Procesy nadzoru nad danymi
Istnieją cztery kategorie procesów nadzoru nad danymi.
| Kategoria procesów | Procesy |
|---|---|
| procesy odkrywania danych, aby zrozumieć ekosystem danych | Proces odnajdywania, mapowania i katalogowania jednostek danych Proces odkrywania profili danych w celu określenia jakości danych Proces odkrywania i zarządzania klasyfikacją danych wrażliwych Proces odnajdywania danych na potrzeby analizy CRUD, na przykład z plików dziennika, w celu zrozumienia użycia i konserwacji danych, takich jak dane główne w przedsiębiorstwie |
| procesy definicji ładu danych | Tworzenie i utrzymywanie wspólnego słownictwa biznesowego w słowniku biznesowym, w tym definiowanie jednostek danych, takich jak dane główne, nazwy atrybutów danych, reguły integralności danych i prawidłowe formaty. Definiowanie danych referencyjnych w celu standaryzacji zestawów kodu w przedsiębiorstwie Definiowanie schematów klasyfikacji zarządzania danymi w celu oznaczania danych i określania, jak nimi zarządzać. Definiowanie zasad i reguł ładu danych w celu zarządzania cyklami życia jednostek danych i dokumentów Definiowanie metryk i progu sukcesu |
| zasady ładu danych i procesy wymuszania reguł | Proces automatyzowania aplikacji i wymuszania zasad i reguł ładu danych Proces ręcznego stosowania i wymuszania zasad i reguł Oparte na zdarzeniach, na żądanie i uruchamiane czasowo (wsadowe) procesy nadzoru danych, opublikowane jako usługi, które można wywołać w celu zarządzania: Pozyskiwanie danych — katalogowanie, klasyfikacja, przypisywanie właściciela i przechowywanie Jakość danych Zabezpieczenia dostępu do danych Prywatność danych Na przykład użycie danych, w tym udostępnianie i zapewnienie, że licencjonowane dane są używane tylko do zatwierdzonych celów Konserwacja danych, taka jak dane główne Przechowywanie danych Synchronizacja danych głównych i danych referencyjnych |
