Elastyczne skalowanie konta usługi Azure Cosmos DB dla usługi Apache Cassandra
DOTYCZY: ![]() Kasandra
Kasandra
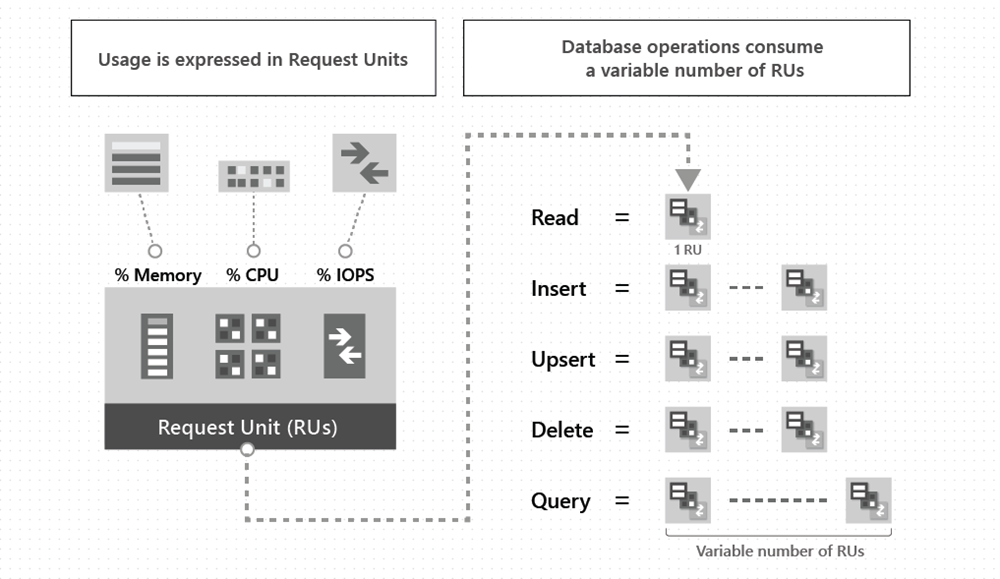
Istnieje wiele opcji, które umożliwiają eksplorowanie elastycznego charakteru usługi Azure Cosmos DB dla bazy danych Apache Cassandra. Aby zrozumieć, jak efektywnie skalować w usłudze Azure Cosmos DB, ważne jest, aby zrozumieć, jak aprowizować odpowiednią ilość jednostek żądań (RU/s), aby uwzględnić wymagania dotyczące wydajności w systemie. Aby dowiedzieć się więcej o jednostkach żądań, zobacz artykuł Jednostki żądań .
W przypadku interfejsu API dla bazy danych Cassandra można pobrać opłatę za jednostkę żądania dla poszczególnych zapytań przy użyciu zestawów SDK platformy .NET i języka Java. Jest to przydatne podczas określania ilości jednostek RU/s, które należy aprowizować w usłudze.
Obsługa ograniczania szybkości (błędy 429)
Usługa Azure Cosmos DB zwróci błędy z ograniczoną szybkością (429), jeśli klienci zużywają więcej zasobów (RU/s) niż ilość aprowizowaną. Interfejs API dla bazy danych Cassandra w usłudze Azure Cosmos DB tłumaczy te wyjątki na przeciążone błędy w natywnym protokole Cassandra.
Jeśli system nie jest wrażliwy na opóźnienia, może wystarczyć do obsługi ograniczania szybkości przepływności przy użyciu ponownych prób. Zobacz Przykłady kodu Java dla wersji 3 i wersji 4 sterowników języka Java apache Cassandra, aby dowiedzieć się, jak obsłużyć ograniczanie szybkości w sposób niewidoczny. Te przykłady implementują niestandardową wersję domyślnych zasad ponawiania prób cassandra w języku Java. Możesz również użyć rozszerzenia Spark do obsługi ograniczania szybkości. W przypadku korzystania z platformy Spark upewnij się, że postępuj zgodnie z naszymi wskazówkami dotyczącymi optymalizowania konfiguracji przepływności łącznika Spark.
Zarządzanie skalowaniem
Jeśli musisz zminimalizować opóźnienie, istnieje spektrum opcji zarządzania przepływnością skalowania i aprowizacji (RU) w interfejsie API dla systemu Cassandra:
- Ręcznie przy użyciu witryny Azure Portal
- Programowo przy użyciu funkcji płaszczyzny sterowania
- Programowo przy użyciu poleceń języka CQL z określonym zestawem SDK
- Dynamiczne skalowanie przy użyciu skalowania automatycznego
W poniższych sekcjach opisano zalety i wady każdego podejścia. Następnie możesz zdecydować się na najlepszą strategię równoważenia potrzeb związanych ze skalowaniem systemu, ogólnym kosztem i wydajnością rozwiązania.
