Aprowizuj analizę w skali chmury
Proces wdrażania strefy docelowej zarządzania danymi
Zespół operacyjny platformy danych jest odpowiedzialny za wdrożenie strefy docelowej zarządzania danymi. Strefa docelowa zarządzania danymi powinna mieć własne repozytorium obsługiwane przez zespół operacyjny platformy danych.
Ostrożność
Utwórz i wdróż strefę docelową zarządzania danymi przed wdrożeniem dowolnej strefy docelowej danych.
Proces wdrażania strefy docelowej danych
Zespoły mogą używać szablonów udostępnianych przez zespół operacyjny platformy danych, aby uniknąć rozpoczynania od podstaw dla każdego zasobu. Zalecamy użycie wzorca rozgałęziania, aby zautomatyzować wdrażanie nowej strefy startowej.
Na przykład zespół operacyjny strefy docelowej danych żąda nowej strefy docelowej danych przy użyciu narzędzia do zarządzania IT lub usługi Power Apps. Po zatwierdzeniu żądania uruchom następujący przepływ pracy przy użyciu parametrów żądania:
- Wdróż nową subskrypcję dla nowej strefy docelowej danych.
- Rozgałęź główną gałąź szablonu strefy docelowej danych, aby utworzyć nowe repozytorium.
- Utwórz połączenie usługi w nowym repozytorium.
- Zaktualizuj parametry w nowym repozytorium na podstawie parametrów z żądania.
- Utwórz pipeline wdrożeniowy do wdrażania usług, które są inicjowane poprzez zatwierdzenie zaktualizowanych parametrów.
- Powiadom zespół operacyjny strefy docelowej danych, że nowa strefa docelowa jest dostępna.