| Monitorowanie procesów | Monitorowanie i inspekcja aktywności użycia danych, jakości danych, zabezpieczeń dostępu do danych, prywatności danych, konserwacji danych i przechowywania danych Monitorowanie wykrywania i rozwiązywania naruszeń reguł zasad |
Wspólne słownictwo biznesowe należy zdefiniować w słowniku biznesowym w katalogu danych.
Grupy robocze ds. zarządzania danymi planują i rozwijają definiowanie danych oraz ulepszanie określonych domen danych (na przykład klienta lub dostawcy); informowanie zarządu ds. ładu danych o postępach; oraz zarządzanie nadzorem w całym przedsiębiorstwie w obrębie określonej domeny. Każda grupa robocza powinna podjąć odpowiedzialność za zdefiniowanie określonej jednostki danych lub obszaru podmiotu danych, takiego jak wiele powiązanych jednostek. Wiele jednostek danych w zasobach danych, wraz z politykami i regułami, można następnie przetwarzać równolegle. Aby uzyskać informacje, proszę zobaczyć Role zarządzania danymi i obowiązki
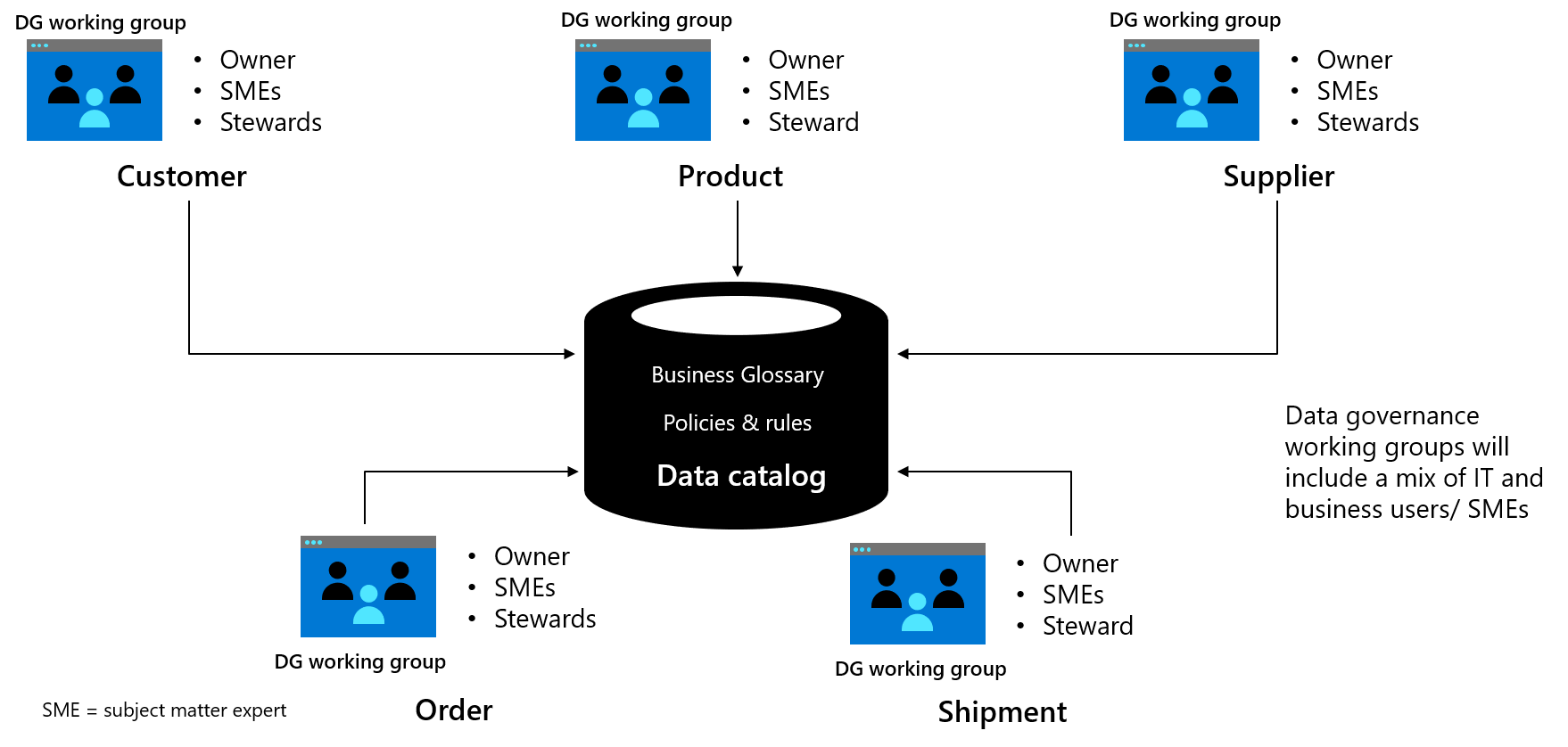 Rysunek 1. Przykładowa grupa robocza ładu danych
Rysunek 1. Przykładowa grupa robocza ładu danych
Integracja słownika biznesowego katalogu z innymi technologiami jest następnie konieczna do uzyskania jednolitego nazewnictwa danych w całych technologiach. Przykłady innych technologii, które można zintegrować, to:
- Narzędzia wyodrębniania, przekształcania, ładowania (ETL)
- Narzędzia do modelowania danych
- Narzędzia do analizy biznesowej, systemy zarządzania bazami danych
- Zarządzanie danymi głównymi
- Narzędzia do wirtualizacji danych
- Narzędzia programistyczne
Dobrym rozwiązaniem do tworzenia wspólnego słownictwa biznesowego jest opracowanie modelu koncepcji danych. Ten model używa podejścia od góry do identyfikowania pojęć dotyczących danych, które mogą być używane jako jednostki danych w typowym słownictwie biznesowym. Różne grupy robocze ds. zarządzania danymi można następnie przypisać do każdego pojęcia danych (jednostki) lub grupy powiązanych pojęć dotyczących danych (obszaru tematycznego). Te zespoły robocze są odpowiedzialne za zarządzanie różnymi jednostkami danych w całym środowisku.
