nie jest ważna. Aparat zapytań określa, które predykaty są bardziej selektywne i odpowiednio uruchamiają zapytanie.
Aby dowiedzieć się, jak skonfigurować indeksy złożone, zobacz Przykłady zasad indeksowania złożonego
Indeksy wektorowe
Indeksy wektorowe zwiększają wydajność podczas przeprowadzania wyszukiwania wektorów przy użyciu funkcji systemowej VectorDistance . Wyszukiwania wektorów będą miały znacznie mniejsze opóźnienie, większą przepływność i mniejsze użycie jednostek RU podczas korzystania z indeksu wektorowego.
Aby dowiedzieć się, jak skonfigurować indeksy wektorowe, zobacz przykłady zasad indeksowania wektorów
ORDER BYzapytania wyszukiwania wektorowego:SELECT TOP 10 * FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Projekcja wyniku podobieństwa w zapytaniach wyszukiwania wektorów:
SELECT TOP 10 c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Filtry zakresu dla wyniku podobieństwa.
SELECT TOP 10 * FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)
Ważne
Obecnie zasady wektorów i indeksy wektorów są niezmienne po utworzeniu. Aby wprowadzić zmiany, utwórz nową kolekcję.
Użycie indeksu
Aparat zapytań może oceniać filtry zapytań na pięć sposobów posortowanych według najbardziej wydajnych i najmniej wydajnych:
- Wyszukiwanie indeksu
- Dokładne skanowanie indeksu
- Rozszerzone skanowanie indeksu
- Pełne skanowanie indeksu
- Pełne skanowanie
Podczas indeksowania ścieżek właściwości aparat zapytań automatycznie używa indeksu tak wydajnie, jak to możliwe. Oprócz indeksowania nowych ścieżek właściwości nie trzeba konfigurować żadnych elementów, aby zoptymalizować sposób używania indeksu przez zapytania. Opłaty za jednostki RU zapytania to kombinacja opłaty za jednostkę RU z użycia indeksu i opłaty za jednostkę ŻĄDANIA z ładowania elementów.
Oto tabela podsumowująca różne sposoby użycia indeksów w usłudze Azure Cosmos DB:
| Typ odnośnika indeksu | opis | Typowe przykłady | Opłata za jednostkę ŻĄDANIA z użycia indeksu | Opłaty za jednostki RU od ładowania elementów z transakcyjnego magazynu danych |
|---|---|---|---|---|
| Wyszukiwanie indeksu | Odczytywanie tylko wymaganych wartości indeksowanych i ładowanie tylko pasujących elementów z transakcyjnego magazynu danych | Filtry równości, IN | Stała na filtr równości | Zwiększa się na podstawie liczby elementów w wynikach zapytania |
| Dokładne skanowanie indeksu | Binarne wyszukiwanie indeksowanych wartości i ładowanie tylko pasujących elementów z transakcyjnego magazynu danych | Porównania zakresów (>, <, <= lub >=), StartsWith | Porównywalne z wyszukiwaniem indeksów, nieznacznie zwiększa się na podstawie kardynalności indeksowanych właściwości | Zwiększa się na podstawie liczby elementów w wynikach zapytania |
| Rozszerzone skanowanie indeksu | Zoptymalizowane wyszukiwanie (ale mniej wydajne niż wyszukiwanie binarne) indeksowanych wartości i ładowanie tylko pasujących elementów z transakcyjnego magazynu danych | StartsWith (bez uwzględniania wielkości liter), StringEquals (bez uwzględniania wielkości liter) | Zwiększa się nieznacznie na podstawie kardynalności indeksowanych właściwości | Zwiększa się na podstawie liczby elementów w wynikach zapytania |
| Pełne skanowanie indeksu | Odczytywanie odrębnego zestawu indeksowanych wartości i ładowanie tylko pasujących elementów z transakcyjnego magazynu danych | Contains, EndsWith, RegexMatch, LIKE | Zwiększa liniowo na podstawie kardynalności indeksowanych właściwości | Zwiększa się na podstawie liczby elementów w wynikach zapytania |
| Pełne skanowanie | Ładowanie wszystkich elementów z transakcyjnego magazynu danych | Górna, Dolna | Nie dotyczy | Zwiększa się na podstawie liczby elementów w kontenerze |
Podczas pisania zapytań należy używać predykatów filtrów, które używają indeksu tak wydajnie, jak to możliwe. Jeśli na przykład albo StartsWith Contains będzie działać w twoim przypadku użycia, należy zdecydować się na StartsWith to, ponieważ wykonuje dokładne skanowanie indeksu zamiast pełnego skanowania indeksu.