Korzystanie z witryny Azure Portal
Zasoby można skalować na koncie usługi Apache Cassandra w usłudze Azure Cosmos DB przy użyciu witryny Azure Portal. Aby dowiedzieć się więcej, zobacz artykuł Aprowizacja przepływności w kontenerach i bazach danych. W tym artykule wyjaśniono względne korzyści wynikające z ustawiania przepływności na poziomie bazy danych lub kontenera w witrynie Azure Portal. Terminy "database" i "container" wymienione w tych artykułach są mapować odpowiednio na "keyspace" i "table" dla interfejsu API dla bazy danych Cassandra.
Zaletą tej metody jest to, że jest to prosty prosty sposób zarządzania pojemnością przepływności w bazie danych. Jednak wadą jest to, że w wielu przypadkach podejście do skalowania może wymagać, aby niektóre poziomy automatyzacji były zarówno ekonomiczne, jak i wysokiej wydajności. W następnych sekcjach opisano odpowiednie scenariusze i metody.
Korzystanie z płaszczyzny sterowania
Interfejs API usługi Azure Cosmos DB dla rozwiązania Cassandra zapewnia możliwość programowego dostosowywania przepływności przy użyciu różnych funkcji płaszczyzny sterowania. Aby uzyskać wskazówki i przykłady, zobacz artykuły dotyczące usługi Azure Resource Manager, programu PowerShell i interfejsu wiersza polecenia platformy Azure.
Zaletą tej metody jest to, że można zautomatyzować skalowanie w górę lub w dół zasobów na podstawie czasomierza, aby uwzględnić szczytową aktywność lub okresy niskiej aktywności. Zapoznaj się z naszym przykładem tutaj , aby dowiedzieć się, jak to zrobić przy użyciu usługi Azure Functions i programu PowerShell.
Wadą tego podejścia może być to, że nie można reagować na nieprzewidywalne potrzeby skalowania w czasie rzeczywistym. Zamiast tego może być konieczne wykorzystanie kontekstu aplikacji w systemie na poziomie klienta/zestawu SDK lub skalowanie automatyczne.
Używanie zapytań CQL z określonym zestawem SDK
System można skalować dynamicznie przy użyciu kodu, wykonując polecenia ALTER języka CQL dla danej bazy danych lub kontenera.
Zaletą tego podejścia jest możliwość dynamicznego reagowania na potrzeby skalowania i w niestandardowy sposób odpowiadający aplikacji. Dzięki temu podejściu można nadal korzystać ze standardowych opłat ru/s i stawek. Jeśli potrzeby skalowania systemu są w większości przewidywalne (około 70% lub więcej), użycie zestawu SDK z językiem CQL może być bardziej opłacalną metodą automatycznego skalowania niż użycie autoskalowania. Wadą tego podejścia jest to, że wdrożenie ponownych prób może być dość złożone, podczas gdy ograniczanie szybkości może zwiększyć opóźnienie.
Korzystanie z aprowizowanej przepływności autoskalowania
Oprócz standardowego (ręcznego) lub programowego sposobu aprowizowania przepływności można również skonfigurować kontenery usługi Azure Cosmos DB w aprowizowanej przepływności autoskalowania. Automatyczne skalowanie będzie automatycznie i natychmiast skalowane do potrzeb związanych z zużyciem w określonych zakresach jednostek ŻĄDANIA bez naruszania umów SLA. Aby dowiedzieć się więcej, zobacz artykuł Tworzenie kontenerów i baz danych usługi Azure Cosmos DB w autoskalowania .
Zaletą tego podejścia jest to, że najłatwiej jest zarządzać potrzebami skalowania w systemie. Nie będzie ona stosować ograniczania szybkości w skonfigurowanych zakresach jednostek RU. Wadą jest to, że jeśli potrzeby skalowania w systemie są przewidywalne, skalowanie automatyczne może być mniej opłacalnym sposobem obsługi potrzeb skalowania niż użycie płaszczyzny sterowania na zamówienie lub metod na poziomie zestawu SDK wymienionych powyżej.
Aby ustawić lub zmienić maksymalną przepływność (RU) na potrzeby autoskalowania przy użyciu języka CQL, użyj następującej wartości (zastępując odpowiednio nazwę przestrzeni kluczy/tabeli):
# to set max throughput (RUs) for autoscale at keyspace level:
create keyspace <keyspace name> WITH cosmosdb_autoscale_max_throughput=5000;
# to alter max throughput (RUs) for autoscale at keyspace level:
alter keyspace <keyspace name> WITH cosmosdb_autoscale_max_throughput=4000;
# to set max throughput (RUs) for autoscale at table level:
create table <keyspace name>.<table name> (pk int PRIMARY KEY, ck int) WITH cosmosdb_autoscale_max_throughput=5000;
# to alter max throughput (RUs) for autoscale at table level:
alter table <keyspace name>.<table name> WITH cosmosdb_autoscale_max_throughput=4000;
Następne kroki
- Wprowadzenie do tworzenia interfejsu API dla konta, bazy danych i tabeli Cassandra przy użyciu aplikacji Java