Podczas tworzenia wspólnego słownictwa biznesowego można użyć oprogramowania wykazu danych, aby automatycznie wykryć, jakie dane istnieją w wielu magazynach danych. To oprogramowanie pomaga zidentyfikować wszystkie atrybuty skojarzone z określonymi jednostkami danych, co jest podejściem do dołu.
Wiele grup roboczych może szybko utworzyć wspólne słownictwo biznesowe, łącząc podejście odgórne modelu danych koncepcyjnych z podejściem oddolnym zautomatyzowanego odkrywania danych.
Używanie wykazu danych do automatycznego odnajdywania danych umożliwia mapowanie różnych danych na wspólne słownictwo. Wykaz danych może pomóc zrozumieć, gdzie dane poszczególnych jednostek danych w słowniku biznesowym znajdują się w całym przedsiębiorstwie.
Zasady i reguły do zarządzania danymi w różnych punktach cyklu życia
Zasady ładu danych opisują zestaw reguł kontroli integralności, jakości, bezpieczeństwa dostępu, prywatności i przechowywania danych. Istnieją różne typy zasad, które obejmują:
- Zasady integralności danych, takie jak prawidłowe wartości, integralność referencyjna.
- Zasady jakości danych z standaryzacją danych, czyszczeniem i dopasowywaniem reguł.
- Zasady ochrony danych z zasadami zabezpieczeń dostępu i prywatności danych.
- Zasady przechowywania danych do zarządzania cyklem życia przy użyciu reguł przechowywania, archiwizacji i tworzenia kopii zapasowych. Aby zarządzać tymi samymi danymi w różnych jurysdykcjach prawnych, może być konieczne zastosowanie wielu wersji zasad.
System klasyfikacji poufności danych ma pięć poziomów klasyfikacji:
- Publiczny
- Tylko do użytku wewnętrznego
- Poufny
- Poufne dane osobowe
- Ograniczone
Zarządzanie danymi przez połączenie tego schematu klasyfikacji z zasadami i regułami. Użyj każdego z pięciu poziomów, aby oznaczyć dane, takie jak poufne dane osobowe. Tworząc reguły dotyczące poufnych danych osobowych i dołączając te reguły do zasad, należy utworzyć zasady dotyczące poufnych danych osobowych. Zasady można dołączyć do etykiety poufnych danych osobowych, a następnie dołączyć etykietę poufnych danych osobowych do danych. W ten sposób wszystkie dane oznaczone jako poufne dane osobowe podlegają tym samym zasadom i regułom. Ten proces jest znany jako zarządzanie zasadami opartymi na tagach. Jest to elastyczne, ponieważ pojedyncza reguła lub zasady mogą zostać niezależnie zmienione. Wszystkie dane oznaczone poufnymi danymi osobowymi podlegają nowym regułom. Podobnie etykieta danych wrażliwych osobowych może zostać odłączona od danych i użyta etykieta poufna. W takim przypadku dane natychmiast podlegają nowemu zestawowi zasad i reguł skojarzonych z etykietą poufne.
Po zdefiniowaniu zasad i reguł w katalogu danych dla każdej klasy w schemacie klasyfikacji zarządzania danymi, mogą być przekazane do innych technologii z katalogu danych, za pośrednictwem interfejsów API, aby je wymusić. Zamiast tego wspólna platforma zarządzania danymi, która może łączyć się z wieloma magazynami danych, może je potencjalnie wymusić.
Następnie powinno być możliwe monitorowanie jakości danych, prywatności, zabezpieczeń dostępu, użycia, konserwacji i przechowywania określonych jednostek danych w całym cyklu życia.