Szczegóły użycia indeksu
W tej sekcji omówiono więcej szczegółów na temat używania indeksów przez zapytania. Ten poziom szczegółowości nie jest konieczny, aby dowiedzieć się, jak rozpocząć pracę z usługą Azure Cosmos DB, ale został szczegółowo udokumentowany dla ciekawych użytkowników. Odwołujemy się do przykładowego elementu udostępnionego wcześniej w tym dokumencie:
Przykładowe elementy:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Usługa Azure Cosmos DB używa odwróconego indeksu. Indeks działa przez mapowanie każdej ścieżki JSON na zestaw elementów zawierających te wartości. Mapowanie identyfikatora elementu jest reprezentowane na wielu różnych stronach indeksu dla kontenera. Oto przykładowy diagram odwróconego indeksu dla kontenera zawierającego dwa przykładowe elementy:
| Ścieżka | Wartość | Lista identyfikatorów elementów |
|---|---|---|
| /locations/0/country | Niemcy | 1 |
| /locations/0/country | Irlandia | 2 |
| /locations/0/city | Berlin | 1 |
| /locations/0/city | Dublin | 2 |
| /locations/1/country | Francja | 1 |
| /locations/1/city | Paryż | 1 |
| /siedziba/kraj | Belgia | 1, 2 |
| /centrala/pracownicy | 200 | 2 |
| /centrala/pracownicy | 250 | 1 |
Odwrócony indeks ma dwa ważne atrybuty:
- Dla danej ścieżki wartości są sortowane w kolejności rosnącej. W związku z tym aparat zapytań może łatwo obsłużyć
ORDER BYz indeksu. - W przypadku danej ścieżki aparat zapytań może skanować za pomocą odrębnego zestawu możliwych wartości w celu zidentyfikowania stron indeksu, na których znajdują się wyniki.
Aparat zapytań może korzystać z odwróconego indeksu na cztery różne sposoby:
Wyszukiwanie indeksu
Rozważ następujące zapytanie:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
Predykat zapytania (filtrowanie elementów, w których dowolna lokalizacja ma wartość "Francja" jako kraj/region), będzie zgodna ze ścieżką wyróżnioną na tym diagramie:
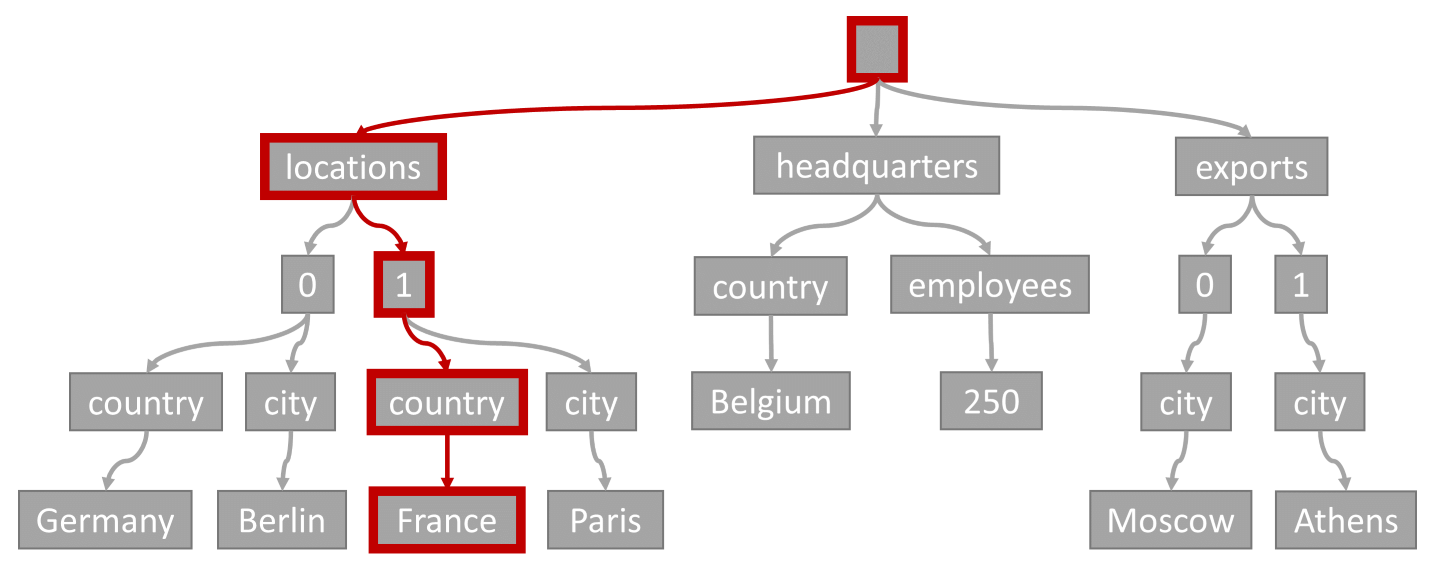
Ponieważ to zapytanie ma filtr równości, po przejściu przez to drzewo możemy szybko zidentyfikować strony indeksu zawierające wyniki zapytania. W takim przypadku aparat zapytań odczytuje strony indeksu zawierające element 1. Wyszukiwanie indeksu jest najbardziej efektywnym sposobem korzystania z indeksu. W przypadku wyszukiwania indeksu odczytujemy tylko niezbędne strony indeksu i załadujemy tylko elementy w wynikach zapytania. W związku z tym czas wyszukiwania indeksu i opłaty za jednostkę ŻĄDANIA z wyszukiwania indeksu są niezwykle niskie, niezależnie od całkowitego woluminu danych.