Zespół operacyjny strefy docelowej danych może teraz zmienić lub dodać szablony usługi Azure Resource Manager.
Ten przepływ pracy można zautomatyzować przy użyciu wielu zestawów usług na platformie Azure. Obsługa niektórych kroków, takich jak zmiana nazwy parametrów w plikach parametrów przy użyciu potoków ciągłej integracji/ciągłego wdrażania. Inne kroki można wykonać przy użyciu innych narzędzi orkiestracji przepływu pracy, takich jak Logic Apps.
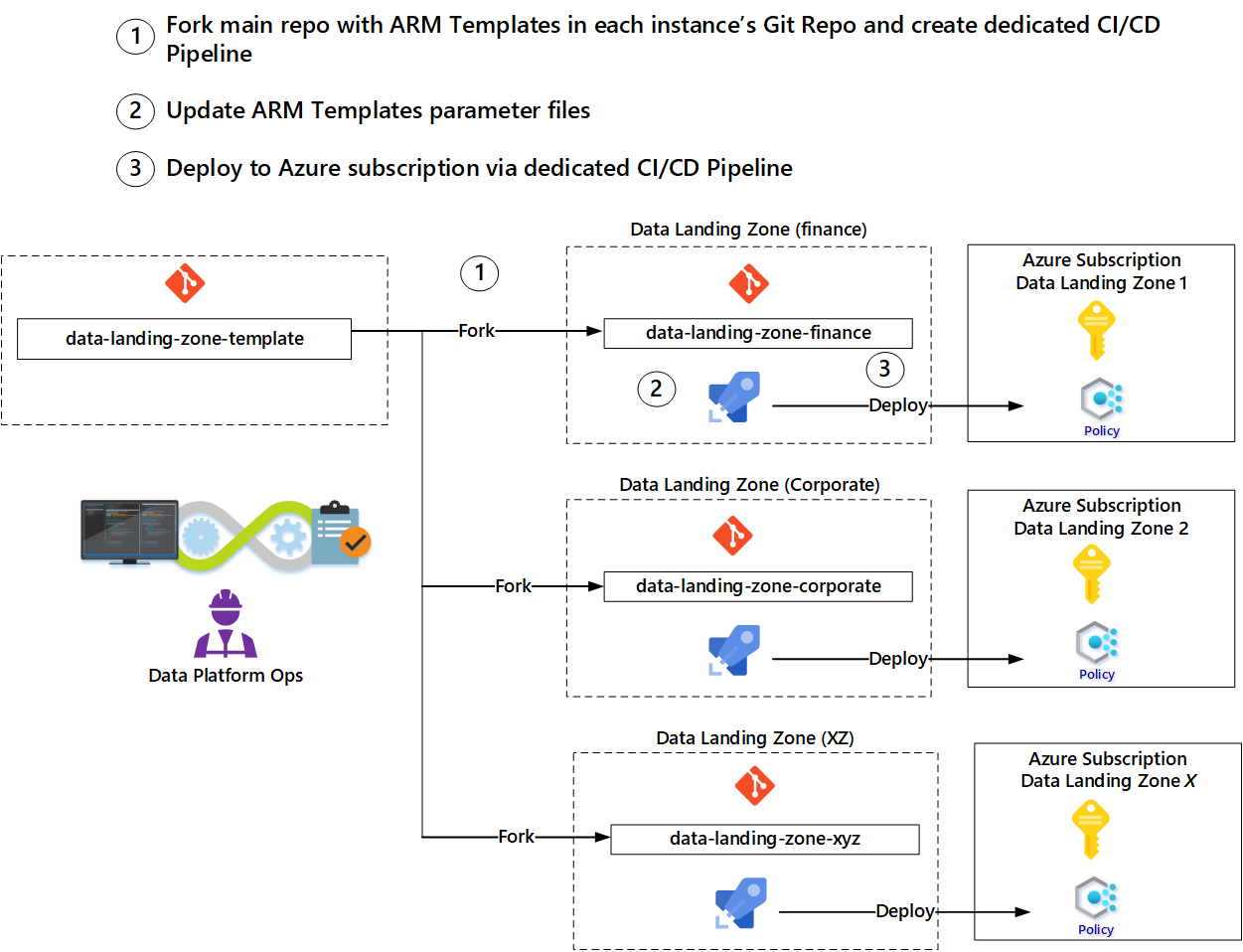
Wzorzec rozwidlenia umożliwia zespołom aktualizowanie szablonów z oryginalnych szablonów używanych do ich rozwidlenia. Ponadto, jeśli w repozytoriach szablonów są wprowadzane ulepszenia lub nowe funkcje, zespoły operacyjne mogą przenieść je do swojego fork'a.
Zastosuj najlepsze rozwiązania dotyczące repozytoriów, takie jak:
- Zabezpiecz gałąź główną.
- Użyj gałęzi dla zmian, aktualizacji i ulepszeń.
- Zdefiniuj właścicieli kodu, którzy zatwierdzają żądania ściągnięcia przed scaleniem zmian w gałęzi głównej.
- Weryfikowanie gałęzi za pomocą testów automatycznych.
- Ogranicz liczbę akcji i członków zespołu, którzy mogą wyzwalać potoki kompilacji i wydania.
Napiwek
Koordynacja działań między zespołami w celu zapewnienia, że ulepszenia lub nowe funkcje w oryginalnych szablonach są replikowane we wszystkich wystąpieniach stref lądowania danych. Zespoły ds. operacji mogą wciągnąć oryginalne zmiany szablonu do swojego rozwidlenia.
