Agnostyczny silnik wczytywania danych
W tym artykule wyjaśniono, jak zaimplementować niezależne od specyfiki danych scenariusze działania aparatu pozyskiwania danych, korzystając z połączenia PowerApps, Azure Logic Apps oraz zadań kopiowania kierowanych metadanymi w usłudze Azure Data Factory.
Agnostyczne względem danych scenariusze silnika pozyskiwania danych zwykle koncentrują się na umożliwieniu nietechnicznym użytkownikom (niedata-inżynierom) publikowania zasobów danych w Data Lake celem dalszego przetwarzania. Aby zaimplementować ten scenariusz, musisz mieć funkcje wprowadzania, które umożliwiają:
- Rejestracja zasobu danych
- Aprowizowanie przepływu pracy i przechwytywanie metadanych
- Planowanie pozyskiwania
Zobaczysz, jak te możliwości współdziałają:
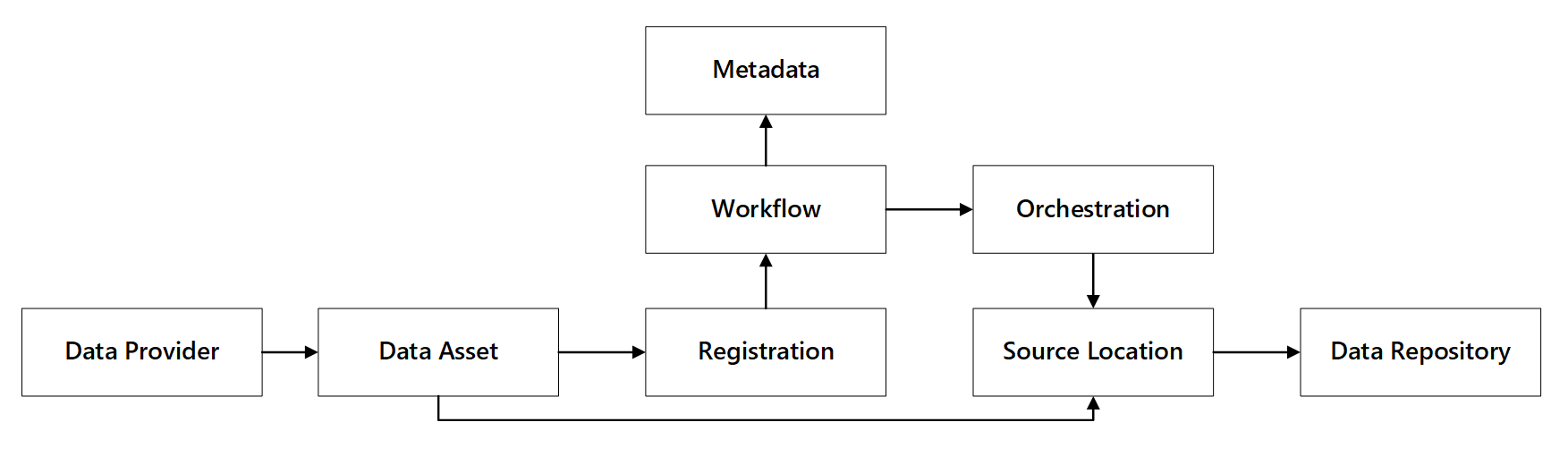
Rysunek 1: Interakcje możliwości rejestrowania danych.
