Operacjonalizacja siatki danych na potrzeby inżynierii cech opartych na domenie sztucznej inteligencji/uczenia maszynowego
Siatka danych ułatwia organizacjom przejście ze scentralizowanego magazynu danych typu data lake lub magazynu danych do decentralizacji opartej na domenie danych analitycznych podkreślonych przez cztery zasady: własność domeny, dane jako produkt, samoobsługowa platforma danych i federacyjny nadzór obliczeniowy. Data mesh zapewnia korzyści wynikające z posiadania rozproszonych danych oraz lepszą jakość i zarządzanie danymi, co przyspiesza działalność biznesową i przyspiesza dostarczanie wartości dla organizacji.
Implementacja siatki danych
Typowa implementacja siatki danych obejmuje zespoły domen z inżynierami danych, którzy tworzą potoki danych. Zespół utrzymuje operacyjne i analityczne magazyny danych, takie jak jeziora danych, hurtownie danych lub jeziora-hurtownie danych. Udostępniają potoki jako produkty danych dla zespołów z innych obszarów albo zespołów nauki o danych do wykorzystania. Inne zespoły używają produktów danych za pomocą centralnej platformy zarządzania danymi, jak pokazano na poniższym diagramie.
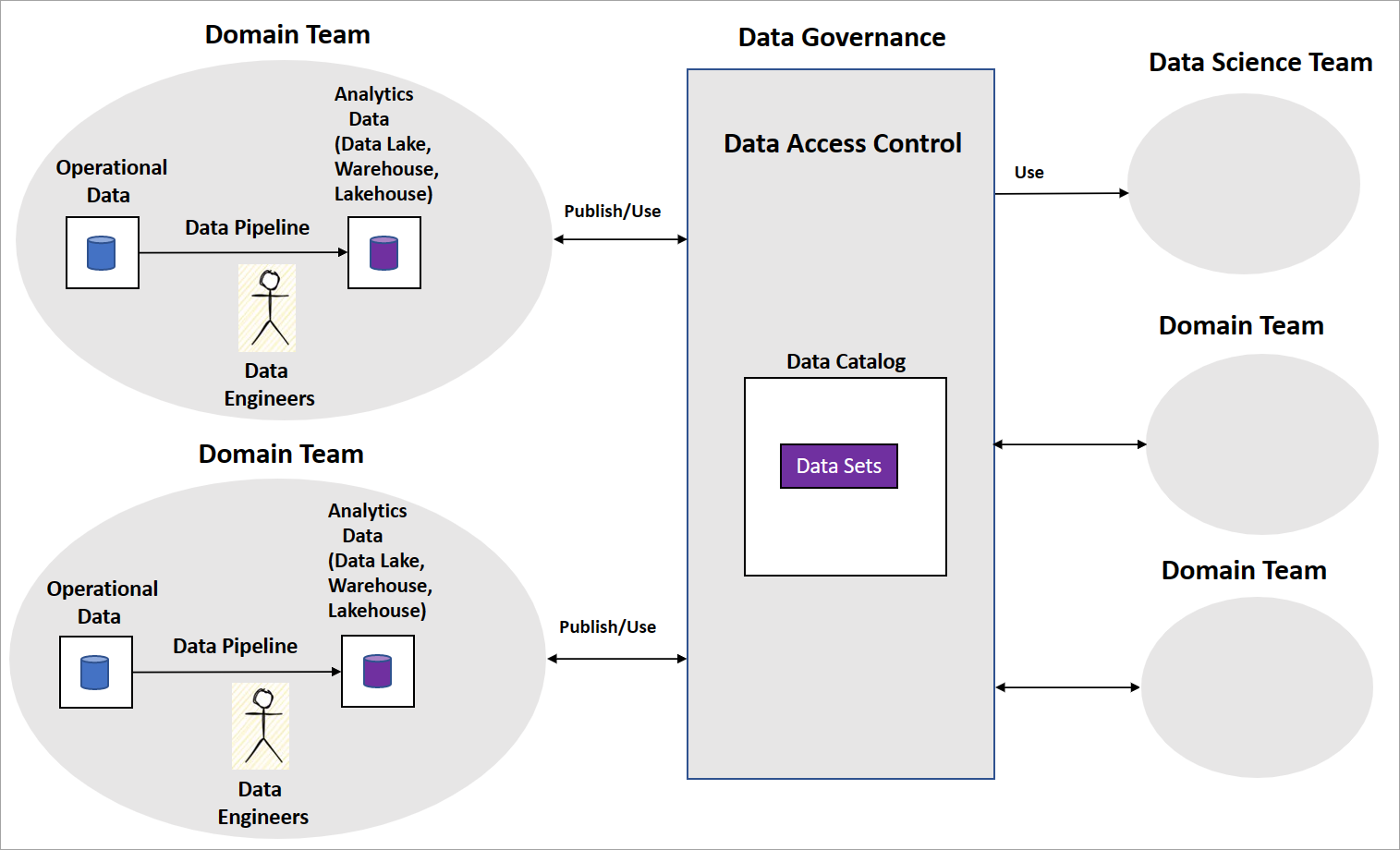
Siatka danych jest jasna w jaki sposób produkty danych obsługują przekształcone i zagregowane zestawy danych na potrzeby analizy biznesowej. Nie chodzi jednak o podejście, które organizacje powinny podjąć w celu tworzenia modeli sztucznej inteligencji/uczenia maszynowego. Nie ma też wskazówek dotyczących struktury zespołów nauki o danych, ładu modelu sztucznej inteligencji/uczenia maszynowego oraz udostępniania modeli sztucznej inteligencji/uczenia maszynowego lub funkcji między zespołami domeny.