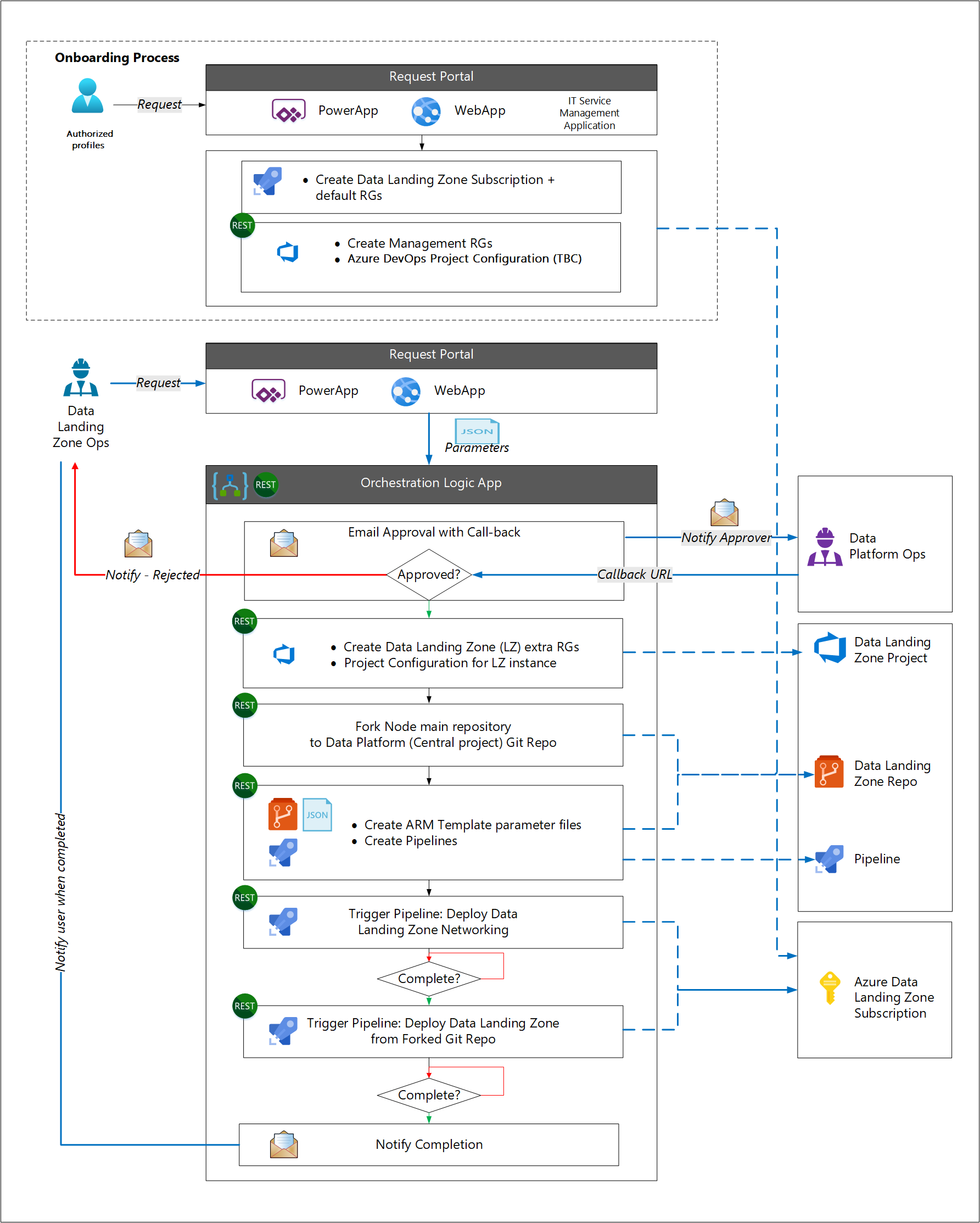
Proces wdrażania jest oddzielony od procesu wdrażania strefy lądowania danych. Ta separacja jest oparta na założeniu, że większość organizacji ma standardowy proces wdrażania subskrypcji platformy Azure w ramach modelu operacyjnego w chmurze. Proces wdrażania pracowników wdraża standardowe składniki firmowe (takie jak narzędzie do zarządzania usługami IT innej firmy). Składniki specyficzne dla strefy docelowej danych są wdrażane w następnej kolejności.
Brak dostępnych interfejsów API usługi Git do klonowania/aktualizowania/zatwierdzania/wypychania w proponowanym rozwiązaniu automatyzacji. Dlatego naszym podejściem jest użycie konta usługi Azure Automation zawierającego elementy Runbook programu PowerShell, które:
- Konfigurowanie strefy docelowej danych
- Rozwidlenie głównego repozytorium do repozytorium Git dla platformy danych
- Skonfiguruj ustawienia podsieci dla strefy lądowania danych
- Konfigurowanie identyfikatora Entra firmy Microsoft
Runbooki używają funkcji Git z modułu GitAutomation PowerShell do obsługi repozytoriów Git. Po zainstalowaniu tego modułu na koncie usługi Azure Automation użytkownicy mogą wykonywać operacje tworzenia, klonowania, wykonywania zapytań, wypychania, ściągania i zatwierdzania w repozytoriach Git. Na poniższej ilustracji przedstawiono moduł GitAutomation zainstalowany na koncie usługi Azure Automation:

Użyj funkcji Copy-GitRepository z modułu GitAutomation, aby sklonować główne repozytorium Git z adresu URL określonego przez URL do ścieżki git platformy danych określonej przez DestinationPath.