Na poniższym diagramie pokazano, jak zaimplementować ten proces przy użyciu kombinacji usług platformy Azure:
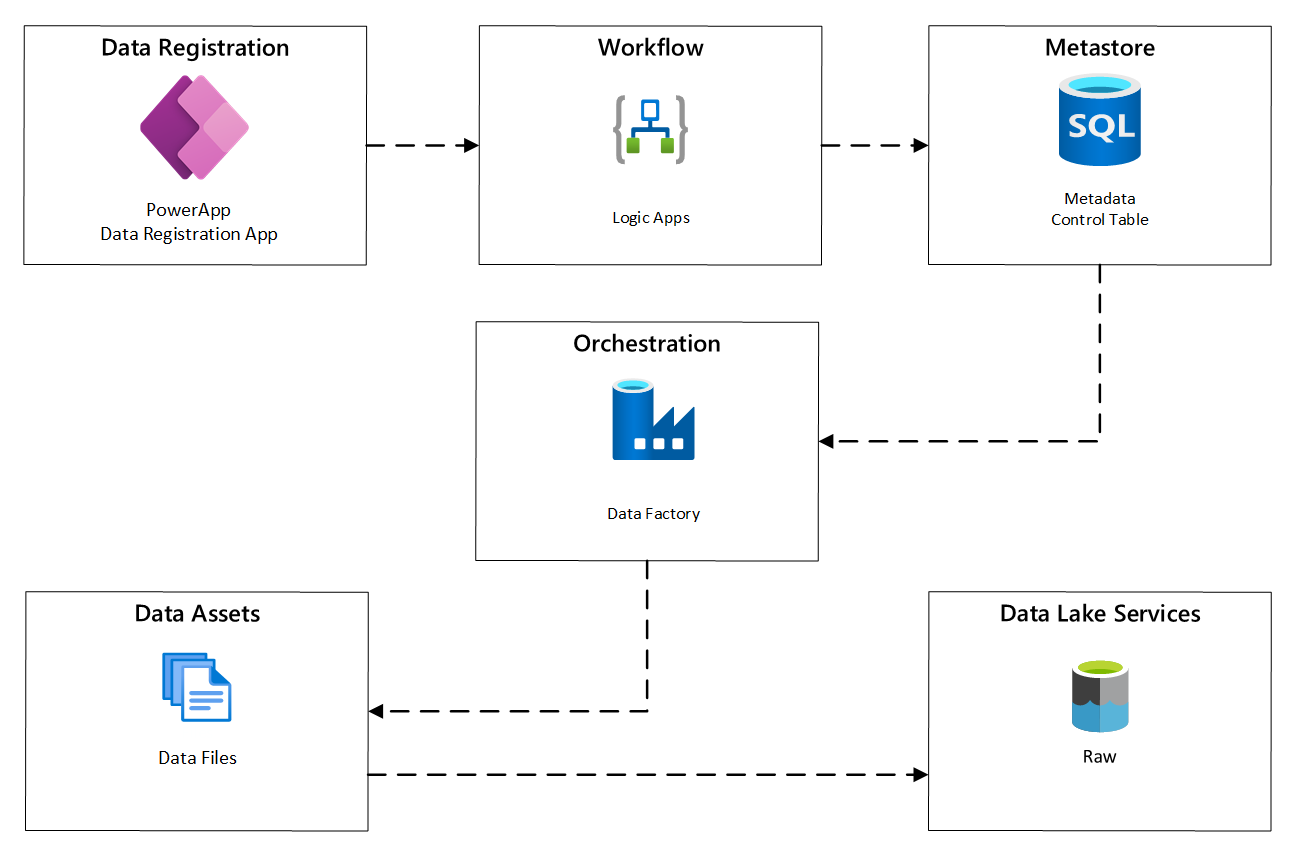
Rysunek 2. Zautomatyzowany proces integracji.
Rejestracja zasobu danych
Aby zapewnić metadane używane do automatycznego pozyskiwania danych, potrzebujesz rejestracji zasobów danych. Przechwycone informacje zawierają:
- Informacje techniczne: Nazwa zasobu danych, system źródłowy, typ, format i częstotliwość.
- Informacje o zarządzaniu: właściciel, osoby odpowiedzialne za nadzór, widoczność (na potrzeby odnajdywania) i poufność.
Usługa PowerApps służy do przechwytywania metadanych opisujących każdy zasób danych. Użyj aplikacji opartej na modelu, aby wprowadzić informacje, które zostaną zapisane w niestandardowej tabeli usługi Dataverse. Po utworzeniu lub zaktualizowaniu metadanych w usłudze Dataverse wyzwala on przepływ zautomatyzowanej chmury, który wywołuje dalsze kroki przetwarzania.
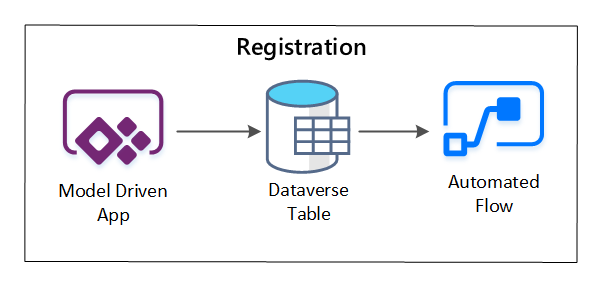
Rysunek 3. Rejestracja zasobów danych.