W poniższej sekcji opisano kilka strategii, których organizacje mogą używać do opracowywania funkcji sztucznej inteligencji/uczenia maszynowego w ramach siatki danych. Zostanie wyświetlona propozycja strategii dotyczącej inżynierii cech lub siatki cech opartej na domenie.
Strategie sztucznej inteligencji/uczenia maszynowego dla siatki danych
Jedną z typowych strategii jest przyjęcie przez organizację zespołów nauki o danych jako użytkowników danych. Te zespoły uzyskują dostęp do różnych produktów danych domeny w siatkach danych zgodnie z przypadkiem użycia. Przeprowadzają eksplorację danych i inżynierię cech danych w celu opracowywania i budowy modeli sztucznej inteligencji/uczenia maszynowego. W niektórych przypadkach zespoły ds. domen opracowują również własne modele sztucznej inteligencji/uczenia maszynowego przy użyciu danych i produktów danych innych zespołów w celu rozszerzenia i uzyskania nowych funkcji.
Inżynieria cech jest kluczowym elementem w budowie modeli i jest zazwyczaj złożona i wymaga wiedzy fachowej. Ta strategia może być czasochłonna, ponieważ zespoły ds. nauki o danych muszą analizować różne produkty danych. Mogą nie mieć pełnej wiedzy na temat domeny w celu tworzenia funkcji wysokiej jakości. Brak wiedzy na temat domeny może prowadzić do powielania prac związanych z inżynierią cech między zespołami zajmującymi się domeną. Ponadto problemy, takie jak powtarzalność modelu sztucznej inteligencji/uczenia maszynowego z powodu niespójnych zestawów funkcji w różnych zespołach. Zespoły ds. nauki o danych lub domenie muszą stale odświeżać funkcje w miarę wydawania nowych wersji produktów danych.
Inną strategią jest udostępnienie przez zespoły domen modeli sztucznej inteligencji/uczenia maszynowego w formacie, na przykład Open Neural Network Exchange (ONNX), ale te wyniki są czarnymi polami i połączeniem modeli sztucznej inteligencji/uczenia maszynowego lub funkcji w różnych domenach byłoby trudne.