Takie podejście do wdrożenia strefy docelowej danych jest elastyczne, zapewniając jednocześnie zgodność akcji z wymaganiami organizacji. Zarządzanie cyklem życia jest włączone przez zastosowanie nowych funkcji lub optymalizacji z oryginalnych szablonów.
Proces wdrażania aplikacji danych
Po utworzeniu strefy lądowania danych, wdrażanie może rozpocząć się dla zespołów ds. aplikacji danych. Zespoły ds. operacji platformy danych lub strefy docelowej danych udzielają zatwierdzenia wdrożenia.
Wdrożenie odbywa się bezpośrednio przy użyciu narzędzi DevOps lub wywoływane za pośrednictwem potoków/przepływów pracy uwidocznionych jako interfejsy API. Podobnie jak w przypadku strefy docelowej danych wdrożenie rozpoczyna się od rozwidlenia oryginalnego repozytorium aplikacji danych.
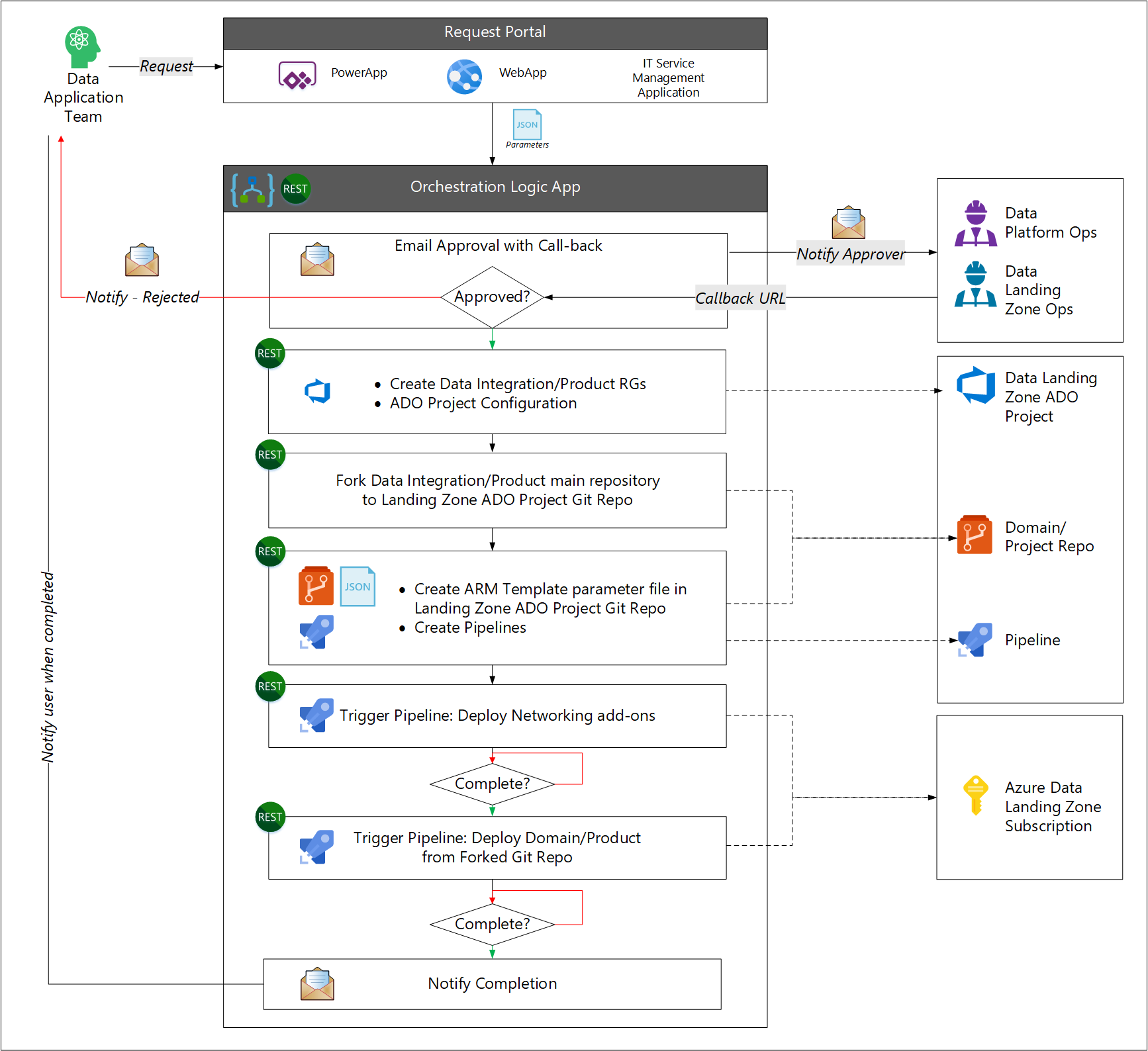
- Użytkownik wysyła żądanie dotyczące nowych usług aplikacji danych.