Dokładne skanowanie indeksu
Rozważ następujące zapytanie:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
Predykat zapytania (filtrowanie elementów, w których istnieje ponad 200 pracowników) można ocenić przy użyciu dokładnego skanowania indeksu ścieżki headquarters/employees . Podczas dokładnego skanowania indeksu aparat zapytań rozpoczyna się od wyszukiwania binarnego odrębnego zestawu możliwych wartości w celu znalezienia lokalizacji wartości 200 dla ścieżki headquarters/employees . Ponieważ wartości dla każdej ścieżki są sortowane w kolejności rosnącej, aparat zapytań może łatwo przeprowadzić wyszukiwanie binarne. Po znalezieniu wartości 200przez aparat zapytań rozpoczyna odczytywanie wszystkich pozostałych stron indeksu (przechodzących w kierunku rosnącym).
Ponieważ aparat zapytań może wykonywać wyszukiwanie binarne, aby uniknąć skanowania niepotrzebnych stron indeksu, dokładne skanowania indeksów zwykle mają porównywalne opóźnienie i opłaty za jednostki RU do indeksowania operacji wyszukiwania.
Rozszerzone skanowanie indeksu
Rozważ następujące zapytanie:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
Predykat zapytania (filtrowanie elementów mających siedzibę w lokalizacji rozpoczynającej się od bez uwzględniania wielkości liter "United") można ocenić za pomocą rozszerzonego skanowania indeksu headquarters/country ścieżki. Operacje, które wykonują rozszerzone skanowanie indeksów, mają optymalizacje, które mogą pomóc uniknąć konieczności skanowania każdej strony indeksu, ale są nieco droższe niż precyzyjne wyszukiwanie binarne skanowania indeksu.
Na przykład podczas oceniania bez uwzględniania StartsWithwielkości liter aparat zapytań sprawdza indeks pod kątem różnych możliwych kombinacji wielkich i małych liter. Ta optymalizacja umożliwia aparatowi zapytań unikanie odczytywania większości stron indeksu. Różne funkcje systemowe mają różne optymalizacje, których mogą używać, aby uniknąć odczytywania każdej strony indeksu, więc są one szeroko kategoryzowane jako rozszerzone skanowanie indeksów.
Pełne skanowanie indeksu
Rozważ następujące zapytanie:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Predykat zapytania (filtrowanie elementów mających siedzibę w lokalizacji zawierającej "United") można ocenić za pomocą skanowania indeksu ścieżki headquarters/country . W przeciwieństwie do dokładnego skanowania indeksu, pełne skanowanie indeksu zawsze skanuje za pomocą odrębnego zestawu możliwych wartości w celu zidentyfikowania stron indeksu, na których znajdują się wyniki. W takim przypadku Contains jest uruchamiany w indeksie. Czas wyszukiwania indeksu i opłata za jednostki RU dla skanowania indeksu wzrasta wraz ze wzrostem kardynalności ścieżki. Innymi słowy, im więcej możliwych odrębnych wartości, które aparat zapytań musi skanować, tym większe opóźnienie i opłaty za jednostki RU związane z wykonywaniem pełnego skanowania indeksu.