Udostępnianie przepływu pracy / przechwytywanie metadanych
Na etapie przepływu pracy udostępniania weryfikujesz i zapisujesz w magazynie metadanych dane zebrane na etapie rejestracji. Są wykonywane zarówno kroki weryfikacji technicznej, jak i biznesowej, w tym:
- Walidacja wejściowego źródła danych
- Inicjowanie przepływu pracy zatwierdzania
- Przetwarzanie logiki w celu zapewnienia trwałości metadanych w magazynie metadanych
- Inspekcja działań
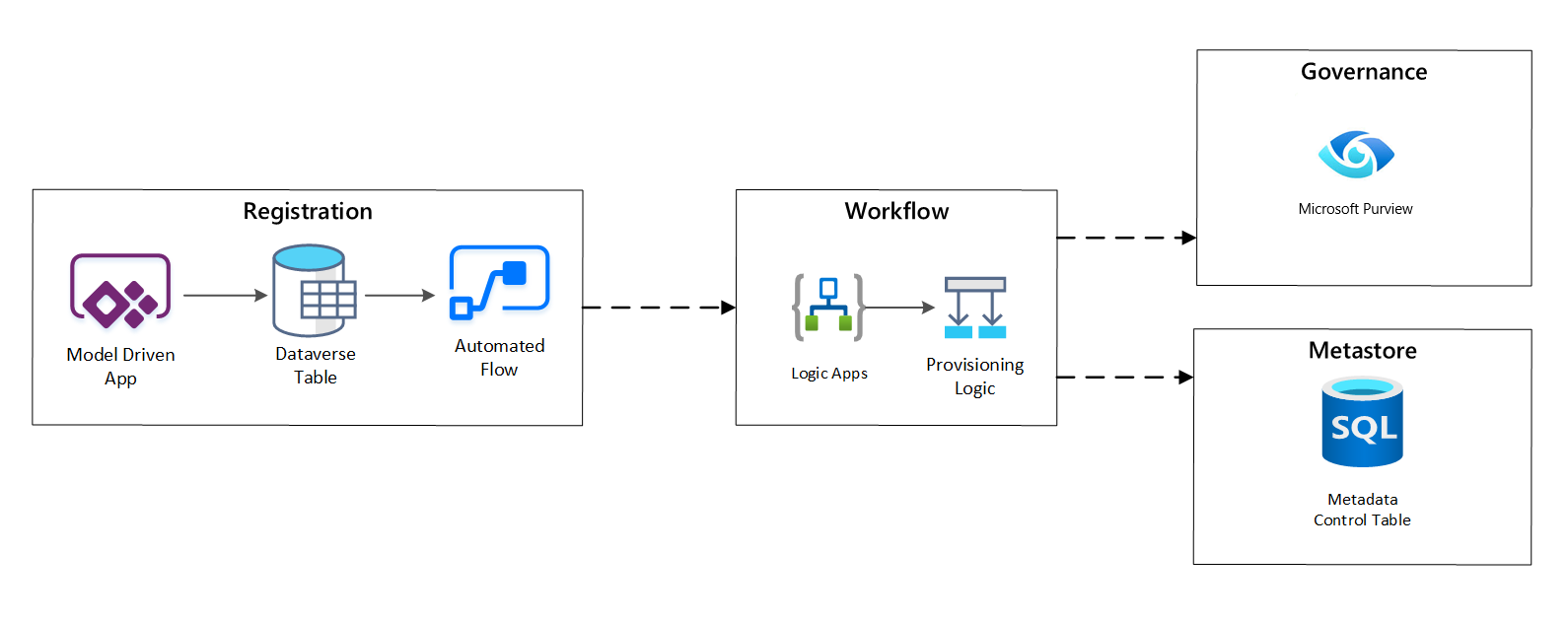
Rysunek 4. Proces rejestracji.
Po zatwierdzeniu żądań pozyskiwania przepływ pracy używa interfejsu API REST usługi Microsoft Purview do wstawiania źródeł do usługi Microsoft Purview.