- Proces przepływu pracy żąda zatwierdzenia przez zespół operacyjny platformy danych lub strefy docelowej danych.
- Przepływ pracy wywołuje interfejs API zarządzania usługami IT, aby utworzyć wymagane grupy zasobów i utworzyć połączenie usługi Azure DevOps. Proces roboczy przypisuje zespół do projektu Azure DevOps.
- Przepływ pracy rozgałęzia oryginalne repozytorium aplikacji danych, aby utworzyć docelowy projekt w Azure DevOps.
- Przepływ pracy tworzy plik i potoki parametrów szablonu usługi Azure Resource Manager.
- Następnie przepływ pracy uruchamia potok platformy Azure w celu utworzenia wymagań sieciowych, oraz kolejnego potoku platformy Azure w celu wdrożenia usług aplikacji danych.
- Workflow powiadamia użytkownika po ukończeniu.
Wskazówka
Jeśli dopiero zaczynasz korzystać z metodyki DataOps, zapoznaj się z DataOps dla nowoczesnego magazynu danych praktyczne laboratorium w Centrum architektury platformy Azure. W scenariuszu laboratorium opisano fikcyjne biuro planowania miasta, które może korzystać z tego rozwiązania wdrożeniowego. Rozwiązanie wdrożeniowe udostępnia kompleksowe potoki danych, które są zgodne ze wzorcem architektury nowoczesnego magazynu danych, wraz z odpowiednimi procesami DevOps i DataOps, w celu oceny korzystania z parkingu i podejmowania świadomych decyzji biznesowych.
Streszczenie
Powyższe wzorce zapewniają kontrolę, elastyczność, samoobsługę i zarządzanie cyklem życia zasad.
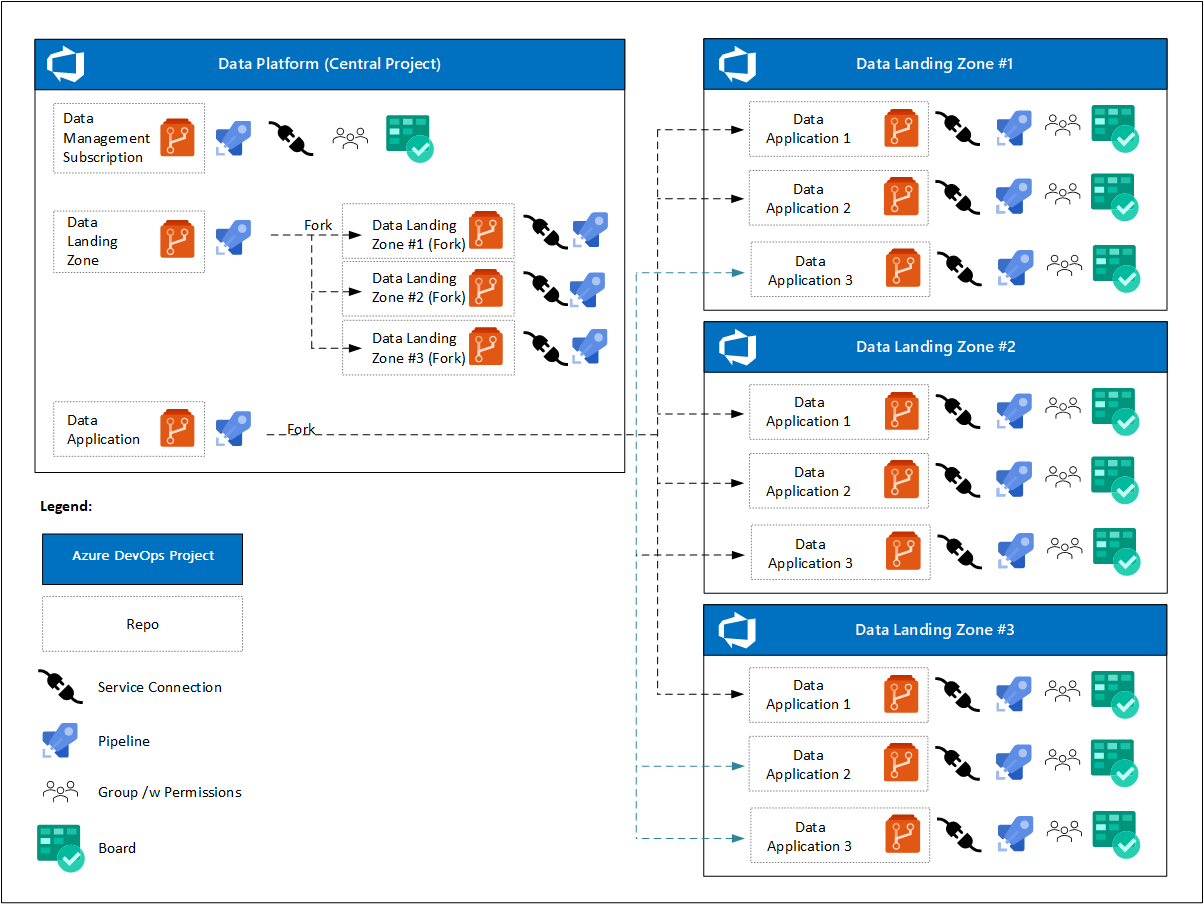
Na początku projektu platforma danych ma jeden projekt usługi Azure DevOps z co najmniej jedną usługą Azure Boards. Poszczególne zespoły DevOps koncentrują się na:
- Jedno repozytorium dla strefy docelowej zarządzania danymi, potoków oraz połączenia usługowego ze środowiskiem chmurowym.