Czy istnieje sposób decentralizacji modelu sztucznej inteligencji/uczenia maszynowego w różnych zespołach ds. domen i nauki o danych, aby sprostać wyzwaniom? Proponowana strategia inżynierii cech lub siatki cech opartej na domenie jest opcją.
Inżynieria funkcji napędzana domeną lub sieć funkcji
Oparta na domenie strategia inżynierii cech lub siatki cech oferuje zdecentralizowane podejście do tworzenia modelu sztucznej inteligencji/uczenia maszynowego w ustawieniu siatki danych. Na poniższym diagramie przedstawiono strategię i sposób, w jaki odnosi się do czterech głównych zasad siatki danych.
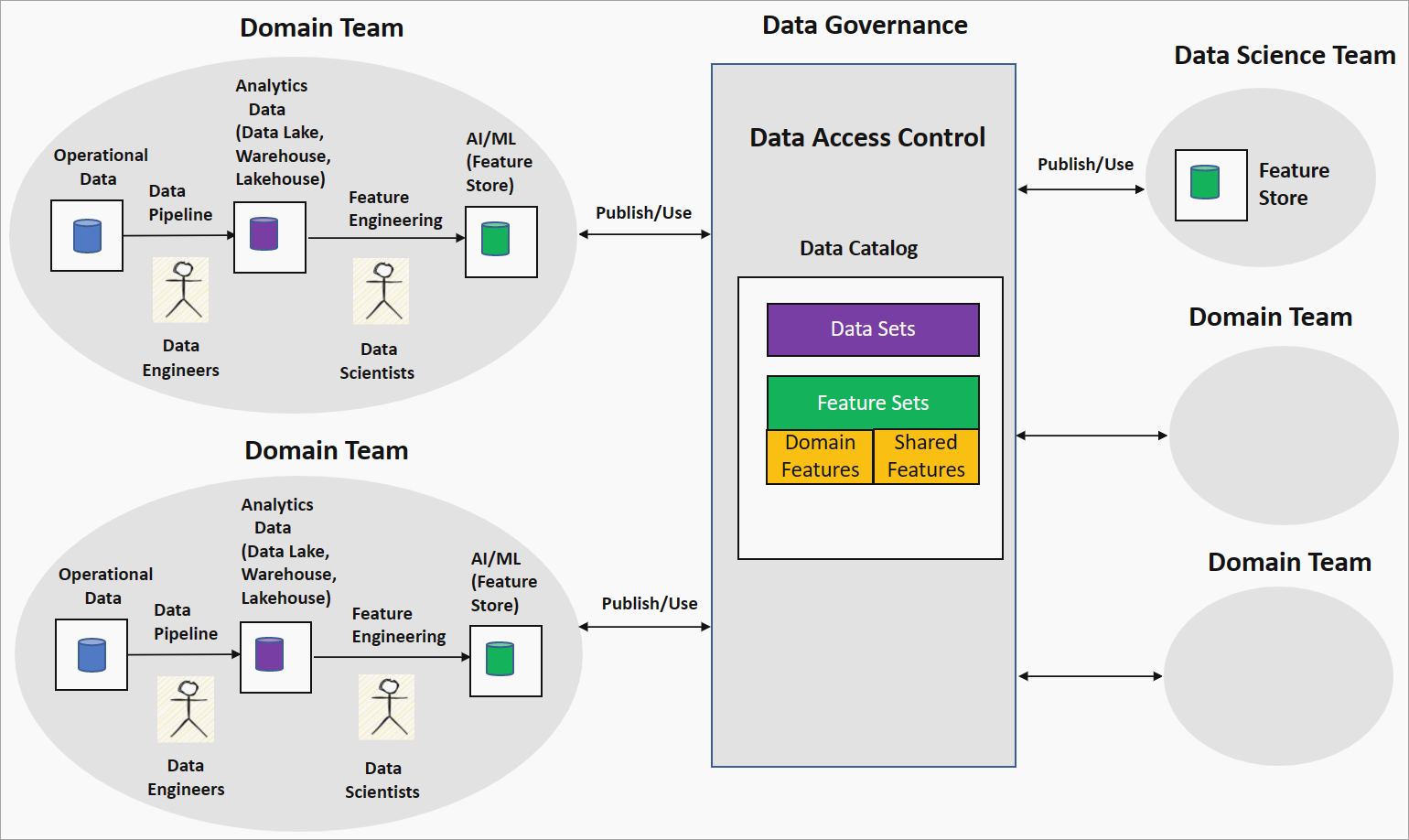
Inżynieria funkcji zarządzania domenami przez zespoły domenowe
W tej strategii organizacja łączy analityków danych z inżynierami danych w zespole domeny, aby uruchomić eksplorację danych na temat czystych i przekształconych danych, na przykład w usłudze Data Lake. Inżynieria generuje cechy, które są przechowywane w magazynie cech. Magazyn funkcji to repozytorium danych, które służy do trenowania i wnioskowania oraz pomaga śledzić wersje funkcji, metadane i statystyki. Ta funkcja umożliwia analitykom danych w zespole domeny ścisłą współpracę z ekspertami w dziedzinie i utrzymywanie odświeżonych funkcji w miarę zmian danych w domenie.
Dane jako produkt: zestawy funkcji
Funkcje generowane przez zespół domeny, znany jako funkcje domeny lub funkcje lokalne, są publikowane w wykazie danych na platformie nadzoru danych jako zestawy funkcji. Te zestawy funkcji są używane przez zespoły nauki o danych lub inne zespoły domen do tworzenia modeli sztucznej inteligencji/uczenia maszynowego. Podczas tworzenia modeli sztucznej inteligencji/uczenia maszynowego zespoły nauki o danych lub domenie mogą łączyć funkcje domeny w celu tworzenia nowych funkcji nazywanych funkcjami udostępnionymi lub globalnymi. Udostępniane funkcje są publikowane z powrotem do katalogu zestawów funkcji do wykorzystania.