Szczegółowy przepływ pracy dotyczący dołączania produktów danych
diagram 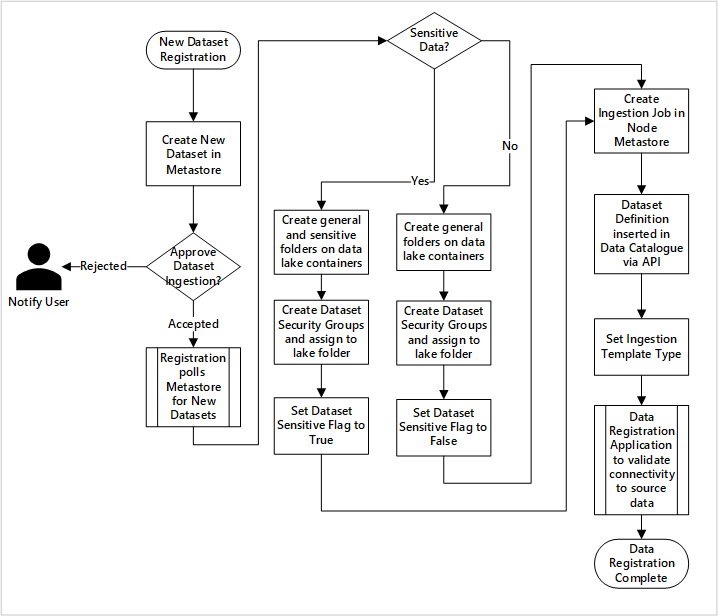
Rysunek 5. Jak nowe zestawy danych są pozyskiwane (zautomatyzowane).
Rysunek 5 przedstawia szczegółowy proces rejestracji automatyzowania pozyskiwania nowych źródeł danych:
- Szczegóły źródła są rejestrowane, w tym środowiska produkcyjne oraz fabryki danych.
- Przechwytywane są ograniczenia dotyczące kształtu, formatu i jakości danych.
- Zespoły ds. aplikacji danych powinny wskazać, czy dane są poufne (dane osobowe) Ta klasyfikacja napędza proces tworzenia folderów typu data lake w celu pozyskiwania nieprzetworzonych, wzbogaconych i wyselekcjonowanych danych. Źródło określa dane surowe i wzbogacone, a nazwy produktów danych to dane zarządzane.
- W celu pozyskania i udzielenia dostępu do zestawu danych tworzy się jednostkę usługi i grupy zabezpieczeń.
- Zadanie pozyskiwania jest tworzone w strefie lądowania danych w metasklepie usługi Data Factory.
- Interfejs API wstawia definicję danych do usługi Microsoft Purview.
- W przypadku weryfikacji źródła danych i zatwierdzenia przez zespół ds. operacji szczegóły są publikowane w magazynie metadanych usługi Data Factory.
Planowanie pobierania danych
W usłudze Azure Data Factory zadania kopiowania sterowane metadanymi zapewniają funkcjonalność, która umożliwia sterowanie potokami orkiestracji przez wiersze w Tabeli Kontrolnej przechowywanej w usłudze Azure SQL Database. Narzędzie do kopiowania danych umożliwia wstępne tworzenie potoków opartych na metadanych.