- Jedno repozytorium szablonów dla strefy lądowania danych, potoki do wdrażania instancji strefy lądowania danych oraz połączenia usług z środowiskami chmurowymi.
- Jedno repozytorium szablonów dla usług produktów danych, potoków w celu wdrożenia wystąpienia produktu danych i połączeń usług ze środowiskami w chmurze. Te połączenia są forkowane ze strefy przechwytywania danych Azure DevOps Projects.
Po wdrożeniu stref docelowych danych analiza w skali chmury określa, że:
- Każda strefa docelowa danych będzie miała własny projekt usługi Azure DevOps z co najmniej jedną usługą Azure Boards.
- Dla każdej aplikacji danych, po zatwierdzeniu żądania, tworzone jest rozwidlenie projektu Azure DevOps w strefie lądowania danych.
- Każda aplikacja danych obejmuje:
- Połączenie z usługą.
- Zarejestrowany potok.
- Zespół DevOps z dostępem do tablicy i repozytorium platformy Azure.
- Inny zestaw zasad dla forku repozytorium.
Aby kontrolować wdrażanie aplikacji danych, wykonaj następujące rozwiązania:
- Zespół operacyjny strefy danych odpowiada za główną gałąź repozytorium i zabezpiecza ją.
- Tylko gałąź główna służy do wdrażania w środowiskach testowych i produkcyjnych.
- Gałęzie funkcji mogą być wdrażane w środowiskach deweloperskich.
- Gałęzie funkcjonalności są własnością zespołów DataOps. Są one używane do testowania nowych lub zmodyfikowanych funkcji.
- Zespoły ds. operacji DataOps mogą scalać gałęzie funkcji z innymi gałęziami funkcji bez zatwierdzania.
- Zespoły DataOps tworzą pull request w celu scalenia gałęzi funkcjonalnych z gałęzią główną, a zespół operacyjny strefy lądowania danych zatwierdza.
- Nowe funkcje lub ulepszenia oryginalnych szablonów są scalane z rozwidlonym repozytorium w celu ich aktualizowania.