Samoobsługowa platforma danych i ład obliczeniowy federacyjny: standaryzacja funkcji i jakość
Ta strategia może prowadzić do wdrożenia innego stosu technologii dla potoków inżynierii funkcji i niespójnych definicji funkcji między zespołami zajmującymi się różnymi domenami. Zasady samoobsługowej platformy danych zapewniają, że zespoły domen używają wspólnej infrastruktury i narzędzi do tworzenia potoków inżynierii funkcji i wymuszania kontroli dostępu. Zasada federacyjnego ładu obliczeniowego zapewnia współdziałanie zestawów funkcji za pośrednictwem globalnej standaryzacji i kontroli jakości funkcji.
Użycie opartej na domenie strategii inżynierii cech lub siatki cech oferuje zdecentralizowane podejście do tworzenia modeli sztucznej inteligencji/uczenia maszynowego dla organizacji, aby skrócić czas opracowywania modeli sztucznej inteligencji/uczenia maszynowego. Ta strategia pomaga zachować spójność funkcji w zespołach domeny. Pozwala unikać duplikowania wysiłków i prowadzić do wysokiej jakości funkcji w celu uzyskania bardziej dokładnych modeli sztucznej inteligencji/uczenia maszynowego, które zwiększają wartość firmy.
Implementacja siatki danych na platformie Azure
W tym artykule opisano pojęcia związane z operacjonalizacją sztucznej inteligencji/uczenia maszynowego w siatce danych i nie obejmują narzędzi ani architektur do tworzenia tych strategii. Platforma Azure oferuje funkcje takie jak Azure Databricks feature store i Feathr z serwisu LinkedIn. Możesz opracowywać Microsoft Purview łączników niestandardowych w celu zarządzania i nadzorowania magazynami funkcji.