Po utworzeniu potoku przepływ pracy aprowizacji dodaje wpisy do tabeli sterowania w celu obsługi pozyskiwania ze źródeł zidentyfikowanych przez metadane rejestracji zasobów danych. Potoki usługi Azure Data Factory i usługa Azure SQL Database zawierające magazyn metadanych Tabeli sterowania mogą istnieć w każdej strefie docelowej danych w celu utworzenia nowych źródeł danych i pozyskiwania ich do stref docelowych danych.
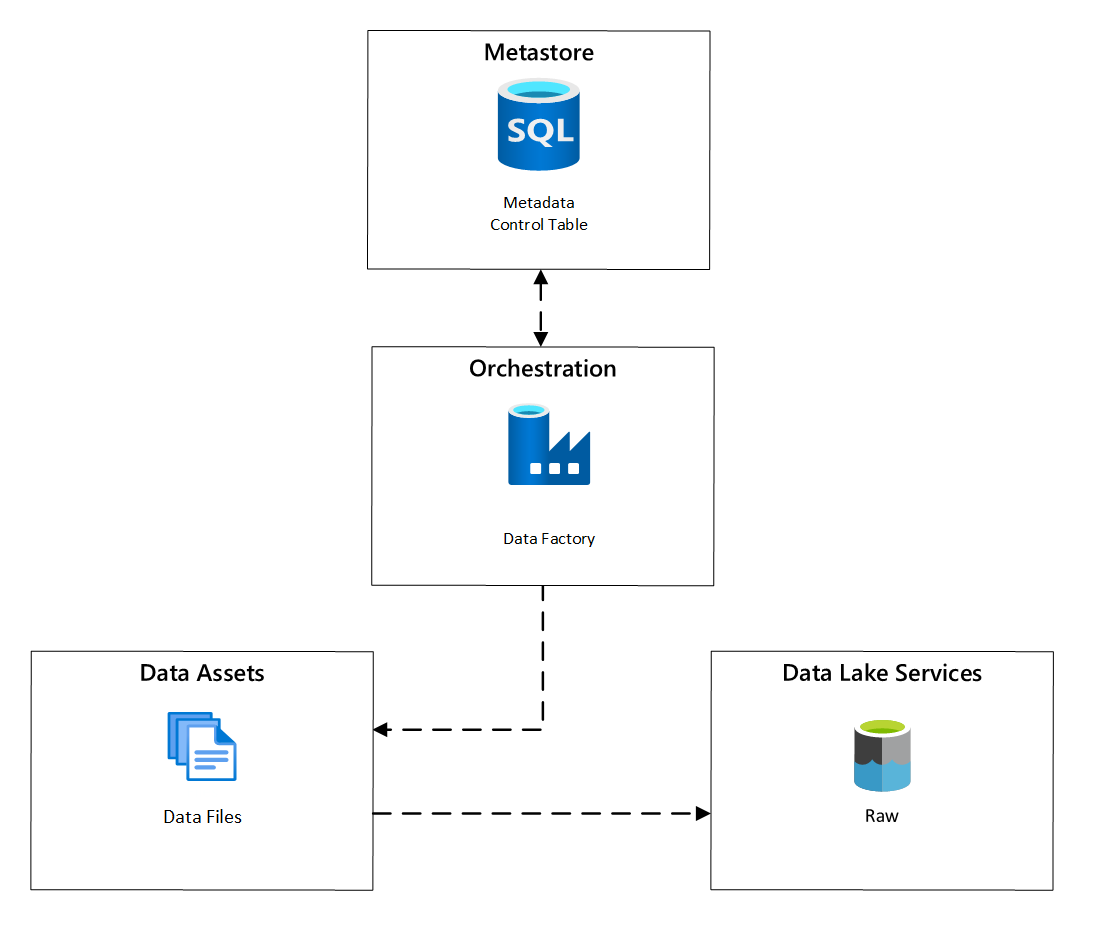
Rysunek 6. Planowanie pozyskiwania zasobów danych.
Szczegółowy przepływ pracy pozyskiwania nowych źródeł danych
Na poniższym diagramie pokazano, jak pobrać zarejestrowane źródła danych w metadanych bazy danych SQL w usłudze Data Factory i jak dane są początkowo pozyskiwane.
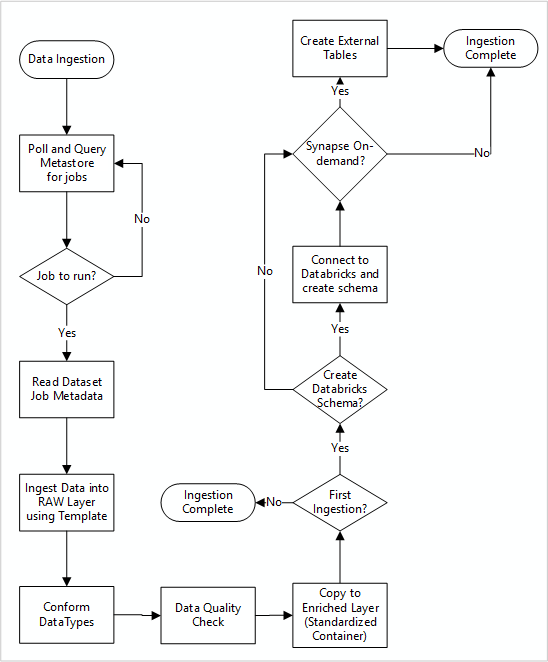
Główny potok przetwarzania danych Data Factory odczytuje konfiguracje z metadanych bazy danych SQL Data Factory, a następnie działa iteracyjnie z odpowiednimi parametrami. Dane są przesyłane ze źródła do warstwy pierwotnej w usłudze Azure Data Lake bez zmian. Kształt danych jest weryfikowany na podstawie magazynu metadanych usługi Data Factory. Formaty plików są konwertowane na formaty Apache Parquet lub Avro, a następnie kopiowane do wzbogaconej warstwy.
Pozyskane dane łączą się z obszarem roboczym nauki o danych i inżynierii usługi Azure Databricks, a definicja danych jest tworzona w strefie docelowej danych w magazynie metadanych Apache Hive.
Jeśli musisz użyć bezserwerowej puli SQL usługi Azure Synapse w celu uwidocznienia danych, niestandardowe rozwiązanie powinno tworzyć widoki nad danymi w jeziorze danych.
Jeśli potrzebujesz szyfrowania na poziomie wiersza lub kolumny, niestandardowe rozwiązanie powinno umieścić dane w usłudze Data Lake, a następnie pozyskać dane bezpośrednio do tabel wewnętrznych w pulach SQL i skonfigurować odpowiednie zabezpieczenia w obliczeniach pul SQL.
Przechwycone metadane
W przypadku korzystania z zautomatyzowanego pozyskiwania danych można wykonywać zapytania dotyczące skojarzonych metadanych i tworzyć pulpity nawigacyjne w celu:
- Śledź zadania i najnowsze znaczniki czasu ładowania danych dla produktów danych związanych z ich funkcjami.
- Śledź dostępne produkty danych.
- Zwiększ woluminy danych.
- Uzyskaj aktualizacje w czasie rzeczywistym dotyczące niepowodzeń zadań.
Metadane operacyjne mogą służyć do śledzenia:
- Zadania, kroki zadania i ich zależności.
- Wydajność pracy i historia wydajności.
- Wzrost ilości danych.
- Błędy zadań.
- Zmiany metadanych źródłowych.
- Funkcje biznesowe, które zależą od produktów danych.
Odnajdywanie danych przy użyciu interfejsu API REST usługi Microsoft Purview
Interfejsy API REST usługi Microsoft Purview powinny być używane do rejestrowania danych w trakcie wstępnego pobierania. Interfejsy API umożliwiają przesyłanie danych do wykazu danych zaraz po ich pobraniu.
Aby uzyskać więcej informacji, zobacz jak używać interfejsów API REST usługi Microsoft Purview.
Rejestrowanie źródeł danych
Użyj następującego wywołania interfejsu API, aby zarejestrować nowe źródła danych:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}
parametry identyfikatora URI dla źródła danych:
| Nazwa | Wymagane | Typ | Opis |
|---|---|---|---|
accountName |
Prawda | Struna | Nazwa konta usługi Microsoft Purview |
dataSourceName |
Prawda | Struna | Nazwa źródła danych |
Używanie interfejsu API REST usługi Microsoft Purview do rejestracji
W poniższych przykładach pokazano, jak używać interfejsu API REST usługi Microsoft Purview do rejestrowania źródeł danych przy użyciu ładunków:
Zarejestruj źródło danych usługi Azure Data Lake Storage Gen2:
{
"kind":"AdlsGen2",
"name":"<source-name> (for example, My-AzureDataLakeStorage)",
"properties":{
"endpoint":"<endpoint> (for example, https://adls-account.dfs.core.windows.net/)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Zarejestruj źródło danych SQL Database:
{
"kind":"<source-kind> (for example, AdlsGen2)",
"name":"<source-name> (for example, My-AzureSQLDatabase)",
"properties":{
"serverEndpoint":"<server-endpoint> (for example, sqlservername.database.windows.net)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Notatka
<collection-name>to bieżąca kolekcja, która istnieje na koncie usługi Microsoft Purview.
Utwórz skan
Dowiedz się, jak utworzyć poświadczenia do uwierzytelniania źródeł w usłudze Microsoft Purview przed skonfigurowaniem i uruchomieniem skanowania.
Użyj następującego wywołania interfejsu API do skanowania źródeł danych:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/
parametrów identyfikatora URI na potrzeby skanowania:
| Nazwa | Wymagane | Typ | Opis |
|---|---|---|---|
accountName |
Prawdziwe | Struna | Nazwa konta usługi Microsoft Purview |
dataSourceName |
Prawda | Struna | Nazwa źródła danych |
newScanName |
Prawda | Struna | Nazwa nowego skanowania |
Użyj interfejsu API REST usługi Microsoft Purview do skanowania
W poniższych przykładach pokazano, jak używać interfejsu API REST usługi Microsoft Purview do skanowania źródeł danych przy użyciu ładunków:
Skanowanie źródła danych usługi Azure Data Lake Storage Gen2:
{
"name":"<scan-name>",
"kind":"AdlsGen2Msi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AdlsGen2"
}
}
Skanowanie źródła danych usługi SQL Database:
{
"name":"<scan-name>",
"kind":"AzureSqlDatabaseMsi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AzureSqlDatabase",
"databaseName": "<database-name>",
"serverEndpoint": "<server-endpoint> (for example, sqlservername.database.windows.net)"
}
}
Użyj następującego wywołania interfejsu API do skanowania źródeł danych:
POST https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/run