Rozważmy na przykład dwie właściwości: town i country. Kardynalność miasta wynosi 5000, a kardynalność country wynosi 200. Poniżej przedstawiono dwa przykładowe zapytania, które mają funkcję systemową Contains , która wykonuje pełne skanowanie indeksu we town właściwości . Pierwsze zapytanie używa więcej jednostek RU niż drugie zapytanie, ponieważ kardynalność miasta jest wyższa niż country.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
Pełne skanowanie
W niektórych przypadkach aparat zapytań może nie być w stanie ocenić filtru zapytania przy użyciu indeksu. W takim przypadku aparat zapytań musi załadować wszystkie elementy z magazynu transakcyjnego, aby ocenić filtr zapytania. Pełne skanowania nie korzystają z indeksu i mają opłatę za jednostkę RU, która zwiększa się liniowo wraz z całkowitym rozmiarem danych. Na szczęście operacje wymagające pełnego skanowania są rzadkie.
Zapytania wyszukiwania wektorowego bez zdefiniowanego indeksu wektora
Jeśli nie zdefiniujesz zasad indeksu wektorowego i użyjesz VectorDistance funkcji systemowej ORDER BY w klauzuli , spowoduje to pełne skanowanie i będzie miało wyższe opłaty za jednostkę RU niż w przypadku zdefiniowania zasad indeksu wektorowego. Podobieństwo, jeśli używasz klasy VectorDistance z wartością logiczną siłową ustawioną na true, i nie ma indeksu zdefiniowanego flat dla ścieżki wektora, nastąpi pełne skanowanie.
Zapytania z złożonymi wyrażeniami filtru
We wcześniejszych przykładach rozważaliśmy tylko zapytania, które miały proste wyrażenia filtru (na przykład zapytania z tylko jednym filtrem równości lub zakresu). W rzeczywistości większość zapytań ma znacznie bardziej złożone wyrażenia filtru.
Rozważ następujące zapytanie:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
Aby wykonać to zapytanie, aparat zapytań musi wykonać wyszukiwanie headquarters/employees indeksu i pełne skanowanie indeksu w programie headquarters/country. Aparat zapytań ma wewnętrzne algorytmy heurystyczne, których używa do oceny wyrażenia filtru zapytania tak wydajnie, jak to możliwe. W takim przypadku aparat zapytań unikałby konieczności odczytywania niepotrzebnych stron indeksu, wykonując najpierw wyszukiwanie indeksu. Jeśli na przykład tylko 50 elementów pasuje do filtru równości, aparat zapytań będzie musiał ocenić Contains tylko na stronach indeksu, które zawierały te 50 elementów. Pełne skanowanie indeksu całego kontenera nie byłoby konieczne.
Wykorzystanie indeksu dla funkcji agregacji skalarnych
Zapytania z funkcjami agregacji muszą polegać wyłącznie na indeksie, aby go używać.
W niektórych przypadkach indeks może zwracać wyniki fałszywie dodatnie. Na przykład podczas oceniania Contains indeksu liczba dopasowań w indeksie może przekraczać liczbę wyników zapytania. Aparat zapytań ładuje wszystkie dopasowania indeksu, oblicza filtr załadowanych elementów i zwraca tylko poprawne wyniki.
W przypadku większości zapytań ładowanie dopasowań indeksu fałszywie dodatniego nie ma zauważalnego wpływu na wykorzystanie indeksu.
Rozważmy na przykład następujące zapytanie:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Funkcja systemowa Contains może zwracać kilka wyników fałszywie dodatnich, więc aparat zapytań musi sprawdzić, czy każdy załadowany element jest zgodny z wyrażeniem filtru. W tym przykładzie aparat zapytań może wymagać ładowania tylko kilku dodatkowych elementów, więc wpływ na użycie indeksu i opłaty za jednostki RU jest minimalny.
Jednak zapytania z funkcjami agregacji muszą polegać wyłącznie na indeksie, aby go używać. Rozważmy na przykład następujące zapytanie zagregowane Count :
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Podobnie jak w pierwszym przykładzie funkcja systemowa Contains może zwracać kilka wyników fałszywie dodatnich. SELECT * W przeciwieństwie do zapytania zapytanie nie może jednak Count ocenić wyrażenia filtru na załadowanych elementach, aby zweryfikować wszystkie dopasowania indeksu. Zapytanie Count musi polegać wyłącznie na indeksie, więc jeśli istnieje prawdopodobieństwo, że wyrażenie filtru zwraca wyniki fałszywie dodatnie, aparat zapytań ucieka się do pełnego skanowania.
Zapytania z następującymi funkcjami agregacji muszą polegać wyłącznie na indeksie, więc ocena niektórych funkcji systemowych wymaga pełnego skanowania.
Następne kroki
Przeczytaj więcej na temat indeksowania w następujących artykułach: